
Corso
Etica dell'AI
1 h
120K
La corsa all’IA a febbraio 2026 è stata insolitamente intensa. Dopo che Anthropic ha rilasciato Claude Opus 4.6 e Claude Sonnet 4.6 a distanza di due settimane, Google ha risposto con Gemini 3.1 Pro.
Google afferma che si tratta di un rilascio significativo, soprattutto perché Gemini 3.1 Pro ha più che raddoppiato le sue prestazioni di ragionamento rispetto a Gemini 3 Pro, come misurato dal benchmark ARC-AGI-2, dove ha ottenuto un punteggio verificato del 77,1%
ARC-AGI-2 è importante perché testa il riconoscimento di pattern inediti piuttosto che la conoscenza memorizzata. È progettato in modo che i modelli non possano semplicemente “allenarsi” per ottenere un punteggio alto nel senso tradizionale. Quindi un raddoppio in questo test è più significativo rispetto, ad esempio, a MMLU. Più avanti approfondiremo l’importanza di questo risultato e lo testeremo anche in prima persona.
Per saperne di più sull’ecosistema IA di Google, ti consiglio le nostre guide su NotebookLM e Nano Banana 2, oltre al nostro tutorial sul Gemini CLI. Dai anche un’occhiata alla nostra guida su uno dei concorrenti più forti di Gemini, il GPT-5.4 di OpenAI.
Teniamo i nostri lettori aggiornati sulle ultime novità dell’IA con The Median, la nostra newsletter gratuita del venerdì che riassume le notizie chiave della settimana. Iscriviti e resta sul pezzo in pochi minuti a settimana:
Gemini 3.1 Pro è l’ultimo modello di punta di Google, rilasciato in anteprima il 19 febbraio 2026. È la prima volta che Google usa un incremento di versione “.1” (ogni aggiornamento intermedio precedente usava “.5”), segnalando un upgrade mirato all’intelligenza piuttosto che un’ampia espansione delle funzionalità. Ha senso, perché Gemini 3 era già un rilascio ampio che introduceva una nuova architettura multimodale.
Il post di lancio di Google spiega che l’intelligenza alla base delle recenti scoperte scientifiche di Deep Think, tra cui la confutazione di una congettura matematica decennale, è stata ora distillata in 3.1 Pro per l’uso quotidiano.
Tecnicamente Deep Think era già disponibile, ma solo con un abbonamento Ultra. Google vorrebbe far credere che l’obiettivo sia sempre stato portare questo tipo di ragionamento all’uso quotidiano su larga scala, ma è solo con questo rilascio di Gemini 3.1 che sembra stia davvero mantenendo la promessa. Forse Google ha scoperto che l’abbonamento Ultra da 249 $/mese era più di quanto le persone fossero disposte a pagare.
Ecco i miglioramenti chiave di questo rilascio:
Come accennato nell’introduzione, il grande cambiamento riguarda il ragionamento astratto e multi-step. Le prestazioni di Gemini 3.1 su ARC-AGI-2 sono più che raddoppiate rispetto a Gemini 3 Pro in circa tre mesi.
Oltre ai miglioramenti su ARC-AGI-2, il modello ha ottenuto il punteggio più alto mai registrato su GPQA Diamond, un benchmark di scienze a livello graduate.
Gemini 3.1 Pro adotta sempre il cosiddetto “pensiero dinamico”: applica automaticamente il chain-of-thought in base alla complessità del compito.
L’API ha introdotto un nuovo parametro thinking_level con quattro impostazioni: low, medium (nuovo in 3.1), high e max, offrendo agli sviluppatori un punto di equilibrio tra velocità e profondità.
Uno dei segnali più chiari in questo rilascio è quanto siano migliorati i benchmark “agentici”. Il modello ora ottiene punteggi molto più alti in ricerche web autonome, compiti multi-step a lungo orizzonte e coding da terminale rispetto al predecessore.
Per chi costruisce workflow in cui il modello opera con supervisione minima (debugging, ricerche web, raccolta dati), questi miglioramenti contano davvero nella pratica.
Le prestazioni agentiche sono all’incirca raddoppiate rispetto a Gemini 3 Pro in alcune categorie, e ora superano GPT-5.2 e Claude nella maggior parte di questi benchmark.
Questo mi ha colpito. Google ha evidenziato che Gemini 3.1 Pro può generare SVG animati e dashboard interattivi interamente tramite output di codice. Poiché si tratta di definizioni matematiche e non di immagini renderizzate, scalano senza perdita di qualità e sono molto più leggeri dei file video.
Gli esempi del lancio sono notevoli: un sito portfolio generato dai temi di Cime tempestose, una dashboard aerospaziale live che estrae la telemetria della ISS e una murmurazione di storni 3D con hand-tracking e colonna sonora generativa.
Si tratta di output di codice, non di immagini: quindi sono modificabili, incorporabili e leggeri.
È meno appariscente ma probabilmente più rilevante nell’immediato per chi ha usato Gemini 3 Pro in produzione. Un reclamo ricorrente sul modello precedente era che tagliasse le risposte lunghe a metà generazione.
Le segnalazioni degli utenti dopo il lancio indicano che 3.1 Pro risolve il problema. Un utente ha riferito di aver generato una risposta enorme in un’unica esecuzione senza alcun troncamento.
JetBrains ha anche confermato reali miglioramenti qualitativi con il nuovo modello, notando che offre “risultati più affidabili” con “meno token di output” necessari. Quel guadagno di efficienza, unito all’assenza di troncamento, fa davvero la differenza nella generazione long-form.
Google mostra che Gemini 3.1 Pro è in testa in 13 dei 16 test benchmark più importanti, inclusi quelli relativi al ragionamento astratto, ai compiti agentici e alle scienze a livello graduate. (Gemini 3 Pro già guidava in alcuni di questi benchmark.)
Ecco come il modello più recente si confronta con gli altri grandi rilasci di febbraio 2026.
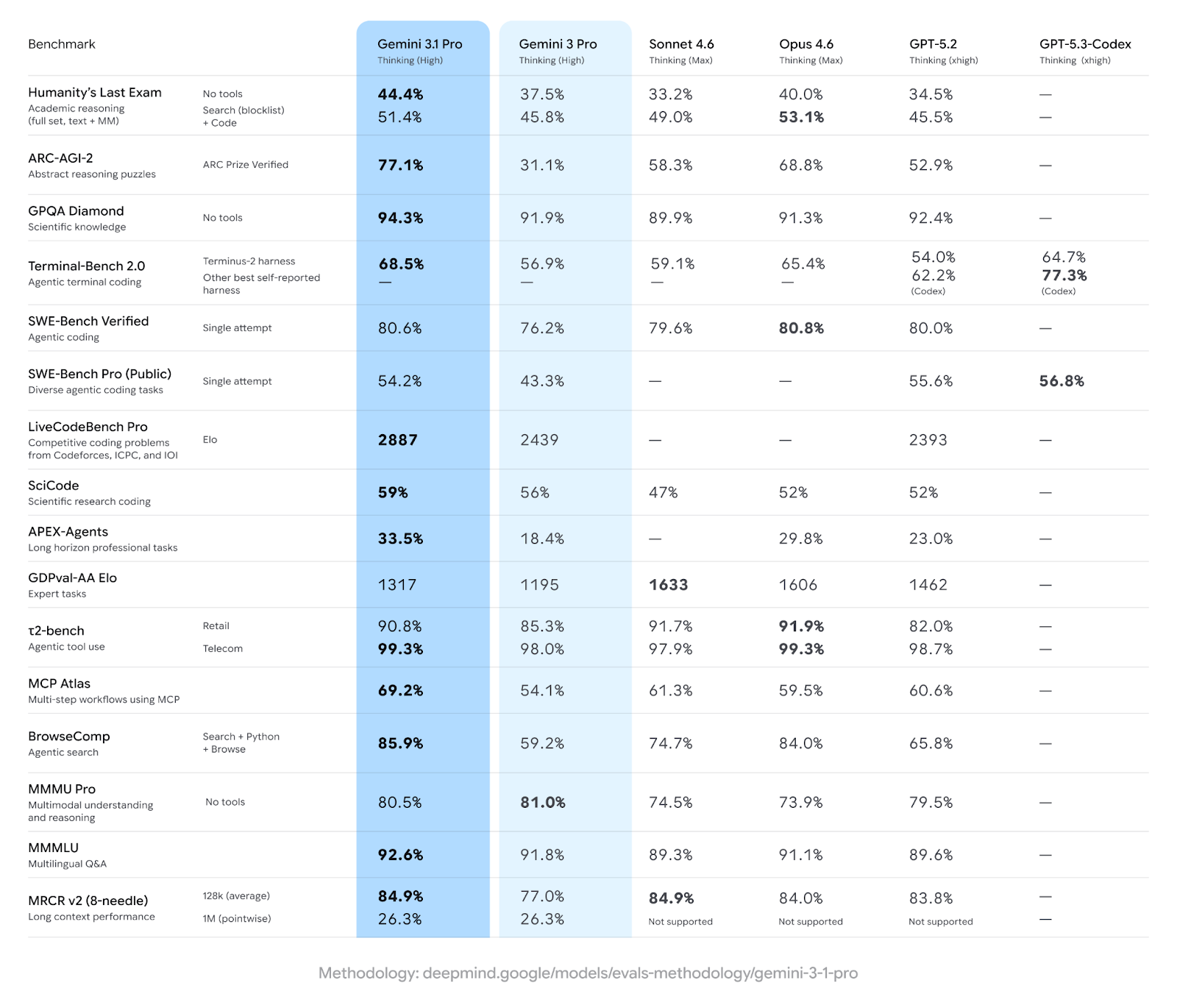
Come puoi vedere, e come dicevo, il risultato nel ragionamento astratto è il più sorprendente. Gemini 3.1 Pro è nettamente avanti rispetto a Opus 4.6, che a sua volta è nettamente avanti rispetto a GPT-5.2. Rappresenta un vero cambio di passo rispetto allo stato dell’arte dei modelli di frontiera solo un anno fa.
Voglio essere chiaro su questo perché è facile lasciarsi trascinare dai numeri. I modelli Claude sono davvero in testa in alcune aree importanti:
Il quadro onesto: Gemini 3.1 Pro è oggi il miglior modello per ragionamento astratto, conoscenza scientifica e ampiezza multimodale. I modelli Claude restano avanti per knowledge work, orchestrazione di strumenti e uso del software tramite interfaccia grafica.
Per vedere come questi miglioramenti si traducono in ragionamento reale, ho eseguito tre test progettati per sondare diversi aspetti del pensiero astratto:
Per vedere come Gemini 3.1 Pro gestisce il ragionamento in stile ARC-AGI-2, abbiamo usato un semplice puzzle di inferenza di regole. Il modello deve dedurre sia una regola sul colore sia una sulla forma a partire dagli esempi, senza che le regole vengano dichiarate esplicitamente.
Ecco il mio prompt:
You are shown these transformations:
- [Red Circle] → [Blue Triangle]
- [Blue Square] → [Red Circle]
- [Red Square] → [Blue Circle]
- [Blue Triangle] → ?Gemini 3.1 Pro ha restituito codice SVG pulito con animazioni CSS. L’output era un loader a tre puntini con rimbalzo sfalsato, esattamente quanto richiesto. Si è renderizzato correttamente nel browser al primo tentativo, senza necessità di modifiche. La dimensione del file era minima e, poiché è codice vettoriale, scala perfettamente a qualsiasi dimensione.
È una di quelle funzionalità che suonano come gimmick in un comunicato stampa ma che poi risultano davvero pratiche. Grafica animata leggera, incorporabile e infinitamente scalabile a partire da un prompt testuale è uno strumento solido per il prototyping frontend o per asset visivi rapidi.
Gemini 3.1 Pro è attualmente in anteprima. Google ha dichiarato che raggiungerà la disponibilità generale a breve, dopo aver recepito i feedback e apportato ulteriori miglioramenti ai workflow agentici.
Ecco le principali opzioni di accesso:
Il Gemini CLI è un agente da terminale open-source che dà al modello accesso diretto al tuo ambiente locale. Installalo con il seguente comando:
npm install -g @google/gemini-cli
# Or run directly: npx @google/gemini-cliLa CLI usa un loop ReAct, il che significa che può scrivere codice, eseguirlo, leggere gli errori, correggere i problemi e iterare in autonomia. Con le migliori prestazioni di coding da terminale di 3.1 Pro, questo loop è visibilmente più affidabile. Il livello gratuito offre 60 richieste al minuto e 1.000 al giorno.
L’API di Gemini offre agli sviluppatori accesso programmatico diretto a Gemini 3.1 Pro.
L’ID del modello che ti serve è: gemini-3.1-pro-preview
Ecco un po’ di codice Python per iniziare:
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="Your prompt here"
)
print(response.text)Il pricing è lo stesso di Gemini 3 Pro Preview.
|
Dimensione contesto |
Input (per 1M token) |
Output (per 1M token) |
|
≤200K token |
$2.00 |
$12.00 |
|
>200K token |
$4.00 |
$18.00 |
Il parametro thinking_level accetta low, medium, high o max. Gli strumenti supportati includono Google Search, contesto da URL, esecuzione di codice e ricerca file. Tratterò i dettagli della finestra di contesto nella sezione di confronto qui sotto.
NotebookLM ora è alimentato da Gemini 3.1 Pro per gli abbonati Google AI Pro e Ultra. NotebookLM risponde solo sulla base dei documenti che carichi, rendendolo uno strumento di ricerca davvero utile quando vuoi che il modello resti ancorato a materiali specifici.
Google ha iniziato a distribuire Gemini 3.1 Pro nei suoi prodotti consumer e per sviluppatori, ma non ha pubblicato una semplice mappatura “piano X = modello Y”. In pratica, vedrai 3.1 Pro nell’app Gemini e nell’API man mano che viene distribuito, con AI Ultra che offre l’accesso più ampio.
|
Piano |
Prezzo mensile (US) |
Cosa ottieni relativo a Gemini |
|
Gratis |
$0 |
Gemini 3 Flash nell’app Gemini, funzionalità limitate |
|
Google AI Pro |
$19.99 |
Limiti più alti e accesso ai modelli Gemini Pro nell’app Gemini |
|
Google AI Ultra |
$249.99 (spesso scontato a $124.99 per i primi 3 mesi) |
Limiti massimi, modalità Deep Think e accesso alle ultime funzionalità IA di Google nei vari prodotti |
I rilasci di febbraio 2026 di Google e Anthropic hanno creato un set di trade-off davvero interessante. Non sono situazioni in cui un modello vince chiaramente. La scelta giusta dipende molto da ciò che stai costruendo.
Vale la pena soffermarsi sul divario di prezzo. Gemini 3.1 Pro costa molto meno sia in input sia in output rispetto a Claude Opus 4.6. Se esegui chiamate API ad alto volume, non è una differenza da poco.
Sulla base dei benchmark e dei test pratici, ecco le aree in cui Gemini 3.1 Pro è particolarmente adatto:
Gemini 3.1 Pro è un buon esempio della direzione in cui stanno andando questi modelli. Meno focus su nuovi tipi di input, più focus su un ragionamento migliore, agenti più affidabili e gestione di contesti più lunghi. Anche se è solo un rilascio “.1”, i miglioramenti nei benchmark e il legame con Deep Think lo fanno sembrare un passo avanti più grande nel modo in cui questi sistemi pensano.
Per i team che costruiscono prodotti reali, non esiste un unico modello “migliore”. Gemini 3.1 Pro funziona bene per ragionamento scientifico, agenti di ricerca e analisi di grandi codebase, soprattutto considerando prezzo e supporto video. Claude è ancora migliore per knowledge work e uso del computer attraverso lo schermo, e GPT-5.3-Codex vince ancora in alcuni test di coding.
La domanda interessante è cosa succederà quando uscirà dall’anteprima. Google ha detto che sta lavorando a miglioramenti agentici prima del rilascio completo. Se arriveranno insieme agli attuali upgrade di ragionamento, il divario tra modelli di ricerca come Deep Think e modelli per l’uso quotidiano si ridurrà. Per ora, è un buon momento per provare modelli diversi e costruire sistemi capaci di sfruttare al meglio i punti di forza di ciascuno.
Per iniziare con gli strumenti IA di Google, dai un’occhiata al nostro corso Introduzione a Google Gemini . Per lavorare con l’API in Python, il nostro tutorial Working with the Gemini API copre gli elementi essenziali.
Impara con DataCamp
Corso
Corso
Corso