
Track
AI Fundamentals
10 hr
Gemini 1.5 Pro represents a significant advancement in the Gemini family. It introduces long-context reasoning, which empowers us to work with massive datasets across various modalities (text, video, and audio).
In this tutorial, we’ll learn how to connect to the Gemini 1.5 Pro API. We’ll learn to execute tasks such as retrieval, long-document and video question answering, long-context automatic speech recognition (ASR), and in-context learning.
If you want to learn more about Gemini, check out this article on What is Google Gemini.
Gemini AI encompasses a series of generative AI models collaboratively developed by multiple teams within Google, including Google Research and Google DeepMind.
These models, equipped with strong capabilities for general-purpose multi-modal tasks, are designed to assess developers in content generation and problem-solving tasks. Each model variant is optimized to specific use cases, ensuring optimal performance across diverse scenarios.
Gemini AI addresses the balance between computational resources and functionality by offering three model sizes:
|
Model |
Size |
Capabilities |
Ideal Use Cases |
|
Gemini Ultra |
Largest |
Most capable, handles highly complex tasks |
Demanding applications, large-scale projects, intricate problem-solving |
|
Gemini Pro |
Medium |
Versatile, suitable for a wide range of tasks, scalable |
General-purpose applications, adaptable to diverse scenarios, projects requiring a balance of power and efficiency |
|
Gemini Nano |
Smallest |
Lightweight and efficient, optimized for on-device and resource-constrained environments |
Mobile applications, embedded systems, tasks with limited computational resources, real-time processing pen_spark |
Our primary focus will be on Gemini 1.5 Pro, the first model released within the Gemini 1.5 series.
Gemini 1.5 Pro, with its large context window of up to at least 10 million tokens, can address the challenge of understanding long contexts across a broad spectrum of applications in real-world scenarios.
A comprehensive evaluation of long dependency tasks has been conducted to thoroughly assess the Gemini 1.5 Pro model’s long-context capabilities. The Gemini 1.5 Pro model adeptly addressed the challenging "needle-in-a-haystack" task, achieving near-perfect (>99%) recall of the "needle" even amidst haystacks spanning multiple millions of tokens across all modalities, encompassing text, video, and audio.
This recall performance was notably maintained even with haystack sizes reaching 10 million tokens within the text modality.
The Gemini 1.5 Pro model surpassed all competing models, including those augmented with external retrieval methods, particularly on tasks necessitating an understanding of the interdependencies across multiple evidence widely spanning the entire long content, such as long dependency Question-Answer (QA) instances.
Gemini 1.5 Pro has also shown its remarkable ability, enabled by very long text, to learn tasks in context, such as translating a new language from a single set of linguistic documentation.
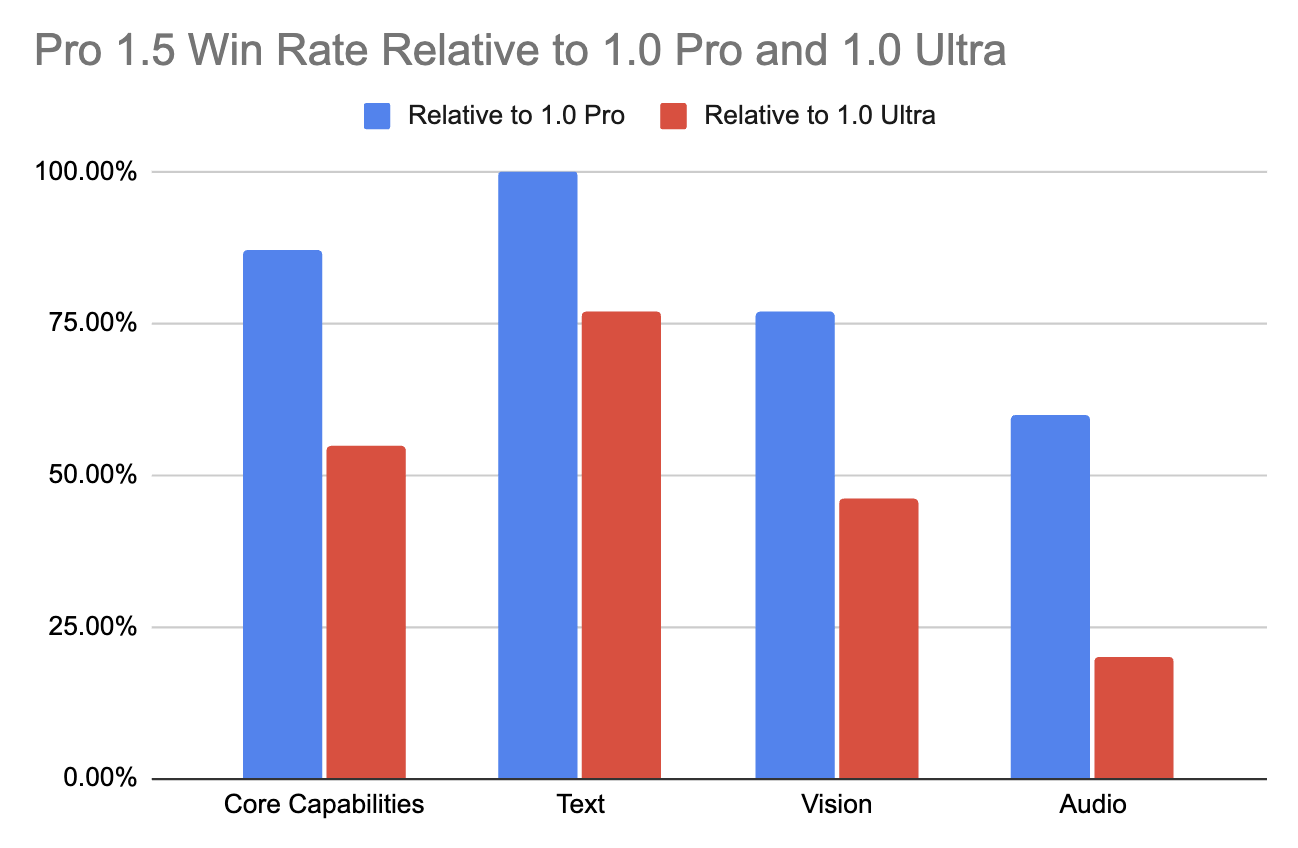
This advancement in Gemini 1.5 Pro's long-context performance is noteworthy, as it doesn't compromise the model's fundamental multi-modal capabilities. Compared to its predecessor (1.0 Pro), it substantially improved in various areas (+28.9% in Math, Science, and Reasoning).
It even surpasses the top-of-the-line 1.0 Ultra model in over half of the benchmarks, particularly excelling in text and vision tasks (as shown in the table below). This is achieved despite requiring fewer resources and being more computationally efficient.
For more detailed insights, I recommend consulting the technical report: “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context”for more detailed insights.
With the ability to process multiple millions of tokens, novel practical applications emerge.
Gemini 1.5 Pro can be widely used in software engineering. Given the entire 746,152 token JAX codebase in context, Gemini 1.5 Pro can identify the specific location of a core automatic differentiation method.
With access to a reference grammar book and a bilingual wordlist (total of ∼250k), Gemini 1.5 Pro can translate from English to Kalamang with a quality comparable to that of a human who studied using the same resources.
The limited availability of online data for Kalamang (less than 200 speakers) forces Gemini 1.5 Pro to rely solely on the context provided in each prompt to understand and translate the language. This finding suggests promising opportunities for utilizing LLMs with extended contextual abilities to aid in preserving and reviving endangered languages and fostering communication and comprehension among different linguistic communities.
Gemini 1.5 Pro can also answer an image query given the entire text of Les Misérables (1382 pages, 732k tokens). Being natively multimodal, the model can identify a famous scene from a hand-drawn sketch.
Given a 45-minute silent film “Sherlock Jr.” (2,674 frames at 1FPS, 684k tokens), Gemini 1.5 Pro retrieves and extracts textual information from a specific frame and provides the corresponding timestamp. The model can also identify a scene in the movie from a hand-drawn sketch.
Now that we know about Gemini 1.5 Pro’s capabilities and applications, let’s learn how to connect to its API.
First, we need to get an API key from the Google AI for Developers page (make sure you are logged in to your Google account). We can do this by clicking the Get an API key button:
Next, we need to establish the project and produce the API key.
Let’s first install the Gemini Python API package using pip.
%pip install google-generativeaiNext, we’ll launch our Jupyter notebook and import the essential Python libraries required for our project.
import google.generativeai as genai
from google.generativeai.types import ContentType
from PIL import Image
from IPython.display import Markdown
import time
import cv2Let’s start by filling our API key in the GOOGLE_API_KEY variable and configure it:
GOOGLE_API_KEY = ‘your-api-key-goes-here’
genai.configure(api_key=GOOGLE_API_KEY)Before calling the API, let’s first check the available models through the free API.
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)models/gemini-1.0-pro
models/gemini-1.0-pro-001
models/gemini-1.0-pro-latest
models/gemini-1.0-pro-vision-latest
models/gemini-1.5-flash-latest
models/gemini-1.5-pro-latest
models/gemini-pro
models/gemini-pro-visionLet's access the gemini-1.5-pro-latest model:
model = genai.GenerativeModel('gemini-1.5-pro-latest')Now let’s make our first API call and prompt Gemini 1.5 Pro!
response = model.generate_content("Please provide a list of the most influential people in the world.")
print(response.text)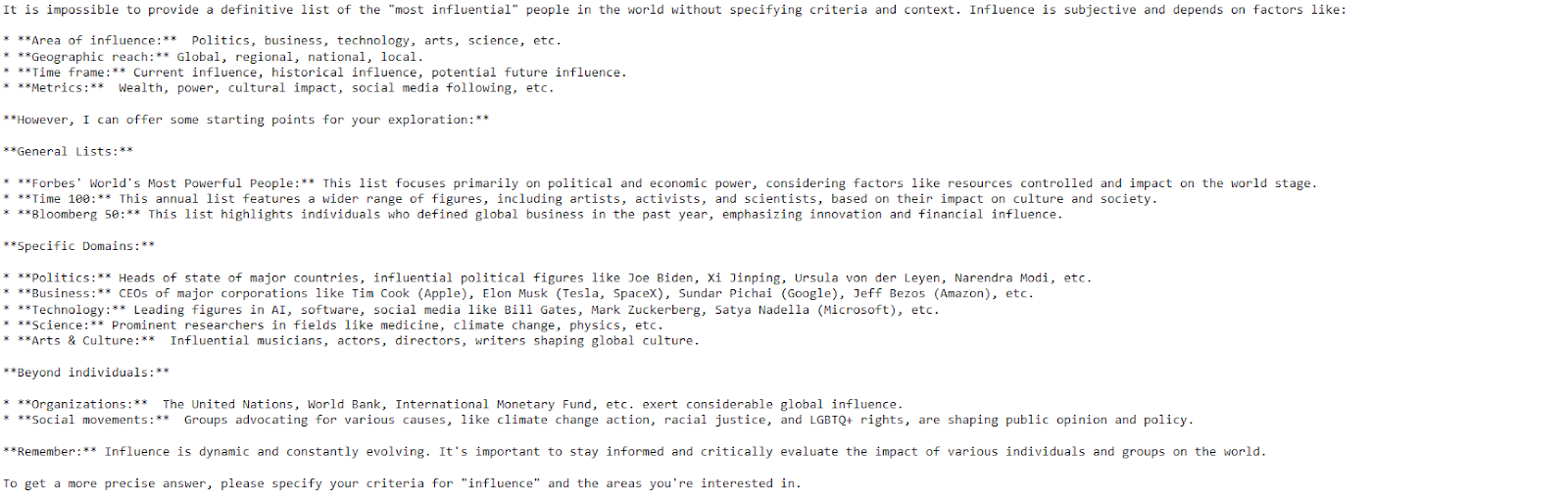
The model provided a clear and detailed response with just a few lines of code.
Gemini AI can produce multiple responses called candidates for a prompt, allowing you to select the most appropriate one. 
In this section, we’ll learn how to leverage Gemini 1.5 Pro to automate extracting a list of books from an image!
Let’s first consider this image:

An image of a bookshelf with several books stacked on it.
Let’s first instruct the model to identify and list book titles in the image following a specific order:
text_prompt = "List all the books and help me organize them into three categories."Next, we’ll open our "bookshelf.jpeg" image using the Image class, preparing it for the model's analysis.
bookshelf_image = Image.open('bookshelf.jpeg')Let’s put both text_prompt and bookshelf_image into a list and prompt the model:
prompt = [text_prompt, bookshelf_image]
response = model.generate_content(prompt)To avoid having the output in Markdown format, let's use the IPython Markdown tool.
Markdown(response.text)
The model has successfully managed to categorize all the books present in the uploaded image into three different categories .
In this tutorial, we have presented Gemini 1.5 Pro, the first release from the Gemini 1.5 family. Beyond its multi-modal capabilities and efficiency, Gemini 1.5 Pro expands the content window compared to the Gemini 1.0 series from 32k to multiple millions of tokens.
Whether working with text, images, video, or audio, the Gemini 1.5 Pro API offers the flexibility to tackle various applications, from information retrieval and question-answering to content generation and translation.
If you want to learn more about AI, check out this six-course AI Fundamentals skill track.
Learn more about LLMs!
Track
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Kurtis Pykes
Tutorial
Ryan Ong
code-along
Richie Cotton
code-along
Zoumana Keita




