
Course
Support Vector Machines in R
4 hr
11K
At its core, a vector database is a purpose-built system designed for the storage and retrieval of vector data. In this context, a vector refers to an ordered set of numerical values that could represent anything from spatial coordinates to feature attributes, such as the case for machine learning and data science use cases where vectors are often used to represent the features of objects. The vector database can efficiently store and retrieve these feature vectors.

Image by Gary Alway
Vector embedding is the process of representing objects, such as words, sentences, or entities, as vectors in a continuous vector space. This technique is commonly used to convert high-dimensional and categorical data into continuous, lower-dimensional vectors, which can be more effectively used by machine learning algorithms. Vector embeddings are particularly popular in natural language processing (NLP), where they are used to represent words or phrases.
The primary idea behind vector embedding is to capture semantic relationships between objects. In the context of word embeddings, for example, words with similar meanings are represented by vectors that are closer together in the vector space. This allows machine learning models to better understand the contextual and semantic relationships between words.
Building on the concept of vector embeddings, Large Language Models (LLMs) leverage these numerical representations to tackle complex language understanding and generation tasks.
As a concrete example, the underlying architecture of the model for chat GTP involves the use of vectors. The model processes input data, such as text, by converting it into numerical vectors.
These vectors capture the semantic and contextual information of the input, allowing the model to understand and generate coherent and contextually relevant responses. The Transformer architecture, which GPT-3.5 is built upon, utilizes self-attention mechanisms to weigh the importance of different words in a sequence, further enhancing the model's ability to capture relationships and context.
“Self-attention” refers to the model's capability to assign varying degrees of importance to different words within the input sequence.
So, in essence, the GPT-3.5 model operates on vectorized representations of language to perform various natural language understanding and generation tasks. This vector-based approach is a key factor in the model's success across a wide range of language-related applications.
PG Vector is an open-source vector similarity search for Postgres. Let’s jump straight in and create a database with Docker. Create a file named docker-compose.yml then at the command line run the following command: docker-compose up -d
services:
db:
hostname: db
image: ankane/pgvector
ports:
- 5432:5432
restart: always
environment:
- POSTGRES_DB=vectordb
- POSTGRES_USER=testuser
- POSTGRES_PASSWORD=testpwd
- POSTGRES_HOST_AUTH_METHOD=trustThe next step is to create a table, and for this example, we are going to catalog DataCamp learning resources, including courses, blogs, tutorials, podcasts, cheat sheets, code alongs, and certifications.
CREATE TABLE resource (
id serial CONSTRAINT "PK_resource" PRIMARY KEY,
name varchar NOT NULL,
content text NOT NULL,
slug varchar NOT NULL,
type varchar NOT NULL,
embedding vector,
CONSTRAINT "UQ_resource" UNIQUE (name, type)
);The embedding column will be generated from a stringified JSON object representing the resource attributes { name, content, slug, type }. To create this vector embedding, we'll utilize an embedding model.
One such model available on AWS Bedrock is amazon.titan-embed-text-v1. Configuring Bedrock isn't covered in this article; it's just an example of one among many embedding models capable of achieving similar results. The primary objective is to take textual input, employ an embedding model to generate vector embeddings, and then store them in the embedding column.
// typescript
const client = new BedrockRuntimeClient({ region: process.env.AWS_REGION });
const response = await client.send(
new InvokeModelCommand({
modelId: "amazon.titan-embed-text-v1",
contentType: "application/json",
accept: "application/json",
body: JSON.stringify({
inputText: JSON.stringify(resource),
}),
})
);
const { embedding } = JSON.parse(new TextDecoder().decode(response.body));# python
client = boto3.client("bedrock-runtime", region_name=region)
response = client.invoke_endpoint(
EndpointName="amazon.titan-embed-text-v1",
ContentType="application/json",
Accept="application/json",
Body=json.dumps({"inputText": json.dumps(resource)})
)
embedding = json.loads(response["Body"].read().decode("utf-8"))["embedding"]Empowered by the capability to store data alongside its vector embeddings, we unlock the power of vector databases, enabling us to engage in natural language-like conversations with our database, effortlessly retrieving meaningful results.
Just formulate any question you would like to “ask your data” and apply the same embedding to that text. Here is what the SQL query looks like:
SELECT
name,
content,
type,
slug,
1 - (embedding <=> $1) AS similarity
FROM
resource
WHERE
1 - (embedding <=> $1) > $2
ORDER BY
similarity DESC;This query employs a cosine similarity search. Parameter $1 represents the embedding result of your input question text, while parameter $2, serving as the similarity threshold, is a variable that will benefit from experimentation. Its optimal value hinges on factors like your dataset's size and your desired result relevance, shaping the granularity of the retrieved information.
With all these components in place, creating a chat-style UI becomes straightforward. The specifics of implementing such an interface are beyond the scope of this article, but here are some examples using my DataCamp dataset, which comprises over 600+ records:
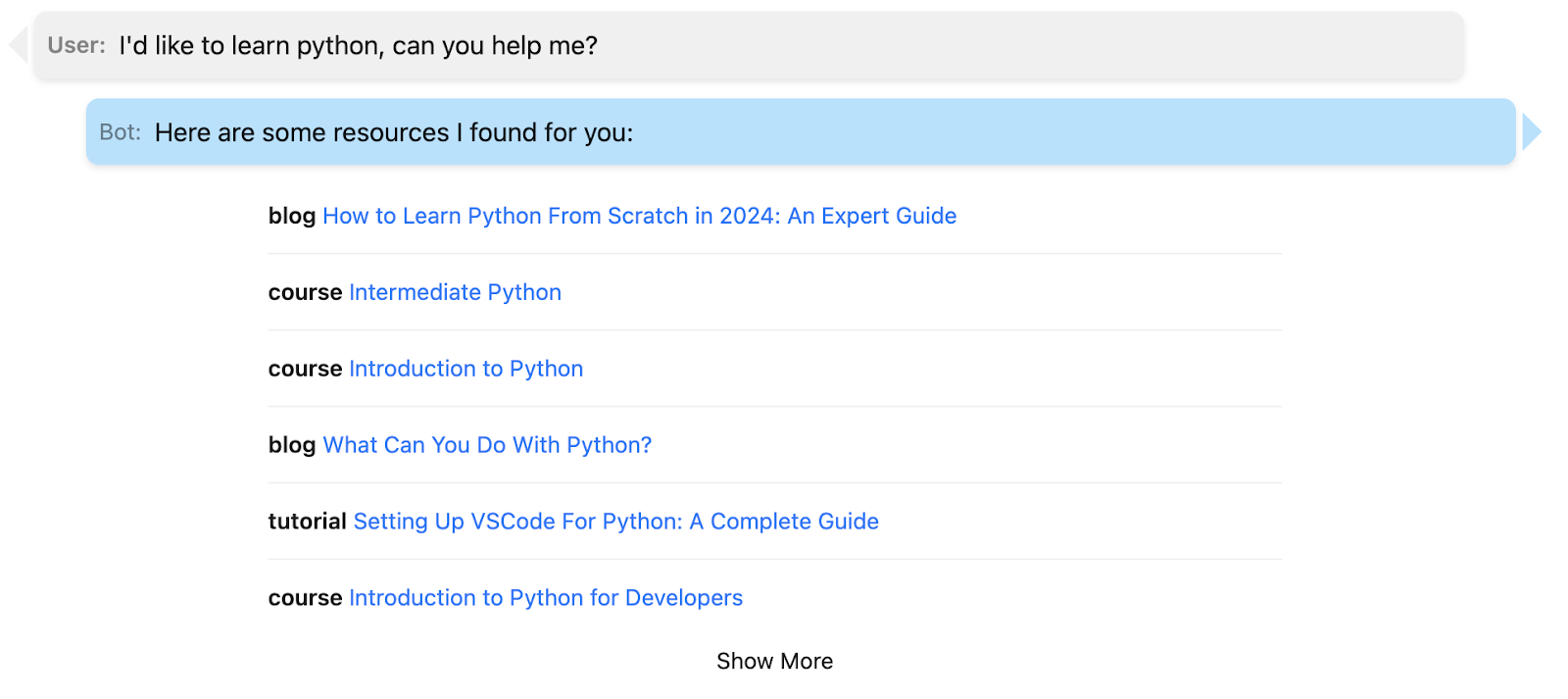
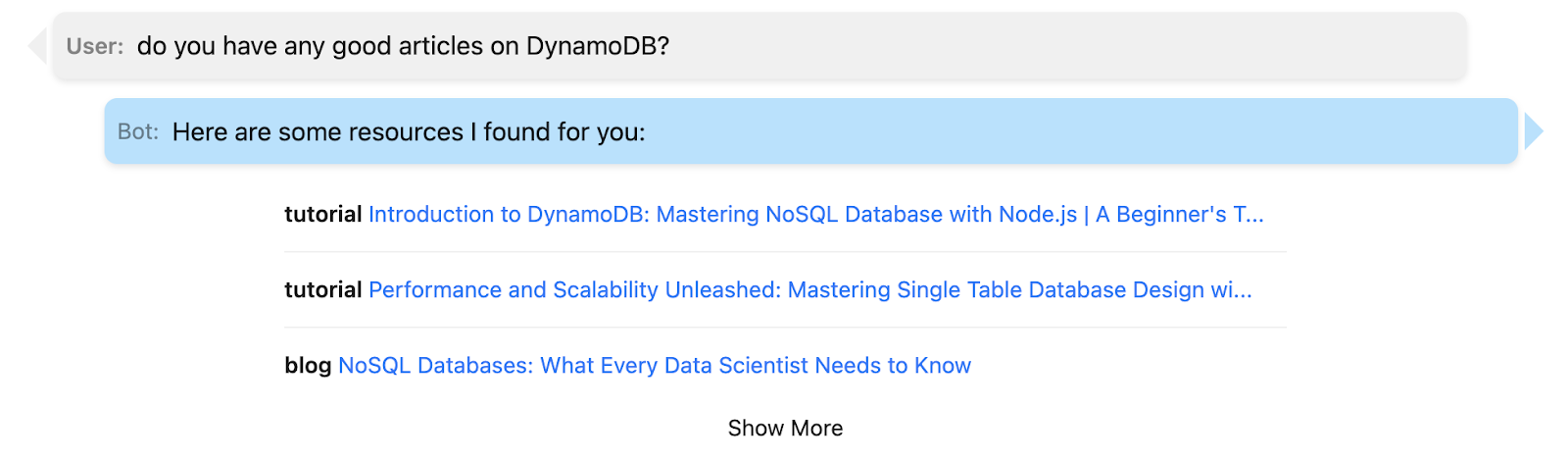
In this article, we've explored the powerful realm of vector databases, leveraging PG Vector to enhance our data storage and retrieval capabilities. As you embark on your journey with vector embeddings, there's much more to discover and learn. To delve deeper into PG Vector, see their readme, which goes into more detail and includes links to clients for your preferred programming language.
A natural progression from understanding vector embeddings is Retrieval Augmented Generation (RAG). This is the process of injecting contextual data into large language models (LLMs). By doing so, RAG provides the model with knowledge outside of its training data, enabling more informed and contextually relevant responses.
You can also find a range of DataCamp resources that cover other elements of vector databases, including:
Happy coding, and may your vector-based endeavors be both insightful and rewarding!
Continue Your Vector Journey Today!
Course
Course
Course
blog
Moez Ali
14 min
blog
Kurtis Pykes
11 min
Tutorial
Moez Ali
Tutorial
Joanne Xiong
Tutorial
Abid Ali Awan
code-along
JP Hwang


