
Course
Streaming Data with AWS Kinesis and Lambda
4 hr
8.5K
If you're building modern applications, you know how important it is to handle large volumes of data efficiently. Event streaming platforms are the go-to solution for real-time data processing and analysis.
In this article, we'll explore two of the most popular platforms in this space: Apache Kafka and Amazon Simple Queue Service (SQS). We'll compare the strengths and weaknesses of each platform and provide practical insights to help you make informed decisions for your data-driven projects.
For those who know precisely what they're after and are just seeking a quick comparison between Apache Kafka and Amazon SQS, the table below will serve as a concise guide. However, if you're looking for a more detailed one, continue reading for an extensive comparison.
|
Category |
Kafka |
SQS |
Winner |
|
Architecture |
Distributed, pub-sub |
Centralized, pull-based |
Kafka |
|
Scalability |
Highly scalable for large volumes |
Highly scalable for smaller volumes |
Kafka for large, SQS for small |
|
Message Persistence |
Configurable retention periods |
Limited retention periods |
Kafka |
|
Message Delivery |
At-least-once, exactly-once with transactions |
At-least-once, exactly-once with deduplication |
Tie |
|
Consumer Groups |
Supported |
Not supported |
Kafka |
|
Integration |
Broad ecosystem, connectors |
Tight AWS integration |
Kafka for non-AWS, SQS for AWS |
|
Ease of Use |
Steeper learning curve |
Fully managed, easier to start |
SQS |
|
Cost |
Open-source, infrastructure costs |
Pay-as-you-go |
SQS for smaller workloads, Kafka for larger |
|
Message Retention |
Longer |
14 days |
Kafka |
|
Protocol Support |
Multiple |
Limited |
Kafka |
|
Syntax Difficulty |
More complex |
Simple and straightforward |
SQS |
Event streaming platforms like Apache Kafka and Amazon SQS are top picks in modern data-driven environments. They enable you to collect, process, and analyze data as it is generated, allowing for faster decision-making and improved responsiveness.
These are some of the reasons why event streaming platforms like Kafka and SQS are important:
Event streaming platforms enable continuous data collection and real-time data processing. This capability is relevant for applications that require immediate insights and actions, such as financial trading systems, fraud detection, and social media monitoring. By processing data as it arrives, you can make timely decisions and respond swiftly to emerging events.
These platforms support asynchronous communication, decoupling the producers and consumers of data. This decoupling allows different system components to operate independently, enhancing resilience and flexibility. Asynchronous communication also enables services to scale independently and evolve without causing disruptions to other components.
Both Kafka and SQS are designed for high scalability and reliability. Kafka can handle millions of events per second by scaling horizontally through the addition of more brokers. SQS automatically scales to manage increased message volumes, making it suitable for varying workloads. These capabilities ensure that the platforms can meet the demands of large-scale data processing tasks.
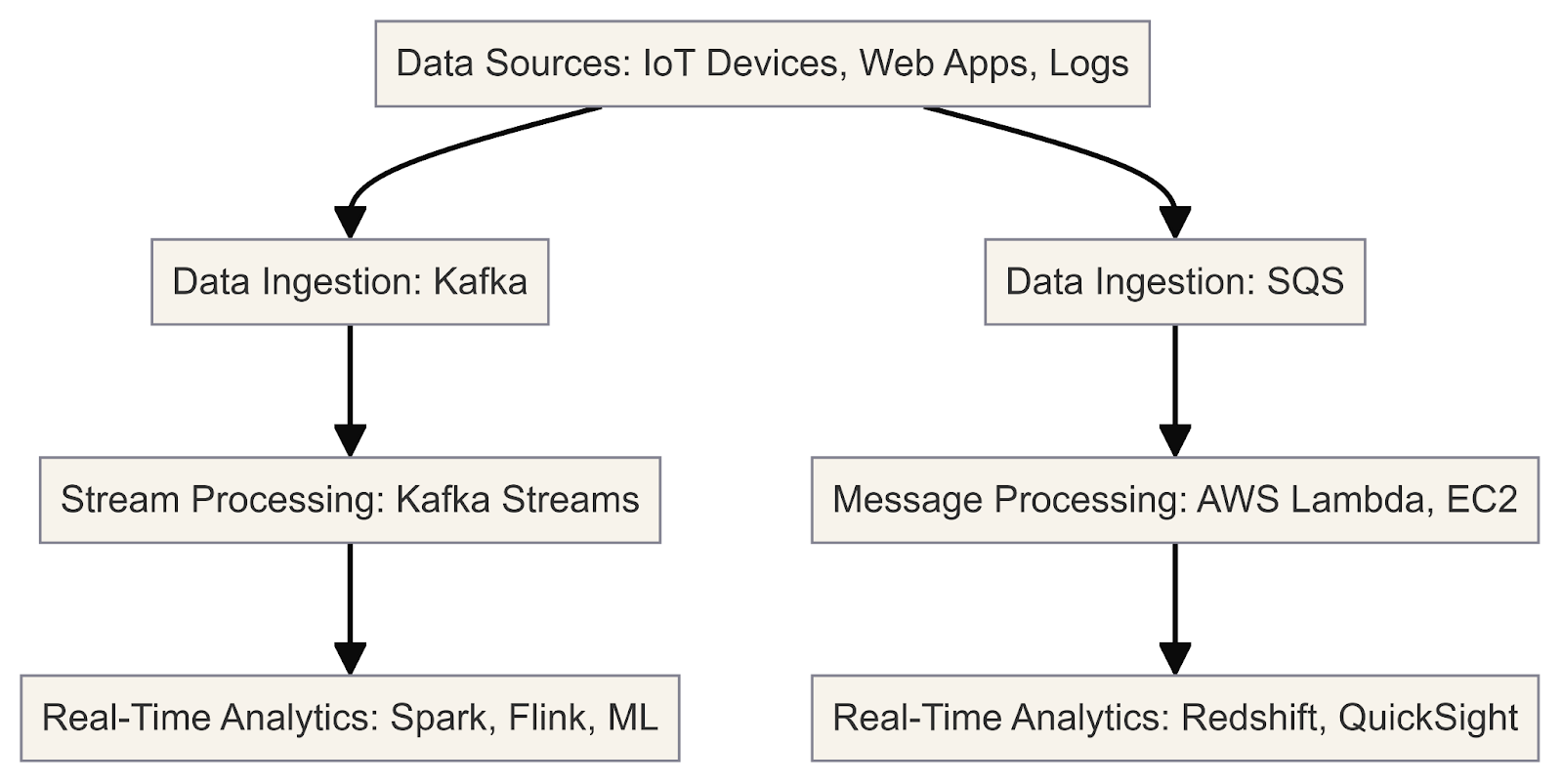
This diagram illustrates the real-time data processing and analysis workflow using Kafka and SQS
Now that we have clarified the importance of streaming platforms let’s review Kafka and SQS in detail.
Apache Kafka is an open-source distributed event streaming platform designed for handling large volumes of real-time data feeds. It's often employed for tasks such as messaging, log aggregation, stream processing, and commit logs.
Kafka's architecture is built for high scalability and fault tolerance, making it a go-to solution for data-driven applications. Think of Kafka as a high-performance data pipeline that allows you to easily create real-time data pipelines and applications.
As a developer, you can leverage Kafka's core components to handle real-time data streams efficiently. Here's a practical example of how Kafka works with Python:
Visit the Apache Kafka website and download the latest version. Choose the binary download that matches your operating system.
Extract the downloaded archive to a directory of your choice. This directory will be your Kafka installation directory.
In a Terminal, navigate to the extracted Kafka directory and start the Zookeeper and Kafka broker services using the provided scripts:
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka broker
bin/kafka-server-start.sh config/server.propertiesNote that Zookeeper is currently marked as deprecated and is planned to be removed in Apache Kafka 4.0. For more details, see the documentation.
Brokers are the Kafka servers that handle the storage and replication of data streams. You can interact with brokers through command-line tools or programmatically using client libraries.
Here’s an example of using command-line tools to manage and interact with Kafka topics:
bin/kafka-topics.sh --create --topic my_topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1bin/kafka-topics.sh --list --bootstrap-server localhost:9092bin/kafka-console-producer.sh --topic my_topic --bootstrap-server localhost:9092bin/kafka-console-consumer.sh --topic my_topic --bootstrap-server localhost:9092 --from-beginningEnsure you have Python installed on your system. Kafka's Python client libraries support Python 3.7 and later versions.
Create a virtual environment to isolate your project dependencies. You can use venv.
This is the official Apache Kafka Python client library:
pip install kafka-pythonDepending on your project requirements, you may need to install additional libraries, such as json, for JSON serialization/deserialization.
Then, use the following script to list brokers programmatically:
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# List the available brokers
brokers = admin_client.describe_cluster()
print("Brokers:", brokers['brokers'])Partitions are a way Kafka achieves parallelism and scalability. Each partition is an ordered, immutable sequence of records that is continuously appended to. You can configure the number of partitions for a topic when creating it:
from kafka.admin import KafkaAdminClient, NewTopic
# Create an AdminClient
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092', client_id='test')
# Create a new topic with 3 partitions
topic = NewTopic(name="social-media-posts", num_partitions=3, replication_factor=1)
admin_client.create_topics([topic])Understanding partitions can help you optimize your applications for better performance and fault tolerance.
With Kafka and the required Python libraries installed, you can now start writing your Kafka producer and consumer applications in Python.
Here's an example of how you can create a Kafka producer to publish social media posts and a consumer to process them:
Producers are the clients that publish data streams to Kafka topics. They can be integrated into your applications, services, or data sources to push data into Kafka in real time.
from kafka import KafkaProducer
import json
# Create a Kafka producer
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('utf-8'))
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Publish the social media post to the 'social-media-posts' topic
producer.send('social-media-posts', social_media_post)Consumers are the clients that subscribe to one or more topics and consume data streams from Kafka. They can implement various consumption patterns based on your application's requirements.
from kafka import KafkaConsumer
import json
# Create a Kafka consumer
consumer = KafkaConsumer('social-media-posts',
bootstrap_servers='localhost:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
# Consume and process social media posts
for message in consumer:
social_media_post = message.value
print(f"Received post: {social_media_post}")
# Process the social media post...This sample code provides a comprehensive overview of installing Kafka, setting up the Python environment, and implementing Kafka producers and consumers for real-time data processing.
SQS is a fully managed message queuing service provided by AWS. It allows you to decouple and scale microservices, distributed systems, and serverless applications.
At its core, SQS is a distributed queue system that enables you to send, store, and receive messages between software components asynchronously. These messages can be any text data, system notifications, or even pointers to larger data stored in other AWS services like S3 or DynamoDB.
One key benefit of SQS is that it removes the need to manage your message queuing infrastructure. AWS handles the underlying queue management, scaling, and fault tolerance aspects under the hood, allowing you to focus on your application logic.
SQS offers two types of queues:
One of the advantages of SQS is that it’s part of the AWS ecosystem, and therefore it can easily integrate with other AWS services. The way such integration happens depends on whether the service is a producer or a consumer:
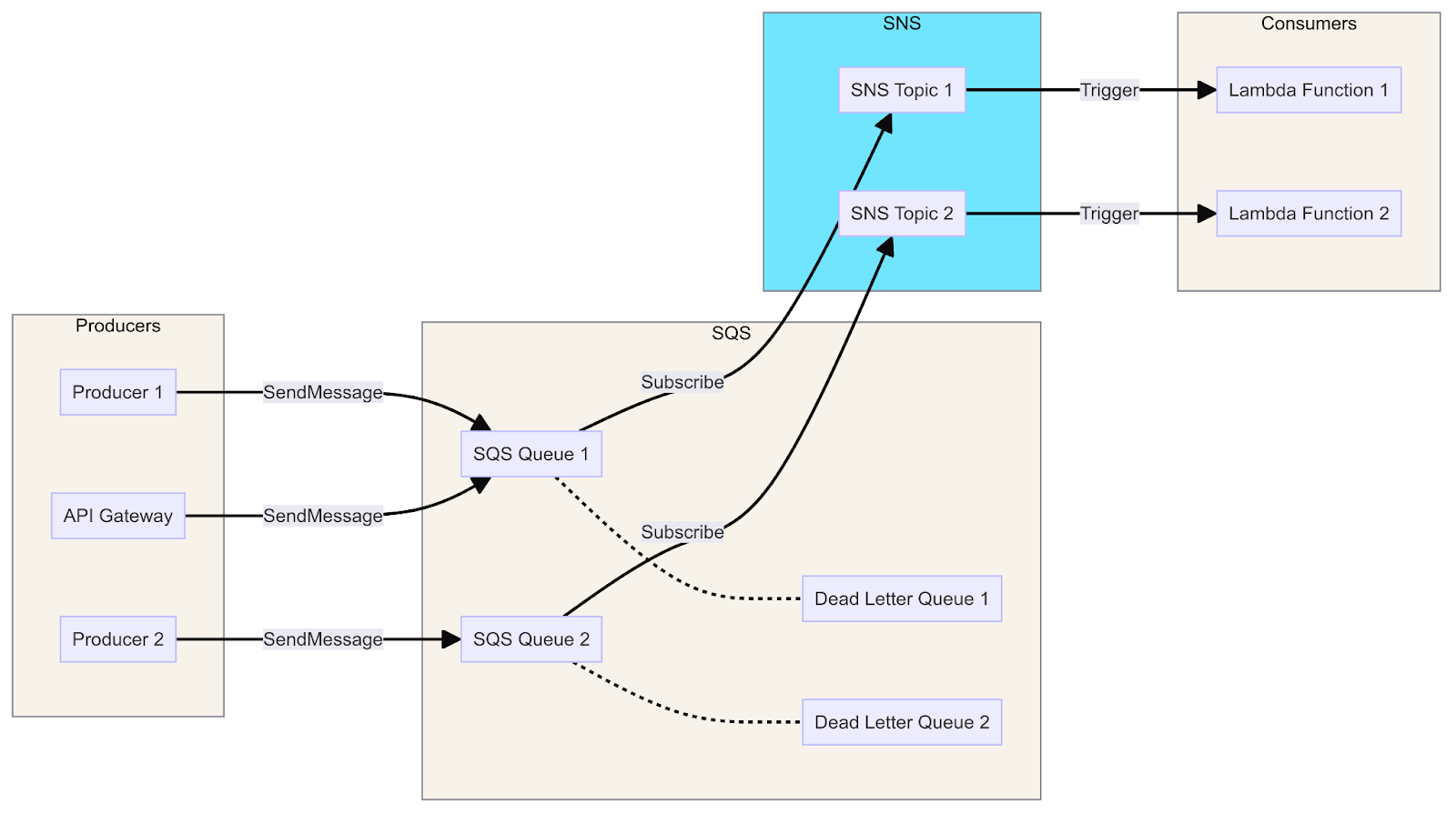
A diagram showing the integration of SQS with Lambda, SNS, and API Gateway, illustrates the message flow from producers to consumers via queues, topics, and functions.
Now let’s see producers and consumers in action. Here's a guide for setting up and using AWS SQS with Python, including basic steps for installation and an example producer and consumer for SQS:
If you don't already have one, create an AWS account at AWS Free Tier.
Install and configure the AWS Command Line Interface (CLI) to manage your AWS resources.
# Install AWS CLI
pip install awscli
# Configure AWS CLI with your credentials
aws configureProvide your AWS access key, secret key, region, and output format when prompted.
We will use the boto3 library, the official AWS SDK for Python, to interact with SQS using Python.
boto3pip install boto3Create an SQS queue using the AWS Management Console or programmatically using boto3.
import boto3
# Create SQS client
sqs = boto3.client('sqs')
# Create a new queue
response = sqs.create_queue(
QueueName='social-media-posts',
Attributes={
'DelaySeconds': '0',
'MessageRetentionPeriod': '86400' # 1 day
}
)
print(response['QueueUrl'])A producer sends messages to the SQS queue.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Define a social media post
social_media_post = {
'platform': 'Twitter',
'user': 'john_doe',
'text': 'Had a great time at the concert last night! #music #live'
}
# Send message to SQS queue
response = sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(social_media_post)
)
print(response['MessageId'])A consumer receives and processes messages from the SQS queue.
import boto3
import json
# Create SQS client
sqs = boto3.client('sqs')
queue_url = 'https://sqs.us-east-1.amazonaws.com/123456789012/social-media-posts' # Replace with your Queue URL
# Receive messages from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
MaxNumberOfMessages=10,
WaitTimeSeconds=10
)
if 'Messages' in response:
for message in response['Messages']:
social_media_post = json.loads(message['Body'])
print(f"Received post: {social_media_post}")
# Process the social media post...
# Delete received message from queue
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=message['ReceiptHandle']
)
else:
print('No messages received')That’s how you can easily create an SQS queue, send messages as a producer, and receive messages as a consumer. The previous example covers the basic steps to get you started.
For more detailed steps to set up, be sure to check out the AWS SQS documentation.
Now, let’s do a side-by-side comparison of Kafka and SQS and see their similarities.
Both Kafka and SQS are message-queuing systems designed to facilitate asynchronous communication between different components of a distributed system. They act as intermediaries, allowing producers to send messages and consumers to receive and process those messages.
Kafka and SQS decouple producers and consumers, enabling them to operate independently and scale independently. This decoupling promotes loose coupling, fault tolerance, and scalability in distributed systems.
Both Kafka and SQS provide mechanisms for persisting messages, ensuring that messages are not lost in case of failures or system restarts. Kafka stores messages in a distributed commit log, while SQS stores messages in a highly durable and available queue.
Kafka and SQS are designed to be highly scalable systems. Kafka can scale horizontally by adding more brokers to the cluster, while SQS can automatically scale to handle increasing message volumes.
Both Kafka and SQS offer integration capabilities with other systems and services. Kafka has a broad ecosystem of connectors and integrations, while SQS integrates seamlessly with other AWS services.
While Kafka and SQS have different ordering guarantees by default, both systems provide mechanisms for preserving message ordering when needed. Kafka offers ordered delivery within partitions, while SQS offers FIFO queues for strictly ordered message processing.
Kafka and SQS provide monitoring and metrics capabilities, allowing users to track and monitor the performance and health of their messaging systems.
Both Kafka and SQS offer security features, such as encryption, access control, and authentication mechanisms, to protect data in transit and at rest.
Now, let’s do a side-by-side comparison of Kafka and SQS and note their most important differences.
Kafka is a distributed streaming platform that follows a publish-subscribe model. It consists of a cluster of brokers that store and manage data streams in topics. Producers publish messages to topics, and consumers subscribe to topics to receive messages.
SQS is a fully managed messaging service provided by AWS. It follows a queue-based model where messages are sent to a queue, and consumers poll the queue to receive messages.
Kafka provides “at-least-once” delivery semantics, meaning messages can be delivered one or more times. It also supports “exactly-once” delivery through the use of idempotent producers and transactional writes.
SQS guarantees “at-least-once” delivery. For other protocols like HTTP/HTTPS, email, and SMS, Amazon SNS should be used in conjunction with SQS.
Kafka maintains message ordering within partitions, ensuring that messages are delivered in the order they were produced.
SQS does not guarantee message ordering by default. However, it supports FIFO topics, which preserve the exact order of messages.
Kafka stores messages on disk in a distributed commit log, providing durability and fault tolerance. Messages can be retained for a configurable period, allowing consumers to rewind and replay messages.
SQS does not provide long-term message persistence. Messages are stored temporarily until they are delivered to all subscribers or until they expire (based on the configured retention period).
Kafka is designed to scale horizontally by adding more brokers to the cluster. It also supports partitioning topics for parallelism and load balancing.
SQS is a fully managed service that automatically scales to handle increasing message volumes without the need for manual intervention.
Kafka has a rich ecosystem of connectors and integrations with various data sources, sinks, and processing frameworks, such as Apache Spark, Apache Flink, and Apache Kafka Streams.
SQS integrates seamlessly with other AWS services, allowing you to send notifications to various endpoints, including AWS Lambda functions, SQS queues, and HTTP/HTTPS endpoints.
Kafka primarily uses command-line interface tools like kafka-topics for managing topics and other administrative tasks. It lacks a dedicated built-in user interface, but third-party tools such as Kafka Manager, Kafka Tool, and Confluent Control Center offer web-based interfaces for managing Kafka clusters.
SQS, as a fully managed service, integrates seamlessly with the AWS Management Console. This web-based interface allows users to easily create, configure, and monitor SQS queues without needing additional tools.
Kafka offers client libraries for various languages, such as Java, Python, and Go. Its syntax can be complex due to concepts like topics, partitions, offsets, and consumer groups.
SQS provides SDKs for multiple languages, including Java, Python, and Node.js. Its syntax is simpler and focuses on sending and receiving messages to and from queues. SQS syntax is more straightforward, while Kafka's syntax is more complex due to its distributed nature and advanced features.
Kafka pricing varies depending on the deployment model (self-managed or managed services like Confluent Cloud or Amazon MSK).
SQS follows a pay-as-you-go pricing model based on the number of requests and data transfers.
After reviewing similarities and differences, here’s a detailed comparison between Apache Kafka and Amazon SQS, focusing on which one is the winner for each category, depending on the case.
Kafka is a distributed, pub-sub messaging system that operates on a distributed log architecture, where messages are preserved in a distributed commit log.
On the other hand, SQS stands as a fully managed, pull-based messaging system that relies on a message broker architecture, with a central service orchestrating the queue management.
Kafka's distributed architecture makes it more scalable and fault-tolerant, while SQS's centralized architecture simplifies management but can become a bottleneck.
Kafka and Amazon SQS both offer high scalability. Kafka is known for its high-throughput, fault-tolerant, and horizontally scalable streaming capabilities. It can handle large data volumes and has extended data retention periods.
Amazon SQS is celebrated for its ability to handle millions of messages per second and automatic scaling in response to varying traffic.
Kafka is more scalable for handling large volumes of data and providing longer retention periods, while SQS is easier to scale automatically for smaller workloads.
Kafka is designed to ensure data persistence through its replicated log system. It offers flexibility by allowing the configuration of both the retention period and the disk space used for data storage.
On the other hand, SQS ensures message persistence by storing messages across multiple data centers, enhancing the system's durability. It comes with a default retention period of 4 days, which can be adjusted up to a maximum of 14 days based on the user's requirements.
Both platforms offer message persistence, but Kafka provides more flexibility in configuring retention periods and storage.
Apache Kafka and Amazon SQS both offer robust messaging capabilities with guaranteed delivery. Kafka ensures “at-least-once” message delivery and can achieve “exactly-once” semantics through mechanisms like idempotent message writes and transactional support.
On the other hand, SQS also ensures "at-least-once” message delivery and provides “exactly-once” delivery semantics through its deduplication mechanisms.
Both platforms offer similar message delivery guarantees, with Kafka providing more advanced features like idempotent writes and transactions.
One key difference between Kafka and SQS is how they handle message consumption.
Kafka uses consumer groups for independent reading from different partitions, enabling load balancing and fault tolerance. SQS lacks built-in support for consumer groups, so separate queues are needed for each consumer to achieve similar functionality.
This shows the varied approaches Kafka and SQS take toward managing consumer interactions with messages.
Kafka's support for consumer groups makes it more suitable for scenarios involving multiple consumers and load balancing.
Kafka boasts a broader integration ecosystem and offers connectors for various data systems and frameworks. On the other hand, SQS is tightly integrated with other AWS services, making it easy to incorporate into any AWS-based architecture.
SQS is the winner for AWS-based architectures, while Kafka offers more flexibility for integrating with non-AWS systems and frameworks.
When comparing Kafka and SQS, it's clear they cater to different needs. Kafka demands a bit more in terms of setup and configuration, presenting a steeper learning curve, particularly when delving into distributed systems concepts.
On the other hand, SQS stands out for its simplicity. As a fully managed service, it requires minimal setup and configuration, making it a more accessible choice for straightforward use cases.
SQS is easier to use and get started with, while Kafka requires more expertise in distributed systems and configuration.
Kafka, an open-source platform, needs investment in infrastructure and management, yet it can be more cost-effective for handling large-scale workloads. On the other hand, SQS offers a fully managed service with a pay-as-you-go pricing model, making it potentially more economical for smaller workloads.
SQS is generally more cost-effective for smaller workloads, while Kafka can be more cost-effective for large-scale workloads, depending on infrastructure and management costs.
To understand Kafka, delve into distributed systems and stream processing. It's rich with concepts like topics, partitions, offsets, and consumer groups. On the other hand, SQS has a user-friendly API, making it simple to send and receive messages from queues with SDKs across multiple programming languages.
SQS is the winner in terms of syntax difficulty. It offers a more straightforward and user-friendly API, making it easier to integrate into applications. Kafka's syntax can be more complex due to its distributed nature and advanced streaming features.
|
Kafka |
SQS |
|
Distributed, pub-sub |
Centralized, pull-based |
|
Highly scalable for large volumes |
Highly scalable for smaller volumes |
|
Configurable retention periods |
Limited retention periods |
|
At-least-once, exactly-once with transactions |
At-least-once, exactly-once with deduplication |
|
Supported |
Not supported |
|
Broad ecosystem, connectors |
Tight AWS integration |
|
Steeper learning curve |
Fully managed, easier to start |
|
Open-source, infrastructure costs |
Pay-as-you-go |
|
Longer |
14 days |
|
Multiple |
Limited |
|
More complex |
Simple and straightforward |
In conclusion, if you need a quick-to-deploy, managed service that integrates well within the AWS ecosystem, AWS SQS is your best bet. It simplifies queue management and scales effortlessly, making it ideal for many standard applications.
Alternatively, if your project demands high throughput, low latency, and the ability to fine-tune your system, Apache Kafka offers flexibility for real-time data streaming and processing.
Choosing the right tool will depend on your project's specific needs, including factors like ease of use, performance, scalability, and integration. Both Kafka and SQS have their strengths, and understanding these will help you leverage the best platform for your next data-driven project!
To continue learning about these topics, check out these resources:
Learn more about stream data infrastructure and management with these courses!
Course
Course
Course
blog
Kurtis Pykes
15 min
blog
Aashish Nair
15 min
blog
Maria Eugenia Inzaugarat
8 min
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Gus Frazer
