
Corso
Introduzione ai database in Python
4 h
101.2K
Questo articolo ti guiderà attraverso SQLAlchemy, un toolkit SQL per Python che semplifica attività come interrogare, creare e gestire database.
Dopo aver letto questo tutorial, ti invito a iscriverti al nostro corso Introduction to Databases in Python per fare ancora più pratica. Tra i punti salienti: progetti pratici che ti guidano nel filtrare e raggruppare i dati, query avanzate con SQLAlchemy e come interrogare, creare e scrivere nei principali database, tra cui SQLite, MySQL e PostgreSQL.

SQLAlchemy è il toolkit SQL per Python che permette agli sviluppatori di accedere e gestire database SQL usando un linguaggio di dominio “pythonico”. Puoi scrivere una query sotto forma di stringa oppure concatenare oggetti Python per ottenere query simili. Lavorare con gli oggetti offre flessibilità agli sviluppatori e consente di creare applicazioni ad alte prestazioni basate su SQL.
In parole semplici, ti permette di connetterti ai database usando il linguaggio Python, eseguire query SQL tramite programmazione orientata agli oggetti e semplificare il flusso di lavoro.
Installare il pacchetto e iniziare a scrivere codice è piuttosto semplice.
Puoi installare SQLAlchemy usando il Python Package Manager (pip):
pip install sqlalchemySe invece usi la distribuzione Anaconda di Python, prova a inserire il comando nel terminale di conda:
conda install -c anaconda sqlalchemyVediamo se il pacchetto è stato installato correttamente:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Ottimo, abbiamo installato con successo SQLAlchemy versione 1.4.41.
In questa sezione impareremo a connettere database SQLite, creare oggetti tabella e usarli per eseguire query SQL.
Useremo il database SQLite di European Football da Kaggle, che contiene due tabelle: divisions e matchs.
Per prima cosa creeremo oggetti motore SQLite usando create_object e passeremo l'indirizzo del percorso del database. Poi creeremo un oggetto connessione collegando il motore. Useremo l'oggetto conn per eseguire tutti i tipi di query SQL.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Se vuoi connetterti a database PostgreSQL, MySQL, Oracle e Microsoft SQL Server, consulta la configurazione dell'engine per una connettività fluida al server.
Questo tutorial su SQLAlchemy presuppone che tu conosca le basi di Python e SQL. In caso contrario, nessun problema. Puoi seguire i percorsi di competenze SQL Fundamentals e Python Fundamentals per costruire solide fondamenta.
Per creare un oggetto tabella, dobbiamo fornire nomi delle tabelle e metadati. Puoi generare i metadati usando la funzione MetaData() di SQLAlchemy.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectStampiamo i metadati di divisions.
print(repr(metadata.tables['divisions']))I metadati contengono il nome della tabella, i nomi delle colonne con il tipo e lo schema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Usiamo l'oggetto tabella division per stampare i nomi delle colonne.
print(division.columns.keys())La tabella è composta dalle colonne division, name e country.
['division', 'name', 'country']Ora arriva la parte divertente. Useremo l'oggetto tabella per eseguire la query ed estrarre i risultati.
Nel codice seguente stiamo selezionando tutte le colonne della tabella division.
query = division.select() #SELECT * FROM divisions
print(query)Nota: puoi anche scrivere il comando select come db.select([division]).
Per vedere la query, stampa l'oggetto query e verrà mostrato il comando SQL.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsOra eseguiremo la query usando l'oggetto connessione ed estrarremo le prime cinque righe.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)Il risultato mostra le prime cinque righe della tabella.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]In questa sezione vedremo vari esempi di SQLAlchemy per creare tabelle, inserire valori, eseguire query SQL, fare analisi dei dati e gestire le tabelle.
Puoi seguire passo passo oppure consultare questo workbook di DataLab. Contiene un database, il codice sorgente e i risultati.
Per prima cosa creeremo un nuovo database chiamato datacamp.sqlite. La funzione create_engine crea automaticamente un nuovo database se non ne esiste già uno con lo stesso nome. Quindi creare e connettere sono operazioni piuttosto simili.
Dopodiché connetteremo il database e creeremo un oggetto metadati.
Useremo la funzione Table di SQLAlchemy per creare una tabella chiamata “Student”.
È composta dalle colonne:
Abbiamo creato la struttura della tabella. Aggiungiamola al database usando `metadata.create_all(engine)`.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Per aggiungere una singola riga, useremo prima insert aggiungendo l'oggetto tabella. Poi, useremo values e inseriremo manualmente i valori nelle colonne. Funziona in modo analogo all'aggiunta di argomenti alle funzioni Python.
Infine, eseguiremo la query usando la connessione per eseguire la funzione.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Verifichiamo di aver aggiunto la riga alla tabella Student eseguendo una select e recuperando tutte le righe.
output = conn.execute(Student.select()).fetchall()
print(output)Abbiamo aggiunto correttamente i valori.
[(1, 'Matthew', 'English', True)]Aggiungere i valori uno per uno non è un modo pratico per popolare il database. Aggiungiamo più valori usando le liste.
Crea una query di inserimento per la tabella Student.
Crea un elenco di più righe con nomi di colonne e valori.
Esegui la query con un secondo argomento come values_list.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Per convalidare i risultati, esegui la semplice query select.
output = conn.execute(db.select([Student])).fetchall()
print(output)Ora la tabella contiene più righe.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]Invece di usare oggetti Python, possiamo anche eseguire query SQL usando una stringa.
Basta aggiungere l'argomento come stringa alla funzione execute() e visualizzare il risultato con fetchall().
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Output:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Puoi anche passare query SQL più complesse. Nel nostro caso stiamo selezionando le colonne Name e Major dove gli studenti hanno superato l'esame.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Output:
[('Matthew', 'English'), ('Natasha', 'Math')]Nelle sezioni precedenti abbiamo usato API/Oggetti SQLAlchemy semplici. Vediamo ora query più complesse e multi-step.
Nell'esempio seguente selezioneremo tutte le colonne in cui il major dello studente è English.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Output:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Applichiamo la logica AND alla query WHERE.
Nel nostro caso, cerchiamo studenti con major in English che hanno fallito.
Nota: diverso da ‘!=’ True è False.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Solo Ben ha fallito l'esame con major in English.
[(4, 'Ben', 'English', False)]Usando una tabella simile, possiamo eseguire tutti i tipi di comandi, come mostrato nella tabella qui sotto.
Puoi copiare e incollare questi comandi per testare i risultati in autonomia. Dai un'occhiata al workbook di DataLab se ti blocchi su uno qualsiasi dei comandi indicati.
|
Comandi |
API |
|
in |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
and, or, not |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
order by |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limit |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
group by |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distinct |
db.select([Student.columns.Major.distinct()]) |
Per conoscere altre funzioni e comandi, consulta la documentazione ufficiale di SQL Statements and Expressions API.
Data scientist e analyst apprezzano i dataframe di pandas e adorano lavorarci. In questa parte impareremo a convertire un risultato di query SQLAlchemy in un dataframe pandas.
Per prima cosa, esegui la query e salva i risultati.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Poi usa la funzione DataFrame() e fornisci i risultati SQL come argomento. Infine, aggiungi i nomi delle colonne usando la prima riga del risultato results[0] e .keys().
Nota: puoi fornire qualsiasi riga valida per estrarre i nomi delle colonne usando keys().
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
In questa parte, connetteremo il database European football, eseguiremo query complesse e visualizzeremo i risultati.
Come al solito, connetteremo il database usando le funzioni create_engine() e connect().
Nel nostro caso, effettueremo un join tra due tabelle, quindi dobbiamo creare due oggetti tabella: division e match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Puoi anche creare query più complesse aggiungendo ulteriori moduli.
Nota: per eseguire l'auto-join di due tabelle puoi anche usare: db.select([division.columns.division,match.columns.Div]).
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data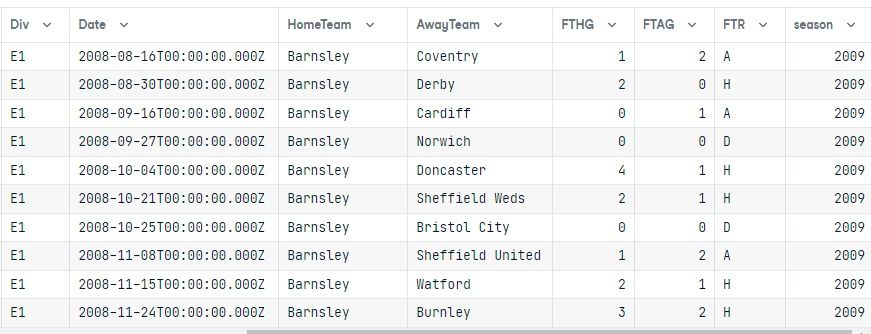
Dopo aver eseguito la query, abbiamo convertito il risultato in un dataframe pandas.
Le due tabelle sono unite e i risultati mostrano solo la division E1 per la stagione 2009 ordinate per la colonna HomeTeam.
Ora che abbiamo un dataframe, possiamo visualizzare i risultati sotto forma di grafico a barre usando Seaborn.
Faremo:
Lo scopo principale di questa parte è mostrarti come puoi usare l'output della query SQL per creare visualizzazioni dei dati efficaci.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)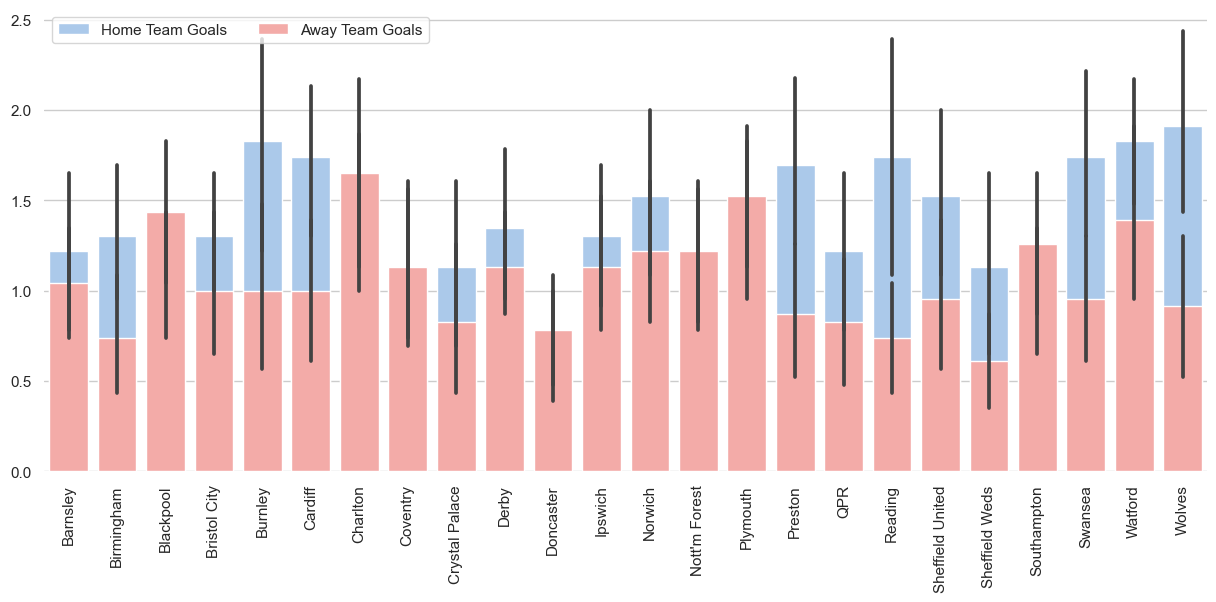
Dopo aver convertito il risultato della query in un dataframe pandas, puoi semplicemente usare la funzione .to_csv() con il nome del file.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Evita di aggiungere una colonna chiamata “Index” usando `index=False`.
data.to_csv("SQl_result.csv",index=False)In questa parte, convertiremo il file CSV di Stock Exchange Data in una tabella SQL.
Per prima cosa, connettiti al database sqlite di datacamp.
engine = create_engine("sqlite:///datacamp.sqlite")Poi importa il file CSV usando la funzione read_csv(). Infine, usa la funzione to_sql() per salvare il dataframe pandas come tabella SQL.
Principalmente, la funzione to_sql() richiede come argomenti la connessione e il nome della tabella. Puoi anche usare if_exisits per sostituire una tabella esistente con lo stesso nome e index per eliminare la colonna dell'indice.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Per convalidare i risultati, dobbiamo connettere il database e creare un oggetto tabella.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Poi esegui la query e mostra i risultati.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Come puoi vedere, abbiamo trasferito con successo tutti i valori dal file CSV alla tabella SQL.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)Aggiornare i valori è semplice. Useremo le funzioni update, values e where per aggiornare un valore specifico nella tabella.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)Nel nostro caso, abbiamo cambiato il valore di Pass da False a True dove il nome della studentessa è Nisha.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Per convalidare i risultati, eseguiamo una semplice query e mostriamo i risultati sotto forma di dataframe pandas.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataAbbiamo cambiato correttamente il valore Pass in True per la studentessa di nome Nisha.
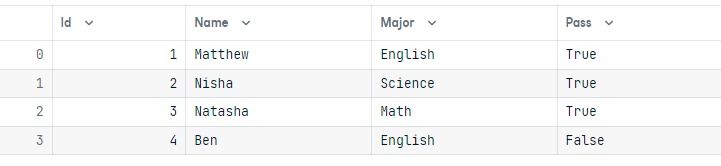
Eliminare le righe è simile ad aggiornare. Richiede le funzioni delete() e where().
table.delete().where(table.columns.column_1 == 6)Nel nostro caso, stiamo eliminando il record dello studente di nome Ben.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Per convalidare i risultati, eseguiremo rapidamente una query e mostreremo i risultati sotto forma di dataframe. Come puoi vedere, abbiamo eliminato la riga contenente lo studente di nome Ben.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Se usi SQLite, eliminare la tabella genererà un errore database is locked. Perché? Perché SQLite è una versione molto leggera. Può eseguire una sola funzione alla volta. Al momento sta eseguendo una query select. Dobbiamo chiudere l'intera esecuzione prima di eliminare la tabella.
results.close()
exe.close()Dopodiché, usa la funzione drop_all() dei metadati e seleziona un oggetto tabella per eliminare la singola tabella. Puoi anche usare il comando Student.drop(engine) per eliminare una singola tabella.
metadata.drop_all(engine, [Student], checkfirst=True)Se non specifichi alcuna tabella per la funzione drop_all(), verranno eliminate tutte le tabelle nel database.
metadata.drop_all(engine)Il tutorial su SQLAlchemy copre varie funzioni di SQLAlchemy, dalla connessione al database fino alla modifica delle tabelle, e se vuoi saperne di più prova a completare il corso interattivo Introduction to Databases in Python. Imparerai le basi dei database relazionali, il filtraggio, l'ordinamento e il raggruppamento. Inoltre, esplorerai funzioni avanzate di SQLAlchemy per la manipolazione dei dati.
Se riscontri problemi nel seguire il tutorial, vai al workbook di DataLab e confronta il tuo codice. Puoi anche farne una copia ed eseguirla direttamente in DataLab.
Corsi di Python & SQL
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

