
Courses
Đạo đức AI
1 giờ
127.1K
Cuộc đua AI trong tháng 2/2026 diễn ra gay gắt bất thường. Sau khi Anthropic phát hành Claude Opus 4.6 và Claude Sonnet 4.6 chỉ cách nhau hai tuần, Google đáp trả bằng Gemini 3.1 Pro.
Google cho biết đây là một bản phát hành đáng kể, chủ yếu vì Gemini 3.1 Pro đã hơn gấp đôi hiệu năng suy luận so với Gemini 3 Pro, theo đánh giá của bài kiểm tra ARC-AGI-2, nơi nó đạt điểm xác minh 77,1%
ARC-AGI-2 quan trọng vì nó kiểm tra khả năng nhận diện mẫu mới thay vì kiến thức ghi nhớ. Bài kiểm tra được thiết kế để các model không thể đơn giản "luyện" theo cách truyền thống để đạt điểm cao. Vì vậy, việc điểm số tăng gấp đôi trên bài này có ý nghĩa hơn nhiều so với, chẳng hạn, MMLU. Chúng ta sẽ đi sâu hơn về tầm quan trọng của kết quả này ở phần sau, và thậm chí tự thử nghiệm.
Để tìm hiểu thêm về hệ sinh thái AI của Google, tôi khuyến nghị xem các hướng dẫn về NotebookLM và Nano Banana 2, cũng như hướng dẫn về Gemini CLI. Ngoài ra, hãy xem hướng dẫn của chúng tôi về một đối thủ rất mạnh của Gemini, GPT-5.4 của OpenAI.
Chúng tôi cập nhật cho độc giả những tin tức mới nhất về AI qua The Median, bản tin miễn phí vào thứ Sáu hằng tuần, tóm lược các câu chuyện chính trong tuần. Đăng ký để nắm bắt nhanh chỉ trong vài phút mỗi tuần:
Gemini 3.1 Pro là model chủ lực mới nhất của Google, phát hành bản xem trước vào ngày 19/02/2026. Đây là lần đầu Google dùng bước nhảy phiên bản ".1" (mọi bản cập nhật giữa chu kỳ trước đó đều dùng ".5"), báo hiệu một nâng cấp tập trung vào trí tuệ thay vì mở rộng tính năng diện rộng. Điều này hợp lý vì Gemini 3 vốn đã là một bản phát hành toàn diện với kiến trúc đa phương thức mới.
Bài đăng ra mắt của Google giải thích rằng năng lực trí tuệ đứng sau những đột phá khoa học gần đây của Deep Think, bao gồm bác bỏ một giả thuyết toán học tồn tại hàng thập kỷ, nay đã được chắt lọc vào 3.1 Pro để sử dụng hằng ngày.
Deep Think về mặt kỹ thuật đã có trước đó, nhưng chỉ nếu bạn có gói Ultra. Google muốn bạn tin rằng mục tiêu luôn là đưa năng lực suy luận này vào sử dụng hằng ngày ở quy mô lớn, nhưng chỉ đến bản phát hành Gemini 3.1 này thì có vẻ họ mới thực sự làm được. Có lẽ Google phát hiện ra mức 249 USD/tháng cho gói Ultra vượt quá sẵn sàng chi trả của đa số người dùng.
Dưới đây là các cải tiến chính trong lần phát hành này:
Như tôi đã đề cập ở phần mở đầu, thay đổi lớn nằm ở suy luận trừu tượng và đa bước. Hiệu năng của Gemini 3.1 trên ARC-AGI-2 đã hơn gấp đôi so với Gemini 3 Pro chỉ trong khoảng ba tháng.
Ngoài các cải thiện trên ARC-AGI-2, model còn đạt điểm cao nhất từng ghi nhận trên GPQA Diamond, một bài đo dành cho kiến thức khoa học bậc cao học.
Gemini 3.1 Pro luôn sử dụng "tư duy động": tự động áp dụng suy luận chuỗi tư duy dựa trên độ phức tạp của tác vụ.
API đã giới thiệu tham số thinking_level mới với bốn thiết lập: low, medium (mới trong 3.1), high và max, giúp nhà phát triển cân bằng giữa tốc độ và chiều sâu.
Một xu hướng rõ ràng trong lần phát hành này là các điểm chuẩn liên quan đến agent tăng mạnh. Model nay đạt điểm cao hơn nhiều ở nghiên cứu web tự động, tác vụ đa bước dài hạn và lập trình trên terminal so với phiên bản tiền nhiệm.
Với những ai xây dựng quy trình mà model vận hành với giám sát tối thiểu (gỡ lỗi, nghiên cứu web, thu thập dữ liệu), các cải thiện này có ý nghĩa thực tế.
Hiệu năng agent tăng xấp xỉ gấp đôi so với Gemini 3 Pro trong một số hạng mục, và hiện dẫn trước GPT-5.2 và Claude ở phần lớn các điểm chuẩn này.
Điểm này thu hút sự chú ý của tôi. Google nhấn mạnh rằng Gemini 3.1 Pro có thể tạo SVG động và bảng điều khiển tương tác hoàn toàn bằng mã. Vì đây là các định nghĩa toán học chứ không phải hình ảnh đã render, chúng có thể phóng to mà không giảm chất lượng và nhẹ hơn rất nhiều so với tệp video.
Các ví dụ khi ra mắt khá ấn tượng: một website portfolio dựa trên chủ đề của Wuthering Heights, một bảng điều khiển hàng không vũ trụ trực tiếp lấy dữ liệu đo đạc của ISS, và một bầy sáo đá 3D bay lượn với theo dõi chuyển động tay và nhạc nền sinh thành.
Đây là đầu ra dạng mã, không phải hình ảnh, nghĩa là có thể chỉnh sửa, nhúng và rất nhẹ.
Điểm này ít hào nhoáng hơn nhưng có lẽ liên quan trực tiếp hơn với bất kỳ ai từng dùng Gemini 3 Pro trong sản xuất. Một phàn nàn thường gặp với phiên bản trước là nó hay cắt ngang phản hồi dài khi đang sinh.
Phản hồi của người dùng sau khi ra mắt cho thấy 3.1 Pro đã khắc phục vấn đề này. Có người cho biết đã tạo một phản hồi cực lớn trong một lần chạy mà không hề bị cắt cụt.
JetBrains cũng xác nhận cải thiện chất lượng thực sự với model mới, lưu ý rằng nó cho ra "kết quả đáng tin cậy hơn" với "ít token đầu ra" hơn. Mức hiệu quả đó, cộng thêm việc không bị cắt cụt, tạo khác biệt rõ rệt cho sinh nội dung dài.
Google cho thấy Gemini 3.1 Pro dẫn đầu ở 13/16 trong số những bài kiểm tra điểm chuẩn quan trọng nhất, bao gồm các bài liên quan đến suy luận trừu tượng, tác vụ agent và khoa học bậc cao học. (Gemini 3 Pro vốn đã dẫn trước ở một vài điểm chuẩn này.)
Dưới đây là cách model mới nhất so kè với các bản phát hành lớn khác của tháng 2/2026.
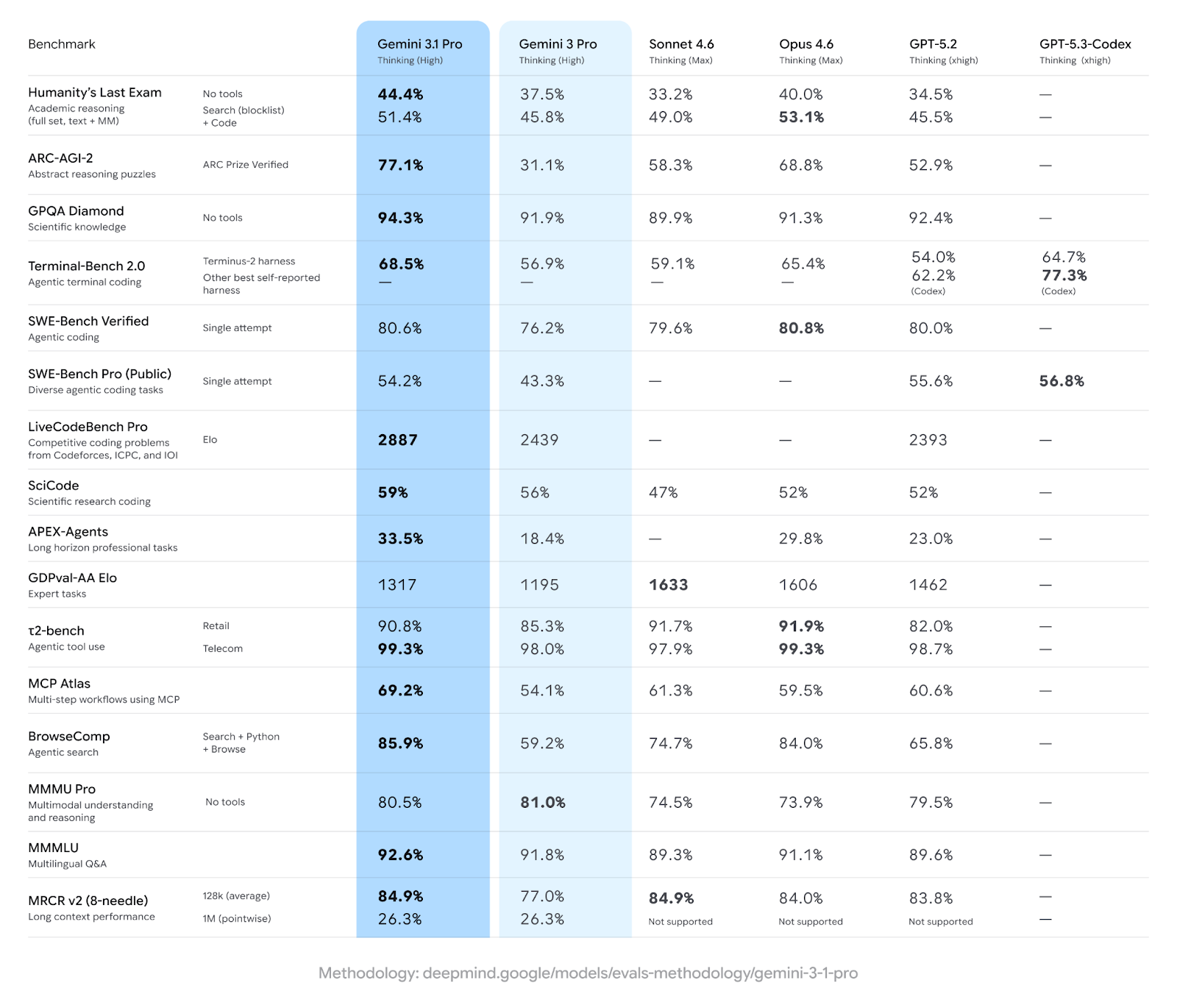
Như bạn thấy, và như tôi đã đề cập, kết quả về suy luận trừu tượng là nổi bật nhất. Gemini 3.1 Pro dẫn trước rõ rệt so với Opus 4.6, trong khi Opus 4.6 lại dẫn trước đáng kể so với GPT-5.2. Điều này thể hiện sự dịch chuyển thực sự so với vị thế của các model hàng đầu chỉ một năm trước.
Tôi muốn nói thẳng điều này vì rất dễ bị cuốn theo những con số lớn. Các model Claude thực sự dẫn đầu ở một số mảng quan trọng:
Bức tranh trung thực: Gemini 3.1 Pro hiện là model tốt nhất cho suy luận trừu tượng, kiến thức khoa học và độ bao phủ đa phương thức. Các model Claude vẫn đi trước ở mảng công việc tri thức, điều phối công cụ và vận hành phần mềm qua giao diện đồ họa.
Để xem các cải tiến này chuyển hóa thế nào sang suy luận thực tế, tôi chạy ba bài thử nhằm thăm dò các khía cạnh khác nhau của tư duy trừu tượng:
Để xem Gemini 3.1 Pro xử lý kiểu suy luận ARC-AGI-2 ra sao, chúng tôi dùng một câu đố suy ra quy tắc đơn giản. Model phải suy ra cả quy tắc màu và quy tắc hình từ ví dụ, mà không được cho biết luật tường minh.
Đây là prompt của tôi:
You are shown these transformations:
- [Red Circle] → [Blue Triangle]
- [Blue Square] → [Red Circle]
- [Red Square] → [Blue Circle]
- [Blue Triangle] → ?Gemini 3.1 Pro trả về mã SVG sạch với hoạt ảnh CSS. Đầu ra là bộ tải ba chấm hoạt hình với nhịp nảy so le, đúng như yêu cầu. Render chuẩn ngay lần đầu trong trình duyệt, không cần chỉnh sửa. Kích thước tệp rất nhỏ, và vì là đồ họa vector dựa trên mã nên phóng to sắc nét ở mọi kích thước.
Đây là một trong những tính năng nghe có vẻ màu mè trên thông cáo báo chí nhưng thực tế lại rất hữu dụng. Đồ họa động nhẹ, có thể nhúng, phóng to vô hạn từ prompt văn bản là công cụ vững chắc cho dựng mẫu frontend hoặc tạo nhanh asset trực quan.
Gemini 3.1 Pro hiện ở giai đoạn xem trước. Google cho biết sẽ sớm ra mắt chính thức sau khi tiếp thu phản hồi và cải thiện thêm các quy trình agent.
Dưới đây là các cách truy cập chính:
Gemini CLI là một agent dòng lệnh mã nguồn mở cho phép model truy cập trực tiếp vào môi trường cục bộ của bạn. Cài đặt bằng đoạn mã sau:
npm install -g @google/gemini-cli
# Or run directly: npx @google/gemini-cliCLI dùng vòng lặp ReAct, nghĩa là có thể viết mã, chạy, đọc lỗi, sửa và tự lặp. Với hiệu năng lập trình terminal được cải thiện của 3.1 Pro, vòng lặp này đáng tin cậy hơn thấy rõ. Gói miễn phí cho phép 60 yêu cầu mỗi phút và 1.000 yêu cầu mỗi ngày.
Gemini API cung cấp quyền truy cập lập trình trực tiếp vào Gemini 3.1 Pro.
ID model bạn cần là: gemini-3.1-pro-preview
Đây là một chút mã Python để bạn bắt đầu:
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="Your prompt here"
)
print(response.text)Mức giá giống với Gemini 3 Pro Preview.
|
Kích thước ngữ cảnh |
Đầu vào (mỗi 1M token) |
Đầu ra (mỗi 1M token) |
|
≤200K token |
$2.00 |
$12.00 |
|
>200K token |
$4.00 |
$18.00 |
Tham số thinking_level chấp nhận low, medium, high hoặc max. Các công cụ hỗ trợ gồm Google Search, ngữ cảnh URL, thực thi mã và tìm kiếm tệp. Tôi sẽ nói về chi tiết cửa sổ ngữ cảnh ở phần so sánh bên dưới.
NotebookLM hiện chạy bằng Gemini 3.1 Pro cho người đăng ký Google AI Pro và Ultra. NotebookLM phản hồi chỉ dựa trên tài liệu bạn tải lên, khiến nó trở thành công cụ nghiên cứu rất hữu ích khi bạn muốn model bám sát vào tài liệu cụ thể.
Google đã bắt đầu triển khai Gemini 3.1 Pro trên các sản phẩm người dùng và nhà phát triển, nhưng chưa công bố một bảng quy đổi đơn giản kiểu "gói X = model Y". Thực tế, bạn sẽ thấy 3.1 Pro trong ứng dụng Gemini và API khi nó được triển khai, với AI Ultra cung cấp quyền truy cập rộng nhất.
|
Gói |
Giá theo tháng (Mỹ) |
Những gì bạn nhận được liên quan đến Gemini |
|
Miễn phí |
$0 |
Gemini 3 Flash trong ứng dụng Gemini, tính năng giới hạn |
|
Google AI Pro |
$19.99 |
Hạn mức cao hơn và truy cập model Gemini Pro trong ứng dụng Gemini |
|
Google AI Ultra |
$249.99 (thường giảm còn $124.99 trong 3 tháng đầu) |
Hạn mức cao nhất, chế độ Deep Think và quyền truy cập các tính năng AI mới nhất của Google trên nhiều sản phẩm |
Các bản phát hành tháng 2/2026 từ Google và Anthropic tạo ra một tập hợp đánh đổi rất thú vị. Không có trường hợp model nào thắng tuyệt đối. Lựa chọn đúng phụ thuộc rất nhiều vào thứ bạn đang xây dựng.
Khoảng cách giá đáng để cân nhắc. Gemini 3.1 Pro rẻ hơn nhiều cả ở đầu vào và đầu ra so với Claude Opus 4.6. Nếu bạn chạy API khối lượng lớn, đây không phải là chênh lệch nhỏ.
Dựa trên điểm chuẩn và thử nghiệm thực tế, đây là những lĩnh vực Gemini 3.1 Pro đặc biệt phù hợp:
Gemini 3.1 Pro là ví dụ điển hình cho hướng phát triển của các model này. Ít tập trung vào kiểu đầu vào mới, chú trọng hơn vào suy luận tốt hơn, agent đáng tin cậy hơn và xử lý ngữ cảnh dài hơn. Dù chỉ là bản ".1", các cải thiện điểm chuẩn và mối liên hệ với Deep Think khiến nó mang cảm giác như bước tiến lớn về cách các hệ thống này tư duy.
Với các đội ngũ xây sản phẩm thực, không có model "tốt nhất" duy nhất. Gemini 3.1 Pro hoạt động tốt cho suy luận khoa học, agent nghiên cứu và phân tích codebase lớn, đặc biệt khi xét đến giá và hỗ trợ video. Claude vẫn tốt hơn cho công việc tri thức và sử dụng máy tính qua màn hình, còn GPT-5.3-Codex vẫn thắng ở một số bài kiểm tra lập trình.
Câu hỏi thú vị là chuyện gì sẽ xảy ra khi nó rời giai đoạn xem trước. Google cho biết họ đang làm việc trên các cải tiến về agent trước khi phát hành chính thức. Nếu những điều đó ra mắt song hành với các nâng cấp suy luận hiện tại, khoảng cách giữa các model nghiên cứu như Deep Think và model dùng hằng ngày sẽ nhỏ lại. Còn hiện tại, đây là thời điểm tốt để thử nhiều model và xây hệ thống có thể tận dụng điểm mạnh của từng cái.
Để bắt đầu với các công cụ AI của Google, hãy xem khóa học Nhập môn Google Gemini của chúng tôi. Để làm việc với API bằng Python, hướng dẫn Làm việc với Gemini API bao quát những điều thiết yếu.
Học cùng DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút