
Track
AI Fundamentals
10 hr
I was introduced to video generation models when OpenAI launched the first iteration of Sora. From that moment, I began to encounter many top-of-the-line video generation models. This inspired me to compile a list of the best models available. The rankings are based on my personal experience, the Artificial Analysis video generation leaderboard, and overall user feedback.
Video generation is similar to image generation, but with an additional constraint: time. Each frame must stay consistent with prior frames, preserving character identity, lighting, camera motion, and scene layout, to maintain temporal coherence.
Modern systems go beyond text-to-video: you can animate a single image in your own style, stitch shots into longer sequences, and even generate synchronized audio (music, SFX, dialogue) from prompts, producing end-to-end cinematic clips.
In this blog, we will explore some of the top-rated video generation models that are transforming the worlds of marketing, cinema, advertising, and content creation, opening new creative possibilities across industries.

Image by Author | Canva + Google Nano Banana
Video generation models are AI systems that create moving images from inputs such as text, images, or existing videos. They build upon text-to-image methods by incorporating the element of time. In addition to ensuring realism and adherence to prompts, these models must also maintain smooth motion, continuity of subjects, and coherence from frame to frame.
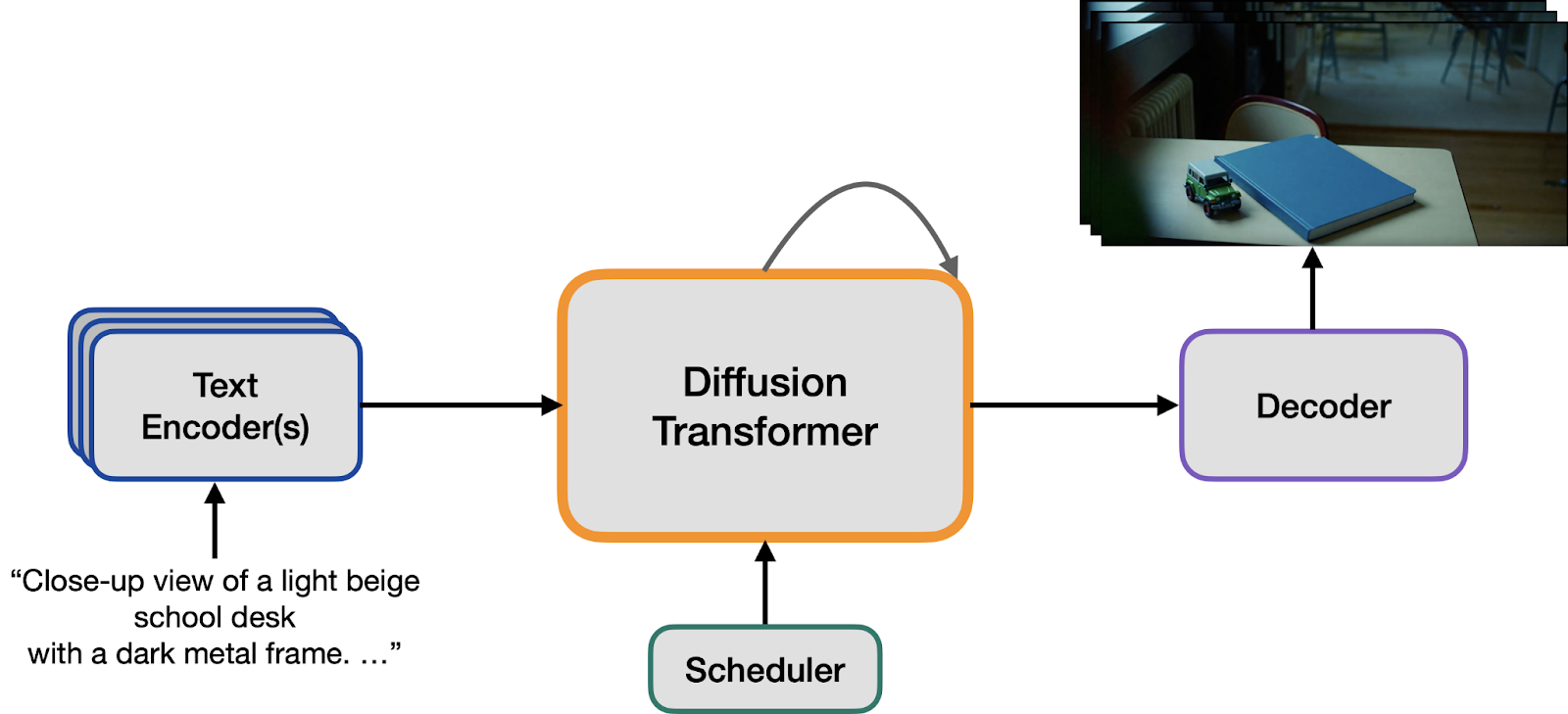
Image from State of open video generation models in Diffusers
A video generation model works by turning a text prompt into a structured representation using a text encoder, then starting from random noise and refining it step by step through a denoising network. A scheduler guides this process, while encoders and decoders move between pixel space and a compressed latent space for efficiency. Unlike image models, video models process 3D tokens that capture both spatial detail and temporal motion. Because decoding requires a lot of memory, many pipelines use frame-by-frame decoding to make generation more efficient.
Veo 3 is Google’s state-of-the-art video generation model, producing high-fidelity, 8-second clips at 720p or 1080p (16:9) with native, always-on audio at 24fps. Available via the Gemini API, it excels across dialogue-driven scenes, cinematic realism, and creative animation, capturing quoted dialogue, explicit sound effects, and ambient soundscapes directly from your prompt.
Top DataCamp Courses
Track
Track
Course
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Abid Ali Awan
7 min
blog
Hesam Sheikh Hassani
15 min
blog
Alex Olteanu
8 min
blog
Javier Canales Luna
9 min
blog
Abid Ali Awan
10 min


