

Cursus
Principes fondamentaux des agents IA
6 h
Si vous travaillez dans la data, vous gérez sans doute chaque jour de nombreuses tâches de codage répétitives : profiler de nouveaux jeux de données, construire des pipelines de données depuis zéro ou encore écrire manuellement des tests de transformation. C’est indispensable, mais cela consomme énormément de temps.
Et si votre terminal pouvait gérer et écrire tout ce code passe‑partout à votre place, pendant que vous concentrez votre énergie sur la réflexion et la prise de décision ? C’est précisément là qu’intervient le Codex‑CLI d’OpenAI. Il s’agit d’un agent de codage IA très performant, intégré directement à votre ligne de commande, et comme nous allons le voir, il est idéal pour fluidifier vos workflows data.
Dans ce tutoriel, nous verrons comment les analystes et scientifiques des données peuvent utiliser Codex‑CLI pour accélérer leurs tâches quotidiennes les plus courantes. Nous allons couvrir l’ensemble du processus, de l’analyse exploratoire des données initiale à la construction de pipelines de données complets, en passant par la génération de tests automatisés pour vos transformations, le tout directement depuis le terminal.
Pour aller plus loin sur la conception de systèmes d’agents IA, nous vous recommandons vivement de vous inscrire au parcours de compétences AI Agent Fundamentals, qui couvre l’essentiel à connaître.
Commençons par définir Codex CLI. Au cœur, Codex CLI est un agent de codage open source fonctionnant dans le terminal, développé par OpenAI.
Il est construit en Rust, ce qui le rend particulièrement rapide et efficace. Surtout, il s’exécute directement dans votre ligne de commande, ce qui lui permet de lire vos fichiers, d’éditer votre code et même d’exécuter des commandes localement sur votre machine.
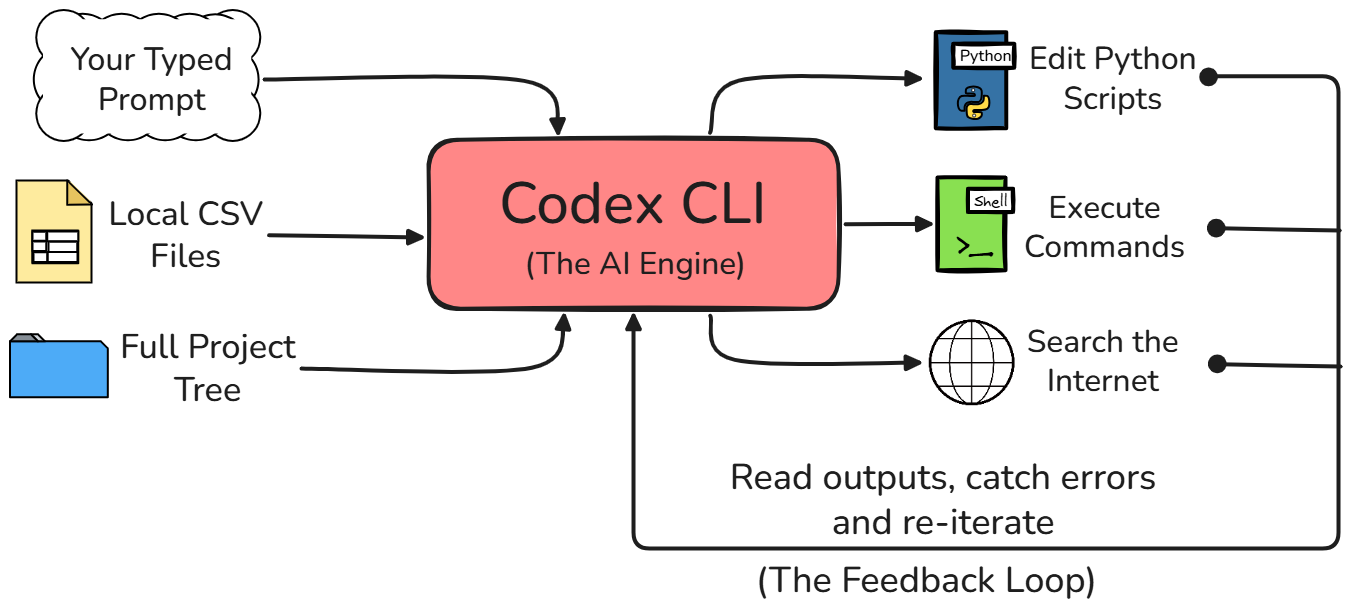
Vous avez peut‑être l’habitude d’utiliser l’interface web standard de ChatGPT pour votre travail, mais Codex CLI est très différent. Avec l’interface web, le modèle d’IA est complètement isolé de votre environnement de travail.
Avec Codex CLI, l’agent a un accès direct à votre système de fichiers local. Il peut exécuter des scripts Python, consulter la sortie ou les erreurs renvoyées, et il conserve une vision complète de la structure de votre projet sans que vous ayez à tout lui expliquer au préalable.
|
Étape du workflow / Fonctionnalité |
ChatGPT (navigateur web) |
Codex CLI (terminal) |
|
Accès aux données |
Vous devez ouvrir manuellement votre fichier CSV et copier‑coller quelques lignes de données brutes dans la conversation pour l’aider à comprendre. |
Il peut ouvrir et lire de manière autonome votre fichier CSV directement depuis votre système de fichiers local. |
|
Exécution du code |
Vous devez copier manuellement le script généré, le coller dans votre éditeur local, puis l’exécuter vous‑même. |
Il écrit automatiquement le script Python nécessaire, l’exécute et affiche la sortie finale directement dans le terminal. |
|
Expérience globale |
Beaucoup d’allers‑retours fastidieux, à copier‑coller entre des fenêtres. |
Tout se déroule dans un flux unique, continu et fluide, au sein du terminal. |
Bien sûr, comme l’agent Codex peut modifier directement vos fichiers et exécuter des commandes sur votre machine, il propose différents modes d’approbation pour que vous gardiez la main. Les trois modes sont :
Pour débuter, nous vous recommandons de commencer en lecture seule, puis de monter en puissance une fois le workflow maîtrisé.
Vous pouvez changer de mode d’approbation pendant une session Codex en cours avec /permissions. C’est le moyen le plus simple de passer de lecture seule à auto quand vous êtes à l’aise.
/permissionsSi vous souhaitez démarrer Codex dans un mode plus strict dès le début, vous pouvez définir les indicateurs de bac à sable et de politique d’approbation au lancement. Par exemple, cette commande démarre en mode lecture seule conservateur tout en vous sollicitant si nécessaire.
codex --sandbox read-only --ask-for-approval on-requestQuelques prérequis sont nécessaires pour suivre correctement ce tutoriel.
Commencez par installer Codex CLI sur votre machine. Ouvrez votre terminal et installez l’outil en global sur votre système avec la commande suivante :
npm install -g @openai/codexL’étape suivante consiste à authentifier votre compte, afin que l’outil sache qui vous êtes. Vous pouvez vérifier l’installation et lancer l’agent pour la première fois en tapant simplement codex dans votre terminal. Vous verrez quelque chose comme ceci :
Après avoir appuyé sur Entrée, une fenêtre de navigateur s’ouvre et vous invite à vous connecter via votre compte ChatGPT. Une fois connecté, vous êtes prêt à utiliser l’outil.
Si vous n’avez pas d’abonnement ChatGPT payant et préférez utiliser une clé d’API, l’option à l’usage est également disponible. Vous pouvez obtenir une clé depuis la console OpenAI.
Avant de demander à l’IA d’analyser des données, il est essentiel de configurer correctement votre environnement Python. Codex CLI s’exécute dans l’environnement en cours. Si l’agent doit écrire un script utilisant des bibliothèques data science comme pandas, scikit‑learn ou matplotlib, assurez‑vous qu’elles sont installées et disponibles.
Activez un environnement virtuel Python avant de lancer Codex. Voici un script d’initialisation avec les commandes à exécuter dans votre terminal pour créer un environnement virtuel, installer les packages nécessaires, l’activer, puis lancer l’agent :
python3 -m venv data_env
source data_env/bin/activate
pip install pandas scikit-learn matplotlib
codexUne autre étape importante consiste à créer un fichier nommé AGENTS.md dans le dossier principal de votre projet. Ce fichier contient des instructions persistantes que l’agent Codex lit automatiquement à chaque ouverture du projet. Il indique à l’IA comment se comporter et comment écrire du code pour cet espace de travail précis.
Pour les tâches data, nous voulons garantir un code propre, lisible et professionnel. Voici un exemple de fichier AGENTS.md spécialement conçu pour un projet de données. Créez ce fichier et collez‑y le texte suivant :
# Data Project Guidelines
When writing Python code for this project, please strictly follow these rules:
- Enforce PEP 8 formatting standards for all Python code.
- Always use highly descriptive variable names. Do not use generic, lazy names like df, data, x, or y. Instead, use specific names like transaction_data or revenue_series.
- Prefer pandas best practices, such as using vectorized operations instead of iterating through rows.
- Generate clear, descriptive docstrings for every single function.
- Always include Python type hints for function arguments and return values.Comme ce fichier est lu à chaque fois, indépendamment de la tâche, il est préférable de rester concis et de se concentrer sur des consignes valables pour tous les prompts. Pour des instructions plus spécifiques, utilisez plutôt des skills.
Passons au travail de fond : l’analyse exploratoire des données (EDA). Comme vous le savez, c’est presque toujours le point de départ de tout nouveau projet data. Avant de construire des modèles ou des pipelines, il faut comprendre la structure et la qualité de vos données.
Avec Codex CLI, un simple prompt en langage naturel peut produire pour vous un script EDA complet et opérationnel.
Le scénario : pour nos exemples, imaginons un jeu de données synthétique mais réaliste. Nous avons un dataset e‑commerce nommé transactions.csv dans notre dossier de projet, rempli de données métier comme des IDs de commande, des IDs utilisateur, des horodatages d’achat et des montants de transaction.
Lorsque vous recevez un nouveau fichier, la première étape consiste à le profiler pour en comprendre la structure de base. Plutôt que d’écrire vous‑même le code pandas standard, ouvrez votre terminal où tourne votre session Codex et saisissez un prompt comme celui‑ci :
Profile the transactions.csv file. Show shape, dtypes, missing values, and summary statistics.À l’exécution, Codex lit les premières lignes de votre fichier transactions.csv directement sur votre système local. Il génère ensuite un script Python complet pour réaliser le profilage et, en mode « suggest », vous demande s’il doit l’exécuter.
Vous voyez immédiatement la forme exacte des données, les types des colonnes e‑commerce et le nombre précis de valeurs manquantes à gérer (exemple ci‑dessous), sans écrire une seule ligne de code.
Les chiffres dans un terminal sont utiles, mais vous aurez besoin de visualiser les données. Vous pouvez générer des visualisations étonnamment complexes en décrivant simplement ce que vous voulez en anglais clair.
Par exemple, pour une vue d’ensemble de votre activité e‑commerce, vous pourriez demander à Codex :
Create a matplotlib dashboard with 3 subplots showing revenue by month, product categories ranked by sales, and order distribution by day of week.C’est une demande assez complexe. Codex analysera le prompt et votre fichier, regroupera les dates, agrégera le chiffre d’affaires, élaborera un plan pas à pas et le traduira en un script matplotlib robuste pour générer ces sous‑graphiques.
Point crucial avec ce type d’agent IA : le travail est fondamentalement itératif. Lorsque Codex propose une première version du code de visualisation, validez‑la pour voir le rendu.
Peut‑être que l’axe des x est illisible ou que les couleurs sont trop vives. Inutile d’ouvrir le script pour ajuster manuellement les paramètres matplotlib.
Répondez simplement par un prompt de suivi : « Les libellés en bas se chevauchent, faites une rotation de 45 degrés et adoucissez les couleurs de la légende. » Codex affinera le script, le relancera et vous fournira un tableau de bord amélioré.
Une fois l’exploration terminée, il faut passer des scripts ad hoc à du code reproductible et modulaire.
Concrètement, il s’agit souvent de mettre en place un pipeline ETL (Extract, Transform, Load). C’est la méthode standard pour ingérer, nettoyer et sauvegarder les résultats.
Pour illustrer, nous allons ingérer les transactions e‑commerce depuis le CSV, nettoyer les données, calculer quelques agrégations métier, puis enregistrer les résultats finaux dans un nouveau fichier propre.
Plutôt que d’écrire toute l’architecture vous‑même, utilisez Codex CLI pour échafauder l’ensemble à partir d’une description de haut niveau.
Première étape : mettre en place la structure du projet. Un bon pipeline sépare les composants dans des fichiers distincts, afin de rester lisible et maintenable. Demandez simplement à Codex de s’en charger. Dans votre terminal, entrez un prompt tel que :
Create a project layout for an ETL pipeline. I need separate Python modules for extraction, transformation, and loading, plus a main entry point script to run them all.Codex créera ces fichiers dans votre répertoire. Après approbation, votre arborescence ressemblera à :
etl_pipeline/
├──__init__.py
├── extract.py
├── transformation.py
└── loading.py
– run_etl.pyCette architecture sépare les responsabilités : la lecture des données est isolée de la logique métier et mathématique, comme tout bon data engineer le ferait.
Décrivons maintenant la transformation souhaitée. Dans un pipeline ETL, la transformation est souvent la partie la plus délicate, mais nous pouvons déléguer les détails à Codex. Supposons que nous devions traiter des valeurs manquantes et calculer le chiffre d’affaires par commande.
Tapez directement dans la CLI :
In transformation.py, write a function that takes the transactions data, drops any rows where the user ID is missing, and creates a new derived column called 'revenue' by multiplying the 'quantity' column by the 'unit_price' column.Comme Codex peut lire votre fichier transactions.csv, il connaît les vrais noms de colonnes. Il n’écrira pas df['qty'] * df['price'] au hasard : il verra que vos colonnes s’appellent quantity et unit_price, et écrira le code pandas exact pour que le script fonctionne.
Après génération du code, exécutez le pipeline de bout en bout pour vérifier qu’il fonctionne. Dites simplement à Codex, « Run the run_etl.py script. »
Lors de l’exécution, la sortie s’affiche dans le terminal et peut ressembler à ceci :
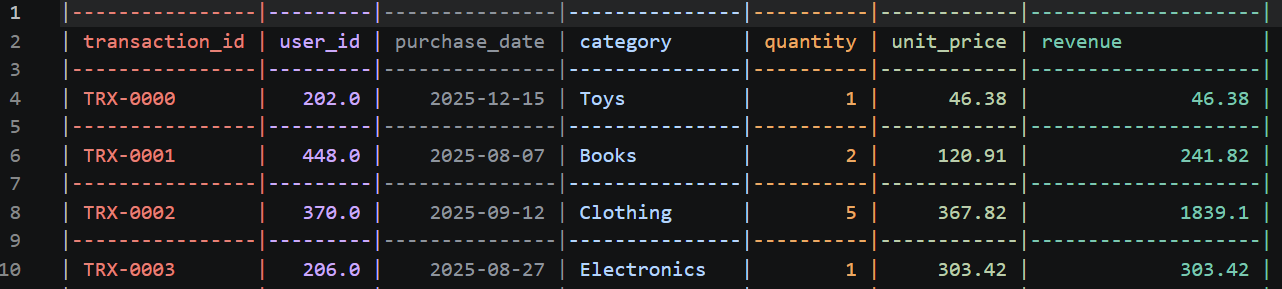
Le nouveau fichier processed_transactions.csv devrait ressembler à ceci :
Dans la vraie vie, des erreurs surviennent. Une chaîne de caractères peut se cacher dans une colonne numérique et provoquer un TypeError. Pas besoin de paniquer ni de copier‑coller l’erreur dans un navigateur : Codex CLI interceptera l’erreur, lira la traceback Python et proposera souvent une correction immédiate.
Cela illustre bien la boucle itérative avec un agent de codage IA :
C’est une collaboration continue, qui permet de produire un logiciel opérationnel bien plus vite qu’en tapant tout à la main.
Tester votre code est crucial pour éviter de casser la production, mais c’est souvent l’étape négligée.
Écrire des tests est fastidieux, surtout quand vous voulez des insights rapides ; s’arrêter pour écrire des tests unitaires peut sembler une corvée. Avec Codex CLI dans votre terminal, ce frein disparaît quasiment.
Pour générer des tests pour la transformation écrite plus haut, vous pouvez rester dans le terminal et utiliser un framework de test Python standard comme pytest. Donnez à Codex un prompt simple comme :
Write high-quality, maintainable pytest tests for the transform module. Test null handling, extreme edge cases like zeroes or negative values, type casting, and revenue calculation.Codex va relire le fichier transformation.py généré plus tôt, comprendre la logique attendue, puis créer un nouveau fichier de test. Vous pourriez voir dans votre terminal, par exemple, un test_transformation.py dans un dossier tests, chargé de vérifier que les fonctions de transformation font bien leur travail.
Codex ne se contente pas d’écrire des assertions génériques, il génère aussi de petites données synthétiques réalistes (fixtures) à injecter dans vos fonctions pour les éprouver. Il crée volontairement des cas limites, comme des IDs utilisateur manquants ou des quantités d’achat négatives, pour s’assurer que votre logique de transformation gère correctement ces scénarios extrêmes.
Tester le code Python est une chose, mais en data, il faut aussi valider les données qui le traversent. On parle de validation des données. Il s’agit de générer des assertions qui vérifient la qualité globale des données avant de les transmettre aux parties prenantes ou de les charger dans un tableau de bord.
Demandez à Codex de produire un script de validation dédié. Par exemple :
Create a data validation script that runs after the very end of the pipeline. It should check that the schema matches our expectations, ensure the null-percentage for user_id is exactly 0%, and verify that all revenue values are greater than or equal to zero.Codex générera un script de validation dédié, véritable filet de sécurité final. Configurez‑le pour qu’il s’exécute en post‑étape à la fin du pipeline.
Ainsi, si la structure du CSV brut change demain, ou si un bug introduit des valeurs de chiffre d’affaires négatives, ce script le détectera et lèvera immédiatement une erreur, évitant de faire circuler silencieusement de mauvaises données.
Jusqu’ici, nous avons surtout utilisé Codex CLI de manière interactive. Mais pour intégrer l’outil à votre routine professionnelle, des modes d’utilisation plus avancés permettent de mettre les tâches rébarbatives en pilotage automatique.
Jupyter Notebooks est idéal pour l’exploration initiale, mais peu adapté à l’exécution fiable en production. On finit souvent par copier‑coller des cellules dans des fichiers Python et corriger des variables globales.
Avec Codex CLI, vous pouvez simplement pointer l’agent vers votre notebook et lui confier la refactorisation. Ouvrez le terminal et tapez :
Refactor analysis.ipynb into a modular Python package with separate files for data loading, transformation, visualization, and a main.py entry point.Après approbation, Codex lit la structure JSON du notebook, extrait le code Python, ignore les sorties parasites et réorganise l’ensemble.
Avant, tout était mêlé dans un unique analysis.ipynb.
Après, vous obtenez un dossier propre et professionnel avec des fichiers data_loader.py, transformer.py et visualizer.py (les noms peuvent varier), reliés par un main.py. De quoi passer instantanément de l’exploration à un code prêt pour la production.
Parfois, vous ne souhaitez pas interagir avec l’interface de chat. Pour des pipelines automatisés (p. ex. des vérifications avant de partager votre code), vous avez besoin que l’IA travaille en arrière‑plan, en totale autonomie.
C’est précisément le rôle de la commande codex exec, conçue pour exécuter Codex dans des scripts et environnements non interactifs sans demander votre permission à chaque étape.
À titre d’exemple, lançons un contrôle rapide. Nous pouvons utiliser codex exec comme un check CI/CD simulé pour détecter/valider automatiquement de mauvaises données.
Ouvrez votre terminal et tapez exactement :
codex exec --skip-git-repo-check "Read transactions.csv. Write and run a quick python script to check if the 'quantity' column contains any negative numbers. If it does, print 'DATA VALIDATION FAILED: Negative quantities detected.' If it is clean, print 'DATA VALIDATION PASSED'." 2> /dev/nullÀ l’exécution, Codex tournera de façon non interactive. Il n’ouvrira pas l’interface de chat habituelle, et le comportement d’approbation dépendra des indicateurs configurés et des valeurs par défaut ; vous devrez peut‑être autoriser certaines actions, sauf si vous désactivez les validations. Pour en savoir plus, consultez la documentation Codex.
Il écrira rapidement le script de validation, l’exécutera sur votre CSV local et enverra le résultat final directement dans la sortie standard du terminal, tant que le répertoire est considéré comme approuvé et que les approbations le permettent. Vous devriez voir un message similaire :
Cette approche couvre de nombreux cas d’usage. Imaginez cette commande telle quelle dans un hook pre‑commit ou un workflow GitHub Actions. Si votre pipeline rencontre des colonnes manquantes, des valeurs NaN ou tout autre comportement inattendu, Codex peut le détecter immédiatement, sans que vous ayez à écrire vous‑même les scripts PyTest et de validation.
Avec les outils d’IA, la manière de formuler vos demandes influence fortement la qualité du code Python généré. Voici quelques bonnes pratiques pour garder un workflow fluide et professionnel.
Il faut apprendre à écrire de bons prompts. Vous ne pouvez pas dire simplement « clean the data » et espérer un résultat parfait. Voici comment structurer vos demandes :
Soyez précis : Indiquez les noms de colonnes, les types attendus et le format de sortie. Par exemple : « cast the 'purchase_date' column to datetime and output a summarized CSV. »
Référencez les fichiers directement : Utilisez la syntaxe @ dans vos prompts. En tapant @transactions.csv, vous forcez Codex à lire ce fichier immédiatement dans son contexte.
Décomposez les tâches complexes : Scindez les demandes en étapes plutôt que de tout confier à un méga‑prompt. Utilisez le mode plan de Codex pour élaborer un brouillon puis exécuter pas à pas.
Pour aller plus loin en prompt engineering, consultez notre cours Prompt Engineering with the OpenAI API.
Comme évoqué plus haut, la CLI propose différents modes d’approbation. Voici quand les utiliser :
La reproductibilité est essentielle. Règle d’or : faites tourner Codex dans un dépôt Git initialisé. Comme Codex écrit et modifie des fichiers sur votre machine, Git vous permet d’inspecter et d’annuler facilement ses changements.
N’oubliez pas de versionner le fichier AGENTS.md créé plus tôt avec votre code. Ainsi, si un autre data scientist clone votre dépôt et ouvre Codex, toute l’équipe bénéficie des mêmes standards et consignes.
Même logique pour les agent skills définies pour des tâches spécifiques. Pour l’inspiration, consultez notre guide des plus de cent top agent skills pour Codex et autres outils de codage agentiques.
Et si vous travaillez sur une analyse lourde sur plusieurs jours, pas besoin de repartir de zéro chaque matin. Utilisez la commande codex resume pour reprendre vos projets multi‑session. Elle recharge votre précédent chat, sans perdre le contexte précieux de vos échanges et plans (dans les limites normales du modèle et de l’historique).
Pour d’autres bonnes pratiques de codage agentique, consultez aussi notre guide Claude Code Best Practices. Bien que Claude Code et Codex diffèrent, comme nous l’avons montré dans notre comparatif Codex vs Claude Code, de nombreux principes de base s’appliquent également à Codex.
Nous avons configuré Codex CLI pour votre travail data et vos environnements Python locaux. Nous avons généré des scripts d’analyse exploratoire, construit des pipelines ETL reproductibles, écrit des tests automatisés de transformation (trop souvent omis) et exploré des moyens avancés d’automatiser les tâches quotidiennes les plus répétitives.
L’essentiel à retenir : nous avons tout fait depuis la ligne de commande, sans allers‑retours avec un navigateur. Codex CLI comble efficacement ce fossé entre l’exploration désordonnée et une ingénierie data de qualité production.
Si vous souhaitez apprendre à construire un agent plus complexe avec Codex CLI, nous vous recommandons notre tutoriel Codex CLI MCP, qui vous guide pas à pas pour créer un agent de tableau de bord de portefeuille financier.
Cours d’IA
Cursus
Cours
Cours