Kursus
Pengantar Python
4 Hr
6.9M
Decision tree adalah struktur pohon mirip bagan alur, di mana node internal merepresentasikan sebuah fitur (atau atribut), cabang merepresentasikan aturan keputusan, dan setiap node daun merepresentasikan hasil.
Node paling atas dalam decision tree dikenal sebagai root node. Node ini belajar melakukan pemartisian berdasarkan nilai atribut. Ia membagi pohon secara rekursif yang disebut pemartisian rekursif. Struktur mirip bagan alur ini membantu Anda dalam pengambilan keputusan. Visualisasinya seperti diagram bagan alur yang mudah meniru cara berpikir manusia. Itulah sebabnya decision tree mudah dipahami dan ditafsirkan.
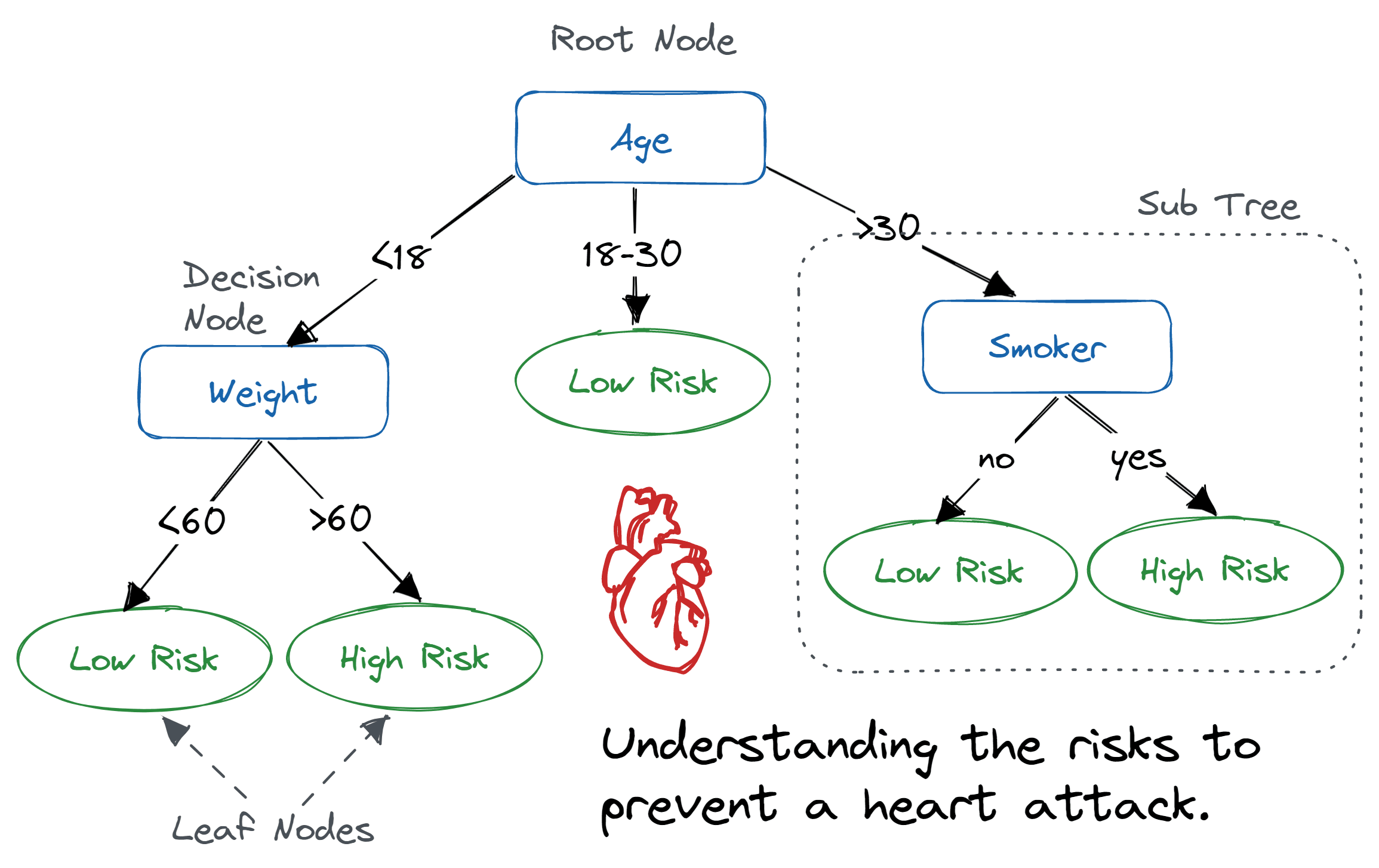
Algoritma decision tree. Gambar oleh Abid Ali Awan
Decision tree adalah jenis algoritma ML white box. Algoritma ini membagikan logika pengambilan keputusan internalnya, yang tidak tersedia pada algoritma jenis black box seperti jaringan saraf. Waktu pelatihannya lebih cepat dibandingkan algoritma jaringan saraf.
Kompleksitas waktu decision tree merupakan fungsi dari jumlah rekaman dan atribut dalam data yang diberikan. Decision tree adalah metode bebas distribusi atau non-parametrik yang tidak bergantung pada asumsi tentang distribusi probabilitas yang mendasari data. Decision tree dapat menangani data berdimensi tinggi dengan akurasi yang baik.
Gagasan dasar di balik algoritma decision tree adalah sebagai berikut:
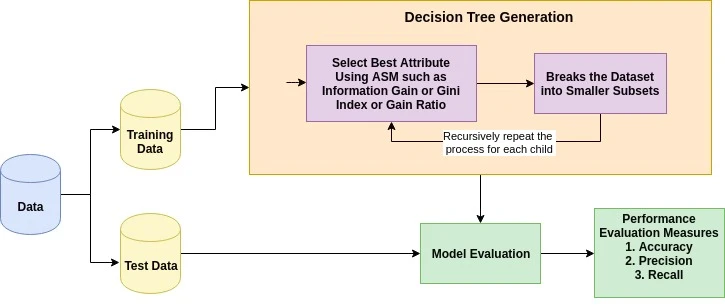
Ukuran pemilihan atribut adalah heuristik untuk memilih kriteria pemisahan yang mempartisi data sebaik mungkin. Ini juga dikenal sebagai aturan pemisahan karena membantu kita menentukan breakpoint untuk tuple pada node tertentu. ASM memberikan peringkat pada setiap fitur (atau atribut) dengan menjelaskan dataset yang diberikan. Atribut dengan skor terbaik akan dipilih sebagai atribut pemisah (Sumber). Untuk atribut bernilai kontinu, titik pemisah untuk cabang juga perlu ditentukan. Ukuran pemilihan yang paling populer adalah Information Gain, Gain Ratio, dan Gini Index.
Claude Shannon menemukan konsep entropi, yang mengukur ketidakmurnian himpunan masukan. Dalam fisika dan matematika, entropi mengacu pada tingkat keacakan atau ketidakmurnian dalam suatu sistem. Dalam teori informasi, entropi merujuk pada ketidakmurnian dalam sekelompok contoh. Information gain adalah penurunan entropi. Information gain menghitung selisih antara entropi sebelum pemisahan dan rata-rata entropi setelah pemisahan dataset berdasarkan nilai atribut yang diberikan. Algoritma decision tree ID3 (Iterative Dichotomiser) menggunakan information gain.
Di mana Pi adalah probabilitas bahwa sebuah tuple acak dalam D termasuk dalam kelas Ci.
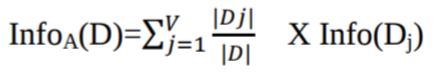
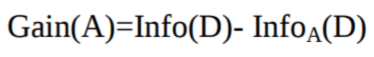
Di mana:
Info(D) adalah jumlah rata-rata informasi yang dibutuhkan untuk mengidentifikasi label kelas dari sebuah tuple dalam D.
|Dj|/|D| berperan sebagai bobot dari partisi ke-j.
InfoA(D) adalah informasi yang diharapkan untuk mengklasifikasikan sebuah tuple dari D berdasarkan pemartisian oleh A.
Atribut A dengan information gain tertinggi, Gain(A), dipilih sebagai atribut pemisah pada node N().
Information gain bias terhadap atribut dengan banyak keluaran. Artinya, ia lebih menyukai atribut dengan banyak nilai yang berbeda. Misalnya, pertimbangkan atribut dengan pengidentifikasi unik seperti customer_ID yang memiliki info(D) nol karena pemartisian murni. Ini memaksimalkan information gain dan menghasilkan pemartisian yang tidak berguna.
C4.5, penyempurnaan dari ID3, menggunakan perluasan information gain yang dikenal sebagai gain ratio. Gain ratio menangani masalah bias dengan menormalkan information gain menggunakan Split Info. Implementasi Java dari algoritma C4.5 dikenal sebagai J48, yang tersedia di alat data mining WEKA.
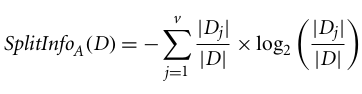
Di mana:
Gain ratio dapat didefinisikan sebagai
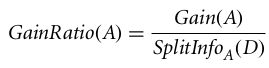
Atribut dengan gain ratio tertinggi dipilih sebagai atribut pemisah (Sumber).
Algoritma decision tree lainnya, CART (Classification and Regression Tree), menggunakan metode Gini untuk membuat titik pemisah.
Di mana pi adalah probabilitas bahwa sebuah tuple dalam D termasuk dalam kelas Ci.
Gini Index mempertimbangkan pemisahan biner untuk setiap atribut. Anda bisa menghitung jumlah berbobot dari ketidakmurnian setiap partisi. Jika pemisahan biner pada atribut A mempartisi data D menjadi D1 dan D2, maka Gini index dari D adalah:
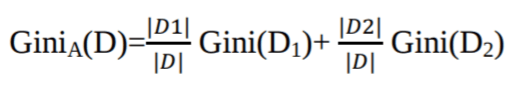
Untuk atribut bernilai diskret, subset yang memberikan gini index minimum untuk atribut yang dipilih akan dipilih sebagai atribut pemisah. Untuk atribut bernilai kontinu, strateginya adalah memilih setiap pasangan nilai berurutan sebagai kemungkinan titik pemisah, dan titik dengan gini index lebih kecil dipilih sebagai titik pemisah.
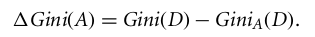
Atribut dengan Gini index minimum dipilih sebagai atribut pemisah.
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeMari kita muat dahulu pustaka yang diperlukan.
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
Mari kita muat terlebih dahulu dataset Pima Indian Diabetes yang diperlukan menggunakan fungsi read CSV dari pandas. Anda dapat mengunduh dataset Kaggle untuk mengikuti langkah-langkahnya.
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=None, names=col_names)
pima.head()
| pregnant | glucose | bp | skin | insulin | bmi | pedigree | age | label | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
Di sini, Anda perlu membagi kolom yang diberikan menjadi dua jenis variabel: variabel terikat (atau variabel target) dan variabel bebas (atau variabel fitur).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
Untuk memahami kinerja model, membagi dataset menjadi set pelatihan dan set uji adalah strategi yang baik.
Mari kita bagi dataset menggunakan fungsi train_test_split(). Anda perlu meneruskan tiga parameter: fitur, target, dan ukuran test_set.
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Mari kita buat model decision tree menggunakan Scikit-learn.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Mari kita perkirakan seberapa akurat pengklasifikasi atau model dapat memprediksi jenis kultivar.
Akurasi dapat dihitung dengan membandingkan nilai set uji aktual dan nilai prediksi.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.6753246753246753
Kita mendapatkan tingkat klasifikasi sebesar 67,53%, yang dianggap sebagai akurasi yang baik. Anda dapat meningkatkan akurasi ini dengan melakukan tuning parameter dalam algoritma decision tree.
Anda dapat menggunakan fungsi export_graphviz() milik Scikit-learn untuk menampilkan pohon di dalam notebook Jupyter. Untuk memplot pohon, Anda juga perlu memasang graphviz dan pydotplus.
pip install graphviz
pip install pydotplusFungsi export_graphviz() mengonversi decision tree classifier menjadi berkas dot, dan pydotplus mengonversi berkas dot ini menjadi PNG atau bentuk yang dapat ditampilkan di Jupyter.
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())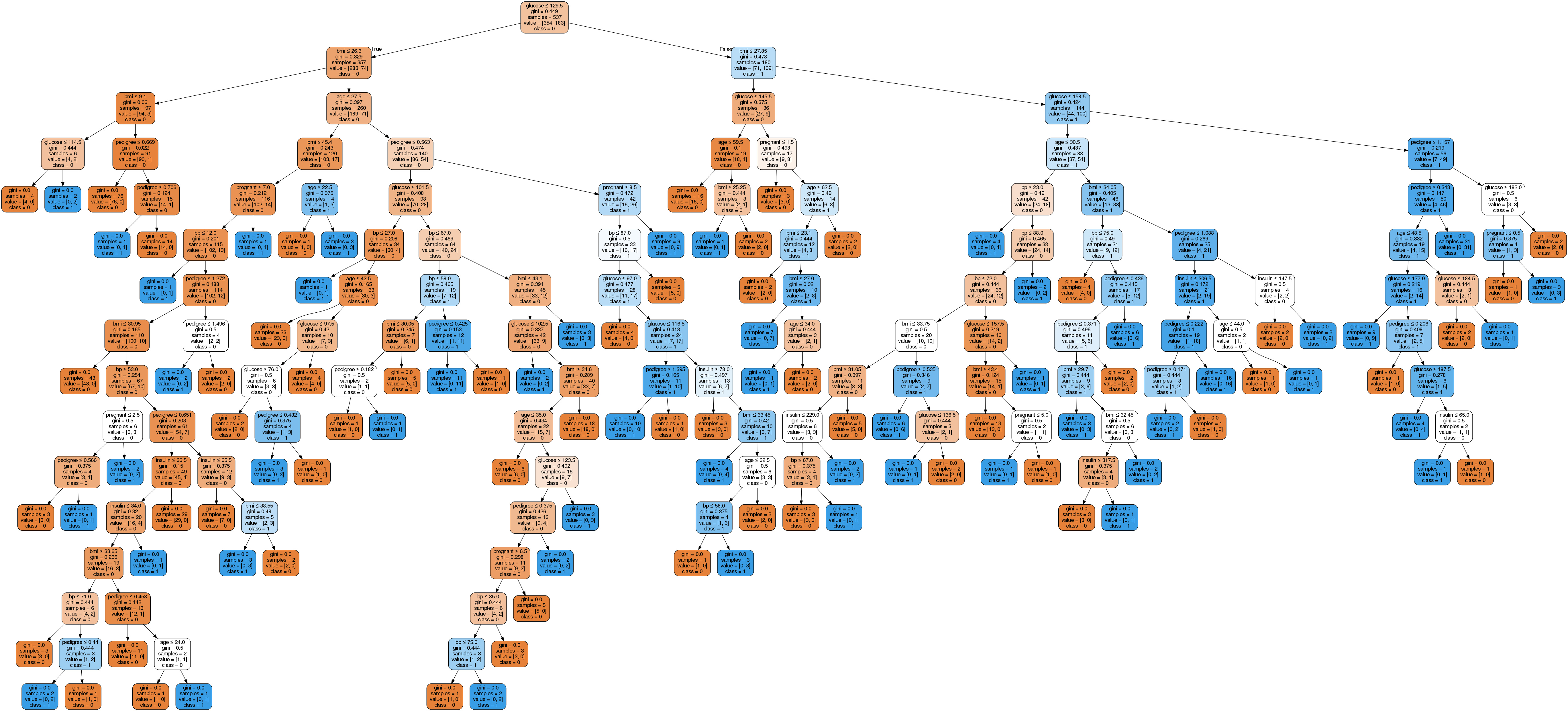
Pada bagan decision tree, setiap node internal memiliki aturan keputusan yang membagi data. Gini, yang disebut sebagai rasio Gini, mengukur ketidakmurnian node. Anda dapat mengatakan sebuah node itu murni ketika semua rekamannya termasuk dalam kelas yang sama; node seperti itu dikenal sebagai node daun.
Di sini, pohon hasilnya belum dipangkas (unpruned). Pohon yang belum dipangkas ini sulit dijelaskan dan tidak mudah dipahami. Pada bagian berikutnya, mari kita optimalkan dengan pemangkasan.
criterion: opsional (default=”gini”) atau Pilih ukuran pemilihan atribut. Parameter ini memungkinkan kita menggunakan ukuran pemilihan atribut yang berbeda-beda. Kriteria yang didukung adalah “gini” untuk Gini index dan “entropy” untuk information gain.
splitter: string, opsional (default=”best”) atau Strategi Pemisahan. Parameter ini memungkinkan kita memilih strategi pemisahan. Strategi yang didukung adalah “best” untuk memilih pemisahan terbaik dan “random” untuk memilih pemisahan acak terbaik.
max_depth: int atau None, opsional (default=None) atau Kedalaman Maksimum Pohon. Kedalaman maksimum pohon. Jika None, maka node akan diperluas hingga semua daun berisi kurang dari sampel min_samples_split. Nilai kedalaman maksimum yang lebih tinggi menyebabkan overfitting, dan nilai yang lebih rendah menyebabkan underfitting (Sumber).
Di Scikit-learn, optimisasi decision tree classifier dilakukan hanya dengan pre-pruning. Kedalaman maksimum pohon dapat digunakan sebagai variabel kontrol untuk pre-pruning. Pada contoh berikut, Anda dapat memplot decision tree pada data yang sama dengan max_depth=3. Selain parameter pre-pruning, Anda juga dapat mencoba ukuran pemilihan atribut lain seperti entropy.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706Baik, tingkat klasifikasi meningkat menjadi 77,05%, yang merupakan akurasi lebih baik dibandingkan model sebelumnya.
Mari kita buat decision tree kita sedikit lebih mudah dipahami menggunakan kode berikut:
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
feature_names=feature_cols,
class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())Di sini, kita telah menyelesaikan langkah-langkah berikut:
Mengimpor pustaka yang diperlukan.
Membuat objek StringIO bernama dot_data untuk menampung representasi teks dari decision tree.
Mengekspor decision tree ke format dot menggunakan fungsi export_graphviz dan menulis keluarannya ke buffer dot_data.
Membuat objek grafik pydotplus dari representasi format dot dari decision tree yang disimpan dalam buffer dot_data.
Menulis grafik yang dihasilkan ke berkas PNG bernama "diabetes.png".
Menampilkan gambar PNG decision tree yang dihasilkan menggunakan objek Image dari modul IPython.display.
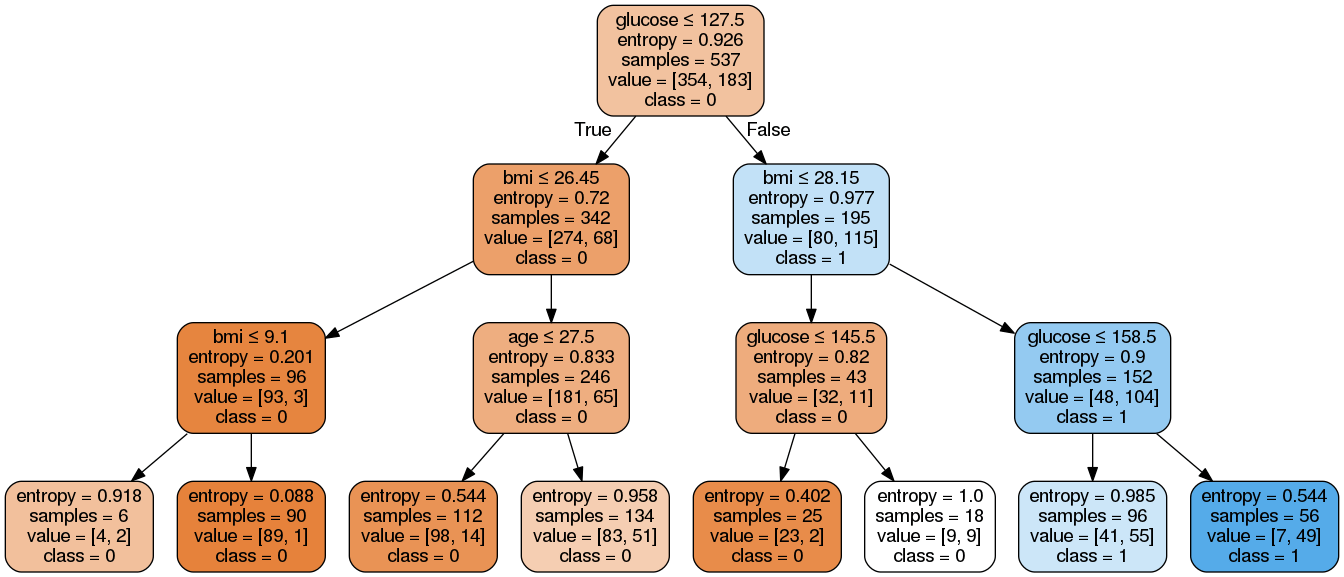
Seperti yang Anda lihat, model yang sudah dipangkas ini kurang kompleks, lebih mudah dijelaskan, dan lebih mudah dipahami dibandingkan plot model decision tree sebelumnya.
Sekarang setelah Anda membangun dan mengoptimalkan decision tree classifier, mari kita luangkan waktu untuk mengevaluasi beberapa kelebihan dan keterbatasan algoritma secara umum. Memahami trade-off membantu Anda memutuskan kapan decision tree adalah pilihan yang tepat.
| Kelebihan | Kekurangan |
|---|---|
| Mudah ditafsirkan dan divisualisasikan | Sensitif terhadap data berisik dan dapat overfit |
| Mudah menangkap pola non-linear | Variasi kecil pada data dapat menghasilkan pohon yang sangat berbeda |
| Memerlukan prapemrosesan data minimal (tidak perlu menormalkan kolom) | Bias pada dataset yang tidak seimbang (disarankan penyeimbangan) |
| Bermanfaat untuk rekayasa fitur (memprediksi nilai hilang, pemilihan variabel) | |
| Tidak ada asumsi tentang distribusi data (non-parametrik) |
Perlu dicatat bahwa beberapa kekurangan, seperti ketidakstabilan varians, dapat diredam melalui metode ansambel seperti algoritma bagging dan boosting.
Meskipun sepanjang tutorial ini kita bekerja dengan decision tree penuh, ada baiknya memahami varian yang lebih sederhana yang disebut decision stump. Decision stump pada dasarnya adalah decision tree dengan kedalaman maksimum satu—artinya hanya memiliki satu pemisahan pada root node dan dua node daun.
| Aspek | Decision Tree | Decision Stump |
|---|---|---|
| Kedalaman | Dapat berapa pun kedalamannya (dikendalikan oleh parameter max_depth) |
Selalu kedalaman 1 (satu pemisahan saja) |
| Kompleksitas | Dapat memodelkan hubungan non-linear yang kompleks | Hanya memodelkan batas keputusan yang sederhana dan linear |
| Kasus Penggunaan | Pengklasifikasi mandiri untuk masalah kompleks | Utamanya digunakan sebagai weak learner dalam metode ansambel |
| Akurasi | Umumnya akurasi lebih tinggi sebagai model mandiri | Akurasi lebih rendah, tetapi efektif saat digabungkan |
| Keterjelasan | Menurun seiring kedalaman (seperti pada pohon yang tidak dipangkas) | Sangat sederhana dan mudah ditafsirkan |
Decision stump jarang digunakan sebagai pengklasifikasi mandiri karena kesederhanaannya. Namun, ia dapat berperan dalam metode ansambel, khususnya AdaBoost yang menggunakan decision stump sebagai weak learner yang digabungkan untuk membuat pengklasifikasi kuat, atau gradient boosting karena stump dapat digunakan sebagai base learner dalam proses boosting.
Anda dapat membuat decision stump di Scikit-learn cukup dengan menyetel max_depth=1:
# Create a Decision Stump
stump = DecisionTreeClassifier(max_depth=1)
stump = stump.fit(X_train, y_train)Selamat, Anda telah mencapai akhir tutorial ini!
Dalam tutorial ini, Anda mempelajari banyak detail tentang decision tree; cara kerjanya, ukuran pemilihan atribut seperti Information Gain, Gain Ratio, dan Gini Index, pembangunan model decision tree, visualisasi, dan evaluasi dataset diabetes menggunakan paket Scikit-learn di Python. Kita juga membahas kelebihan dan kekurangannya, serta cara mengoptimalkan performa decision tree melalui penyetelan parameter.
Semoga sekarang Anda dapat memanfaatkan algoritma decision tree untuk menganalisis dataset Anda sendiri.
Jika Anda ingin mempelajari lebih lanjut tentang Machine Learning di Python, ikuti kursus Machine Learning with Tree-Based Models in Python kami. Selain itu, lihat juga Tutorial Kaggle: Model Machine Learning Pertama Anda.
Kursus Python
Kursus
Kursus
Kursus