Cursus
Introductie tot Python
4 Hr
6.9M
Een beslissingsboom is een stroomdiagram-achtige boomstructuur waarbij een interne knoop een feature (of attribuut) voorstelt, de tak een beslisregel representeert en elke bladknoop de uitkomst weergeeft.
De bovenste knoop in een beslissingsboom staat bekend als de wortelknoop. Die leert te partitioneren op basis van de attribuutwaarde. Het partitioneert de boom op een recursieve manier, ook wel recursive partitioning genoemd. Deze stroomdiagrameske structuur helpt je bij het nemen van beslissingen. De visualisatie lijkt op een flowchart die makkelijk het menselijk denkproces nabootst. Daarom zijn beslissingsbomen eenvoudig te begrijpen en te interpreteren.
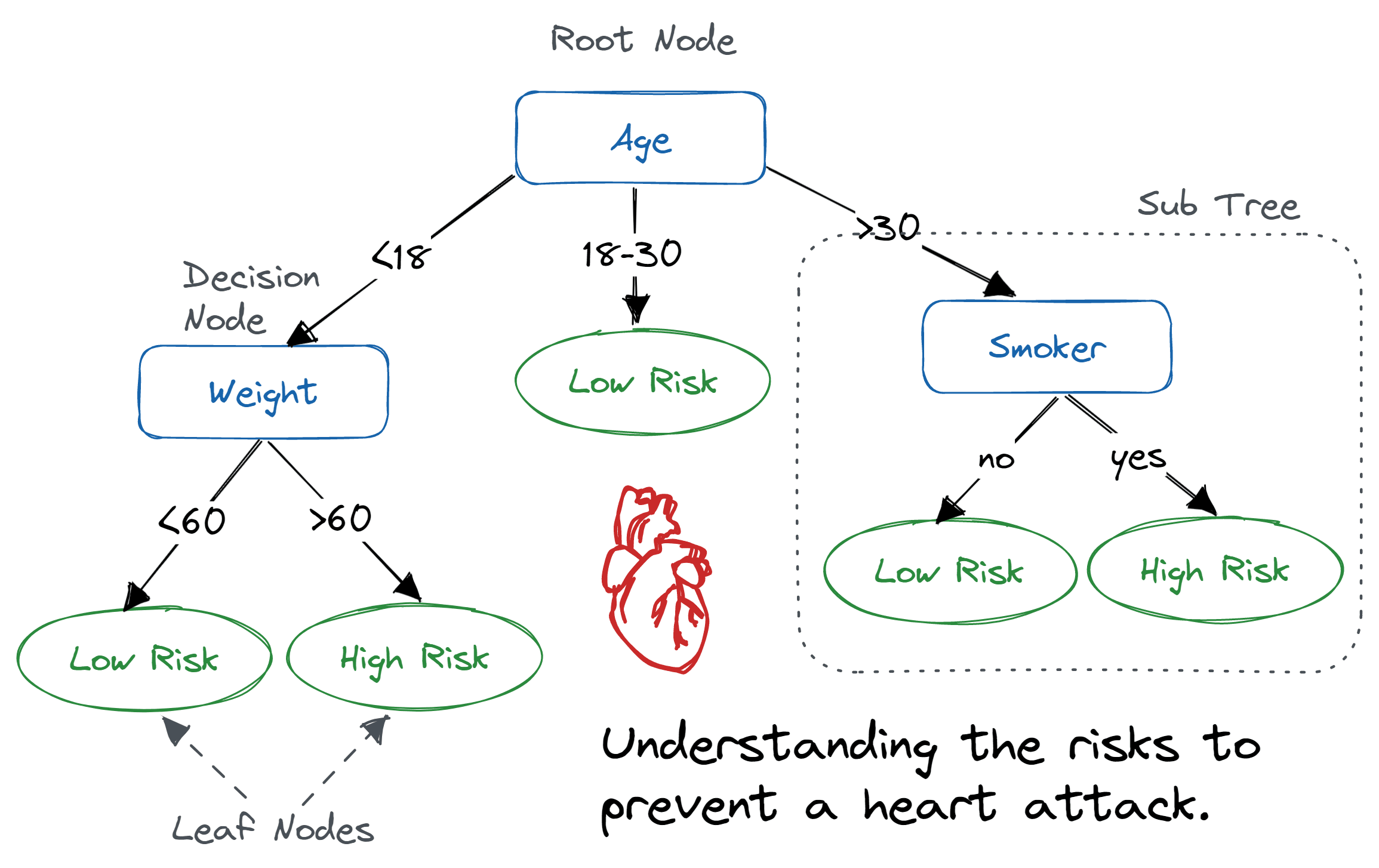
Beslissingsboomalgoritme. Afbeelding door Abid Ali Awan
Een beslissingsboom is een whitebox-type ML-algoritme. Het deelt interne besluitvormingslogica, wat niet beschikbaar is bij blackbox-algoritmen zoals een neuraal netwerk. De trainingstijd is sneller vergeleken met het neurale netwerk-algoritme.
De tijdscomplexiteit van beslissingsbomen is een functie van het aantal records en attributen in de gegeven data. De beslissingsboom is een distributievrije of niet-parametrische methode die niet afhangt van aannames over de onderliggende kansverdeling van de data. Beslissingsbomen kunnen data met hoge dimensies met goede nauwkeurigheid aan.
Het basisidee achter elk beslissingsboomalgoritme is als volgt:
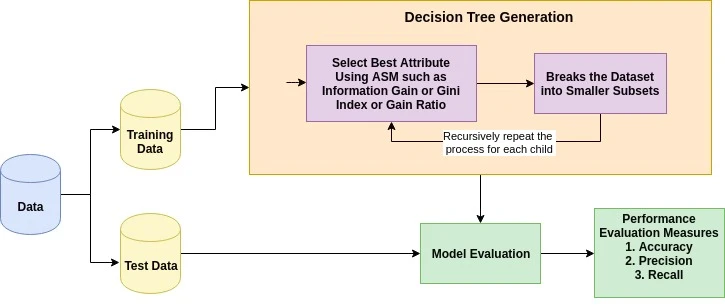
Een maat voor attribuutselectie is een heuristiek om het splitsingscriterium te kiezen dat data op de best mogelijke manier indeelt. Het staat ook bekend als splitting rules omdat het helpt breekpunten voor tuples op een gegeven knoop te bepalen. ASM kent een rang toe aan elke feature (of attribuut) door de gegeven dataset te verklaren. Het attribuut met de beste score wordt gekozen als splitsingsattribuut (Bron). Bij een continu-waardig attribuut moeten ook splitspunten voor takken worden gedefinieerd. De populairste selectiematen zijn Information Gain, Gain Ratio en Gini-index.
Claude Shannon introduceerde het concept entropie, dat de onzuiverheid van de inputset meet. In de natuurkunde en wiskunde verwijst entropie naar de willekeur of onzuiverheid in een systeem. In de informatietheorie verwijst het naar de onzuiverheid in een groep voorbeelden. Information gain is de afname in entropie. Information gain berekent het verschil tussen de entropie vóór de splitsing en de gemiddelde entropie na de splitsing van de dataset op basis van gegeven attribuutwaarden. Het ID3 (Iterative Dichotomiser) beslissingsboomalgoritme gebruikt information gain.
Waarbij Pi de kans is dat een willekeurige tuple in D tot klasse Ci behoort.
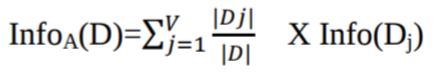
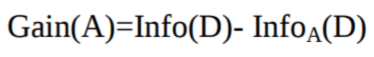
Waarbij:
Info(D) de gemiddelde hoeveelheid informatie is die nodig is om het klasselabel van een tuple in D te identificeren.
|Dj|/|D| fungeert als het gewicht van de jde partitie.
InfoA(D) de verwachte informatie is die nodig is om een tuple uit D te classificeren op basis van de partitionering door A.
Het attribuut A met de hoogste information gain, Gain(A), wordt gekozen als het splitsingsattribuut bij knoop N().
Information gain is bevooroordeeld ten gunste van een attribuut met veel uitkomsten. Dat betekent dat het attribuut met een groot aantal verschillende waarden de voorkeur krijgt. Neem bijvoorbeeld een attribuut met een unieke identifier, zoals customer_ID, dat nul info(D) heeft vanwege een zuivere partitie. Dit maximaliseert de information gain en creëert nutteloze partitionering.
C4.5, een verbetering van ID3, gebruikt een uitbreiding op information gain, bekend als de gain ratio. Gain ratio pakt de bias aan door de information gain te normaliseren met Split Info. De Java-implementatie van het C4.5-algoritme staat bekend als J48 en is beschikbaar in de WEKA data mining-tool.
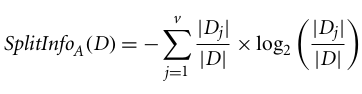
Waarbij:
De gain ratio kan als volgt worden gedefinieerd
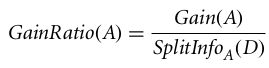
Het attribuut met de hoogste gain ratio wordt gekozen als het splitsingsattribuut (Bron).
Een ander beslissingsboomalgoritme, CART (Classification and Regression Tree), gebruikt de Gini-methode om splitspunten te creëren.
Waarbij pi de kans is dat een tuple in D tot klasse Ci behoort.
De Gini-index beschouwt een binaire splitsing voor elk attribuut. Je kunt een gewogen som van de onzuiverheid van elke partitie berekenen. Als een binaire splitsing op attribuut A de data D verdeelt in D1 en D2, is de Gini-index van D:
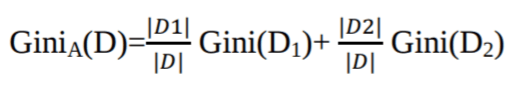
In het geval van een discreet attribuut wordt de subset die de minimale Gini-index oplevert voor dat gekozen attribuut geselecteerd als splitsingsattribuut. Bij continu-waardige attributen is de strategie om elk paar aangrenzende waarden als mogelijk splitspunt te kiezen, en het punt met een kleinere Gini-index wordt gekozen als het splitspunt.
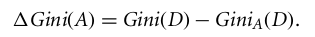
Het attribuut met de minimale Gini-index wordt gekozen als het splitsingsattribuut.
Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenLaten we eerst de vereiste libraries laden.
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
Laten we eerst de vereiste Pima Indian Diabetes-dataset laden met de read CSV-functie van pandas. Je kunt de Kaggle-dataset downloaden om mee te doen.
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=None, names=col_names)
pima.head()
| pregnant | glucose | bp | skin | insulin | bmi | pedigree | age | label | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
Hier moet je de gegeven kolommen opdelen in twee typen variabelen: afhankelijke (of doelvariabele) en onafhankelijke variabelen (of featurevariabelen).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
Om de modelprestatie te begrijpen, is het een goede strategie om de dataset in een trainingsset en een testset te verdelen.
Laten we de dataset splitsen met de functie train_test_split(). Je moet drie parameters meegeven: features, target en de grootte van de testset.
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Laten we een beslissingsboommodel maken met Scikit-learn.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Laten we inschatten hoe nauwkeurig de classifier of het model het type cultivars kan voorspellen.
Nauwkeurigheid kun je berekenen door werkelijke testsetwaarden te vergelijken met voorspelde waarden.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.6753246753246753
We kregen een classificatiepercentage van 67,53%, wat als een goede nauwkeurigheid wordt beschouwd. Je kunt deze nauwkeurigheid verbeteren door de parameters in het beslissingsboomalgoritme te tunen.
Je kunt de functie export_graphviz() van Scikit-learn gebruiken om de boom binnen een Jupyter-notebook weer te geven. Voor het plotten van de boom moet je ook graphviz en pydotplus installeren.
pip install graphviz
pip install pydotplusDe export_graphviz()-functie zet de beslissingsboomclassifier om naar een dot-bestand, en pydotplus zet dit dot-bestand om naar PNG of een weergavebaar formaat in Jupyter.
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())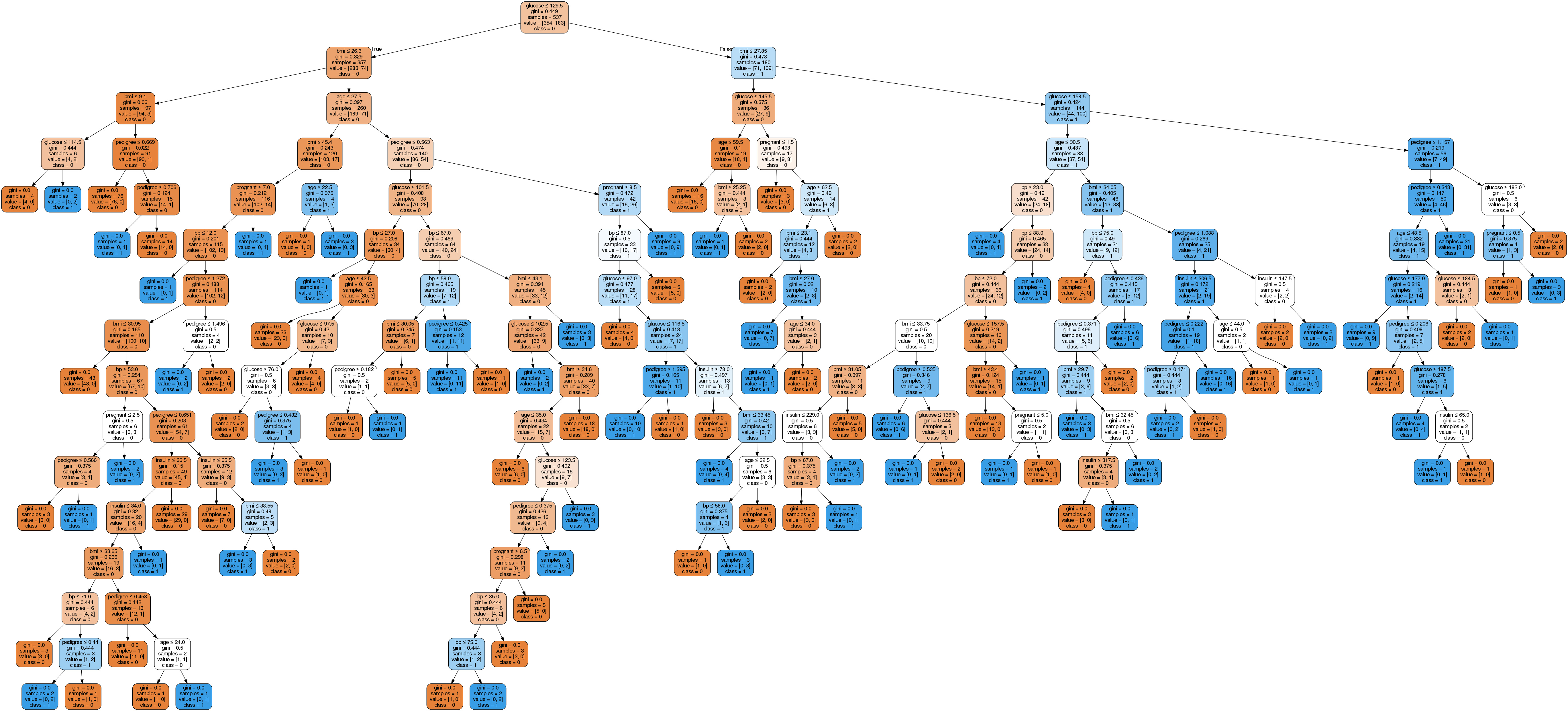
In het diagram van de beslissingsboom heeft elke interne knoop een beslisregel die de data splitst. Gini, ook wel Gini-ratio genoemd, meet de onzuiverheid van de knoop. Je kunt zeggen dat een knoop zuiver is wanneer al zijn records tot dezelfde klasse behoren; zulke knopen worden bladknopen genoemd.
Hier is de resulterende boom ongesnoeid. Deze ongesnoeide boom is niet uitlegbaar en niet makkelijk te begrijpen. In de volgende sectie optimaliseren we hem door te snoeien.
criterion: optioneel (standaard=”gini”) of kies maat voor attribuutselectie. Met deze parameter kun je verschillende maten voor attribuutselectie gebruiken. Ondersteunde criteria zijn “gini” voor de Gini-index en “entropy” voor de information gain.
splitter: string, optioneel (standaard=”best”) of splitsstrategie. Met deze parameter kies je de splitsstrategie. Ondersteunde strategieën zijn “best” om de beste splitsing te kiezen en “random” om de beste willekeurige splitsing te kiezen.
max_depth: int of None, optioneel (default=None) of maximale diepte van een boom. De maximale diepte van de boom. Als None, dan worden knopen uitgebreid totdat alle bladeren minder dan min_samples_split samples bevatten. Een hogere maximale diepte veroorzaakt overfitting en een lagere waarde veroorzaakt underfitting (Bron).
In Scikit-learn wordt de optimalisatie van een decision tree-classifier alleen uitgevoerd door pre-pruning. De maximale diepte van de boom kan worden gebruikt als stuurvariabele voor pre-pruning. In het volgende voorbeeld kun je een beslissingsboom op dezelfde data plotten met max_depth=3. Naast pre-pruningparameters kun je ook een andere maat voor attribuutselectie proberen, zoals entropy.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706Mooi, het classificatiepercentage steeg naar 77,05%, wat een betere nauwkeurigheid is dan het vorige model.
Laten we onze beslissingsboom iets begrijpelijker maken met de volgende code:
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
feature_names=feature_cols,
class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())Hier hebben we het volgende gedaan:
De vereiste libraries geïmporteerd.
Een StringIO-object gemaakt, dot_data genoemd, om de tekstuele representatie van de beslissingsboom vast te houden.
De beslissingsboom naar het dot-formaat geëxporteerd met de functie export_graphviz en de output naar de buffer dot_data geschreven.
Een pydotplus-graafobject gemaakt op basis van de dot-representatie van de beslissingsboom die in de buffer dot_data is opgeslagen.
De gegenereerde graaf weggeschreven naar een PNG-bestand met de naam "diabetes.png".
De gegenereerde PNG-afbeelding van de beslissingsboom weergegeven met het Image-object uit de module IPython.display.
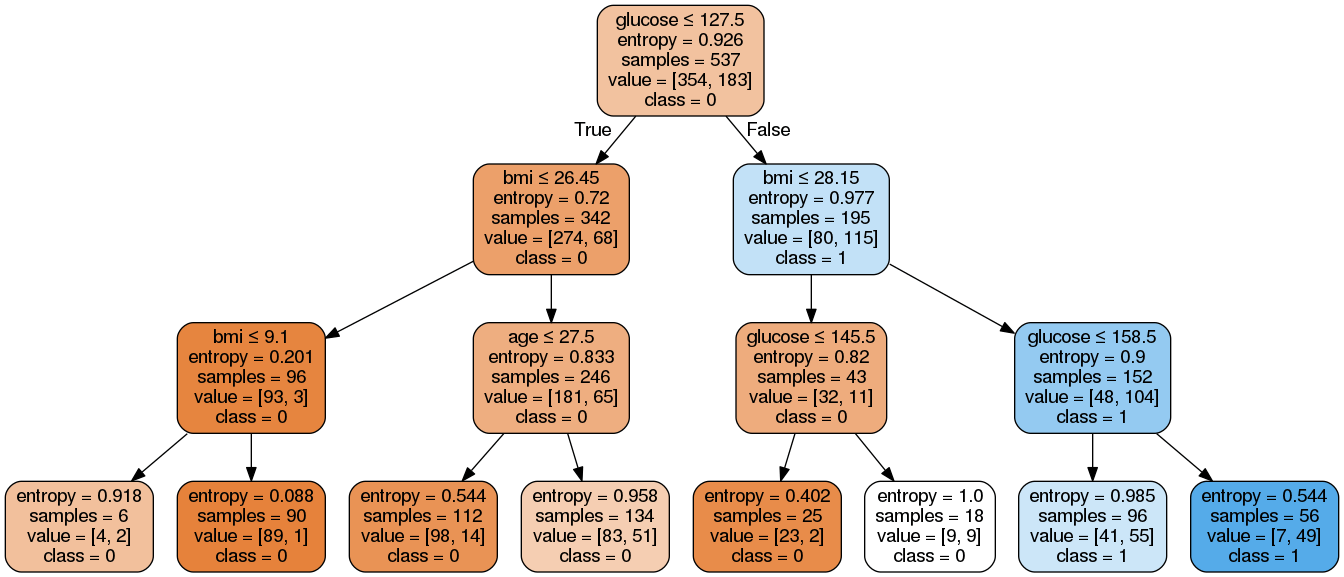
Zoals je ziet is dit gesnoeide model minder complex, beter uitlegbaar en makkelijker te begrijpen dan de vorige plot van het beslissingsboommodel.
Nu je een beslissingsboomclassifier hebt gebouwd en geoptimaliseerd, is het goed om even stil te staan bij de sterke en zwakke punten van het algoritme in het algemeen. Het begrijpen van trade-offs helpt je te beslissen wanneer beslissingsbomen de juiste keuze zijn.
| Voordelen | Nadelen |
|---|---|
| Eenvoudig te interpreteren en te visualiseren | Gevoelig voor ruis in data en kan overfitten |
| Kan eenvoudig niet-lineaire patronen vastleggen | Kleine variaties in data kunnen tot heel verschillende bomen leiden |
| Vraagt minimale datapreprocessing (kolommen hoeven niet genormaliseerd) | Bevooroordeeld bij ongelijke klassenverdeling (balanceren aanbevolen) |
| Nuttig voor feature engineering (missende waarden voorspellen, variabele selectie) | |
| Geen aannames over dataverdeling (niet-parametrisch) |
Let op: sommige nadelen, zoals variantie-instabiliteit, kunnen worden beperkt met ensemblemethoden zoals bagging en boosting-algoritmen.
Hoewel we in deze tutorial met volledige beslissingsbomen hebben gewerkt, is het de moeite waard een eenvoudigere variant te begrijpen: een decision stump. Een decision stump is in feite een beslissingsboom met een maximale diepte van één—oftewel slechts één splitsing bij de wortelknoop en twee bladknopen.
| Aspect | Decision Tree | Decision Stump |
|---|---|---|
| Diepte | Kan elke diepte hebben (geregeld door de max_depth-parameter) |
Altijd diepte 1 (slechts één splitsing) |
| Complexiteit | Kan complexe, niet-lineaire relaties modelleren | Modelleert alleen eenvoudige, lineaire beslisgrenzen |
| Use case | Losstaande classifier voor complexe problemen | Vooral gebruikt als zwakke learner in ensemblemethoden |
| Nauwkeurigheid | Over het algemeen hogere nauwkeurigheid als losstaand model | Lagere nauwkeurigheid, maar effectief in combinatie |
| Interpretatie | Neemt af met de diepte (zoals we zagen bij onze ongesnoeide boom) | Extreem eenvoudig en goed te interpreteren |
Decision stumps worden zelden als zelfstandige classifiers gebruikt vanwege hun eenvoud. Maar ze kunnen een rol spelen in ensemblemethoden; met name AdaBoost gebruikt decision stumps als zwakke learners die worden gecombineerd tot een sterke classifier, en gradient boosting omdat stumps als basislearners in het boosting-proces kunnen worden gebruikt.
Je kunt in Scikit-learn eenvoudig een decision stump maken door max_depth=1 te zetten:
# Create a Decision Stump
stump = DecisionTreeClassifier(max_depth=1)
stump = stump.fit(X_train, y_train)Gefeliciteerd, je bent aan het einde van deze tutorial gekomen!
In deze tutorial heb je veel details over beslissingsbomen behandeld: hoe ze werken, maten voor attribuutselectie zoals Information Gain, Gain Ratio en de Gini-index, het bouwen van een beslissingsboommodel, visualisatie en evaluatie van een diabetesdataset met de Scikit-learn-package van Python. We bespraken ook de voors en tegens en hoe je de prestaties van een beslissingsboom kunt optimaliseren via parameter-tuning.
Hopelijk kun je het beslissingsboomalgoritme nu gebruiken om je eigen datasets te analyseren.
Wil je meer leren over Machine Learning in Python? Volg dan onze cursus Machine Learning with Tree-Based Models in Python. Kijk ook eens naar onze Kaggle Tutorial: Your First Machine Learning Model.
Python-cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
