
Cursus
Introductie tot data importeren in Python
3 Hr
336.1K
Openpyxl is een Python-bibliotheek waarmee je Excel-bestanden kunt lezen en beschrijven.
Met dit framework kun je functies schrijven, spreadsheets opmaken, rapporten maken en grafieken bouwen rechtstreeks in Python, zonder dat je Excel hoeft te openen.
Bovendien maakt Openpyxl het mogelijk om door werkbladen te itereren en dezelfde analyse tegelijk op meerdere datasets uit te voeren.
Dit verhoogt de efficiëntie en maakt automatisering van Excel-workflows mogelijk, omdat je de analyse maar op één werkblad hoeft uit te voeren en die vervolgens zo vaak als nodig kunt repliceren.
Om Openpyxl te installeren, open je simpelweg je commandprompt of PowerShell en typ je de volgende opdracht:
$pip install openpyxlJe zou het volgende bericht moeten zien dat aangeeft dat het pakket succesvol is geïnstalleerd:

In deze tutorial gebruiken we de dataset Video Game Sales van Kaggle. Deze dataset is voor dit artikel door ons team voorbewerkt, en je kunt de aangepaste versie downloaden via deze link. Je kunt Excel in Python importeren door het onderstaande proces te volgen:
Importeer na het downloaden van de dataset de Openpyxl-bibliotheek en laad de werkmap in Python:
import openpyxl
wb = openpyxl.load_workbook('videogamesales.xlsx')Nu het Excel-bestand als een Python-object is geladen, moet je de bibliotheek vertellen welk werkblad je wilt benaderen. Dat kan op twee manieren:
De eerste methode is om simpelweg het actieve werkblad aan te roepen, dat is het eerste blad in de werkmap, met de volgende regel code:
ws = wb.activeAls je de naam van het werkblad kent, kun je het ook op naam benaderen. We gebruiken in dit deel van de tutorial het blad “vgsales”:
ws = wb['vgsales']Laten we nu het aantal rijen en kolommen in dit werkblad tellen:
print('Total number of rows: '+str(ws.max_row)+'. And total number of columns: '+str(ws.max_column))Bovenstaande code zou de volgende output moeten opleveren:
Total number of rows: 16328. And total number of columns: 10Nu we de afmetingen van het blad kennen, gaan we verder en leren we hoe je data uit de werkmap leest.
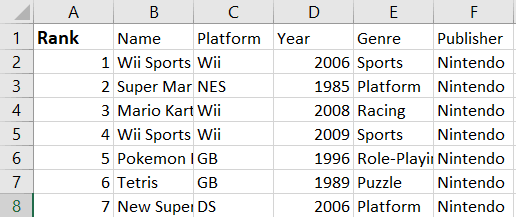
Hier is een screenshot van het actieve blad waar we in dit onderdeel mee werken:
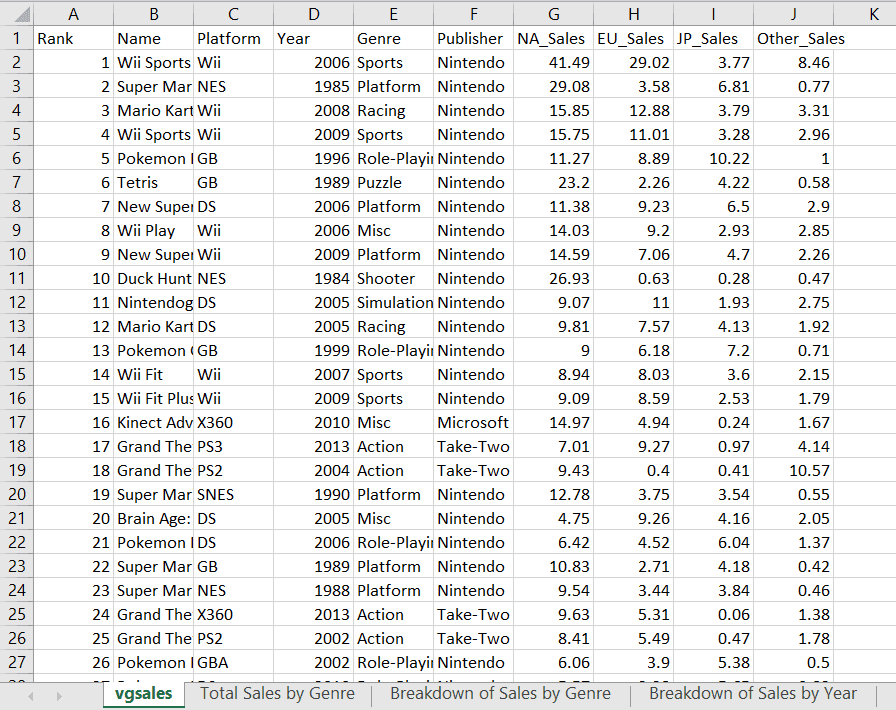
Om met Openpyxl data uit een specifieke cel op te halen, kun je de celwaarde zo aanroepen:
print(f"The value in cell A1 is: {ws['A1'].value}")Je zou de volgende output moeten krijgen:
The value in cell A1 is: RankNu we weten hoe je data uit een specifieke cel leest, wat als we alle celwaarden in een bepaalde rij van de spreadsheet willen printen?
Hiervoor kun je een eenvoudige for-loop schrijven om door alle waarden in een specifieke rij te itereren:
values = [ws.cell(row=1,column=i).value for i in range(1,ws.max_column+1)]
print(values)Bovenstaande code print alle waarden in de eerste rij:
['Rank', 'Name', 'Platform', 'Year', 'Genre', 'Publisher', 'NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales']Laten we vervolgens meerdere rijen in een specifieke kolom printen.
We maken een for-loop om de eerste tien rijen in de kolom “Name” als lijst weer te geven. We zouden de namen moeten krijgen die in het rode vak hieronder zijn gemarkeerd:
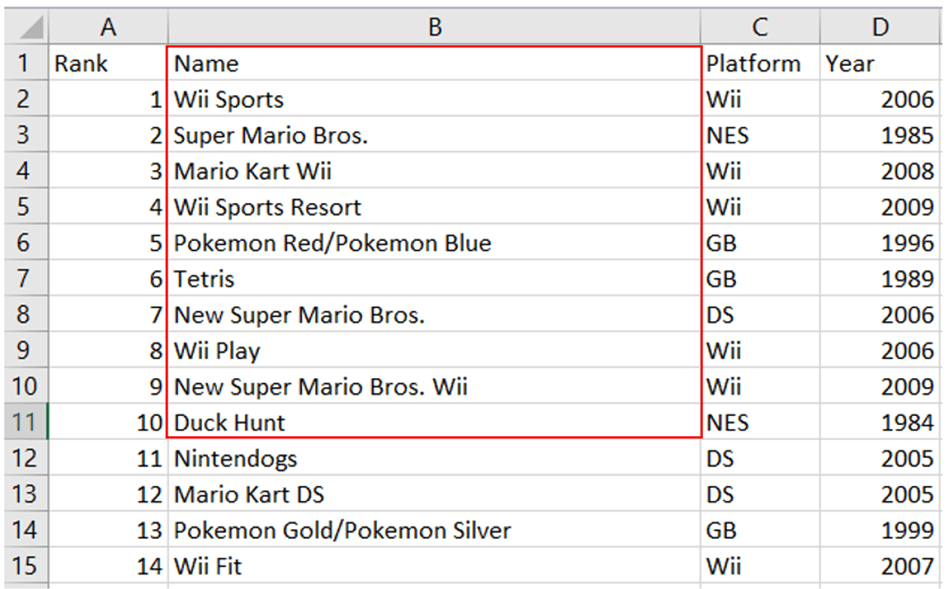
data=[ws.cell(row=i,column=2).value for i in range(2,12)]
print(data)Bovenstaande code genereert de volgende output:
['Wii Sports', 'Super Mario Bros.', 'Mario Kart Wii', 'Wii Sports Resort', 'Pokemon Red/Pokemon Blue', 'Tetris', 'New Super Mario Bros.', 'Wii Play', 'New Super Mario Bros. Wii', 'Duck Hunt']Tot slot printen we de eerste tien rijen in een reeks kolommen van de spreadsheet:
# reading data from a range of cells (from column 1 to 6)
my_list = list()
for value in ws.iter_rows(
min_row=1, max_row=11, min_col=1, max_col=6,
values_only=True):
my_list.append(value)
for ele1,ele2,ele3,ele4,ele5,ele6 in my_list:
(print ("{:<8}{:<35}{:<10}
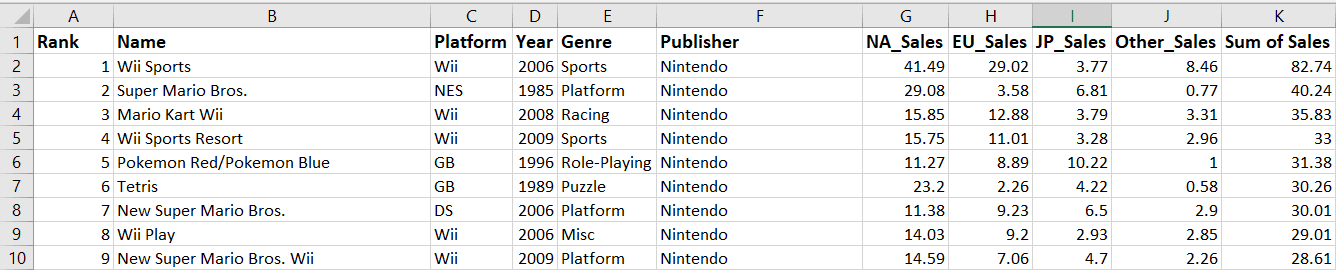
{:<10}{:<15}{:<15}".format(ele1,ele2,ele3,ele4,ele5,ele6)))Na het uitvoeren van de bovenstaande code worden de eerste tien rijen data in de eerste zes kolommen weergegeven:
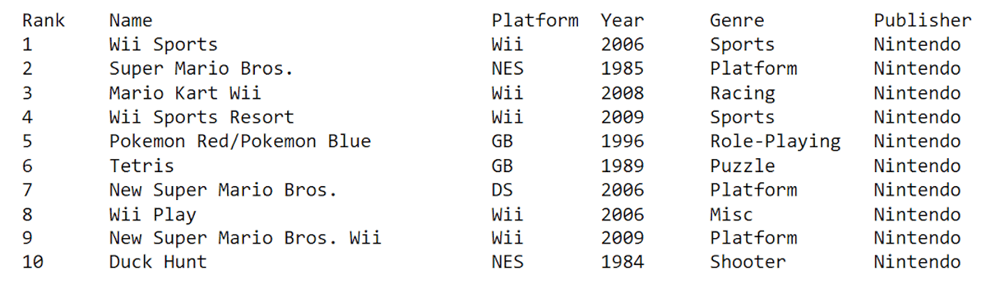
Nu we weten hoe je toegang krijgt tot data in Excel-bestanden en deze leest, leren we hoe je er met Openpyxl naartoe schrijft.
Er zijn twee manieren om met Openpyxl naar een bestand te schrijven.
Je kunt de cel rechtstreeks benaderen via zijn sleutel:
ws['K1'] = 'Sum of Sales'Een alternatief is om de rij- en kolompositie van de cel op te geven waarnaar je wilt schrijven:
ws.cell(row=1, column=11, value = 'Sum of Sales')Elke keer dat je met Openpyxl naar een Excel-bestand schrijft, moet je je wijzigingen opslaan met de volgende regel code, anders worden ze niet doorgevoerd in het werkblad:
wb.save('videogamesales.xlsx')Als je werkmap nog open is wanneer je probeert op te slaan, krijg je de volgende permissiefout:

Zorg dat je het Excel-bestand sluit voordat je je wijzigingen opslaat. Je kunt het daarna opnieuw openen om te controleren of de wijziging is doorgevoerd in je werkblad:
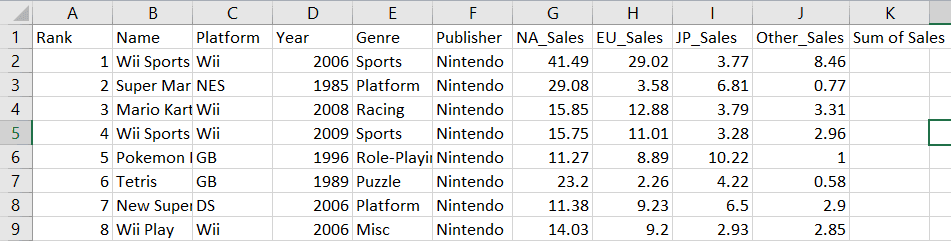
Merk op dat er een nieuwe kolom met de naam “Sum of Sales” is aangemaakt in cel K1.
Laten we nu de som van de verkopen in elke regio toevoegen en deze in kolom K schrijven.
We doen dit voor de verkoopgegevens in de eerste rij:
row_position = 2
col_position = 7
total_sales = ((ws.cell(row=row_position, column=col_position).value)+
(ws.cell(row=row_position, column=col_position+1).value)+
(ws.cell(row=row_position, column=col_position+2).value)+
(ws.cell(row=row_position, column=col_position+3).value))
ws.cell(row=2,column=11).value=total_sales
wb.save('videogamesales.xlsx')Merk op dat de totale verkoop is berekend in cel K2 voor het eerste spel in het werkblad:
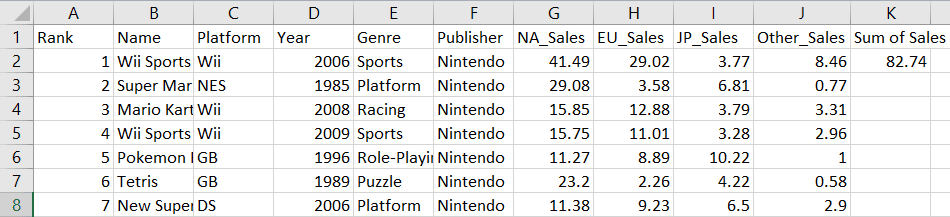
Maak op dezelfde manier een for-loop om de verkoopwaarden in elke rij op te tellen:
row_position = 1
for i in range(1, ws.max_row):
row_position += 1
NA_Sales = ws.cell(row=row_position, column=7).value
EU_Sales = ws.cell(row=row_position, column=8).value
JP_Sales = ws.cell(row=row_position, column=9).value
Other_Sales = ws.cell(row=row_position, column=10).value
total_sales = (NA_Sales + EU_Sales + JP_Sales + Other_Sales)
ws.cell(row=row_position, column=11).value = total_sales
wb.save("videogamesales.xlsx")Je Excel-bestand zou nu een nieuwe kolom moeten hebben die de totale verkoop van videogames in alle regio’s weergeeft:
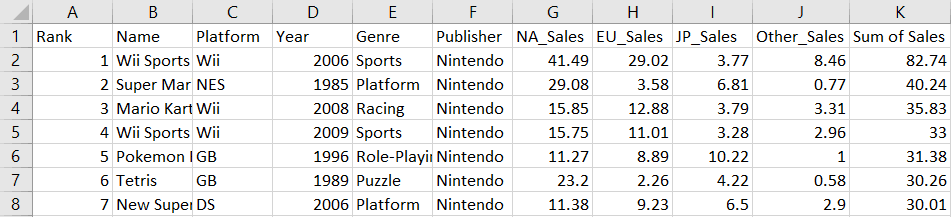
Om een nieuwe rij aan de werkmap toe te voegen, maak je eenvoudig een tuple met de waarden die je wilt opnemen en schrijf je die naar het blad:
new_row = (1,'The Legend of Zelda',1986,'Action','Nintendo',3.74,0.93,1.69,0.14,6.51,6.5)
ws.append(new_row)
wb.save('videogamesales.xlsx')Je kunt bevestigen dat deze data is toegevoegd door de laatste rij in de werkmap te printen:
values = [ws.cell(row=ws.max_row,column=i).value for i in range(1,ws.max_column+1)]
print(values)De volgende output wordt gegenereerd:
[1, 'The Legend of Zelda', 1986, 'Action', 'Nintendo', 3.74, 0.93, 1.69, 0.14, 6.51, 6.5]Om de zojuist gemaakte rij te verwijderen, kun je de volgende regel code uitvoeren:
ws.delete_rows(ws.max_row, 1) # row number, number of rows to delete
wb.save('videogamesales.xlsx')Het eerste argument in de functie delete_rows() is het rijnummer dat je wilt verwijderen. Het tweede argument geeft het aantal te verwijderen rijen aan.
Je kunt met Openpyxl formules schrijven precies zoals in Excel. Hier zijn enkele voorbeelden van basisfuncties die je met Openpyxl kunt maken:
Laten we een nieuwe kolom “Average Sales” maken om de gemiddelde totale verkoop van videogames in alle markten te berekenen:
ws['P1'] = 'Average Sales'
ws['P2'] = '= AVERAGE(K2:K16220)'
wb.save('videogamesales.xlsx')De gemiddelde verkoop over alle markten is ongeveer 0,19. Dit wordt geprint in cel P2 van je werkblad.
De “COUNTA”-functie in Excel telt cellen die zijn gevuld binnen een specifiek bereik. Laten we deze gebruiken om het aantal records tussen E2 en E16220 te vinden:
ws['Q1'] = "Number of Populated Cells"
ws['Q2'] = '=COUNTA(E2:E16220)'
wb.save('videogamesales.xlsx')Er zijn 16.219 records in dit bereik met informatie erin.
COUNTIF() is een veelgebruikte Excel-functie die het aantal cellen telt dat aan een specifieke voorwaarde voldoet. Laten we deze gebruiken om het aantal games met het genre “Sports” in deze dataset te tellen:
ws['R1'] = 'Number of Rows with Sports Genre'
ws['R2'] = '=COUNTIF(E2:E16220, "Sports")'
wb.save('videogamesales.xlsx')Er zijn 2.296 sportgames in de dataset.
Nu zoeken we de totale “Sum of Sales” die door sportgames is gegenereerd met de functie SUMIF:
ws['S1'] = 'Total Sports Sales'
ws['S2'] = '=SUMIF(E2:E16220, "Sports",K2:K16220)'
wb.save('videogamesales.xlsx')Het totale aantal verkopen dat door sportgames is gegenereerd is 454.
De functie CEILING() in Excel rondt een getal naar boven af op het dichtstbijzijnde gespecificeerde veelvoud. Laten we het totale aantal verkopen door sportgames naar boven afronden met deze functie:
ws['T1'] = 'Rounded Sum of Sports Sales'
ws['T2'] = '=CEILING(S2,25)'
wb.save('videogamesales.xlsx')We hebben de totale verkoop door sportgames afgerond op het dichtstbijzijnde veelvoud van 25, wat 475 oplevert.
De bovenstaande codefragmenten zouden in je Excel-blad de volgende output moeten genereren (van cellen P1 tot T2):

Je kunt onze Excel Basics Cheat Sheet raadplegen om meer te leren over Excel-formules, operatoren, wiskundige functies en voorwaardelijke berekeningen.
Nu we weten hoe je werkbladen benadert en ernaar schrijft, leren we hoe we ze kunnen manipuleren, verwijderen en dupliceren met Openpyxl.
Print eerst de naam van het actieve blad waarmee we momenteel werken met behulp van het attribuut title van Openpyxl:
print(ws.title)De volgende output wordt weergegeven:
vgsalesHernoem dit werkblad nu met de volgende regels code:
ws.title ='Video Game Sales Data'
wb.save('videogamesales.xlsx')De naam van je actieve blad is nu gewijzigd in “Video Game Sales Data”.
Voer de volgende regel code uit om alle werkbladen in de werkmap op te sommen:
print(wb.sheetnames)Je ziet een array met de namen van alle werkbladen in het bestand:
['Video Game Sales Data', 'Total Sales by Genre', 'Breakdown of Sales by Genre', 'Breakdown of Sales by Year']Laten we nu een nieuw leeg werkblad maken:
wb.create_sheet('Empty Sheet') # create an empty sheet
print(wb.sheetnames) # print sheet names again
wb.save('videogamesales.xlsx')Merk op dat er nu een nieuw blad “Empty Sheet” is aangemaakt:
['Video Game Sales Data', 'Total Sales by Genre', 'Breakdown of Sales by Genre', 'Breakdown of Sales by Year', ‘Empty Sheet’]Om een werkblad met Openpyxl te verwijderen, gebruik je simpelweg het attribuut remove en print je opnieuw alle bladnamen om te bevestigen dat het blad is verwijderd:
wb.remove(wb['Empty Sheet'])
print(wb.sheetnames)
wb.save('videogamesales.xlsx')Merk op dat het werkblad “Empty Sheet” niet meer beschikbaar is:
['Video Game Sales Data', 'Total Sales by Genre', 'Breakdown of Sales by Genre', 'Breakdown of Sales by Year']Voer tot slot deze regel code uit om een kopie van een bestaand werkblad te maken:
wb.copy_worksheet(wb['Video Game Sales Data'])
wb.save('vgsales_2.xlsx')Als we alle bladnamen opnieuw printen, krijgen we de volgende output:
['Video Game Sales Data', 'Total Sales by Genre', 'Breakdown of Sales by Genre', 'Breakdown of Sales by Year', 'Video Game Sales Data Copy']Excel wordt vaak gezien als de go-to tool voor het maken van visualisaties en het samenvatten van datasets. In dit onderdeel leren we grafieken in Excel te bouwen, rechtstreeks vanuit Python met Openpyxl.
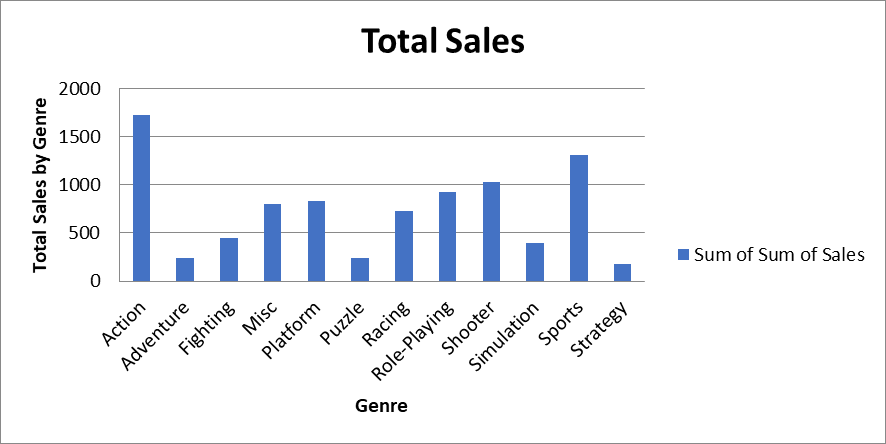
Laten we eerst een eenvoudig staafdiagram maken met de totale verkoop van videogames per genre. We gebruiken hiervoor het werkblad “Total Sales by Genre”:
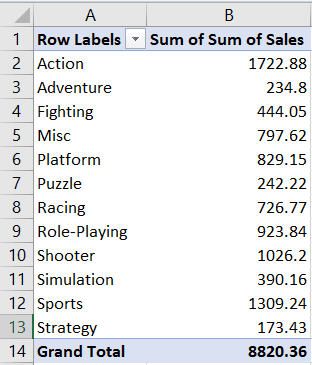
Dit werkblad bevat een draaitabel waarin de som van de verkopen per genre is geaggregeerd, zoals te zien is in de screenshot hierboven.
Laten we dit werkblad benaderen voordat we het staafdiagram maken:
ws = wb['Total Sales by Genre'] # access the required worksheetNu moeten we Openpyxl vertellen welke waarden en categorieën we willen plotten.
De waarden omvatten de “Sum of Sales”-data die we willen plotten. We moeten Openpyxl vertellen waar deze data in het Excel-bestand staat door het bereik op te nemen waarin je waarden beginnen en eindigen.
Vier parameters in Openpyxl laten je specificeren waar je waarden zich bevinden:
Min_column: De minimale kolom met data
Max_column: De maximale kolom met data
Min_row: De minimale rij met data
Max_row: De maximale rij met data
Hier is een afbeelding die laat zien hoe je deze parameters kunt definiëren:
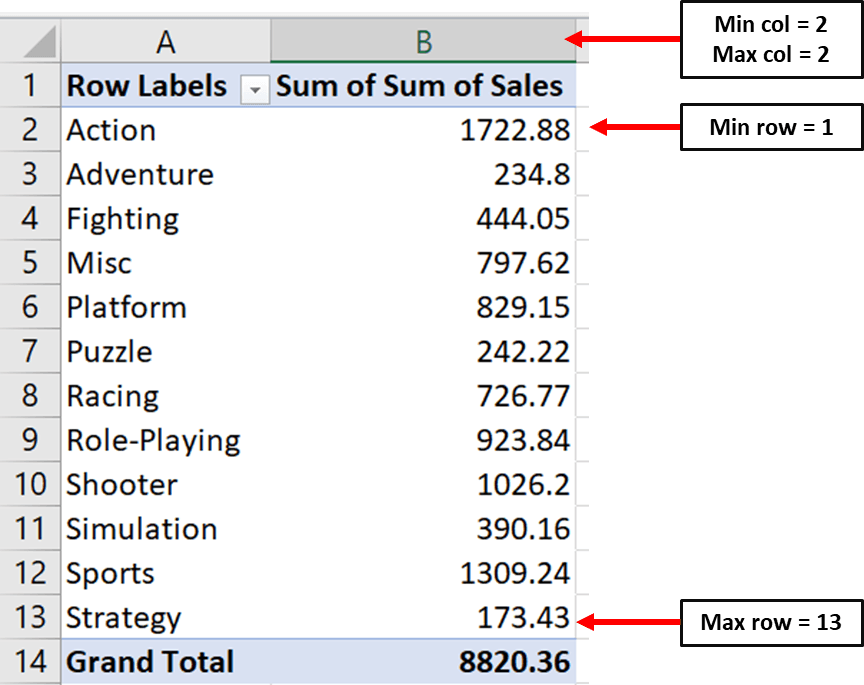
Let op: de minimale rij is de eerste rij en niet de tweede. Dit komt omdat Openpyxl begint te tellen vanaf de rij die een numerieke waarde bevat.
# Values for plotting
from openpyxl.chart import Reference
values = Reference(ws, # worksheet object
min_col=2, # minimum column where your values begin
max_col=2, # maximum column where your values end
min_row=1, # minimum row you’d like to plot from
max_row=13) # maximum row you’d like to plot fromNu moeten we dezelfde parameters definiëren voor de categorieën in ons staafdiagram:
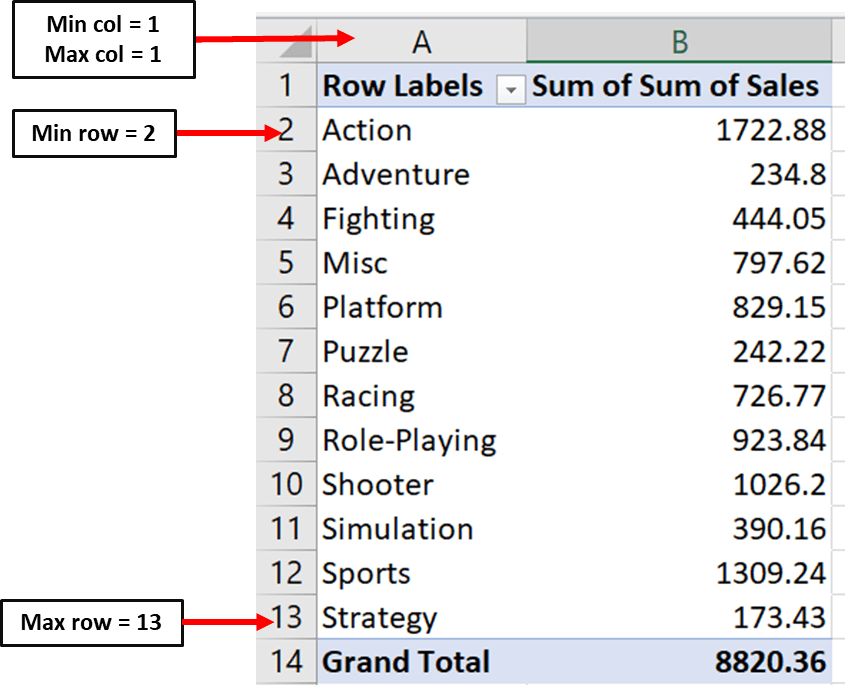
Hier is de code die je kunt gebruiken om parameters voor de categorieën van de grafiek in te stellen:
cats = Reference(ws,
min_col=1,
max_col=1,
min_row=2,
max_row=13)Nu kunnen we het staafdiagramobject maken en onze waarden en categorieën toevoegen met de volgende regels code:
from openpyxl.chart import BarChart
chart = BarChart()
chart.add_data(values, titles_from_data=True)
chart.set_categories(cats)Tot slot kun je de grafiektitels instellen en aangeven waar je de grafiek in het Excel-blad wilt plaatsen:
# set the title of the chart
chart.title = "Total Sales"
# set the title of the x-axis
chart.x_axis.title = "Genre"
# set the title of the y-axis
chart.y_axis.title = "Total Sales by Genre"
# the top-left corner of the chart
# is anchored to cell F2 .
ws.add_chart(chart,"D2")
# save the file
wb.save("videogamesales.xlsx")Open vervolgens het Excel-bestand en ga naar het werkblad “Total Sales by Genre”. Je zou een grafiek moeten zien die er zo uitziet:
Nu maken we een gegroepeerd staafdiagram dat de totale verkoop per genre en regio weergeeft. De data voor deze grafiek vind je in het werkblad “Breakdown of Sales by Genre”:
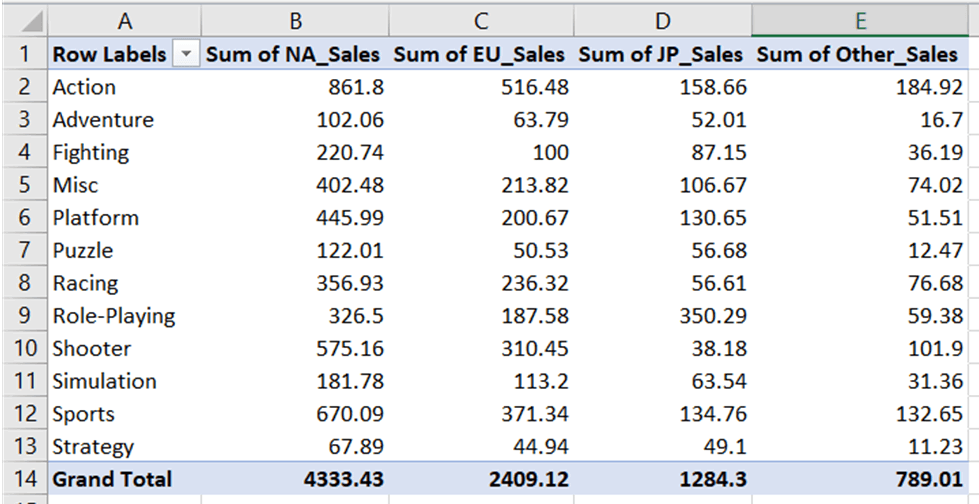
Net als bij het staafdiagram moeten we het bereik voor waarden en categorieën definiëren:
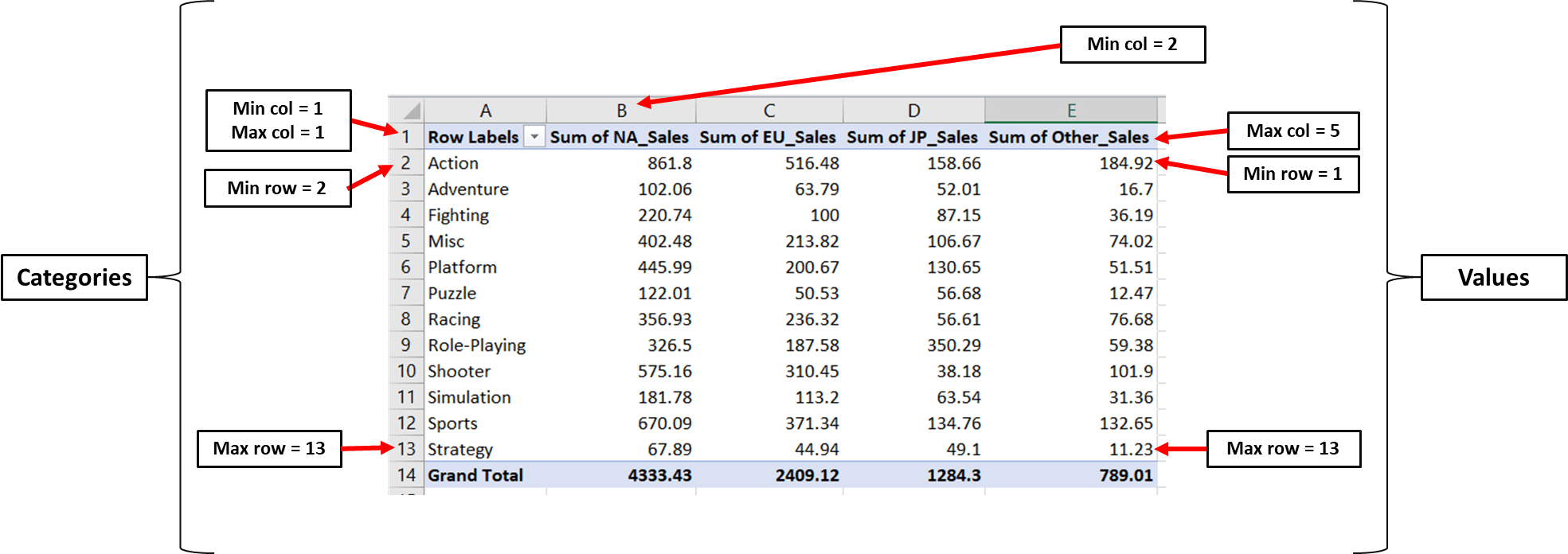
We kunnen nu het werkblad benaderen en dit in code uitschrijven:
### Creating a Grouped Bar Chart with Openpyxl
ws = wb['Breakdown of Sales by Genre'] # access worksheet
# Data for plotting
values = Reference(ws,
min_col=2,
max_col=5,
min_row=1,
max_row=13)
cats = Reference(ws, min_col=1,
max_col=1,
min_row=2,
max_row=13)We kunnen nu het staafdiagramobject maken, de waarden en categorieën toevoegen en de titelparameters instellen, precies zoals we eerder deden:
# Create object of BarChart class
chart = BarChart()
chart.add_data(values, titles_from_data=True)
chart.set_categories(cats)
# set the title of the chart
chart.title = "Sales Breakdown"
# set the title of the x-axis
chart.x_axis.title = "Genre"
# set the title of the y-axis
chart.y_axis.title = "Breakdown of Sales by Genre"
# the top-left corner of the chart is anchored to cell H2.
ws.add_chart(chart,"H2")
# save the file
wb.save("videogamesales.xlsx")Wanneer je het werkblad opent, zou er een gegroepeerd staafdiagram verschijnen dat er zo uitziet:
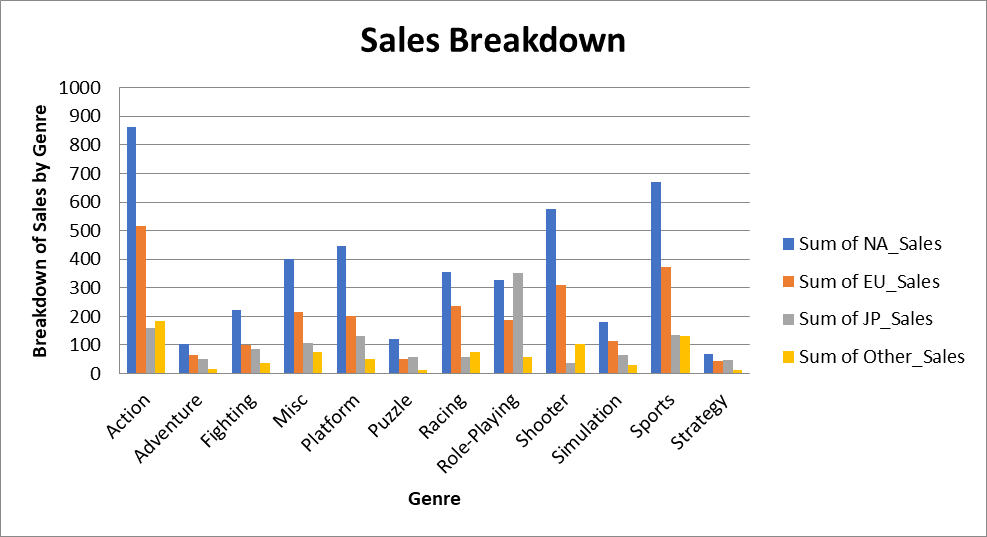
Tot slot maken we een gestapeld lijndiagram met data op het tabblad “Breakdown of Sales by Year”. Dit werkblad bevat verkoopdata van videogames uitgesplitst naar jaar en regio:
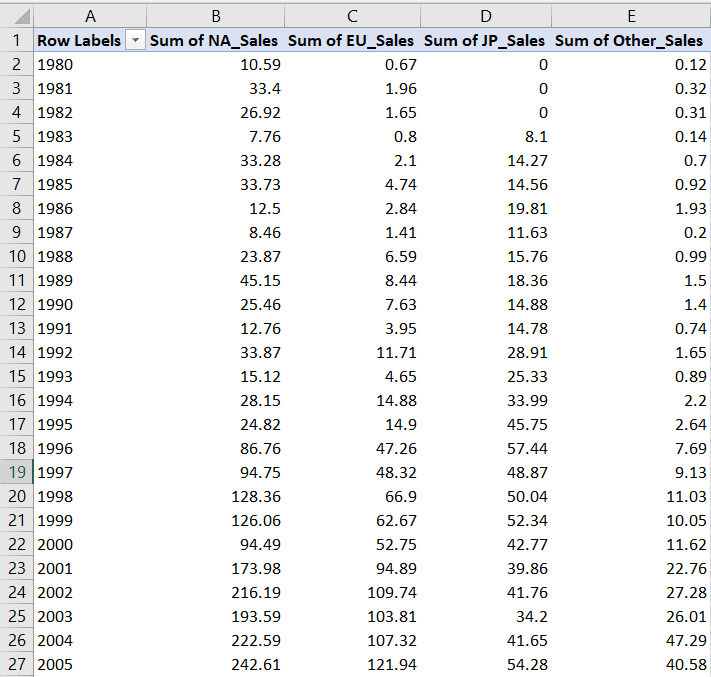
Laten we het bereik voor de waarden en categorieën van deze grafiek definiëren:
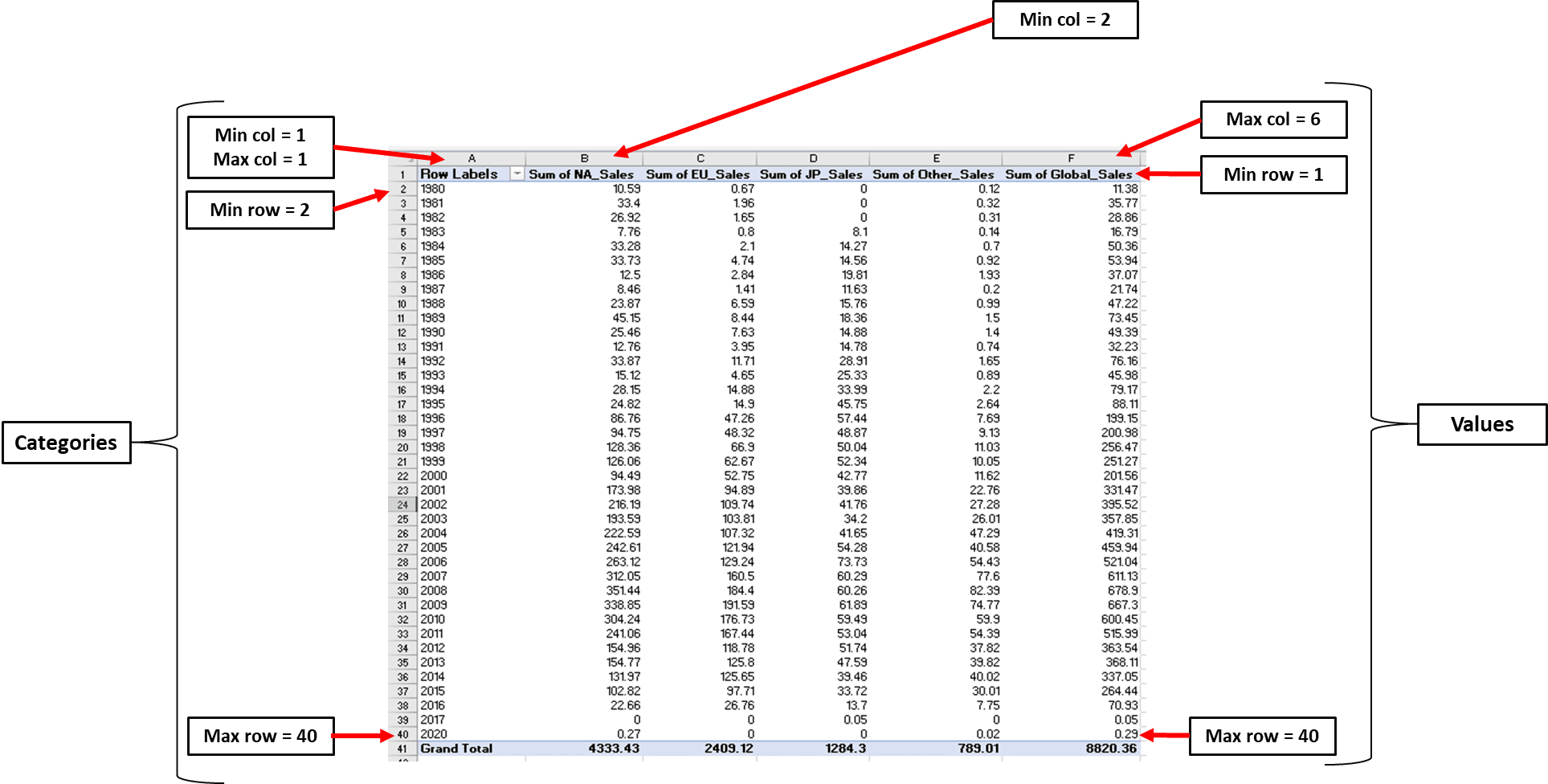
We kunnen deze minimale en maximale waarden nu in code vastleggen:
# Data for plotting
values = Reference(ws,
min_col=2,
max_col=6,
min_row=1,
max_row=40)
cats = Reference(ws, min_col=1, max_col=1, min_row=2, max_row=40)Maak tot slot het lijndiagramobject en stel de titel van de grafiek, de x-as en y-as in:
# Create object of LineChart class
from openpyxl.chart import LineChart
chart = LineChart()
chart.add_data(values, titles_from_data=True)
chart.set_categories(cats)
# set the title of the chart
chart.title = "Total Sales"
# set the title of the x-axis
chart.x_axis.title = "Year"
# set the title of the y-axis
chart.y_axis.title = "Total Sales by Year"
# the top-left corner of the chart is anchored to cell H2
ws.add_chart(chart,"H2")
# save the file
wb.save("videogamesales.xlsx")Er zou een gestapeld lijndiagram op je werkblad moeten verschijnen dat er zo uitziet:
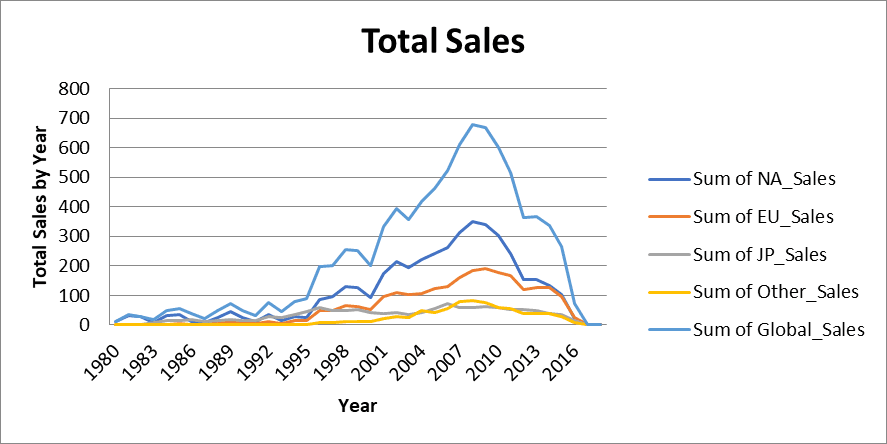
Openpyxl laat gebruikers cellen in Excel-werkboeken stijlen. Je kunt je spreadsheet mooier maken door lettergroottes, achtergrondkleuren en celranden te veranderen, rechtstreeks in Python.
Hier zijn enkele manieren om je Python-Excel-spreadsheet aan te passen met Openpyxl:
Laten we de lettergrootte in cel A1 verhogen en de tekst vet maken met de volgende regels code:
from openpyxl.styles import Font
ws = wb['Video Game Sales Data']
ws['A1'].font = Font(bold=True, size=12)
wb.save('videogamesales.xlsx')Merk op dat de tekst in cel A1 nu iets groter en vet is:
En wat als we de lettergrootte en -stijl willen wijzigen voor alle kolomkoppen in de eerste rij?
Daarvoor kunnen we dezelfde code gebruiken en een for-loop maken om door alle kolommen in de eerste rij te itereren:
for row in ws.iter_rows(min_row=1, max_row=1):
for cell in row:
cell.font = Font(bold=True, size=12)
wb.save('videogamesales.xlsx')Wanneer we door [“1:1”] itereren, geven we Openpyxl aan wat de begin- en eindrijen zijn om doorheen te lopen. Als we bijvoorbeeld door de eerste tien rijen willen loopen, zouden we in plaats daarvan [“1:10”] opgeven.
Je kunt het Excel-blad openen om te controleren of de wijzigingen zijn doorgevoerd:
Je kunt letterkleuren in Openpyxl wijzigen met hex-codes:
from openpyxl.styles import colors
ws['A1'].font = Font(color = 'FF0000',bold=True, size=12) ## red
ws['A2'].font = Font(color = '0000FF') ## blue
wb.save('videogamesales.xlsx')Na het opslaan en opnieuw openen van de werkmap zouden de letterkleuren in de cellen A1 en A2 veranderd moeten zijn: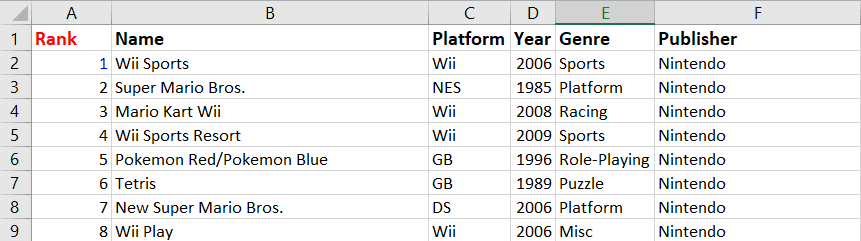
Om de achtergrondkleur van een cel te wijzigen, kun je de module PatternFill van Openpyxl gebruiken:
## changing background color of a cell
from openpyxl.styles import PatternFill
ws["A1"].fill = PatternFill('solid', start_color="38e3ff") # light blue background color
wb.save('videogamesales.xlsx')De volgende wijziging zou in je werkblad zichtbaar moeten zijn:
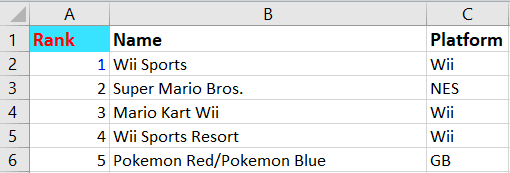
Om een celrand toe te voegen met Openpyxl, voer je de volgende regels code uit:
## cell borders
from openpyxl.styles import Border, Side
my_border = Side(border_style="thin", color="000000")
ws["A1"].border = Border(
top=my_border, left=my_border, right=my_border, bottom=my_border
)
wb.save("videogamesales.xlsx")Je zou een rand moeten zien die er zo uitziet in cel A1:
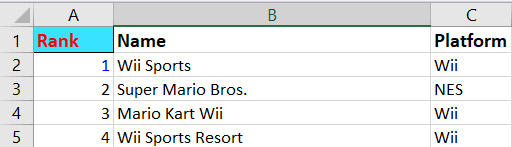
Voorwaardelijke opmaak is het proces waarbij specifieke waarden in een Excel-bestand worden gemarkeerd op basis van een set voorwaarden. Het stelt gebruikers in staat data eenvoudiger te visualiseren en de waarden in hun werkbladen beter te begrijpen.
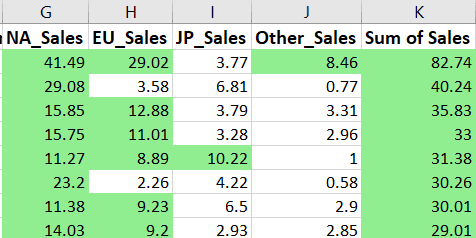
Laten we met Openpyxl alle verkoopwaarden van videogames die groter dan of gelijk aan 8 zijn groen markeren:
from openpyxl.formatting.rule import CellIsRule
fill = PatternFill(
start_color='90EE90',
end_color='90EE90',fill_type='solid') # specify background color
ws.conditional_formatting.add(
'G2:K16594', CellIsRule(operator='greaterThan', formula=[8], fill=fill)) # include formatting rule
wb.save('videogamesales.xlsx')In het eerste codeblok geven we de achtergrondkleur op van de cellen die we willen opmaken. In dit geval is de kleur lichtgroen.
Vervolgens maken we een regel voor voorwaardelijke opmaak waarin staat dat elke waarde groter dan 8 moet worden gemarkeerd met de opgegeven vulkleur. We geven ook het celbereik op waarop we deze voorwaarde willen toepassen.
Na het uitvoeren van de bovenstaande code zouden alle verkoopwaarden boven de 8 als volgt gemarkeerd moeten zijn:
We hebben in deze tutorial veel behandeld, van de basis van de Openpyxl-bibliotheek tot meer geavanceerde handelingen zoals het maken van grafieken en het opmaken van spreadsheets in Python.
Op zichzelf zijn Python en Excel krachtige tools voor datamanipulatie waarmee je voorspellende modellen bouwt, analytische rapporten maakt en wiskundige berekeningen uitvoert.
Het grootste voordeel van Excel is dat vrijwel iedereen het gebruikt. Van niet-technische stakeholders tot junioren: medewerkers van alle niveaus begrijpen rapporten die in een Excel-spreadsheet worden gepresenteerd.
Python daarentegen wordt gebruikt om grote hoeveelheden data te analyseren en modellen te bouwen. Het kan teams helpen om arbeidsintensieve taken te automatiseren en de efficiëntie van de organisatie te verbeteren.
Wanneer Excel en Python samen worden gebruikt, kan dat uren van de workflows van een bedrijf afhalen, terwijl je toch vasthoudt aan een interface die voor iedereen in de organisatie vertrouwd is.
Meer leren over Python en spreadsheets
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
