
Cursus
Intermediate Data Visualization with Seaborn
4 Hr
75K
Seaborn is een van de favoriete Python-bibliotheken voor statistische datavisualisatie. Gebouwd op Matplotlib genereert het gepolijste grafieken met minder code, integreert het naadloos met pandas DataFrames en behandelt het veelvoorkomende statistische plots—histogrammen, boxplots, heatmaps, regressiecurves—via een consistente API.
In deze tutorial loop ik door Seaborns kernplottypes, laat ik zien hoe je ze aanpast en vergelijk ik Seaborn met andere Python-visualisatiebibliotheken zoals Matplotlib en Plotly. Alle codevoorbeelden gebruiken Seaborn 0.13+ en pandas 2.0+.
Seaborn is een Python-bibliotheek voor statistische visualisatie gebouwd op Matplotlib—installeer met pip install seaborn
Werkt direct met pandas DataFrames: geef kolomnamen door als x, y en hue-argumenten
Belangrijkste plottypes: scatterplot(), lineplot(), barplot(), histplot(), boxplot(), heatmap(), pairplot()
Figure-level functies (relplot(), displot(), catplot()) maken met één call rasterindelingen met meerdere panelen
Pas het uiterlijk aan met set_theme() en ingebouwde kleurpaletten
Seaborn is een Python-bibliotheek voor datavisualisatie, gebouwd boven op Matplotlib. Het werkt rechtstreeks met pandas DataFrames, dus je geeft kolomnamen als argumenten door in plaats van ruwe arrays. De bibliotheek dekt de meest gangbare statistische grafiektypen: scatterplots, lijndiagrammen, staafdiagrammen, histogrammen, boxplots, heatmaps en meer.
Seaborn ordent zijn API in drie niveaus:
Figure-level functies (relplot(), displot(), catplot()) maken volledige figuurrasters en regelen facetten automatisch
Axes-level functies (scatterplot(), histplot(), boxplot(), enz.) tekenen op één Matplotlib-as
Hulpfuncties (heatmap(), pairplot(), jointplot()) voor gespecialiseerde lay-outs met meerdere panelen
Je kunt meer leren over Seaborn met onze cursus Introduction to Data Visualization with Seaborn.
Seaborn wordt geleverd met ingebouwde thema's en kleurpaletten die je met één set_theme()-aanroep toepast. Het bevat ook statistische schatting—betrouwbaarheidsintervallen op staafdiagrammen, regressiecurves, kernel-dichtheidsschattingen—zodat je met minimale code van ruwe data naar een publiceerbare figuur gaat.
De twee meest gebruikte Python-bibliotheken voor datavisualisatie zijn Matplotlib en Seaborn. Hoewel beide bibliotheken zijn ontworpen om hoogwaardige grafieken en visualisaties te maken, hebben ze enkele belangrijke verschillen waardoor ze beter geschikt zijn voor verschillende use-cases.
Matplotlib geeft je volledige controle over elk element van een figuur (assen, ticks, legendes, annotaties), maar die controle betekent meer code voor elke grafiek. Seaborn ruilt een deel van die granulariteit in voor snelheid: één functieaanroep met een DataFrame levert een gestileerde statistische plot op.
| Feature | Matplotlib | Seaborn |
|---|---|---|
| Abstraction level | Low-level (fijne controle) | High-level (statistische defaults) |
| Default styling | Minimaal—vereist handmatige theming | Publicatieklare thema's ingebouwd |
| DataFrame integration | Accepteert arrays; DataFrame-ondersteuning later toegevoegd | Gebouwd rond pandas DataFrames |
| Statistical features | Geen ingebouwd | Betrouwbaarheidsintervallen, regressie, KDE |
| Multi-panel layouts | Handmatig met subplots() |
Automatisch met FacetGrid, relplot() |
| Best for | Aangepaste, niet-standaard figuren | Exploratieve data-analyse, standaard statistische grafieken |
In de praktijk gebruik je ze samen. Seaborn maakt de plot, daarna gebruik je Matplotlib-functies om labels, limieten of annotaties te fine-tunen—zoals je hieronder in de voorbeelden ziet.
Je kunt Matplotlib uitgebreider verkennen met onze tutorial Introduction to Plotting with Matplotlib in Python.
Seaborn vereist Python 3.9+ (vanaf versie 0.13) en is afhankelijk van Matplotlib, pandas en NumPy. Installeer met pip of conda:
# install seaborn with pip
pip install seabornWanneer je pip gebruikt, worden Seaborn en de vereiste afhankelijkheden geïnstalleerd. Wil je toegang tot extra, optionele features, dan kun je optionele dependencies meenemen in pip install. Bijvoorbeeld:
pip install seaborn[stats]
Of met conda:
# install seaborn with conda
conda install seaborn
Seaborn biedt diverse ingebouwde datasets die we kunnen gebruiken voor datavisualisatie en statistische analyse. Deze datasets zijn opgeslagen in pandas-dataframes, waardoor ze eenvoudig te gebruiken zijn met de plotfuncties van Seaborn.
Een van de meest gebruikte datasets, die ook in alle officiële voorbeelden van Seaborn voorkomt, is de `tips`-dataset; die bevat informatie over fooien in restaurants. Hier is een voorbeeld van het laden en visualiseren van de Tips-dataset in Seaborn:
import seaborn as sns
tips = sns.load_dataset("tips")
sns.histplot(data=tips, x="total_bill")Output:
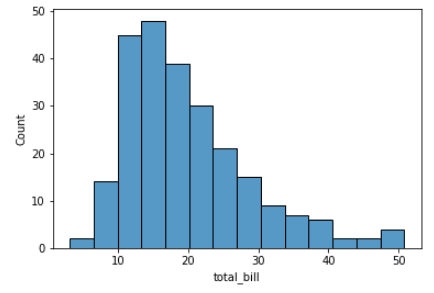
Begrijp je deze plot nog niet? Geen zorgen. Dit heet een histogram. Later in deze tutorial leggen we histogrammen uitgebreider uit. Voor nu is de kern dat Seaborn veel voorbeelddatasets als pandas DataFrames meelevert die gemakkelijk te gebruiken zijn om je visualisatieskills te oefenen. Hier is een ander voorbeeld met de `exercise`-dataset.
import seaborn as sns
# Load the exercise dataset
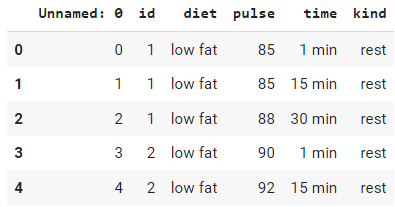
exercise = sns.load_dataset("exercise")
# check the head
exercise.head()Output:
Seaborn biedt een reeks plottypen voor verschillende analytische behoeften. Elke visualisatie valt doorgaans in een van drie categorieën:

Hier zijn enkele van de meest gebruikte plottypen in Seaborn:
We bekijken nu voorbeelden en gedetailleerde uitleg voor elk van deze in de volgende sectie van deze tutorial.
Een van de belangrijkste concepten in Seaborn is het onderscheid tussen figure-level en axes-level functies. Als je dit begrijpt, bespaart dat je debugtijd.
Axes-level functies (zoals scatterplot(), histplot(), boxplot()) tekenen op één Matplotlib-as. Je kunt een ax-argument doorgeven om te bepalen waar de plot komt:
import seaborn as sns
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
tips = sns.load_dataset("tips")
sns.histplot(data=tips, x="total_bill", ax=axes[0])
sns.boxplot(data=tips, x="day", y="total_bill", ax=axes[1])
plt.tight_layout()
plt.show()Figure-level functies (relplot(), displot(), catplot()) maken hun eigen figuur en kunnen data automatisch opdelen in meerdere panelen via de parameters col en row:
import seaborn as sns
tips = sns.load_dataset("tips")
sns.displot(data=tips, x="total_bill", col="time", kde=True)Figure-level functies retourneren een FacetGrid-object in plaats van een as, dus je stelt titels en labels anders in: gebruik g.set_axis_labels() en g.set_titles() in plaats van plt.xlabel().
Laten we Seaborn in actie zien met een paar voorbeelden van verschillende plottypen.
Scatterplots worden gebruikt om de relatie tussen twee continue variabelen te visualiseren. Elk punt in de plot vertegenwoordigt één datapunt, en de positie op de x- en y-as geeft de waarden van de twee variabelen weer.
De plot kan worden aangepast met verschillende kleuren en markers om groepen datapunten te onderscheiden. In Seaborn kun je scatterplots maken met de functie scatterplot().
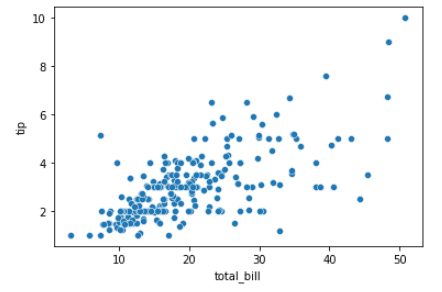
import seaborn as sns
tips = sns.load_dataset("tips")
sns.scatterplot(x="total_bill", y="tip", data=tips)Output:
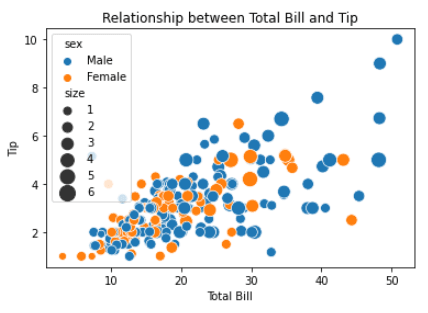
Deze simpele plot kun je verbeteren door de parameters `hue` en `size` aan te passen. Zo doe je dat:
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
# customize the scatter plot
sns.scatterplot(x="total_bill", y="tip", hue="sex", size="size", sizes=(50, 200), data=tips)
# add labels and title
plt.xlabel("Total Bill")
plt.ylabel("Tip")
plt.title("Relationship between Total Bill and Tip")
# display the plot
plt.show()Output:
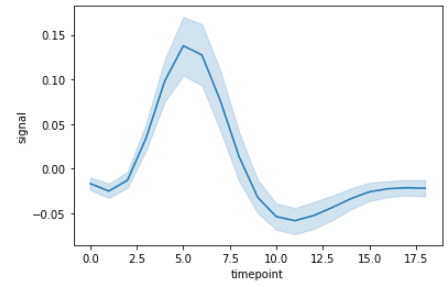
Lijndiagrammen worden gebruikt om trends in data over tijd of andere continue variabelen te visualiseren. In een lijndiagram worden datapunten verbonden door een lijn, zodat er een vloeiende curve ontstaat. In Seaborn maak je lijndiagrammen met de functie lineplot(). Meer verdieping vind je in onze Seaborn line plot-tutorial.
import seaborn as sns
fmri = sns.load_dataset("fmri")
sns.lineplot(x="timepoint", y="signal", data=fmri)Output:
We kunnen dit heel eenvoudig aanpassen met de kolommen `event` en `region` uit de dataset.
import seaborn as sns
import matplotlib.pyplot as plt
fmri = sns.load_dataset("fmri")
# customize the line plot
sns.lineplot(x="timepoint", y="signal", hue="event", style="region", markers=True, dashes=False, data=fmri)
# add labels and title
plt.xlabel("Timepoint")
plt.ylabel("Signal Intensity")
plt.title("Changes in Signal Intensity over Time")
# display the plot
plt.show()Output:
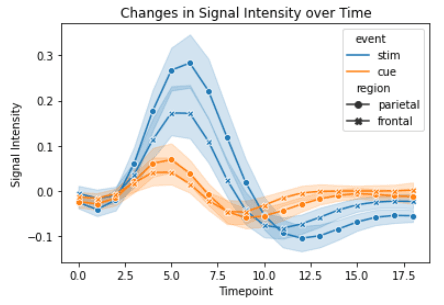
Ook hier gebruikte ik Seaborn voor de basisplot en Matplotlib voor de aslabels en titel.
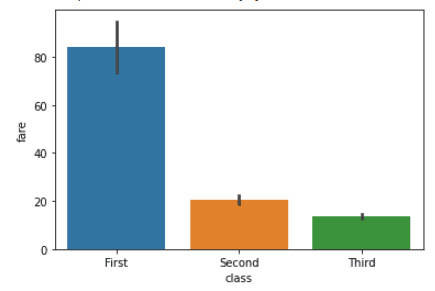
Staafdiagrammen worden gebruikt om de relatie tussen een categorische variabele en een continue variabele te visualiseren. In een staafdiagram vertegenwoordigt elke staaf het gemiddelde of de mediaan (of een andere aggregatie) van de continue variabele per categorie. In Seaborn maak je staafdiagrammen met de functie barplot(). Voor meer details, zie onze Seaborn-barplotgids.
import seaborn as sns
titanic = sns.load_dataset("titanic")
sns.barplot(x="class", y="fare", data=titanic)Output:
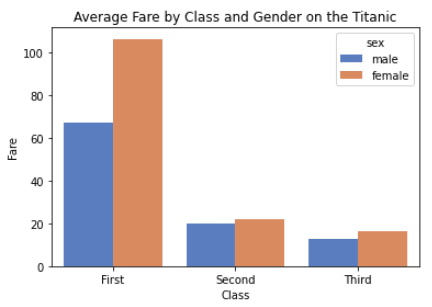
Laten we deze plot aanpassen door de kolom `sex` uit de dataset toe te voegen.
import seaborn as sns
import matplotlib.pyplot as plt
titanic = sns.load_dataset("titanic")
# customize the bar plot
sns.barplot(x="class", y="fare", hue="sex", errorbar=None, palette="muted", data=titanic)
# add labels and title
plt.xlabel("Class")
plt.ylabel("Fare")
plt.title("Average Fare by Class and Gender on the Titanic")
# display the plot
plt.show()Output:
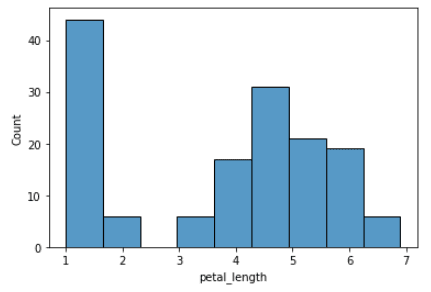
Histogrammen visualiseren de verdeling van een continue variabele. De data wordt verdeeld in bins en de hoogte van elke bin geeft de frequentie of het aantal datapunten binnen die bin weer. In Seaborn maak je histogrammen met de functie histplot(). Onze Seaborn-histogramgids gaat hier dieper op in.
import seaborn as sns
iris = sns.load_dataset("iris")
sns.histplot(x="petal_length", data=iris)Output:
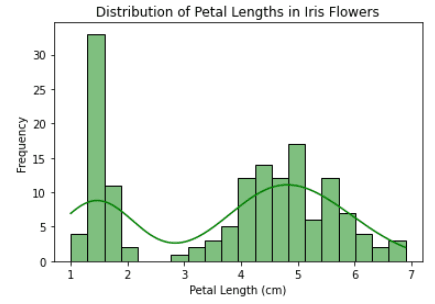
import seaborn as sns
import matplotlib.pyplot as plt
iris = sns.load_dataset("iris")
# customize the histogram
sns.histplot(data=iris, x="petal_length", bins=20, kde=True, color="green")
# add labels and title
plt.xlabel("Petal Length (cm)")
plt.ylabel("Frequency")
plt.title("Distribution of Petal Lengths in Iris Flowers")
# display the plot
plt.show()Output:
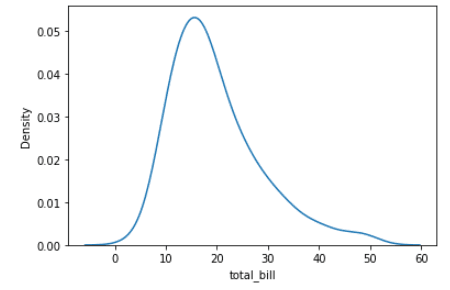
Dichtheidsplots (ook wel kernel density estimate of KDE-plots) tonen de verdeling van een continue variabele als een vloeiende curve in plaats van discrete bins. Ze zijn handig wanneer je verdelingen wilt vergelijken zonder de gevoeligheid voor bin-grootte van histogrammen. In Seaborn maak je ze met kdeplot().
import seaborn as sns
tips = sns.load_dataset("tips")
sns.kdeplot(data=tips, x="total_bill")Output:
Laten we de plot verbeteren door hem aan te passen.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset from Seaborn
tips = sns.load_dataset("tips")
# Create a density plot of the "total_bill" column from the "tips" dataset
# We use the "hue" parameter to differentiate between "lunch" and "dinner" meal times
# We use the "fill" parameter to fill the area under the curve
# We adjust the "alpha" and "linewidth" parameters to make the plot more visually appealing
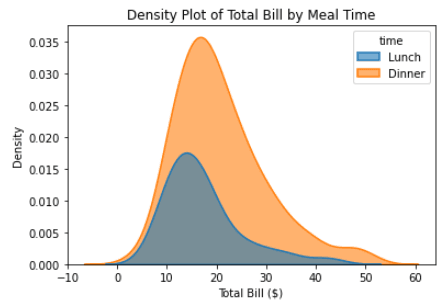
sns.kdeplot(data=tips, x="total_bill", hue="time", fill=True, alpha=0.6, linewidth=1.5)
# Add a title and labels to the plot using Matplotlib
plt.title("Density Plot of Total Bill by Meal Time")
plt.xlabel("Total Bill ($)")
plt.ylabel("Density")
# Show the plot
plt.show()Output:
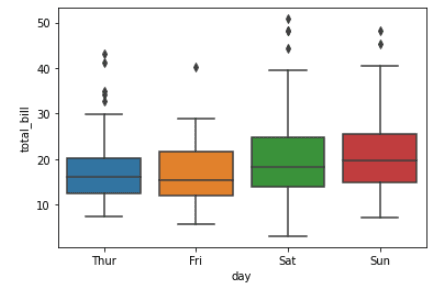
Boxplots zijn een type visualisatie dat de verdeling van een dataset toont. Ze worden vaak gebruikt om de verdeling van één of meer variabelen over verschillende categorieën te vergelijken.
import seaborn as sns
tips = sns.load_dataset("tips")
sns.boxplot(x="day", y="total_bill", data=tips)Output:
Pas de boxplot aan door de kolom `time` uit de dataset toe te voegen.
import seaborn as sns
import matplotlib.pyplot as plt
# load the tips dataset from Seaborn
tips = sns.load_dataset("tips")
# create a box plot of total bill by day and meal time, using the "hue" parameter to differentiate between lunch and dinner
# customize the color scheme using the "palette" parameter
# adjust the linewidth and fliersize parameters to make the plot more visually appealing
sns.boxplot(x="day", y="total_bill", hue="time", data=tips, palette="Set3", linewidth=1.5, fliersize=4)
# add a title, xlabel, and ylabel to the plot using Matplotlib functions
plt.title("Box Plot of Total Bill by Day and Meal Time")
plt.xlabel("Day of the Week")
plt.ylabel("Total Bill ($)")
# display the plot
plt.show()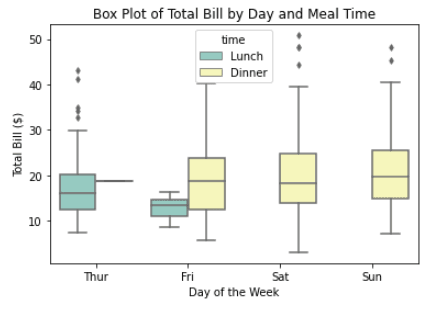
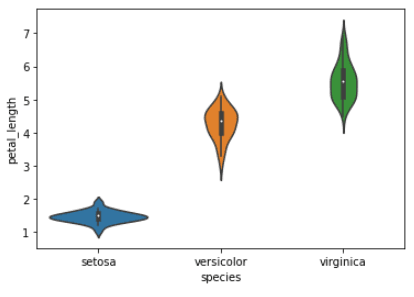
Een violinplot is een type datavisualisatie dat aspecten van zowel boxplots als dichtheidsplots combineert. Het toont een dichtheidsschatting van de data, meestal gesmoothd met een kernel-dichtheidsschatting, samen met het interkwartielbereik (IQR) en de mediaan in een boxplot-achtige vorm.
De breedte van de viool geeft de dichtheidsschatting weer, waarbij bredere delen een hogere dichtheid aangeven, en de IQR en mediaan worden weergegeven als een witte stip en lijn binnen de viool.
import seaborn as sns
import matplotlib.pyplot as plt
iris = sns.load_dataset("iris")
sns.violinplot(x="species", y="petal_length", data=iris)
plt.show()Output:
Een heatmap gebruikt kleuren om waarden in een matrix te representeren. In data-analyse worden heatmaps vaak gebruikt om correlatiematrices te visualiseren. Onze Seaborn-heatmapsgids behandelt geavanceerde aanpassingsopties.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
tips = sns.load_dataset('tips')
# Create a heatmap of the correlation between variables
corr = tips.select_dtypes(include="number").corr()
sns.heatmap(corr, annot=True, cmap="coolwarm")
# Show the plot
plt.show()Output:

Nog een voorbeeld van een heatmap met de `flights`-dataset.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
flights = sns.load_dataset('flights')
# Pivot the data
flights = flights.pivot(index="month", columns="year", values="passengers")
# Create a heatmap
sns.heatmap(flights, cmap='Blues', annot=True, fmt='d')
# Set the title and axis labels
plt.title('Passengers per month')
plt.xlabel('Year')
plt.ylabel('Month')
# Show the plot
plt.show()Output:
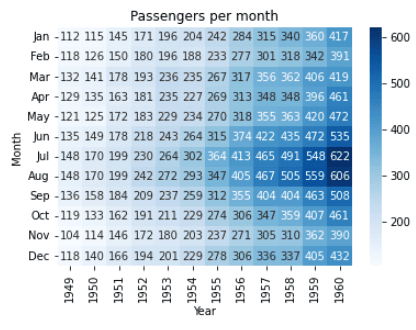
In dit voorbeeld gebruiken we de `flights`-dataset uit de `seaborn`-bibliotheek. We pivotten de data om deze geschikt te maken voor een heatmapweergave met de methode .pivot(). Daarna maken we een heatmap met de functie sns.heatmap() en geven we de gepivotte flights-variabele door als argument.
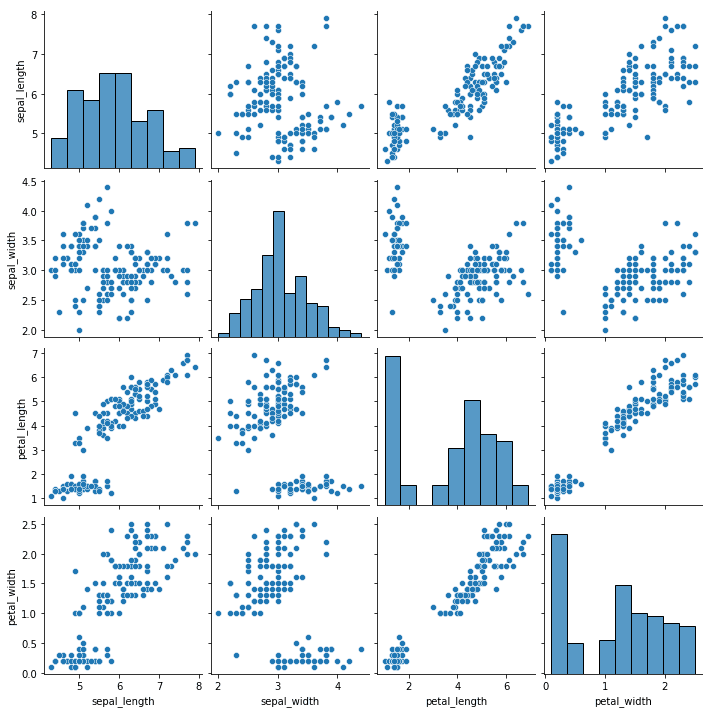
Pairplots zijn een type visualisatie waarin meerdere paarsgewijze scatterplots in een matrix worden weergegeven. Elke scatterplot toont de relatie tussen twee variabelen, terwijl de diagonale plots de verdeling van de individuele variabelen tonen.
import seaborn as sns
# Load iris dataset
iris = sns.load_dataset("iris")
# Create pair plot
sns.pairplot(data=iris)
# Show plot
plt.show()Output:
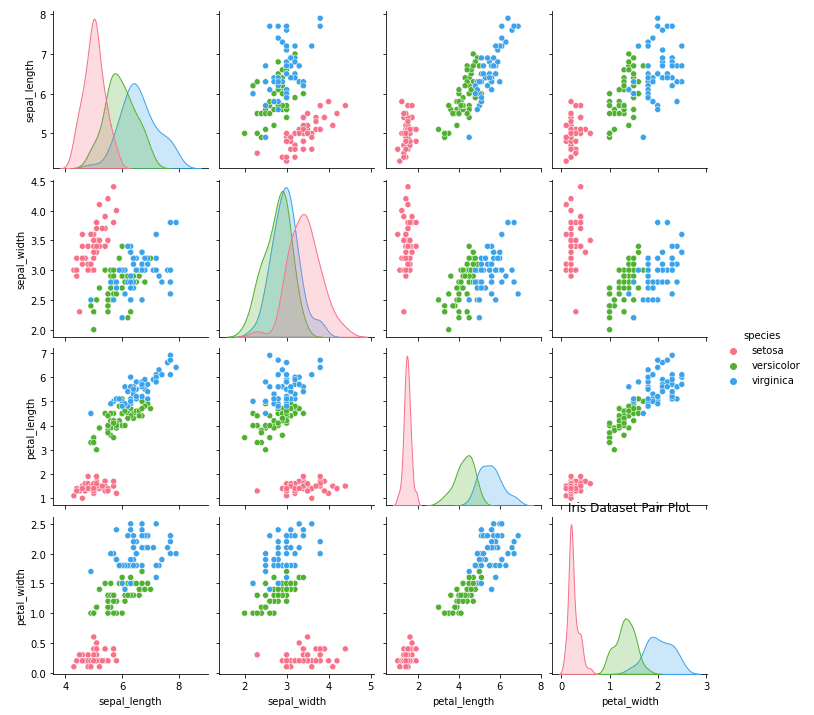
We kunnen deze plot aanpassen met de parameters `hue` en `diag_kind`.
import seaborn as sns
import matplotlib.pyplot as plt
# Load iris dataset
iris = sns.load_dataset("iris")
# Create pair plot with custom settings
sns.pairplot(data=iris, hue="species", diag_kind="kde", palette="husl")
# Set title
plt.title("Iris Dataset Pair Plot")
# Show plot
plt.show()Output:
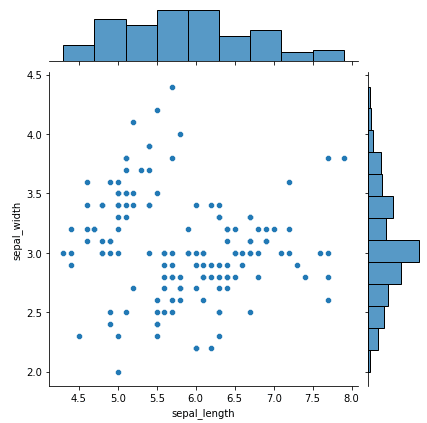
Een jointplot combineert een scatterplot (midden) met marginale histogrammen (boven- en rechterrand) in één figuur. Deze lay-out toont zowel de relatie tussen twee variabelen als hun individuele verdelingen in één oogopslag.
Hier is een eenvoudig voorbeeld van een seaborn-jointplot met de iris-dataset:
import seaborn as sns
import matplotlib.pyplot as plt
# load iris dataset
iris = sns.load_dataset("iris")
# plot a joint plot of sepal length and sepal width
sns.jointplot(x="sepal_length", y="sepal_width", data=iris)
# display the plot
plt.show()Output:
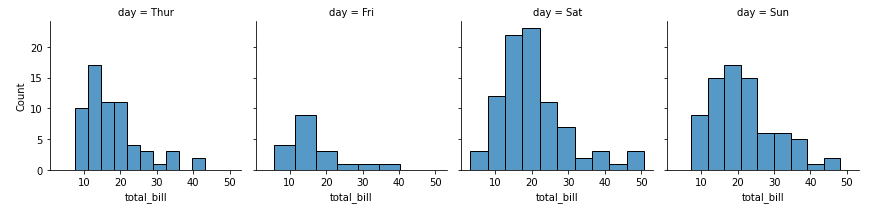
FacetGrid maakt een raster van subplots—één per unieke waarde in een categorische variabele. Zo kun je dezelfde plot per groep vergelijken (bijv. total-bill-verdelingen voor elke dag van de week).
import seaborn as sns
# load the tips dataset
tips = sns.load_dataset('tips')
# create a FacetGrid for day vs total_bill
g = sns.FacetGrid(tips, col="day")
# plot histogram for total_bill in each day
g.map(sns.histplot, "total_bill")Output:
|
Python Seaborn Cheat Sheet |
Seaborn biedt vijf ingebouwde thema's die de algehele look van je plots bepalen. Roep sns.set_theme() bovenaan je script aan om er één globaal toe te passen:
import seaborn as sns
sns.set_theme(style="whitegrid") # options: darkgrid, whitegrid, dark, white, ticksJe kunt ook de schaal van plotelementen regelen met de parameter context. Dit past lettergroottes, lijndiktes en andere elementen aan voor verschillende outputformaten:
sns.set_theme(style="whitegrid", context="talk") # options: paper, notebook, talk, posterDe context "notebook" (de standaard) werkt goed voor Jupyter-notebooks, terwijl "talk" en "poster" alles opschalen voor presentaties.
Naast de standaardstyling geeft Seaborn je controle over kleurpaletten, figuurformaten, thema's en annotaties. Dit zijn de meest voorkomende aanpassingen:
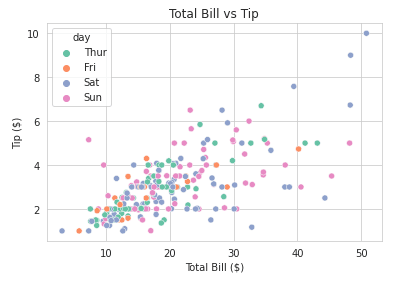
Hier is een voorbeeld van hoe je de kleurpaletten van je seaborn-plots kunt wijzigen:
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
tips = sns.load_dataset("tips")
# Create a scatter plot with color palette
sns.scatterplot(x="total_bill", y="tip", hue="day", data=tips, palette="Set2")
# Customize plot
plt.title("Total Bill vs Tip")
plt.xlabel("Total Bill ($)")
plt.ylabel("Tip ($)")
plt.show()Output:
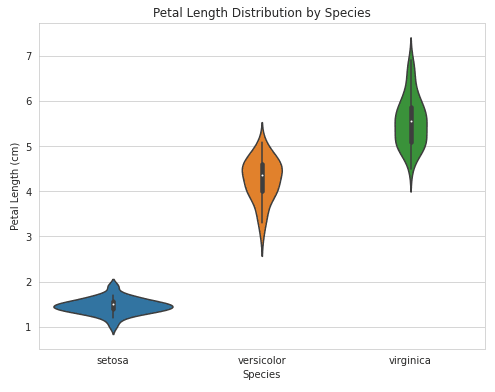
Om het figuurformaat van je seaborn-plots aan te passen, kun je onderstaand voorbeeld als leidraad gebruiken:
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
iris = sns.load_dataset("iris")
# Create a violin plot with adjusted figure size
plt.figure(figsize=(8,6))
sns.violinplot(x="species", y="petal_length", data=iris)
# Customize plot
plt.title("Petal Length Distribution by Species")
plt.xlabel("Species")
plt.ylabel("Petal Length (cm)")
plt.show()Output:
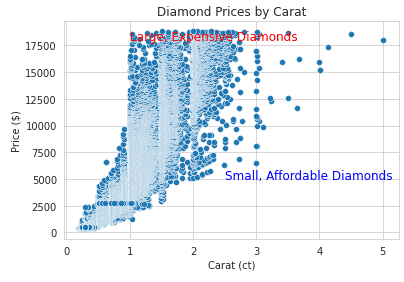
Annotaties kunnen je visualisaties beter leesbaar maken. Hieronder een voorbeeld van hoe je ze toevoegt:
import seaborn as sns
import matplotlib.pyplot as plt
# Load sample dataset
diamonds = sns.load_dataset("diamonds")
# Create a scatter plot with annotations
sns.scatterplot(x="carat", y="price", data=diamonds)
# Add annotations
plt.text(1, 18000, "Large, Expensive Diamonds", fontsize=12, color="red")
plt.text(2.5, 5000, "Small, Affordable Diamonds", fontsize=12, color="blue")
# Customize plot
plt.title("Diamond Prices by Carat")
plt.xlabel("Carat (ct)")
plt.ylabel("Price ($)")
plt.show()Output:
Hier zijn een paar best practices om in gedachten te houden om het meeste uit Seaborn te halen.
Seaborn biedt een breed scala aan plottypen, elk ontworpen voor verschillende soorten data en analyses. Het is belangrijk het juiste plottype voor je data te kiezen om je bevindingen effectief te communiceren. Een scatterplot is bijvoorbeeld geschikter om de relatie tussen twee continue variabelen te visualiseren, terwijl een staafdiagram beter past bij categorische data.
Kleur kan een krachtig hulpmiddel zijn bij datavisualisatie, maar gebruik het wel doordacht. Vermijd te veel of te felle kleuren, want dat maakt de visualisatie moeilijk leesbaar. Gebruik kleur in plaats daarvan om belangrijke informatie te benadrukken of om vergelijkbare datapunten te groeperen.
Labels en titels zijn essentieel voor effectieve datavisualisatie. Label je assen duidelijk en geef je visualisatie een beschrijvende titel. Zo begrijpt je publiek beter welke boodschap je wilt overbrengen.
Houd bij het maken van visualisaties rekening met je publiek en de boodschap die je wilt communiceren. Is je publiek niet technisch, gebruik dan duidelijke en beknopte taal, vermijd jargon en leg statistische concepten helder uit.
Seaborn biedt diverse statistische functies die je kunt gebruiken om je data te analyseren. Kies een statistische functie die past bij je data en onderzoeksvraag.
Je vindt in Seaborn veel aanpassingsopties om je visualisaties te verbeteren. Experimenteer met verschillende lettertypes, stijlen en kleuren om te vinden wat jouw boodschap het best overbrengt.
Voortbouwend op wat we hebben vastgesteld, bekijken we hoe Seaborn zich verhoudt tot Matplotlib en twee andere alternatieven die je tegenkomt, en welke bibliotheek bij welke use-case past:
| Library | Strengths | Limitations | Best for |
|---|---|---|---|
| Matplotlib | Volledige controle over elk figuurelement | Uitvoerig; geen ingebouwde statistiek | Aangepaste, publicatiewaardige figuren |
pandas .plot() |
Snelle plots vanuit DataFrames zonder extra imports | Beperkte grafiektypen; minimale styling | Snelle exploratieve checks |
| Plotly | Interactief; in te bedden op het web; 3D-ondersteuning | Zwaardere dependency; leercurve voor aanpassing | Dashboards, webapps, interactieve rapporten |
| Seaborn | Statistische defaults; duidelijke API; pandas-integratie | Alleen statisch; minder flexibel dan pure Matplotlib | Exploratieve data-analyse, statistische plots |
Voor de meeste data-analyse gebruik ik Seaborn voor de eerste verkenning, Matplotlib voor het fine-tunen en Plotly wanneer de output interactief moet zijn. Ze sluiten elkaar niet uit.
Seaborn is een krachtige bibliotheek voor datavisualisatie in Python die een intuïtieve en gebruiksvriendelijke interface biedt voor het maken van informatieve statistische grafieken. Met het brede scala aan visualisatietools kun je met Seaborn snel en efficiënt inzichten uit complexe datasets verkennen en communiceren.
Van scatterplots en lijndiagrammen tot heatmaps en facetgrids: Seaborn biedt een breed palet aan visualisaties voor verschillende behoeften. Bovendien maakt Seaborns integratie met Pandas en Numpy het een onmisbaar hulpmiddel voor data-analisten en -scientists.
Met deze beginnersgids voor Python Seaborn kun je de wereld van datavisualisatie verkennen en je inzichten effectief communiceren naar een breder publiek.
Wil je je kennis verder verdiepen, bekijk dan onze cursussen Introduction to Data Visualization with Seaborn of Intermediate Data Visualization with Seaborn.
In deze cursussen leer je hoe je Seaborns geavanceerde visualisatietools inzet om uiteenlopende echte datasets te analyseren, zoals de American Housing Survey, collegegelddata en gasten van The Daily Show.
Bekijk ook onze gratis Seaborn-cheatsheet.
Leer Python met DataCamp!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
