Programa
Desenvolvedor Python
28 h
Para qualquer cientista de dados ou engenheiro de software, a capacidade de mapear eficientemente relacionamentos entre pontos de dados é uma habilidade inegociável. Se você está analisando respostas JSON complexas de uma API, agregando estatísticas de um conjunto de dados massivo ou simplesmente configurando definições de aplicativos, o dicionário é, sem dúvida, a ferramenta mais poderosa do Python. Ele impulsiona uma manipulação de dados limpa, legível e altamente otimizada.
Embora qualquer pessoa possa consultar um valor em um dicionário, a verdadeira experiência aparece quando você sabe como aplicar seus métodos aos seus fluxos de trabalho de dados e desbloquear padrões avançados.
Neste artigo, veremos as tabelas hash que tornam os dicionários tão rápidos, métodos essenciais de dicionário, estratégias de tratamento de erros e técnicas de otimização de desempenho.
Se você é novo em dicionários, recomendo a leitura do nosso tutorial fundamental Dicionário Python como um bom ponto de partida.
Os dicionários Python são uma estrutura de dados integrada projetada para consultas rápidas e flexíveis. Eles permitem armazenar e recuperar valores usando chaves significativas em vez de posições numéricas, o que os torna ideais para representar dados estruturados do mundo real. Vamos analisar sua estrutura e propriedades principais.
Antes de entrarmos nos detalhes dos métodos de dicionário do Python, ajuda entender como os dicionários são construídos sobre tabelas hash. Muitos dos erros que você encontrará, como TypeError: unhashable type, vêm diretamente da maneira como essa estrutura funciona.
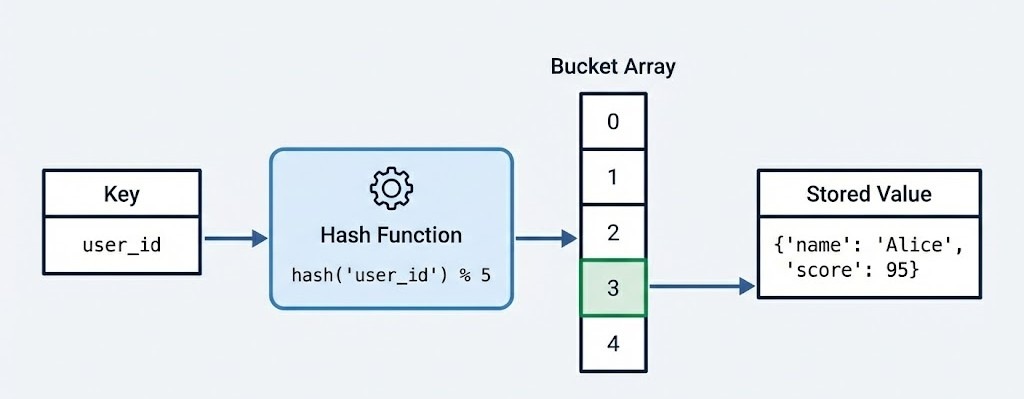
Em um nível estrutural, um dicionário Python implementa uma tabela hash. Essa escolha arquitetônica é o que confere ao dicionário sua velocidade e versatilidade. Quando você define um dicionário, você está essencialmente criando um array esparso, frequentemente chamado de array de buckets.
Quando você insere um par chave-valor, o Python passa a chave por uma função hash. Essa função calcula um número inteiro único (o hash) que determina o índice específico no array de buckets onde o valor será armazenado.
Devido a esse design:
As chaves devem ser hashable, o que geralmente significa que devem ser de um tipo imutável (por exemplo, str, int, tuple)
Os valores podem ser mutáveis, incluindo listas, outros dicionários ou objetos personalizados
Consultas, inserções e exclusões ocorrem em tempo médio amortizado O(1)
O exemplo a seguir mostra algumas chaves válidas, mas também demonstra que uma lista não é aceita como chave de dicionário:
# Valid dictionary - immutable keys, any values
user_data = {
"name": "Alice", # string key, string value
42: [1, 2, 3], # integer key, list value
(10, 20): {"nested": True} # tuple key, dict value
}
print(type(user_data), "valid dict")
# Invalid - will raise TypeError
try:
invalid_dict = {[1, 2]: "value"} # lists are not hashable
except TypeError as e:
print(f"Error: {e}")<class 'dict'> valid dict
Error: unhashable type: 'list'Essa estrutura é importante para o desempenho. Enquanto pesquisar um item em uma lista requer iterar pelos elementos um por um, uma operação O(n), recuperar um valor de um dicionário é uma operação O(1) em média.
Isso significa que procurar um ID de usuário em um conjunto de dados de um milhão de usuários leva aproximadamente o mesmo tempo que procurá-lo em um conjunto de dados de dez usuários. Entender as diferenças entre tipos de dados em Python é fundamental para escolher a estrutura certa para o seu caso de uso.
Uma das mudanças mais significativas na história do Python ocorreu na versão 3.7. Antes disso, os dicionários eram considerados coleções não ordenadas, e iterar sobre eles podia produzir chaves em sequências aparentemente aleatórias. Se você imprimisse um dicionário, os itens poderiam aparecer em uma ordem diferente da que você os inseriu, dependendo dos valores hash e do histórico interno do array.
No entanto, a partir do Python 3.6, os dicionários começaram a preservar a ordem de inserção como um detalhe de implementação no CPython. Então, começando com o Python 3.7 (e oficialmente garantido na especificação da linguagem), os dicionários preservam a ordem de inserção.
Essa mudança de mapeamentos não ordenados para ordenados tem algumas implicações importantes para o desenvolvimento moderno em Python. Por exemplo, a serialização JSON agora produz uma saída previsível, o que facilita a depuração e garante a reprodutibilidade dos dados em diferentes execuções.
Se você trabalha com pipelines de dados onde a ordem importa, como processar eventos de séries temporais ou manter hierarquias de configuração, essa garantia elimina toda uma classe de bugs sutis. A seguir, vamos ver como criar um dicionário.
Embora criar um dicionário pareça simples, o método que você escolhe pode impactar tanto a legibilidade quanto o desempenho do seu código. O Python oferece várias maneiras de inicialização, que variam de literais simples a técnicas avançadas de geração programática para fluxos de trabalho de ciência de dados. Vamos analisar as formas mais importantes.
A maneira mais comum e preferida de criar um dicionário é usando a sintaxe de chaves {}. Essa notação literal não é apenas mais legível, mas também mais rápida do que métodos alternativos. O Python pode otimizar a construção do bytecode diretamente sem a sobrecarga de uma chamada de função. Abaixo está o código mostrando um dicionário:
# Preferred: Literal syntax
user_profile = {
"name": "Alice",
"role": "Data Scientist",
"active": True
}
user_profile{'name': 'Alice', 'role': 'Data Scientist', 'active': True}No entanto, o construtor dict() é indispensável em alguns cenários. Ele atua como um conversor de tipo, permitindo que você crie dicionários a partir de sequências de tuplas ou argumentos de palavra-chave. É particularmente útil nestes casos específicos:
# Using keyword arguments (cleaner for string keys)
config = dict(host="localhost", port=8080, debug=True)
print(config)
# Converting a list of tuples (common in data processing)
pairs = [("a", 1), ("b", 2), ("c", 3)]
lookup_table = dict(pairs)
print(lookup_table){'host': 'localhost', 'port': 8080, 'debug': True}
{'a': 1, 'b': 2, 'c': 3}Para cenários de criação de dicionário mais complexos, as comprehensions de dicionário oferecem uma maneira concisa e eficiente de filtrar, transformar ou gerar pares chave-valor programaticamente. É uma técnica essencial para qualquer profissional de dados que precise processar e remodelar dados dinamicamente.
As comprehensions são vitais para tarefas como:
Vamos ver como criar uma comprehension de dicionário abaixo:
# Classic use case: Creating a squares map
squares = {x: x**2 for x in range(5)}
print(squares)
# Filtering data during creation
raw_data = {"a": 10, "b": None, "c": 5}
clean_data = {k: v for k, v in raw_data.items() if v is not None}
print(clean_data){0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
{'a': 10, 'c': 5}Se você quiser se aprofundar, recomendo que leia nosso tutorial Comprehension de Dicionário Python.
Outro método de dicionário Python útil para inicialização é dict.fromkeys(). Este método cria um novo dicionário com chaves especificadas e um único valor. É frequentemente usado para inicializar contadores ou sinalizadores de status.
# Initialize multiple keys with the same default value
categories = ["electronics", "clothing", "food", "books"]
inventory = dict.fromkeys(categories, 0)
print(inventory)
# Initialize with None for optional fields
user_fields = ["email", "phone", "address", "company"]
user_profile = dict.fromkeys(user_fields)
print(user_profile){'electronics': 0, 'clothing': 0, 'food': 0, 'books': 0}
{'email': None, 'phone': None, 'address': None, 'company': None}Ao usar .fromkeys() com objetos mutáveis como listas ou dicionários, todas as chaves farão referência ao mesmo objeto na memória. Isso cria uma armadilha de "referência compartilhada" que pode levar a comportamentos inesperados. Vamos ver isso com um exemplo:
# DANGEROUS - all keys share the same list!
categories = ["A", "B", "C"]
wrong_way = dict.fromkeys(categories, [])
wrong_way["A"].append(1)
print(wrong_way)
# CORRECT - use dictionary comprehension for independent lists
right_way = {cat: [] for cat in categories}
right_way["A"].append(1)
print(right_way){'A': [1], 'B': [1], 'C': [1]}
{'A': [1], 'B': [], 'C': []}Podemos ver que o mesmo valor foi compartilhado por todas as chaves no primeiro caso. Para evitar isso, precisamos usar uma comprehension de dicionário para listas independentes.
Uma vez criado um dicionário, interagir com os dados armazenados dentro dele é uma das tarefas de programação diárias mais comuns. Vamos analisar algumas dessas maneiras.
Existem algumas maneiras diferentes de acessar valores.
A maneira mais direta de recuperar um valor de um dicionário é através da notação de colchetes d[key], que retorna o valor associado se a chave existir. Essa abordagem é ideal quando você tem certeza de que a chave está presente no seu dicionário. Abaixo está o código para fazer isso:
product = {
"name": "Laptop",
"price": 1299.99,
"stock": 45,
"category": "Electronics"
}
# Direct access with brackets
print(product["name"])
print(product["price"])
# Attempting to access a non-existent key raises KeyError
try:
print(product["manufacturer"])
except KeyError as e:
print(f"Key not found: {e}")Laptop
1299.99
Key not found: 'manufacturer'Para uma recuperação mais segura quando a existência da chave é incerta, o método .get() oferece uma solução elegante. Ele retorna None (ou um valor padrão especificado) em vez de levantar uma exceção se a chave não existir.
# Safe retrieval with .get()
manufacturer = product.get("manufacturer")
print(manufacturer) # None
# Provide a custom default value
warranty = product.get("warranty", "No warranty information")
print(warranty)
# .get() is especially useful in data pipelines
customer_data = {"name": "John Doe", "email": "[email protected]"}
phone = customer_data.get("phone", "Not provided")
print(phone)
address = customer_data.get("address", "Not provided")
print(address)None
No warranty information
Not provided
Not providedO método .setdefault() combina recuperação e inserção em uma única operação. Ele recupera um valor se a chave existir, ou insere um valor padrão e o retorna se a chave estiver ausente, o que é perfeito para padrões de acumulação.
# Using .setdefault() for initialization and retrieval
page_visits = {}
# First visit to 'home' - inserts 0 and returns it
count = page_visits.setdefault("home", 0)
print(count)
page_visits["home"] += 1
# Subsequent call returns existing value
count = page_visits.setdefault("home", 0)
print(count)
# Practical example: grouping items
inventory = [
("apple", "fruit"),
("carrot", "vegetable"),
("banana", "fruit"),
("broccoli", "vegetable")
]
grouped = {}
for item, category in inventory:
grouped.setdefault(category, []).append(item)
print(grouped)0
1
{'fruit': ['apple', 'banana'], 'vegetable': ['carrot', 'broccoli']}Os dicionários são dinâmicos; você frequentemente precisará adicionar ou remover dados conforme seu programa é executado.
Adicionar um único par é tão simples quanto a atribuição (d['new'] = 1), mas para operações em massa, o método .update() é superior. Ele aceita outro dicionário ou um iterável de pares chave-valor e os mescla ao objeto existente.
Vamos ver como usar o método .update():
# Simple assignment for single key-value pairs
user = {"username": "alice_2024", "role": "analyst"}
user["email"] = "[email protected]" # Add new key
user["role"] = "senior_analyst" # Update existing key
# Bulk update with .update()
user.update({"department": "Analytics", "level": 3})
print(user)
# Update from sequence of tuples
additional_info = [("projects", 12), ("rating", 4.8)]
user.update(additional_info)
print(user)
# Update with keyword arguments
user.update(active=True, certified=True)
print(user){'username': 'alice_2024', 'role': 'senior_analyst', 'email': '[email protected]', 'department': 'Analytics', 'level': 3}
{'username': 'alice_2024', 'role': 'senior_analyst', 'email': '[email protected]', 'department': 'Analytics', 'level': 3, 'projects': 12, 'rating': 4.8}
{'username': 'alice_2024', 'role': 'senior_analyst', 'email': '[email protected]', 'department': 'Analytics', 'level': 3, 'projects': 12, 'rating': 4.8, 'active': True, 'certified': True}Para um passo a passo detalhado sobre como adicionar itens, recomendo que leia este guia sobre Append em Dicionário Python.
O Python oferece três métodos distintos para remover entradas de dicionário, cada um com comportamento e casos de uso diferentes:
.pop(key): Remove a chave e retorna seu valor. Isso é útil quando você precisa usar o dado uma última vez antes de excluí-lo.
.popitem(): Remove e retorna o último par chave-valor inserido (LIFO). Este é um benefício direto da natureza ordenada dos dicionários modernos.
del d[key]: exclui puramente a chave. Ele não retorna o valor e é ligeiramente mais rápido se o valor de retorno não for necessário.
Vamos ver exemplos desses métodos:
Método .pop():
scores = {"Alice": 95, "Bob": 87, "Carol": 92, "David": 78}
# .pop() - removes key and returns its value
alice_score = scores.pop("Alice")
print(alice_score)
print(scores) 95
{'Bob': 87, 'Carol': 92, 'David': 78}Método .popitem():
# .popitem() - removes and returns last inserted pair (LIFO in Python 3.7+)
scores = {"Alice": 95, "Bob": 87, "Carol": 92, "David": 78}
last_item = scores.popitem()
print(last_item)
print(scores)('David', 78)
{'Alice': 95, 'Bob': 87, 'Carol': 92}del:
# del statement - removes key without returning value
scores = {"Alice": 95, "Bob": 87, "Carol": 92, "David": 78}
del scores["Bob"]
print(scores){'Alice': 95, 'Carol': 92, 'David': 78}O método .clear() esvazia todo o dicionário, deixando você com um objeto {} vazio. Isso é diferente de excluir a própria variável. O objeto permanece na memória, apenas vazio. Vamos ver como esse método funciona:
# .clear() - removes all items but keeps the dictionary object
scores = {"Alice": 95, "Bob": 87, "Carol": 92, "David": 78}
scores.clear()
print(scores)
print(type(scores)){}
<class 'dict'>A distinção entre esses métodos é importante. Use .pop() quando precisar do valor removido, .popitem() para comportamento tipo pilha, del para remoção simples e .clear() para redefinir um dicionário preservando sua identidade.
Em versões mais antigas do Python 2, métodos como .keys() retornavam uma lista estática. Nas versões atuais do Python (3.x), eles retornam objetos de visualização (view objects). As visualizações são janelas dinâmicas para o dicionário. Se o dicionário mudar, a visualização reflete essas mudanças instantaneamente sem precisar ser chamada novamente.
Você pode iterar através de chaves (.keys()), valores (.values()) ou ambos simultaneamente usando .items(). Vamos ver esses métodos com um exemplo:
experiment = {
"model": "RandomForest",
"accuracy": 0.94,
"precision": 0.91,
"recall": 0.89
}
# .keys() returns a view of all keys
print(experiment.keys())
# .values() returns a view of all values
print(experiment.values())
# .items() returns (key, value) tuples - most commonly used
for metric, value in experiment.items():
if isinstance(value, float):
print(f"{metric}: {value:.2%}")dict_keys(['model', 'accuracy', 'precision', 'recall'])
dict_values(['RandomForest', 0.94, 0.91, 0.89])
accuracy: 94.00%
precision: 91.00%
recall: 89.00%A natureza dinâmica dos objetos de visualização significa que eles refletem automaticamente as alterações feitas no dicionário após a criação da visualização. Vamos ver um exemplo:
metrics = {"MAE": 0.23, "RMSE": 0.45}
keys_view = metrics.keys()
print(keys_view)
# Add new metric
metrics["R2"] = 0.87
print(keys_view)dict_keys(['MAE', 'RMSE'])
dict_keys(['MAE', 'RMSE', 'R2'])Um recurso poderoso dos objetos de visualização é que eles suportam operações de conjunto. Você pode executá-las diretamente nas visualizações de chaves para comparar dois dicionários de forma eficiente usando estes operadores:
Interseção: &
União: |
Diferença: -
Diferença simétrica/XOR: ^
Vamos ver um exemplo:
dict1 = {"a": 1, "b": 2, "c": 3}
dict2 = {"b": 20, "c": 30, "d": 4}
# Find common keys (intersection)
common_keys = dict1.keys() & dict2.keys()
print(common_keys)
# Find all unique keys (union)
all_keys = dict1.keys() | dict2.keys()
print(all_keys)
# Find keys in dict1 but not in dict2 (difference)
unique_to_dict1 = dict1.keys() - dict2.keys()
print(unique_to_dict1)
# Symmetric difference - keys in either but not both
exclusive_keys = dict1.keys() ^ dict2.keys()
print(exclusive_keys){'b', 'c'}
{'b', 'c', 'd', 'a'}
{'a'}
{'d', 'a'}Essas operações de conjunto baseadas em visualização são muito mais eficientes em termos de memória do que converter dicionários em conjuntos explicitamente, especialmente ao trabalhar com grandes conjuntos de dados.
Como os dicionários são frequentemente usados como a interface principal para dados externos, como payloads JSON de APIs ou arquivos de configuração, eles são uma fonte comum de erros em tempo de execução. Escrever código robusto requer mais do que apenas saber como acessar dados. Requer saber como lidar com sua ausência.
O erro de dicionário mais comum é KeyError, que ocorre ao tentar acessar uma chave que não existe. O Python oferece duas abordagens filosóficas para lidar com isso:
O padrão EAFP é considerado mais Pythonico e geralmente tem melhor desempenho quando as chaves geralmente existem, pois evita verificações redundantes. Ele usa blocos try-except para lidar com erros após eles ocorrerem, assumindo que as operações geralmente serão bem-sucedidas. Vamos ver como isso funciona:
# EAFP approach - try first, handle exceptions
user_data = {"username": "data_analyst", "email": "[email protected]"}
try:
phone = user_data["phone"]
print(f"Phone: {phone}")
except KeyError:
print("Phone number not available")
phone = None
# More sophisticated error handling with specific actions
config = {"host": "localhost", "port": 5432}
try:
database = config["database"]
except KeyError:
print("Warning: Database not specified, using default")
database = "default_db"
config["database"] = database # Add missing configurationPhone number not available
Warning: Database not specified, using defaultNo entanto, existem cenários onde falhar ruidosamente, permitindo que o KeyError se propague, é na verdade preferível a falhas silenciosas. Na abordagem LBYL, você verifica explicitamente a existência da chave antes de acessá-la. Vamos ver um exemplo:
# Critical configuration - fail loudly if missing
required_config = {"api_key": "secret123", "endpoint": "api.example.com"}
def initialize_api(config):
# Don't catch KeyError - we WANT the program to crash if required keys are missing
api_key = config["api_key"]
endpoint = config["endpoint"]
timeout = config.get("timeout", 30) # Optional with default
return {"key": api_key, "endpoint": endpoint, "timeout": timeout}Invocar esta função levantará KeyError se qualquer chave no dicionário estiver ausente, o que é o comportamento correto porque é melhor falhar durante a inicialização do que silenciosamente durante a produção.
Ao processar dados de fontes externas como APIs ou entrada do usuário, o tratamento de erro explícito torna-se importante. Vamos ver como fazer isso com um exemplo:
# Processing API response with defensive error handling
def extract_user_info(api_response):
"""Extract user information with comprehensive error handling."""
user_info = {}
try:
user_info["id"] = api_response["user"]["id"]
user_info["name"] = api_response["user"]["profile"]["name"]
except KeyError as e:
print(f"Missing required field in API response: {e}")
return None
# Optional fields - use .get() with defaults
user_info["email"] = api_response.get("user", {}).get("contact", {}).get("email", "N/A")
user_info["verified"] = api_response.get("user", {}).get("verified", False)
return user_info
# Example usage
response = {
"user": {
"id": 12345,
"profile": {"name": "Jane Smith"},
"verified": True
}
}
user = extract_user_info(response)
print(user){'id': 12345, 'name': 'Jane Smith', 'email': 'N/A', 'verified': True}Entender quando usar .get() versus notação de colchetes versus try-except é importante.
A abordagem LBYL usa declarações condicionais usando os operadores in e not in para verificar a existência da chave antes de tentar o acesso. Esse padrão é mais claro ao lidar com lógica condicional ou quando você precisa tomar ações diferentes com base na presença da chave. Vamos ver um exemplo disso:
# Proactive checking with 'in' operator
student_grades = {
"Alice": 95,
"Bob": 87,
"Carol": 92
}
# Check before access
student_name = "David"
if student_name in student_grades:
print(f"{student_name}'s grade: {student_grades[student_name]}")
else:
print(f"No grade recorded for {student_name}")
# Conditional update based on existence
if "David" not in student_grades:
student_grades["David"] = 0 # Initialize new student
print("New student added to grading system")
# Multiple key checks for validation
required_fields = ["name", "email", "department"]
employee_record = {"name": "John Doe", "email": "[email protected]"}
missing_fields = [field for field in required_fields if field not in employee_record]
if missing_fields:
print(f"Error: Missing required fields: {missing_fields}")
else:
print("All required fields present")No grade recorded for David
New student added to grading system
Error: Missing required fields: ['department']Ao validar dicionários derivados de fontes externas, como JSON de APIs, arquivos CSV ou entrada do usuário, o teste de associação proativo fornece uma lógica de validação clara e legível. Vamos ver isso com um exemplo:
# Validating API response structure
def validate_product_data(product):
"""Validate product dictionary has all required fields."""
required = ["id", "name", "price", "category"]
optional = ["description", "stock", "manufacturer"]
# Check all required fields exist
for field in required:
if field not in product:
raise ValueError(f"Missing required field: {field}")
# Validate data types for existing fields
if "price" in product and not isinstance(product["price"], (int, float)):
raise TypeError("Price must be a number")
if "stock" in product and product["stock"] < 0:
raise ValueError("Stock cannot be negative")
return True
# Example usage with proper error handling
product_from_api = {
"id": 101,
"name": "Wireless Mouse",
"price": 29.99,
"category": "Electronics",
"stock": 150
}
try:
if validate_product_data(product_from_api):
print("Product data validated successfully")
# Proceed with processing
except (ValueError, TypeError) as e:
print(f"Validation failed: {e}")Product data validated successfullyA escolha entre EAFP e LBYL geralmente depende do seu caso de uso. Use EAFP quando as operações geralmente forem bem-sucedidas e as exceções forem raras. Use LBYL quando precisar de lógica de ramificação explícita ou ao validar a entrada antes de operações dispendiosas.
Antes de iterar sobre um dicionário derivado de uma fonte externa, é uma boa prática:
Seguindo essas práticas, você pode tornar seu código muito mais robusto ao lidar com dados imprevisíveis ou incompletos de APIs, entrada do usuário ou arquivos de configuração.
Para um olhar mais profundo sobre como escrever código Python resiliente, recomendo fazer nosso curso sobre Escrevendo Código Python Eficiente.
À medida que seus projetos de ciência de dados crescem em complexidade, você frequentemente precisará combinar, copiar e transformar dicionários. Aprender essas operações avançadas permite que você manipule estruturas de dados de forma eficiente, evitando bugs sutis que podem descarrilar pipelines. Vamos ver alguns desses métodos.
O Python 3.9 introduziu operadores de união elegantes para mesclar dicionários:
| (operador de mesclagem): Cria um novo dicionário mesclado.
|= (operador de atualização): Atualiza um dicionário existente no local.
Esses operadores fornecem uma sintaxe limpa e legível para combinar dados de várias fontes. Vamos ver um exemplo:
# Union operator | creates a new merged dictionary
defaults = {"theme": "light", "language": "en", "notifications": True}
user_prefs = {"theme": "dark", "font_size": 14}
final_config = defaults | user_prefs
print(final_config)
# Update operator |= modifies in place
settings = {"auto_save": True, "theme": "light"}
settings |= {"theme": "dark", "font_size": 12}
print(settings){'theme': 'dark', 'language': 'en', 'notifications': True, 'font_size': 14}
{'auto_save': True, 'theme': 'dark', 'font_size': 12}Para versões do Python anteriores à 3.9, o método de desempacotamento de estrela dupla (**) fornece funcionalidade semelhante:
# Double-star unpacking
base_config = {"host": "localhost", "port": 5432, "ssl": False}
override_config = {"port": 5433, "ssl": True, "timeout": 30}
# Merge using unpacking
merged = {**base_config, **override_config}
print(merged)
# Multiple dictionary merge
db_config = {"database": "analytics"}
auth_config = {"username": "admin", "password": "secret"}
pool_config = {"pool_size": 10, "max_overflow": 20}
complete_config = {**db_config, **auth_config, **pool_config}
print(complete_config){'host': 'localhost', 'port': 5433, 'ssl': True, 'timeout': 30}
{'database': 'analytics', 'username': 'admin', 'password': 'secret', 'pool_size': 10, 'max_overflow': 20}Em todas as técnicas de mesclagem, a regra é simples: o último visto vence. O valor do dicionário à direita substitui o da esquerda se as chaves colidirem:
dict1 = {"a": 1, "b": 2, "c": 3}
dict2 = {"b": 20, "c": 30, "d": 4}
dict3 = {"c": 300, "e": 5}
result = dict1 | dict2 | dict3
print(result)
result2 = {**dict1, **dict2, **dict3}
print(result2)
# Order matters - reversing changes the result
result3 = dict3 | dict2 | dict1
print(result3){'a': 1, 'b': 20, 'c': 300, 'd': 4, 'e': 5}
{'a': 1, 'b': 20, 'c': 300, 'd': 4, 'e': 5}
{'c': 3, 'e': 5, 'b': 2, 'd': 4, 'a': 1}Esse comportamento é consistente, quer você use |, |=, desempacotamento ou o método .update(). A ordem importa, tornando-o especialmente útil para gerenciamento de configuração em camadas (por exemplo, padrões do sistema < configurações de ambiente < substituições do usuário).
Uma das armadilhas mais perigosas é não entender como o Python lida com atribuições de variáveis.
dict_a = dict_b não cria uma cópia. Ele cria uma referência (um alias). Modificar um modifica o outro. O exemplo a seguir ilustra o conceito:
# Reference assignment - creates an alias, not a copy
original = {"name": "Dataset_v1", "records": 1000}
alias = original
# Modifying through the alias changes the original
alias["records"] = 2000
print(original)
print(alias is original){'name': 'Dataset_v1', 'records': 2000}
TrueComo podemos ver, existe apenas um dicionário e tanto original quanto alias fazem referência a ele. Consequentemente, quando o valor para a chave records é definido como 2000, a alteração só pode se aplicar a este único dicionário.
Uma cópia superficial (.copy() ou dict()) cria um novo objeto de dicionário, mas objetos mutáveis aninhados permanecem referências compartilhadas.
# Shallow copy - creates a new dict but shares nested objects
original = {
"name": "Experiment_A",
"parameters": {"learning_rate": 0.01, "epochs": 100},
"results": [0.85, 0.89, 0.92]
}
shallow = original.copy()
# Modifying top-level keys works as expected
shallow["name"] = "Experiment_B"
print(original["name"])
print(shallow["name"])
# But modifying nested objects affects both
shallow["parameters"]["learning_rate"] = 0.001
print(original["parameters"]["learning_rate"])
shallow["results"].append(0.94)
print(original["results"])Experiment_A
Experiment_B
0.001
[0.85, 0.89, 0.92, 0.94]Como você pode ver, as chaves de nível superior são modificadas conforme o esperado, mas se você modificar objetos mutáveis aninhados, isso afeta tanto o original quanto a cópia superficial.
Por causa disso, cópias superficiais frequentemente causam bugs sutis em pipelines de aprendizado de máquina e gerenciamento de configuração.
Portanto, você precisa de uma cópia profunda usando copy.deepcopy() da biblioteca padrão para dicionários contendo objetos mutáveis aninhados. Isso copia recursivamente todos os objetos aninhados, criando estruturas completamente independentes. Um exemplo mostrando isso é dado abaixo:
import copy
# Deep copy - creates completely independent nested structures
original = {
"model": "RandomForest",
"hyperparameters": {
"n_estimators": 100,
"max_depth": 10,
"min_samples_split": 2
},
"feature_importance": [0.3, 0.25, 0.2, 0.15, 0.1]
}
deep = copy.deepcopy(original)
# Modify nested structures
deep["hyperparameters"]["n_estimators"] = 200
deep["feature_importance"].append(0.05)
# Original remains completely unchanged
print(original["hyperparameters"]["n_estimators"])
print(len(original["feature_importance"]))
print(len(deep["feature_importance"]))100
5
6Ao implementar as seguintes técnicas, você garantirá a integridade e a manutenibilidade dos dados em pipelines complexos.
Use | e |= para mesclagens de dicionário limpas.
Lembre-se de que o último visto vence em colisões.
Distinga entre atribuição de referência, cópias superficiais e cópias profundas para evitar bugs sutis.
Sempre prefira copy.deepcopy() ao trabalhar com estruturas mutáveis aninhadas em código de produção.
Embora o dict padrão seja versátil, a biblioteca padrão do Python oferece mapeamentos especializados otimizados para tarefas específicas, como contagem, agrupamento ou imposição de estruturas de dados. Escolher o tipo especializado certo pode simplificar drasticamente seu código e prevenir classes inteiras de bugs.
O módulo collections oferece alguns tipos de dicionário especializados úteis.
O defaultdict do módulo collections elimina verificações repetitivas de existência de chaves inicializando automaticamente chaves ausentes com um valor padrão. Isso é muito útil para tarefas de acumulação como contagem, agrupamento ou construção de estruturas aninhadas:
from collections import defaultdict
# Standard dict requires manual key checking
word_count = {}
text = "the quick brown fox jumps over the lazy dog".split()
for word in text:
if word not in word_count:
word_count[word] = 0
word_count[word] += 1
# defaultdict eliminates the check
word_count_auto = defaultdict(int) # int() returns 0
for word in text:
word_count_auto[word] += 1 # No checking needed!
print(dict(word_count_auto))
# Grouping with defaultdict(list)
transactions = [
("2024-01-15", "groceries", 45.50),
("2024-01-15", "gas", 60.00),
("2024-01-16", "groceries", 32.75),
("2024-01-16", "entertainment", 25.00),
("2024-01-17", "gas", 55.00)
]
by_date = defaultdict(list)
for date, category, amount in transactions:
by_date[date].append((category, amount))
for date, items in by_date.items():
print(f"{date}: {items}")
# Nested defaultdict for complex structures
nested = defaultdict(lambda: defaultdict(int))
events = [
("2024-01", "login", 150),
("2024-01", "purchase", 45),
("2024-02", "login", 200),
("2024-02", "purchase", 60)
]
for month, event_type, count in events:
nested[month][event_type] += count
print(dict(nested)){'the': 2, 'quick': 1, 'brown': 1, 'fox': 1, 'jumps': 1, 'over': 1, 'lazy': 1, 'dog': 1}
2024-01-15: [('groceries', 45.5), ('gas', 60.0)]
2024-01-16: [('groceries', 32.75), ('entertainment', 25.0)]
2024-01-17: [('gas', 55.0)]
{'2024-01': defaultdict(<class 'int'>, {'login': 150, 'purchase': 45}), '2024-02': defaultdict(<class 'int'>, {'login': 200, 'purchase': 60})}A classe Counter é uma subclasse de dicionário especializada projetada para contar objetos hashable e realizar operações de multiconjunto. É particularmente poderosa para análise estatística e distribuições de frequência. Vamos ver um exemplo de como esse tipo funciona:
from collections import Counter
# Count occurrences in a sequence
tags = ["python", "data", "python", "ml", "data", "python", "statistics", "ml"]
tag_counts = Counter(tags)
print(tag_counts)
# Most common elements
print(tag_counts.most_common(2))
# Counter arithmetic - multiset operations
skills_alice = Counter(["Python", "SQL", "Tableau", "Python"])
skills_bob = Counter(["Python", "R", "SQL"])
# Union (maximum of counts)
combined_skills = skills_alice | skills_bob
print(combined_skills)
# Intersection (minimum of counts)
shared_skills = skills_alice & skills_bob
print(shared_skills)
# Addition (sum of counts)
total_mentions = skills_alice + skills_bob
print(total_mentions)
# Practical example: Analyzing survey responses
responses = ["satisfied", "neutral", "satisfied", "satisfied",
"dissatisfied", "neutral", "satisfied", "very_satisfied"]
sentiment_analysis = Counter(responses)
# Calculate percentage distribution
total = sum(sentiment_analysis.values())
for sentiment, count in sentiment_analysis.most_common():
percentage = (count / total) * 100
print(f"{sentiment}: {count} ({percentage:.1f}%)")Counter({'python': 3, 'data': 2, 'ml': 2, 'statistics': 1})
[('python', 3), ('data', 2)]
Counter({'Python': 2, 'SQL': 1, 'Tableau': 1, 'R': 1})
Counter({'Python': 1, 'SQL': 1})
Counter({'Python': 3, 'SQL': 2, 'Tableau': 1, 'R': 1})
satisfied: 4 (50.0%)
neutral: 2 (25.0%)
dissatisfied: 1 (12.5%)
very_satisfied: 1 (12.5%)Antes do Python 3.7, OrderedDict era essencial para preservar a ordem de inserção. Embora os dicionários padrão agora mantenham a ordem, OrderedDict ainda tem casos de uso específicos, particularmente para verificações de igualdade que consideram a ordem e para mover itens para qualquer uma das extremidades:
from collections import OrderedDict
# OrderedDict equality considers order
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 2, "a": 1}
print(dict1 == dict2)
ordered1 = OrderedDict([("a", 1), ("b", 2)])
ordered2 = OrderedDict([("b", 2), ("a", 1)])
print(ordered1 == ordered2)
# Move items to beginning or end
task_queue = OrderedDict([
("task1", "pending"),
("task2", "in_progress"),
("task3", "pending")
])
# Move task3 to the beginning (highest priority)
task_queue.move_to_end("task3", last=False)
print(list(task_queue.keys()))
# Move task2 to the end (lowest priority)
task_queue.move_to_end("task2")
print(list(task_queue.keys()))True
False
['task3', 'task1', 'task2']
['task3', 'task1', 'task2']O gráfico a seguir ilustra quando escolher qual tipo de dicionário.
À medida que a adoção do Python cresce em ambientes de produção em larga escala, a segurança de tipo torna-se uma questão importante. Os módulos typing e types introduzem maneiras de impor estrutura aos seus dicionários. Entender métodos dunder do Python pode também ajudá-lo a construir objetos personalizados semelhantes a dicionários com comportamentos especiais.
O módulo typing do Python fornece TypedDict para definir estruturas de dicionário com chaves obrigatórias específicas e anotações de tipo. Isso melhora a documentação do código, permite o preenchimento automático da IDE e detecta erros de tipo durante a análise estática. Vamos ver como funciona:
from typing import TypedDict
# Define strict structure for user data
class UserProfile(TypedDict):
user_id: int
username: str
email: str
is_active: bool
role: str
# Create properly typed dictionary
user: UserProfile = {
"user_id": 12345,
"username": "data_scientist",
"email": "[email protected]",
"is_active": True,
"role": "analyst"
}
# IDE will autocomplete and type-check
def process_user(user: UserProfile) -> str:
# IDE knows these keys exist and their types
return f"User {user['username']} (ID: {user['user_id']}) - {user['role']}"
# Optional keys with total=False
class PartialConfig(TypedDict, total=False):
host: str
port: int
database: str # All keys are optional
config: PartialConfig = {"host": "localhost"} # Valid - partial configPara cenários onde você precisa expor um dicionário, mas impedir a modificação, MappingProxyType cria uma visualização imutável e somente leitura de um dicionário padrão. Isso é excelente para proteger constantes de configuração global de alterações acidentais. Vamos ver isso em ação:
from types import MappingProxyType
# Create read-only view of configuration
_INTERNAL_CONFIG = {
"API_VERSION": "v2",
"MAX_RETRIES": 3,
"TIMEOUT": 30,
"ENDPOINTS": {
"users": "/api/v2/users",
"data": "/api/v2/data"
}
}
# Expose as immutable proxy
CONFIG = MappingProxyType(_INTERNAL_CONFIG)
# Reading works normally
print(CONFIG["API_VERSION"])
print(CONFIG["TIMEOUT"])
# Modifications raise TypeError
try:
CONFIG["TIMEOUT"] = 60
except TypeError as e:
print(f"Cannot modify: {e}")
# Caution: nested modifications succeed
try:
CONFIG["ENDPOINTS"]["users"] = "/new/endpoint"
except TypeError as e:
print(f"Cannot modify nested: {e}")
# Practical use case: Class constants
class DataPipeline:
_default_config = {
"batch_size": 1000,
"parallel_workers": 4,
"retry_failed": True
}
# Expose as read-only to prevent accidental changes
DEFAULT_CONFIG = MappingProxyType(_default_config)
def __init__(self, custom_config=None):
# Merge with custom config while keeping defaults safe
self.config = {**self.DEFAULT_CONFIG, **(custom_config or {})}v2
30
Cannot modify: 'mappingproxy' object does not support item assignmentPortanto, como podemos ver, MappingProxyType torna o dicionário em si somente leitura (sem adicionar, excluir ou reassociar chaves), mas não congela valores mutáveis armazenados dentro dele. Para evitar alterações em estruturas aninhadas, você também deve tornar esses objetos aninhados imutáveis ou envolvê-los em suas próprias visualizações somente leitura.
Para assinaturas de função e dicas de tipo, use Dict e Mapping do módulo typing para documentar estruturas de dicionário esperadas. Podemos fazer isso como mostrado abaixo:
from typing import Dict, List, Mapping, Any
# Dict for mutable dictionaries
def process_scores(scores: Dict[str, float]) -> Dict[str, str]:
"""Convert numeric scores to letter grades."""
grades = {}
for student, score in scores.items():
if score >= 90:
grades[student] = "A"
elif score >= 80:
grades[student] = "B"
elif score >= 70:
grades[student] = "C"
else:
grades[student] = "F"
return grades
# Mapping for read-only or general mapping types
def display_config(config: Mapping[str, Any]) -> None:
"""Display configuration - accepts any mapping type."""
for key, value in config.items():
print(f"{key}: {value}")
# Works with dict, MappingProxyType, OrderedDict, etc.
display_config({"host": "localhost", "port": 5432})
display_config(CONFIG) # MappingProxyType from earlierhost: localhost
port: 5432
API_VERSION: v2
MAX_RETRIES: 3
TIMEOUT: 30
ENDPOINTS: {'users': '/new/endpoint', 'data': '/api/v2/data'}À medida que seus conjuntos de dados crescem de milhares para milhões de registros, a eficiência do seu código torna-se importante. Por esse motivo, é necessário entender as características de desempenho dos dicionários. Então, vamos analisar a complexidade computacional, as implicações de memória e as estratégias de otimização para operações de dicionário.
As operações de dicionário alcançam sua alta velocidade através da implementação de tabela hash, entregando complexidade de tempo O(1) no caso médio para as três operações mais comuns:
get)set)delete)Esse desempenho de tempo constante significa que essas operações levam aproximadamente a mesma ordem de magnitude de tempo em média, quer seu dicionário contenha 10 itens ou 10 milhões. Vamos ver isso com um exemplo de código:
import time
import statistics
def benchmark_lookup(size, repeats=50_000):
"""
Measure the median time for a single dictionary lookup in a dictionary of given size.
Parameters:
size (int): Number of elements in the dictionary to create
repeats (int): How many times to repeat the lookup (for more stable median)
Returns:
float: Median lookup time in microseconds (μs)
"""
# Create a large dictionary with string keys and integer values
large_dict = {f"key_{i}": i for i in range(size)}
# The key we will look up repeatedly (last element)
target_key = f"key_{size - 1}"
# Store individual measurement times (in nanoseconds)
times = []
# Perform many lookups to reduce measurement noise
for _ in range(repeats):
# Use high-resolution timer (nanoseconds)
start = time.perf_counter_ns()
_ = large_dict[target_key] # The actual dictionary lookup
end = time.perf_counter_ns()
times.append(end - start)
# Calculate median time to minimize impact of outliers
median_ns = statistics.median(times)
# Convert nanoseconds to microseconds
return median_ns / 1000
# Sizes to test (from 100k to 10 million elements)
sizes = [100_000, 1_000_000, 10_000_000]
print("Dictionary lookup benchmark (median time over many repeats)\n")
print(f"{'Size':>12} | {'Median Lookup Time':>18} | Notes")
print("-" * 50)
for size in sizes:
lookup_time_us = benchmark_lookup(size)
print(f"{size:>12,} | {lookup_time_us:>15.2f} μs | "
f"{'→ still ~constant' if size == sizes[-1] else ''}")Dictionary lookup benchmark (median time over many repeats)
Size | Median Lookup Time | Notes
--------------------------------------------------
100,000 | 0.14 μs |
1,000,000 | 0.14 μs |
10,000,000 | 0.14 μs | → still ~constantOs tempos médios de consulta acima podem mudar para você com base em seus recursos computacionais. O ponto principal a ser observado é que, quaisquer que sejam os valores, eles quase permanecem os mesmos com alguma variabilidade, tornando a diferença completamente negligenciável, provando a propriedade O(1).
No entanto, no pior cenário, ele pode degradar para complexidade O(n) quando ocorrem colisões de hash excessivas. Colisões de hash acontecem quando chaves diferentes produzem o mesmo valor hash, forçando o Python a pesquisar através de múltiplas entradas armazenadas no mesmo bucket de hash. Vamos ver isso com um exemplo:
# Pathological case: forcing hash collisions
class BadHash:
"""Object with intentionally poor hash function."""
def __init__(self, value):
self.value = value
def __hash__(self):
return 1 # All instances hash to same value - worst case!
def __eq__(self, other):
return isinstance(other, BadHash) and self.value == other.value
# This will have O(n) performance due to collisions
bad_dict = {BadHash(i): i for i in range(1000)}
# Compare with well-distributed hashes
good_dict = {f"key_{i}": i for i in range(1000)}
# Benchmark the difference
start = time.perf_counter()
_ = bad_dict[BadHash(999)]
bad_time = time.perf_counter() - start
start = time.perf_counter()
_ = good_dict["key_999"]
good_time = time.perf_counter() - start
print(f"Bad hash lookup: {bad_time * 1_000_000:.2f} μs")
print(f"Good hash lookup: {good_time * 1_000_000:.2f} μs")
print(f"Performance degradation: {bad_time / good_time:.1f}x slower")Bad hash lookup: 582.48 μs
Good hash lookup: 93.99 μs
Performance degradation: 6.2x slowerNovamente, os resultados exatos e a degradação de desempenho variarão dependendo do seu poder computacional. Mas a tendência será a mesma: a consulta de hash ruim levará muito mais tempo do que aquela que atinge a complexidade de tempo O(1).
Outro custo oculto é o redimensionamento. À medida que os dicionários crescem, o Python redimensiona automaticamente a tabela hash interna para manter o desempenho. Essa operação de redimensionamento tem um custo computacional, pois requer re-hash de todas as chaves existentes e redistribuí-las em um array maior.
O Python usa uma estratégia de fator de crescimento, geralmente dobrando pelo menos o tamanho quando um limite é atingido. Entender esses padrões de redimensionamento ajuda ao inicializar dicionários grandes. Se você souber o tamanho final aproximado, pode pré-alocar espaço para evitar múltiplas operações de redimensionamento.
A velocidade geralmente vem ao custo da memória. Os dicionários têm uma sobrecarga de memória significativa em comparação com tuplas ou listas porque precisam armazenar a estrutura da tabela hash (índices, hashes, chaves e valores). Vamos entender isso com um exemplo de código:
import sys
# Compare memory footprint of different data structures
data_list = [("name", "Alice"), ("age", 30), ("city", "NYC")]
data_tuple = (("name", "Alice"), ("age", 30), ("city", "NYC"))
data_dict = {"name": "Alice", "age": 30, "city": "NYC"}
print(f"List of tuples: {sys.getsizeof(data_list)} bytes")
print(f"Tuple of tuples: {sys.getsizeof(data_tuple)} bytes")
print(f"Dictionary: {sys.getsizeof(data_dict)} bytes")List of tuples: 88 bytes
Tuple of tuples: 64 bytes
Dictionary: 184 bytesNo exemplo acima, você pode ver que o dicionário usa ~2x-3x mais memória para os mesmos dados. Para classes que criam muitas instâncias, usar __slots__ em vez de __dict__ de instância pode reduzir drasticamente o consumo de memória.
Por padrão, o Python armazena atributos de instância em um dicionário acessível via __dict__, mas __slots__ usa uma estrutura baseada em array mais compacta. Vamos ver um exemplo disso:
import sys
# Regular class - uses __dict__ for attributes
class RegularUser:
def __init__(self, user_id, name, email):
self.user_id = user_id
self.name = name
self.email = email
# Optimized class - uses __slots__
class OptimizedUser:
__slots__ = ['user_id', 'name', 'email']
def __init__(self, user_id, name, email):
self.user_id = user_id
self.name = name
self.email = email
# Create instances
regular = RegularUser(12345, "Alice", "[email protected]")
optimized = OptimizedUser(12345, "Alice", "[email protected]")
# Compare memory usage
print(f"Regular instance: {sys.getsizeof(regular.__dict__)} bytes (__dict__)")
print(f"Optimized instance: {sys.getsizeof(optimized)} bytes (__slots__)")
# For massive instance counts, the savings multiply
regular_users = [RegularUser(i, f"User{i}", f"user{i}@example.com") for i in range(1000)]
optimized_users = [OptimizedUser(i, f"User{i}", f"user{i}@example.com") for i in range(1000)]
regular_total = sum(sys.getsizeof(u.__dict__) for u in regular_users)
optimized_total = sum(sys.getsizeof(u) for u in optimized_users)
print(f"\n1000 regular instances: {regular_total:,} bytes")
print(f"1000 optimized instances: {optimized_total:,} bytes")
print(f"Memory savings: {((regular_total - optimized_total) / regular_total * 100):.1f}%")Regular instance: 296 bytes (__dict__)
Optimized instance: 56 bytes (__slots__)
1000 regular instances: 96,000 bytes
1000 optimized instances: 56,000 bytes
Memory savings: 41.7%Finalmente, embora os dicionários sejam excelentes para acesso aleatório, eles não são otimizados para processamento de dados colunares. Se você estiver lidando com dados tabulares em larga escala (por exemplo, milhões de linhas), migrar para um pandas DataFrame é uma escolha sábia, porque eles são otimizados tanto para eficiência de memória quanto para velocidade vetorizada.
import pandas as pd
import time
import sys
n = 10_000
# Dict
dict_data = {i: {"user_id": i, "score": i * 1.5, "category": f"cat_{i % 10}"} for i in range(n)}
# Optimized DF: use category dtype for strings, int32 for ids
df_data = pd.DataFrame({
"user_id": pd.Series(range(n), dtype="int32"),
"score": [i * 1.5 for i in range(n)],
"category": pd.Series([f"cat_{i % 10}" for i in range(n)], dtype="category")
})
dict_memory = sys.getsizeof(dict_data)
df_memory = df_data.memory_usage(deep=True).sum()
print(f"Dictionary: {dict_memory:,} bytes")
print(f"Optimized DataFrame: {df_memory:,} bytes")
# Bulk operation: mean score per category
start = time.perf_counter()
df_mean = df_data.groupby("category")["score"].mean()
df_time = (time.perf_counter() - start) * 1_000_000
# Equivalent in dict (manual loop)
start = time.perf_counter()
from collections import defaultdict
means = defaultdict(lambda: [0, 0])
for row in dict_data.values():
cat = row["category"]
means[cat][0] += row["score"]
means[cat][1] += 1
dict_mean = {k: s/c for k, (s, c) in means.items()}
dict_time = (time.perf_counter() - start) * 1_000_000
print(f"\nDF groupby mean: {df_time:.2f} μs")
print(f"Dict manual mean: {dict_time:.2f} μs")Dictionary: 294,992 bytes
Optimized DataFrame: 130,972 bytes
DF groupby mean: 1630.24 μs
Dict manual mean: 3931.47 μsVocê pode ver claramente que o DataFrame supera o dicionário em nosso exemplo. Para fluxos de trabalho de ciência de dados que exigem consultas rápidas e operações analíticas, considere abordagens híbridas, como usar dicionários para indexação e acesso rápido, e depois converter para DataFrames para análise em massa.
A chave para a otimização é combinar a estrutura de dados com seus padrões de acesso. Se você faz consultas frequentes baseadas em chaves, os dicionários são ideais. Para operações colunares, filtragem e agregações em grandes conjuntos de dados, os DataFrames oferecem um bom desempenho.
Os dicionários são muito mais do que simples recipientes de armazenamento. Eles são a cola que mantém unidas as aplicações complexas de ciência de dados. Se você está construindo uma tabela de consulta rápida para um script ou arquitetando um pipeline de dados de alto rendimento, um dicionário é provavelmente sua ferramenta mais valiosa.
No entanto, confiar no comportamento padrão sem um tratamento de erro robusto é uma receita para falhas em tempo de execução. Padrões robustos de tratamento de erros, como usar abordagens EAFP versus LBYL e validação proativa, provavelmente evitarão falhas em tempo de execução ao processar dados externos.
Coleções especializadas como defaultdict, Counter e TypedDict fazem seu código passar de funcional para nível de produção. Sempre tenha em mente a complexidade de tempo e o gerenciamento de memória para garantir que seu código seja executado com eficiência. Além disso, lembre-se de que a otimização é um processo iterativo.
Para continuar desenvolvendo suas habilidades em Python, recomendo fazer nosso curso de Python Intermediário para mais sobre estruturas de dados, ou a trilha mais ampla de Desenvolvedor Python para um caminho de aprendizado abrangente.
Cursos de Python
Programa
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Neetika Khandelwal
Tutorial
Javier Canales Luna
Tutorial
Abid Ali Awan

