Track
Developing AI Applications
21 hr
Gone are the days when we were happy with large language models that can only process text. We now demand multimodal LLMs capable of understanding and interacting with text, images, and videos.
Enter Llama 3.2 11B & 90B vision models, Meta AI’s first open-source multimodal models, capable of processing both text and image inputs.
In this hands-on guide, I will take you through the process of creating a multimodal customer support assistant with the help of Llama 3.2 and Gradio. By the end of this tutorial, you will have a fully functional web application that can analyze textual descriptions and uploaded images to generate helpful solutions - just like a support ticket assistant would!
If you need a quick introduction to Llama 3.2 before we get started, I recommend reading this Llama 3.2 guide.
In this hands-on demo, we’ll be using the Llama3.2-11B-Vision model (multimodal). Before starting to code, let’s make sure we have all the necessary dependencies.
We need a few libraries to make everything work. The key ones are:
Run the following commands to install the necessary dependencies:
!pip3 install -U transformers bitsandbytes accelerate peft -q
!pip3 install gradio -qNow, let’s load the Llama 3.2 model and processor. We’ll make use of Hugging Face’s transformers library to load the model and processor, making sure the model runs on GPU if it’s available, or defaults to CPU otherwise. Being an 11B parameter model, it works well on an A100 GPU in Google Colab.
In the code block below:
tie_weight(), which ensures that the weights of the input and output embedding layers are identical. This reduces memory consumption and can improve performance.import torch
from PIL import Image
import gradio as gr
from transformers import MllamaForConditionalGeneration, AutoProcessor
def load_model():
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu" # Check if GPU is available
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto", # Automatically map to available device
offload_folder="offload", # Offload to disk if necessary
)
model.tie_weights() # Tying weights for efficiency
processor = AutoProcessor.from_pretrained(model_id)
print(f"Model loaded on: {device}")
return model, processorGradio is a lightweight Python library that allows us to quickly build machine-learning apps with web-based interfaces. Instead of writing complex HTML or JavaScript, we can define our app’s components (like text boxes, buttons, or images) directly in Python.
Here’s what a basic Gradio UI looks like:
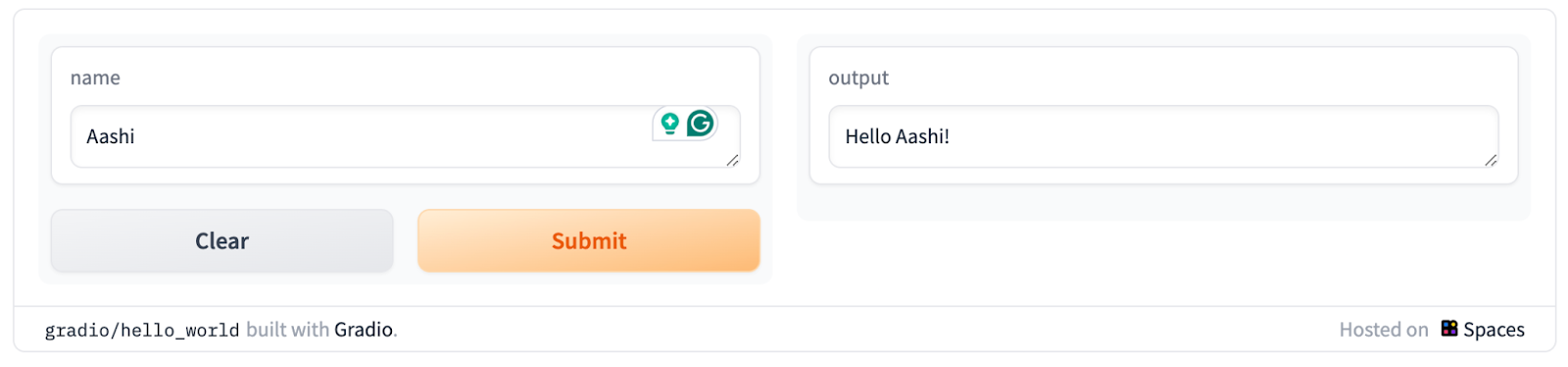
Gradio has a few benefits:
For this demo, Gradio makes it simple for users to input both text and images and see the output (analysis of text and image, in this case) in real time. It’s perfect for showcasing the power of models like Llama 3.2 in a user-friendly environment.
Now that we have already set up our imports and have successfully set up our model, let’s move forward with the main part of the app—processing the inputs (text and image) and generating the response.
We start by defining a function that takes in user text and, optionally, an image. This function then uses the Llama 3.2 model to generate a response.
def process_ticket(text, image=None):
model, processor = load_model()
try:
if image:
# Resize the image for consistency
image = image.convert("RGB").resize((224, 224))
prompt = f"<|image|><|begin_of_text|>{text}"
# Process both the image and text input
inputs = processor(images=[image], text=prompt, return_tensors="pt").to(model.device)
else:
prompt = f"<|begin_of_text|>{text}"
# Process text-only input
inputs = processor(text=prompt, return_tensors="pt").to(model.device)
# Generate response (restrict token length for faster output)
outputs = model.generate(**inputs, max_new_tokens=200)
# Decode the response from tokens to text
response = processor.decode(outputs[0], skip_special_tokens=True)
return response
except Exception as e:
print(f"Error processing ticket: {e}")
return "An error occurred while processing your request."This function handles two types of input within the loop:
Once the input type is identified, it is passed to a processor sourced from the transformer library to process the input. Then, the model generates an output within the range of max_new_tokens.
The Gradio interface binds everything together and enables us to run tests in a web-based format. This interface allows users to submit text and images of an issue they are facing and see the AI-generated solution.
Let’s take a look at the code and then explain it.
def create_interface():
text_input = gr.Textbox(
label="Describe your issue",
placeholder="Describe the problem you're experiencing",
lines=4,
)
image_input = gr.Image(label="Upload a Screenshot (Optional)", type="pil")
# Output element
output = gr.Textbox(label="Suggested Solution", lines=5)
# Create the Gradio interface
interface = gr.Interface(
fn=process_ticket, # Function to process inputs
inputs=[text_input, image_input], # User inputs (text and image)
outputs=output, # AI-generated output
title="Multimodal Customer Support Assistant",
description="Submit a description of your issue, along with an optional screenshot, and get AI-powered suggestions.",
)
# Launch the interface with debug mode
interface.launch(debug=True)In the code above, we:
text_input for textimage_input for imagedebug = True to debug the errors. Once the code works fine, switch it back to False.The final interface will look like this:
Our multimodal customer support assistant Gradio application is ready! To get the desired response, try changing the max_new_tokens parameter or playing around with the prompt a bit.
In addition to the demo we created in this tutorial, there are a few other use cases that require minimal effort. These include:
For every use case, there are a few tips that every developer can use while developing an app like the one we already built. Here are a few best practices which a developer can adopt while working with models like llama3.2.
Since multimodal tasks can be resource-intensive, reducing latency is key. Consider optimizing the model for faster responses by using caching, model pruning, or limiting the number of tokens generated.
It’s important to put mechanisms in place to handle errors. In cases where the model fails to generate a meaningful response (e.g., due to poor image quality), we can provide fallback responses or error messages. We can even opt for human feedback, which, in return, helps to improve the model.
Tracking the app's performance, such as response times and user interaction data, can help optimize the interface and even improve the user experience. By noting performance time, we can try to optimize the model latency using libraries like bits and bytes.
In this guide, we learned how to combine Llama 3.2's multimodal capabilities and Gradio's intuitive interface. From customer support to education and content creation, the potential applications are vast and varied.
By adhering to best practices like latency management, error handling, and performance monitoring, we can ensure our Llama 3.2 and Gradio applications are robust, efficient, and user-friendly.
To learn more, I recommend these tutorials:
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Bhavishya Pandit
Tutorial
Ryan Ong
Tutorial
Bex Tuychiev
Tutorial
Ryan Ong