Course
Working with the OpenAI API
3 hr
151.7K
GPT-5 introduces a new reasoning effort parameter that lets you control how deeply the model thinks before responding. You can choose from minimal, low, medium, or high effort levels, depending on your needs.
Minimal effort is perfect for speed-sensitive tasks like quick coding or simple instruction following, while medium and high allow for more thorough, step-by-step reasoning. This flexibility means you can balance latency, cost, and accuracy.
First, install the OpenAI Python SDK and set your API key as an environment variable:
pip install openaiSet your API key (replace with your actual key):
export OPENAI_API_KEY="your_api_key_here"setx OPENAI_API_KEY "your_api_key_here"Let’s use the Response API to generate text with “minimal” reasoning effort. This means the model will respond directly, without allocating tokens for internal reasoning.
import os
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
)
print(resp.output_text)Output:
Guido van Rossum is known as the father (creator) of Python. He first released Python in 1991.You can also check the token usage summary to understand how the model processed your request:
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")As shown, zero tokens were used for reasoning when effort is set to minimal.
Input tokens: 13
- Cached tokens: 0
Output tokens: 31
- Reasoning tokens: 0
Total tokens: 44Now, let’s increase the reasoning effort to "high" to see how the model’s internal reasoning changes:
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "high"},
)
print(resp.output_text)Output:
Guido van Rossum. He created Python and first released it in 1991.Check the token usage again:
print(f"Input tokens: {resp.usage.input_tokens}")
print(f" - Cached tokens: {resp.usage.input_tokens_details.cached_tokens}")
print(f"Output tokens: {resp.usage.output_tokens}")
print(f" - Reasoning tokens: {resp.usage.output_tokens_details.reasoning_tokens}")
print(f"Total tokens: {resp.usage.total_tokens}")Even for a simple question, the model used 192 tokens for reasoning at high effort. This demonstrates how you can now control the depth of reasoning to optimize for cost, speed, or accuracy as needed.
Input tokens: 13
- Cached tokens: 0
Output tokens: 216
- Reasoning tokens: 192
Total tokens: 229With GPT-5, you can now directly control how much the model says using the verbosity parameter. Set it to low for concise answers, medium for balanced detail, or high for in-depth explanations. This is especially useful for code generation—low verbosity produces short, clean code, while high verbosity includes inline comments and detailed reasoning.
You can combine the verbosity parameter with reasoning controls to tailor responses exactly to your needs. Whether you want a short sentence, a longer answer, or a comprehensive report, you have full flexibility.
The “low” verbosity produces a brief, direct answer.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
print(resp.output_text)Output:
Guido van Rossum.The “high” verbosity generates a much more detailed and explanatory response.
resp = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "high"},
)
print(resp.output_text)Output:
Guido van Rossum is known as the "father of Python." He created Python in the late 1980s and released the first version (Python 0.9.0) in 1991. He also served for many years as Python's "Benevolent Dictator For Life" (BDFL), guiding the language's development.One of GPT-5’s biggest upgrades is its ability to pass chain-of-thought (CoT) reasoning between turns in the Responses API. This means the model remembers its internal reasoning from previous steps, avoiding redundant rethinking and improving both speed and accuracy.
In multi-turn conversations, especially when using tools, simply pass the previous_response_id to keep the reasoning context alive.
The first request asks, “Who is the father of Python?”, and the second request, linked to the first via previous_response_id, asks the model to “Write a blog on it” without restating the subject. By passing the previous response’s ID, the model retains the reasoning context.
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
first = client.responses.create(
model="gpt-5",
input="Who is the father of Python?",
reasoning={"effort": "minimal"},
text={"verbosity": "low"},
)
followup = client.responses.create(
model="gpt-5",
previous_response_id=first.id,
input="Write a blog on it.",
reasoning={"effort": "medium"},
text={"verbosity": "high"},
)
print(followup.output_text)As a result, we got a blog on the father of Python.

Custom tools in GPT-5 now support freeform inputs, allowing the model to send raw text, like code, SQL queries, or shell commands directly to your tools. This is a big leap from the old structured JSON-only approach, giving you more flexibility in how the model interacts with your systems. Whether you are building a code executor, a query engine, or a DSL interpreter, freeform input makes GPT-5 far more adaptable for real-world, unstructured tasks.
In the code below, we have defined a fake SQL runner, registered it as a custom tool, and made an initial request where the model responds with a freeform SQL query. That query is extracted, executed locally, and the result is sent back to the model using the same call_id to maintain the tool call context. Finally, GPT‑5 turns the raw tool output into a natural language answer.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
print("\n[FAKE DB] Executing SQL:\n", sql)
categories = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
result = "category | total_sales\n" + "-" * 28 + "\n"
for cat in categories:
result += f"{cat:<11} | {random.randint(5000, 200000)}\n"
return result
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL queries on the company sales database.",
}
]
messages = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
# 1) First call - model emits a freeform tool call
resp = client.responses.create(model="gpt-5", tools=tools, input=messages)
# IMPORTANT: carry the tool call into the next turn
messages += resp.output # <-- this preserves the tool_call with its call_id
# Find the tool call from the response output
tool_call = next(
(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
),
None,
)
assert tool_call is not None, "No tool call found."
# Freeform text is in input (fallback to arguments for safety) raw_text = getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "") sql_text = raw_text.strip() # 2) Execute the tool locally fake_result = run_sql_query(sql_text) # 3) Send tool result back, referencing the SAME call_id messages.append( { "type": "function_call_output", "call_id": tool_call.call_id, "output": fake_result, } ) # 4) Final call - model turns tool output into a natural answer final = client.responses.create(model="gpt-5", tools=tools, input=messages) print("\nFinal output text:\n", final.output_text)Output:
[FAKE DB] Executing SQL:
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema','pg_catalog')
ORDER BY 1,2;
Final output text:
Here are the total sales by category for last month (July 2025):
- Electronics: 31,766
- Clothing: 90,266
- Furniture: 55,471
- Toys: 124,625
- Books: 74,263
Want this as a CSV or chart?For scenarios where precision is critical, GPT-5 supports context-free grammars (CFGs) to strictly control output formats. By attaching a grammar like SQL syntax or a domain-specific language, you can ensure the model’s responses always match your required structure. This is especially valuable for high-stakes or automated workflows, where even small deviations in format could cause errors.
In the example code, we built a sql_query_runner tool and defined its SQL syntax using a Lark grammar, ensuring that any SQL the model generates is always valid and follows our exact structure.
In the first model call, GPT‑5 uses this tool to produce a grammar‑compliant SQL query for last month’s sales by category. We then execute that query locally, send the results back to the model using the same call_id, and make a second call where GPT‑5 turns the raw data into a clear, natural‑language answer.
from openai import OpenAI
import random
client = OpenAI()
def run_sql_query(sql: str) -> str:
cats = ["Electronics", "Clothing", "Furniture", "Toys", "Books"]
rows = [f"{c:<11} | {random.randint(5_000, 200_000)}" for c in cats]
return "category | total_sales\n" + "-" * 28 + "\n" + "\n".join(rows)
tools = [
{
"type": "custom",
"name": "sql_query_runner",
"description": "Runs raw SQL on the sales DB.",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": r"""
start: SELECT CATEGORY COMMA SUM LPAREN SALES RPAREN AS TOTAL_SALES FROM ORDERS WHERE ORDER_MONTH EQ ESCAPED_STRING GROUP BY CATEGORY ORDER BY TOTAL_SALES (DESC|ASC)?
SELECT: "SELECT"
CATEGORY: "category"
COMMA: ","
SUM: "SUM"
LPAREN: "("
SALES: "sales"
RPAREN: ")"
AS: "AS"
TOTAL_SALES: "total_sales"
FROM: "FROM"
ORDERS: "orders"
WHERE: "WHERE"
ORDER_MONTH: "order_month"
EQ: "="
GROUP: "GROUP"
BY: "BY"
ORDER: "ORDER"
DESC: "DESC"
ASC: "ASC"
%import common.ESCAPED_STRING
%ignore /[ \t\r\n]+/
""",
},
}
]
msgs = [
{
"role": "user",
"content": "Show me the total sales for each product category last month.",
}
]
print("\n=== 1) First Model Call ===")
resp = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("Raw model output objects:\n", resp.output)
msgs += resp.output
tool_call = next(
x
for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "function_call", "tool_call")
)
sql = (getattr(tool_call, "input", None) or getattr(tool_call, "arguments", "")).strip()
print("\nExtracted SQL from tool call:\n", sql)
print("\n=== 2) Local Tool Execution ===")
tool_result = run_sql_query(sql)
print(tool_result)
msgs.append(
{
"type": "function_call_output",
"call_id": getattr(tool_call, "call_id", None) or tool_call["call_id"],
"output": tool_result,
}
)
print("\n=== 3) Second Model Call ===")
final = client.responses.create(
model="gpt-5", input=msgs, tools=tools, text={"format": {"type": "text"}}
)
print("\nFinal natural-language answer:\n", final.output_text)As we can see, the model first generated a grammar-compliant SQL query, then executed the function to retrieve sales data. Finally, GPT-5 converted that data into a clear, ranked natural-language summary of last month’s sales by category.
=== 1) First Model Call ===
Raw model output objects:
[ResponseReasoningItem(id='rs_6897acee8afc819f9e7ae0f675bfa4ee0d5175a46255063b', summary=[], type='reasoning', content=None, encrypted_content=None, status=None), ResponseCustomToolCall(call_id='call_vzcHPT7EGvb7QbhF2djVIJZA', input='SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC', name='sql_query_runner', type='custom_tool_call', id='ctc_6897acf67a34819f84a085191e4ca1fb0d5175a46255063b', status='completed')]
Extracted SQL from tool call:
SELECT category, SUM(sales) AS total_sales FROM orders WHERE order_month = "2025-07" GROUP BY category ORDER BY total_sales DESC
=== 2) Local Tool Execution ===
category | total_sales
----------------------------
Electronics | 52423
Clothing | 59976
Furniture | 172713
Toys | 69667
Books | 14633
=== 3) Second Model Call ===
Final natural-language answer:
Here are the total sales by category for last month (2025-07):
- Furniture: 172,713
- Toys: 69,667
- Clothing: 59,976
- Electronics: 52,423
- Books: 14,633
Want this as a chart or need a different month?The new allowed_tools parameter lets you define a subset of tools the model can use from your full toolkit. You can set the mode to auto (model may choose) or required (model must use one). This improves safety, predictability, and prompt caching by preventing the model from calling unintended tools, while still giving it flexibility to choose the best option from the allowed set.
A full toolkit contains both get_weather and send_email, but we have allowed only get_weather and set the mode to "required", forcing the model to use it.
When asked, “What’s the weather in Oslo?”, GPT‑5 responded with a function call to get_weather and the correct argument {"city": "Oslo"}.
from openai import OpenAI
client = OpenAI()
# Full toolset (N)
tools = [
{
"type": "function",
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
{
"type": "function",
"name": "send_email",
"parameters": {
"type": "object",
"properties": {"to": {"type": "string"}, "body": {"type": "string"}},
"required": ["to", "body"],
},
},
]
# Allowed subset (M < N), mode=required → must call get_weather
resp = client.responses.create(
model="gpt-5",
input="What's the weather in Oslo?",
tools=tools,
tool_choice={
"type": "allowed_tools",
"mode": "required", # use "auto" to let it decide
"tools": [{"type": "function", "name": "get_weather"}],
},
)
for item in resp.output:
if getattr(item, "type", None) in ("function_call", "tool_call", "custom_tool_call"):
print("Tool name:", getattr(item, "name", None))
print("Arguments:", getattr(item, "arguments", None))Output:
Tool name: get_weather
Arguments: {"city":"Oslo"}Preambles are short, user-visible explanations that GPT-5 can generate before calling a tool, explaining why it’s making that call. This boosts transparency, user trust, and debugging ease, especially in complex workflows. By simply instructing the model to “explain before calling a tool,” you can make interactions feel more human-like and intentional without adding significant latency.
In the code below, we defined a get_weather function tool and added a system instruction telling the model to output a short, user‑visible sentence prefixed with "Preamble:" before making the tool call.
When asked, “What’s the weather in Oslo?”, GPT‑5 first produced a preamble explaining it was checking a live weather service, then called the get_weather tool with the correct argument {"city": "Oslo"}. After executing the tool locally and returning the result, the model gave the final natural‑language answer.
from openai import OpenAI
client = OpenAI()
def get_weather(city: str):
return {"city": city, "temperature_c": 12}
# Tool
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a city.",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
"additionalProperties": False
},
"strict": True,
}]
# Messages (enable preamble via system instruction)
msgs = [
{"role": "system", "content": "Before you call a tool, explain why you are calling it in ONE short sentence prefixed with 'Preamble:'."},
{"role": "user", "content": "What's the weather in Oslo?"}
]
# 1) Model call → expect a visible preamble + a tool call
resp = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("=== First response objects ===")
for item in resp.output:
t = getattr(item, "type", None)
if t == "message": # preamble is a normal assistant message
print("PREAMBLE:", getattr(item, "content", None))
if t in ("function_call","tool_call","custom_tool_call"):
print("TOOL:", getattr(item, "name", None))
print("ARGS:", getattr(item, "arguments", None))
tool_call = next(x for x in resp.output if getattr(x, "type", None) in ("function_call","tool_call","custom_tool_call"))
msgs += resp.output # keep context
# 2) Execute tool locally (fake)
import json
args = json.loads(getattr(tool_call, "arguments", "{}"))
city = args.get("city", "Unknown")
tool_result = get_weather(city)
# 3) Return tool result
msgs.append({"type": "function_call_output", "call_id": tool_call.call_id, "output": json.dumps(tool_result)})
# 4) Final model call → natural answer
final = client.responses.create(model="gpt-5", input=msgs, tools=tools)
print("\n=== Final answer ===")
print(final.output_text)As we can see, the model first gave a short preamble explaining its intent, then correctly called the get_weather tool with {"city": "Oslo"}, and finally returned the temperature in natural language.
=== First response objects ===
PREAMBLE: [ResponseOutputText(annotations=[], text='Preamble: I'm checking a live weather service to get the current conditions for Oslo.', type='output_text', logprobs=[])]
TOOL: get_weather
ARGS: {"city":"Oslo"}
=== Final answer ===
It's currently about 12°C in Oslo.GPT-5 is designed to excel with well-crafted prompts, and OpenAI provides a Prompt Optimizer to help you fine-tune them. This tool automatically adapts your prompts for GPT-5’s reasoning style, improving accuracy and efficiency.
Go to the Edit prompt - OpenAI API and write a simple prompt, such as "Create a Netflix clone web application." It will break down your prompt into a detailed structure, optimized for the GPT-5 model.
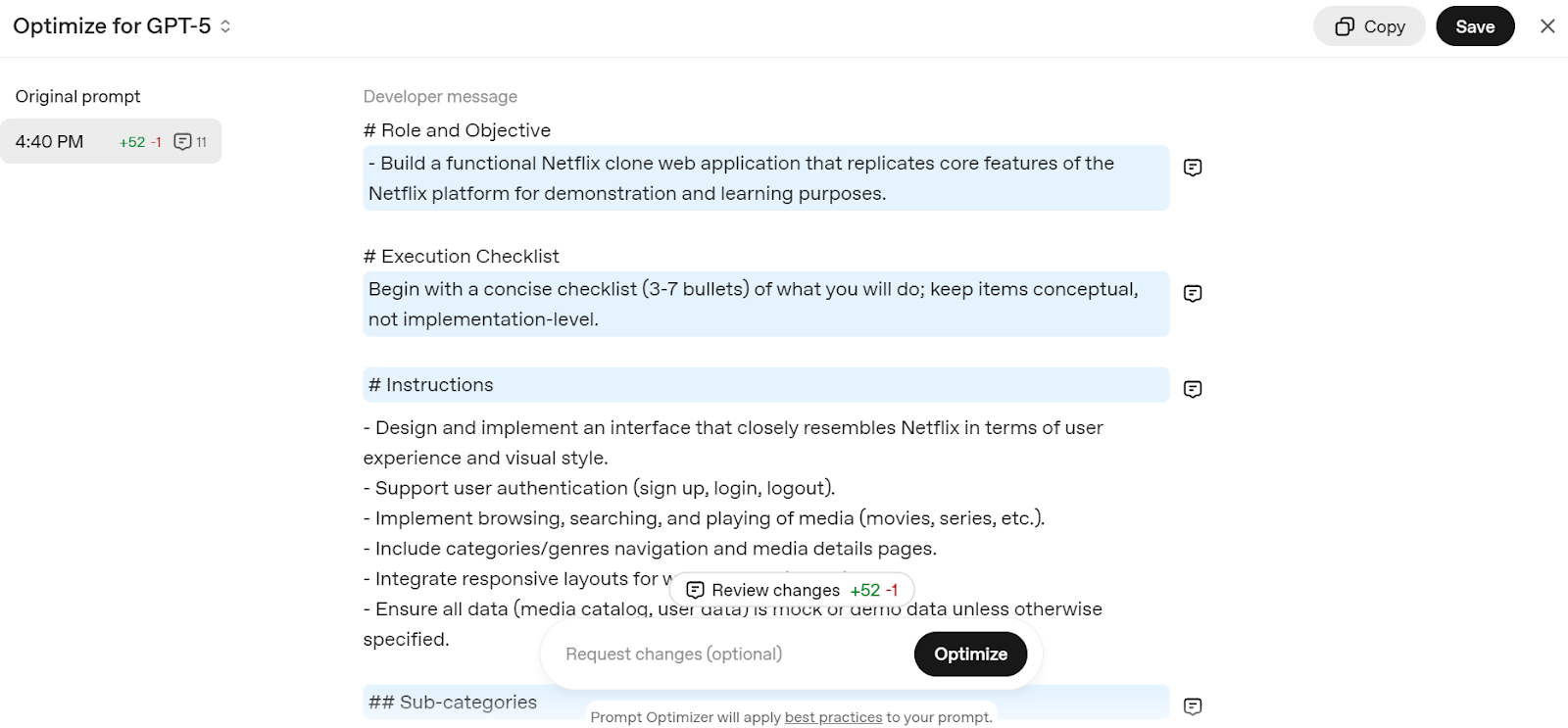
Source: Prompt Optimizer
Just copy the prompt and add it to the ChatGPT chat to start building your own Netflix web service.
OpenAI strongly recommends that developers migrate from older models to the new GPT‑5 family to reduce costs, improve accuracy, and enhance response quality.
Migration is straightforward; simply follow the table below to choose the right GPT‑5 model and reasoning level for your use case.
|
Current Model |
Recommended GPT-5 Model |
Starting Reasoning Level |
Migration Notes |
|
o3 |
GPT-5 |
Medium |
Start with medium reasoning + prompt tuning; increase to high if needed. |
|
gpt-4.1 |
GPT-5 |
Minimal |
Start with minimal reasoning + prompt tuning; increase to low for better performance. |
|
o4-mini |
GPT-5-mini |
Medium |
Use GPT-5-mini with prompt tuning. |
|
gpt-4.1-mini |
GPT-5-mini |
Minimal |
Use GPT-5-mini with prompt tuning. |
|
gpt-4.1-nano |
GPT-5-nano |
Minimal |
Use GPT-5-nano with prompt tuning. |
GPT-5 is more than just a smarter model; it is a developer toolkit for building intelligent, reliable, and efficient AI systems. With fine-grained control over reasoning, verbosity, tool usage, and output formats, it adapts to everything from quick coding tasks to complex multi-step workflows.
By leveraging its new features and best practices, you can develop production-ready AI applications using the OpenAI SDK with minimal effort.
If you’re new to working with OpenAI, be sure to check out the resources below:
Top OpenAI Courses
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
Tutorial
François Aubry
Tutorial
Marie Fayard
code-along
Richie Cotton
code-along
Zoumana Keita