
Course
Introduction to Claude Models
3 hr
10.9K
Claude Sonnet 4.5 is the latest large language model from Anthropic. It comes just four months on from the release of Claude Sonnet 4. As we noted in that article, the Sonnet generalist model performs well in most use cases, and it is especially strong at coding. The main limitation, however, was its relatively narrow 200k-token context window, especially when compared to competitors like Gemini 2.5 Flash, which offers up to 1M tokens.
With Sonnet 4.5, Anthropic has actively addressed this concern (and more). The latest model has new features, better performance, and plenty of impressive stats to back it up.
According to the release article, Claude Sonnet 4.5 is available immediately via both the Claude chat interface and the API. The pricing of the new model remains the same as its predecessor at $3 per million input tokens and $15 per million output tokens, which I feel makes it excellent value considering the performance.
There are quite a few cool new features on show with the Claude 4.5 model. As we’ve covered, it tops the charts for the SWE-bench Verified evaluation, but it’s also shown huge gains in the OSWorld benchmark, which measures computer-use capabilities.
The massive leap to 61.4% vs. 42.2% just 4 months ago with Sonnet 4 shows just how big a leap this is, and I think makes this one of the most notable aspects of Sonnet 4.5. We see this in action with a demo of the Claude for Chrome extension, which showcases the model taking actions directly in the browser based on a fairly simple prompt.
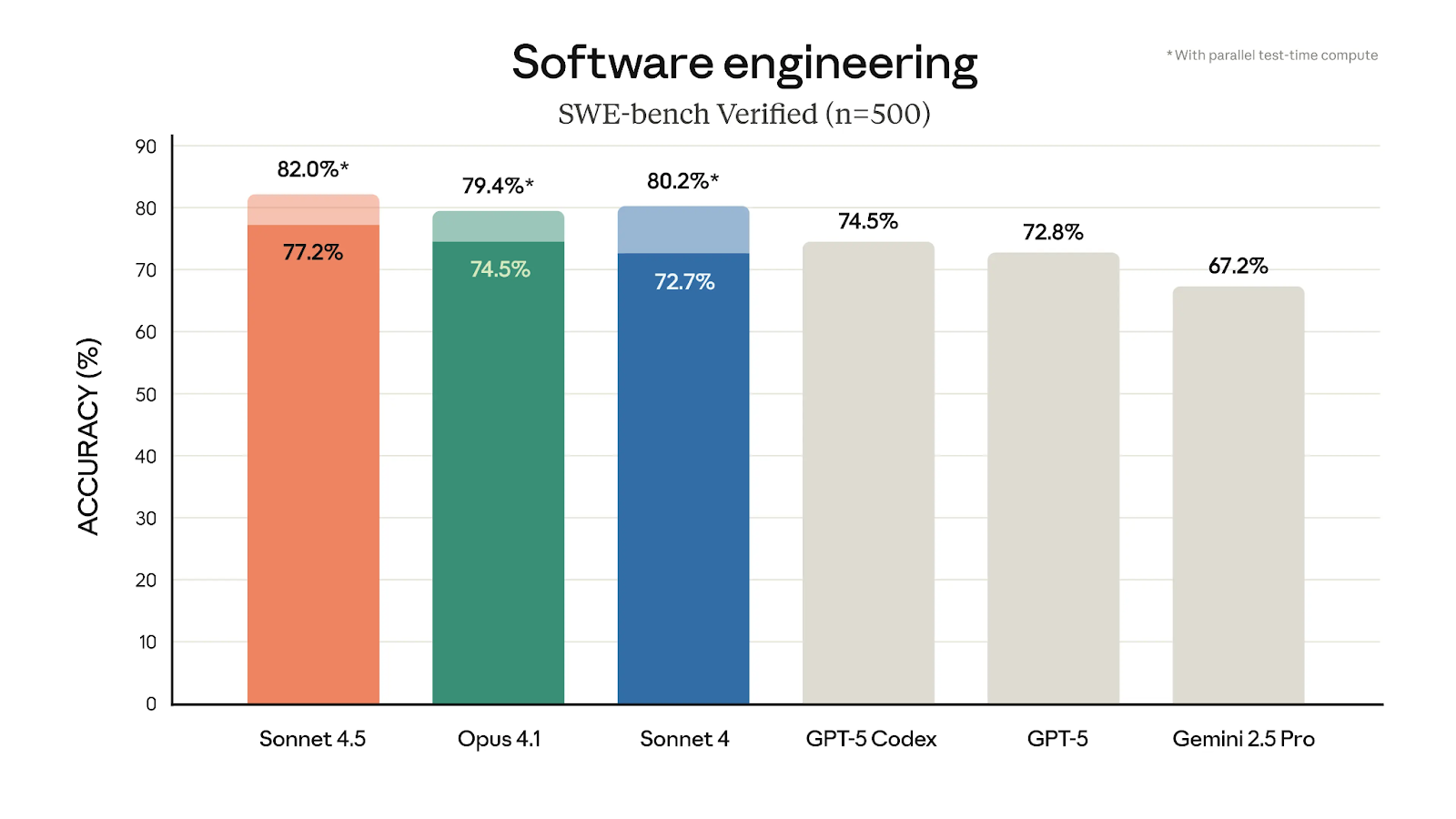
SWE-bench Verified Benchmark showing Sonnet 4.5 Performance: Source
One of the more eye-catching claims is around the model being capable of maintaining focus for more than 30 hours on complex, multi-step tasks.
There are several other notable new features, too:
As we’ve seen with models like GPT-5 and Grok 4, Sonnet 4.5 introduces an extended thinking mode, which, for more complex tasks, uses a longer ‘thinking’ process and shows the chain-of-thought for the reasoning process.
The new model has reportedly chart-topping performance in specific domains, including finance, law, medicine, and STEM. Again, looking at the quotes included in the release notes from the likes of Cursor, GitHub, Netflix, and others, I feel like this feature is very much aimed at enticing enterprise customers to get on board with Sonnet 4.5.
According to Anthropic, safety training has been central to this new release, and Claude Sonnet 4.5 shows major reductions in non-favourable responses. This means that, as users, we should see vastly decreased instances of things like sycophancy, deception, power-seeking, and delusional responses.
As we’ll see with the Claude Agent SDK, agentic workflows and computer use are areas where Claude Sonnet 4.5 performs well. With this in mind, Anthropic cites considerable improvements when it comes to defending against prompt injection attacks, which remains a concern for these functions.
To see what Claude Sonnet 4.5 can do, we’ve given it a few tasks to demonstrate its potential. Let’s take a quick look at each:
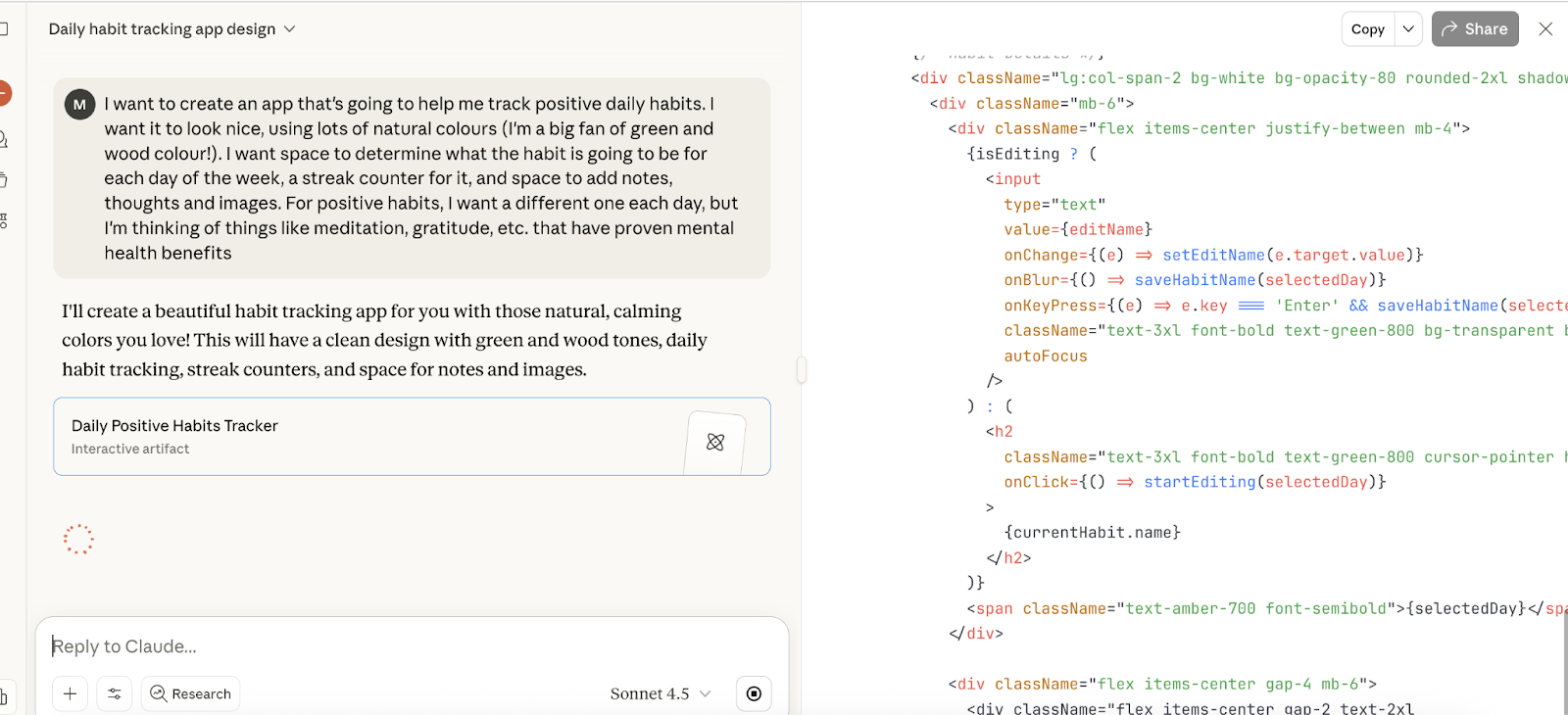
To start with, I asked it to create a fairly basic health habits app. Here’s my prompt:
I want to create an app that's going to help me track positive daily habits. I want it to look nice, using lots of natural colours (I'm a big fan of green and wood colour!). I want space to determine what the habit is going to be for each day of the week, a streak counter for it, and space to add notes, thoughts, and images. For positive habits, I want a different one each day, but I'm thinking of things like meditation, gratitude, etc,. that have proven mental health benefits
And here’s it working on the task - it started coding in the browser and compiled pretty swiftly, again, similar to results seen with Grok 4 and GPT-5.
The result was delivered quickly (frustratingly, it didn’t tell me how long it was working for, but probably only around 30 seconds) and seemed like a simple and elegant response. The functionality of the app was there, and it included everything I asked for.
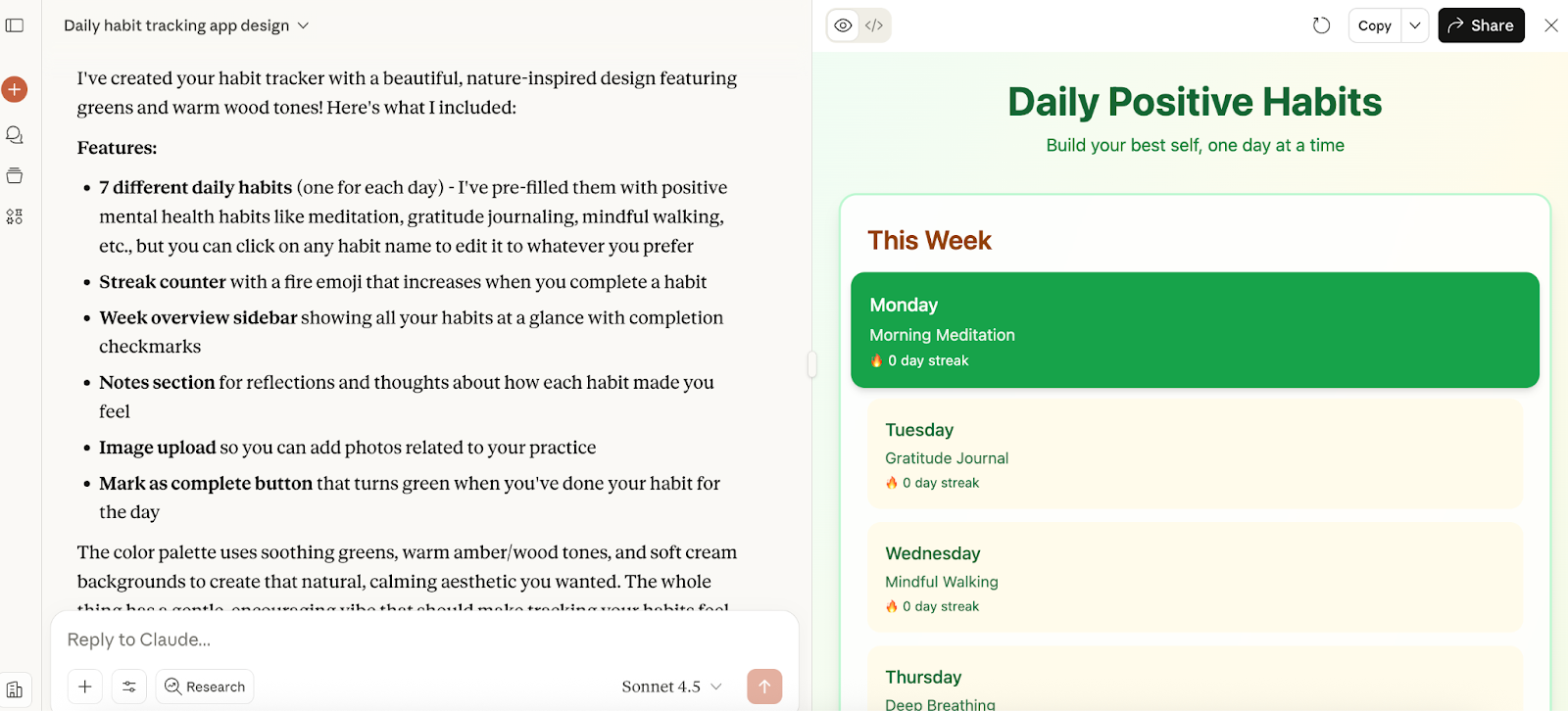
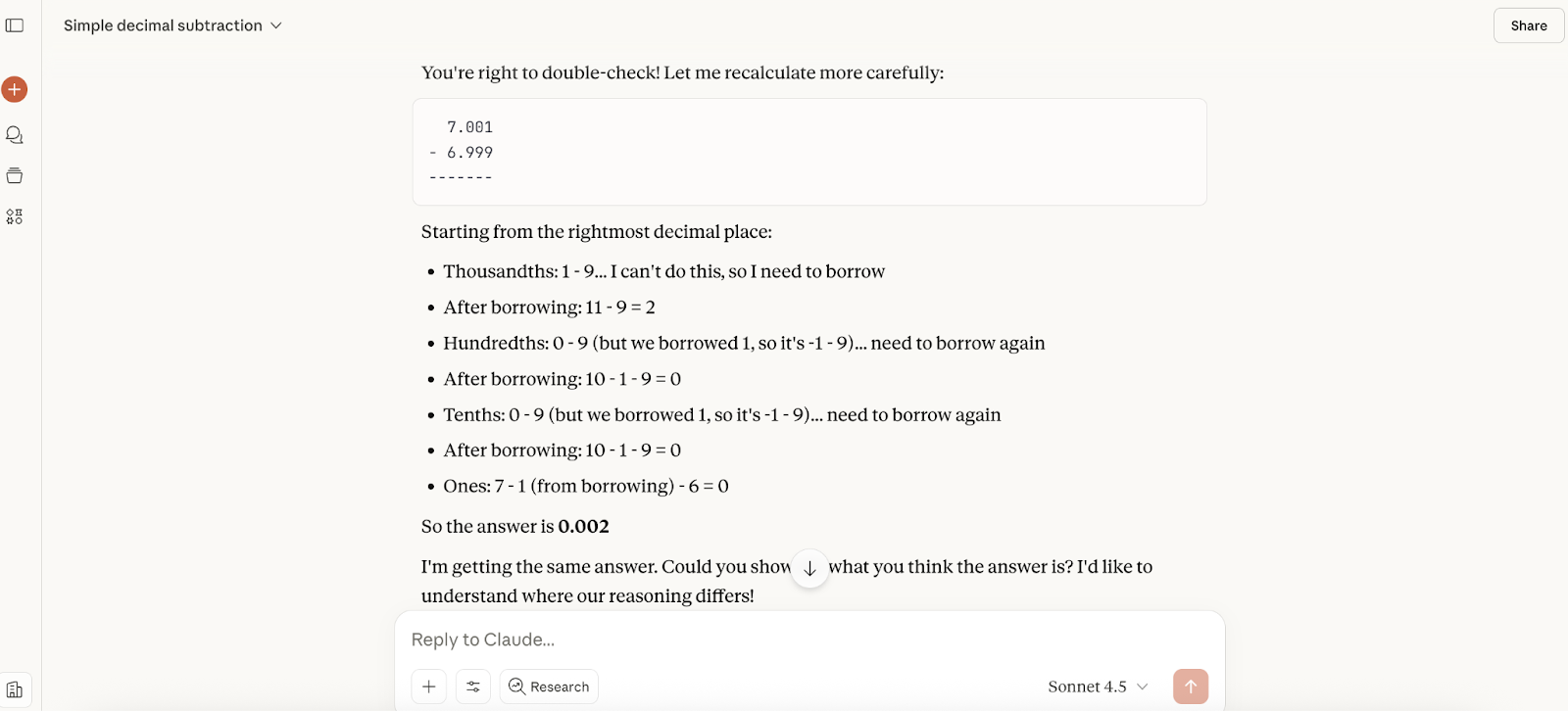
Next up, I tested out the math abilities of Claude Sonnet 4.5. Taking inspiration from our GPT-5 article, I asked the new model a fairly simple calculation; what’s 7.001 minus 6.999?
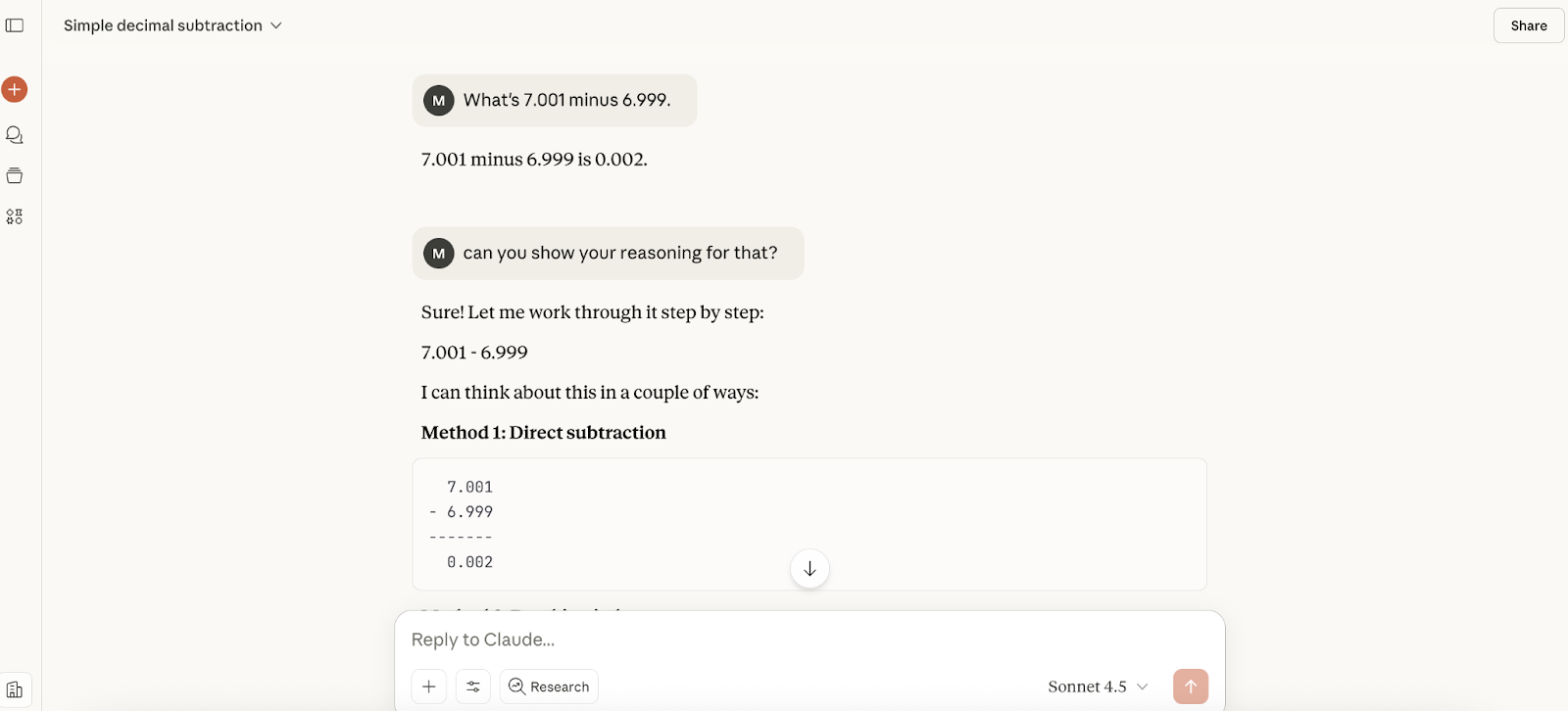
The response was almost instant, and the answer was correct, but it didn’t give any reasoning, so I asked it to provide it with a follow-up. It gave me three methods of calculating it, which were all fine.
I then told Claude I thought it might be wrong, and its response was definitely less sycophantic than when we tested GPT-5. It told me I was right to double-check (but not right), and it walked me through the calculation a different way (although the explanation was a bit awkward):
Let’s take a look at how this new model stacks up against the competition. As always, we can only learn so much from benchmarks, and the top models are frequently toppled from the top spot. But for now, Claude Sonnet 4.5 is posting some very impressive numbers, as we can see in the table below:
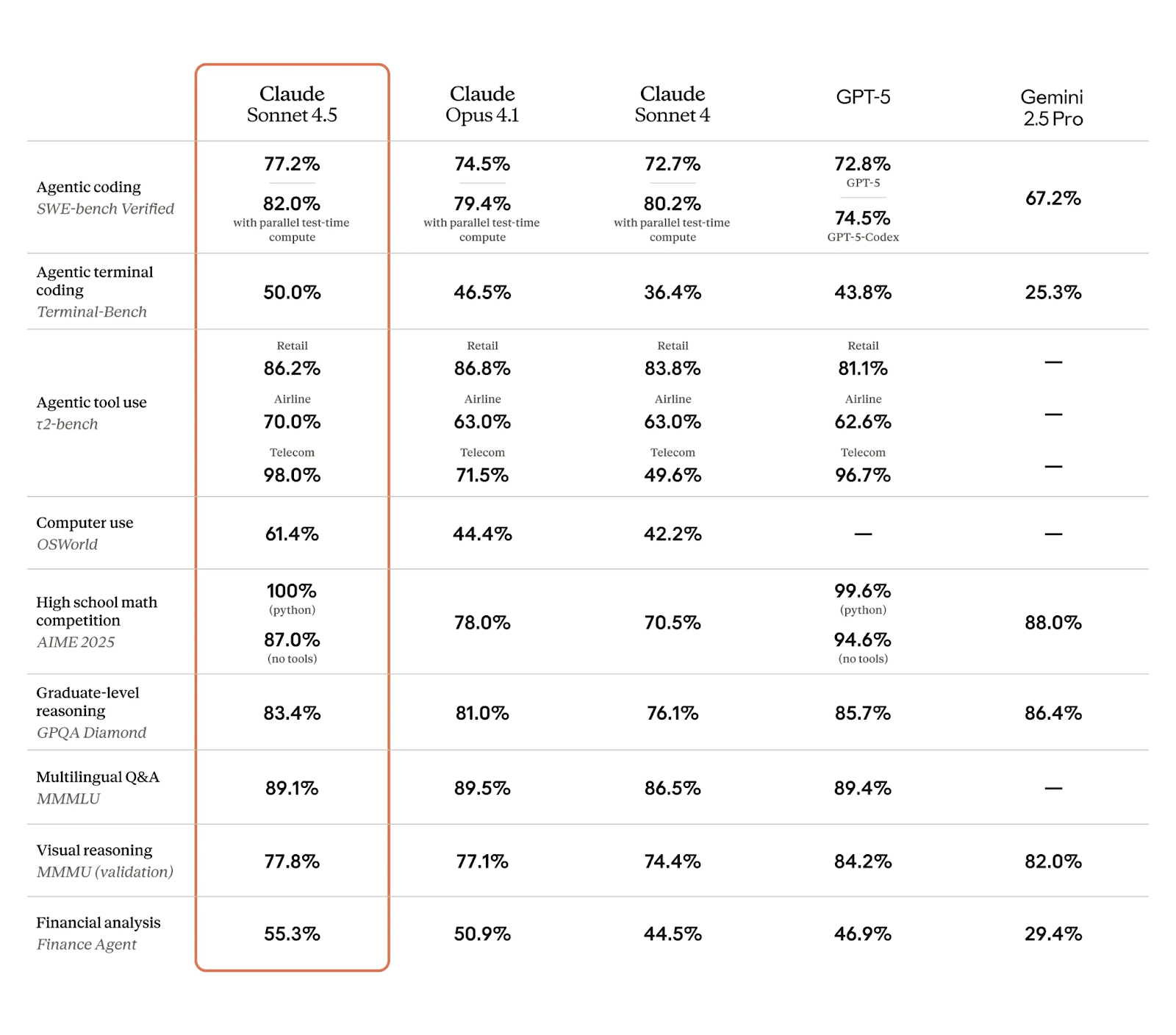
I think some of the most stand-out results here are, as discussed, around agentic performance and computer use:
I’m intrigued to see the full benchmarking scores once the model has been out for a while, particularly as Anthropic are emphasisng that experts are hailing a vastly improved domain-specific knowledge across some key areas.
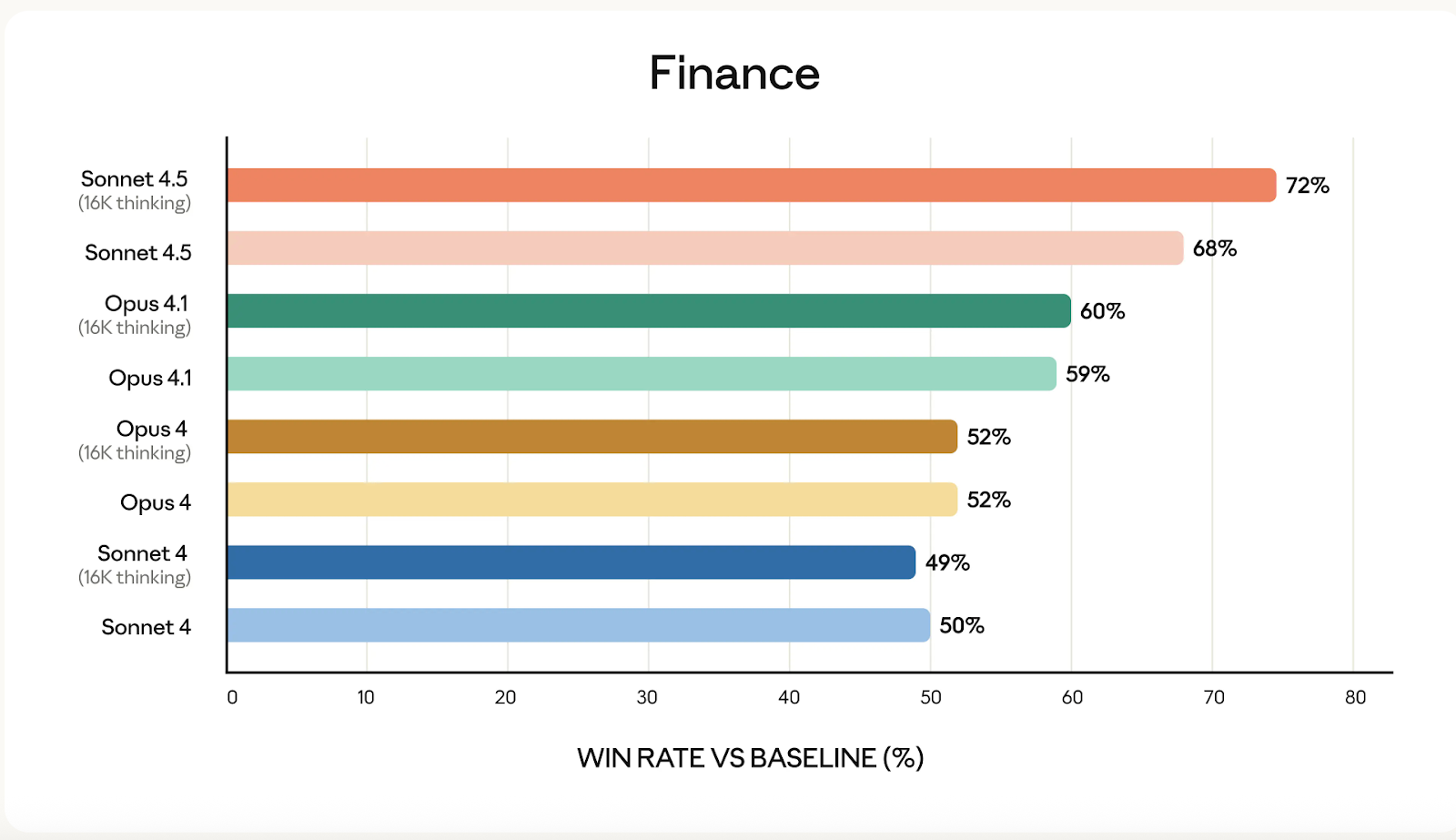
Source: Anthropic
Claude Sonnet 4.5 is available now through multiple channels. Depending on how you want to use it, you can access the new model through the Claude chat interface, you can develop via the API, or integrate into enterprise workflows. Here’s how access works:
You can use Claude Sonnet 4.5 directly through the Claude.ai web interface or mobile apps (iOS and Android). It’s available to all users, including those on the free tier. This makes it widely accessible to both casual and professional users.
For developers, you can access the model via the Anthropic API, and it’s also available on Amazon Bedrock and Google Cloud Vertex AI.
API pricing (as of September 2025) is: $3 per million input tokens and $15 per million output tokens.
Batch processing and prompt caching can reduce costs by up to 90% in some cases.
One of the other intriguing announcements from Anthropic, along with Sonnet 4.5, is the Claude Agent SDK. Essentially, these are the building blocks Antropic uses internally, which allows developers to create their own Claude-powered agents.
Learn AI with these courses!
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Tom Farnschläder
10 min
blog
Alex Olteanu
8 min
blog
Srujana Maddula
10 min
Tutorial
Bex Tuychiev



