
Curso
Introducción a los modelos Claude
3 h
1.7K
Claude Sonnet 4.5 es el último modelo de lenguaje grande de Anthropic. Llega solo cuatro meses después del lanzamiento de Claude Sonnet 4. Como señalamos en ese artículo, el modelo generalista Sonnet funciona bien en la mayoría de los casos de uso y es especialmente eficaz en la codificación. Sin embargo, la principal limitación era su ventana contextual relativamente estrecha de 200 000 tokens, especialmente en comparación con competidores como Gemini 2.5 Flash, que ofrece hasta 1 millón de tokens.
Con Sonnet 4.5, Anthropic ha abordado activamente esta preocupación (y otras más). El último modelo tiene nuevas características, un mejor rendimiento y un montón de estadísticas impresionantes que lo respaldan.
Según el artículo de lanzamiento, Claude Sonnet 4.5 ya está disponible a través de la interfaz de chat de Claude y la API. El precio del nuevo modelo sigue siendo el mismo que el de su predecesor: 3 dólares por cada millón de tokens de entrada y 15 dólares por cada millón de tokens de salida, lo que, en mi opinión, lo convierte en una excelente opción teniendo en cuenta su rendimiento.
El modelo Claude 4.5 presenta varias funciones nuevas muy interesantes. Como ya hemos comentado, encabeza las listas de la evaluación SWE-bench Verified, pero también ha obtenido grandes avances en la prueba de rendimiento OSWorld, que mide capacidades de uso del ordenador.
El enorme salto al 61,4 % frente al El 42,2 % hace solo cuatro meses con Sonnet 4 demuestra lo grande que es este salto, y creo que es uno de los aspectos más destacables de Sonnet 4.5. Podemos verlo en acción con una demostración de la extensión Claude para Chrome, que muestra cómo el modelo realiza acciones directamente en el navegador basándose en una indicación bastante sencilla.
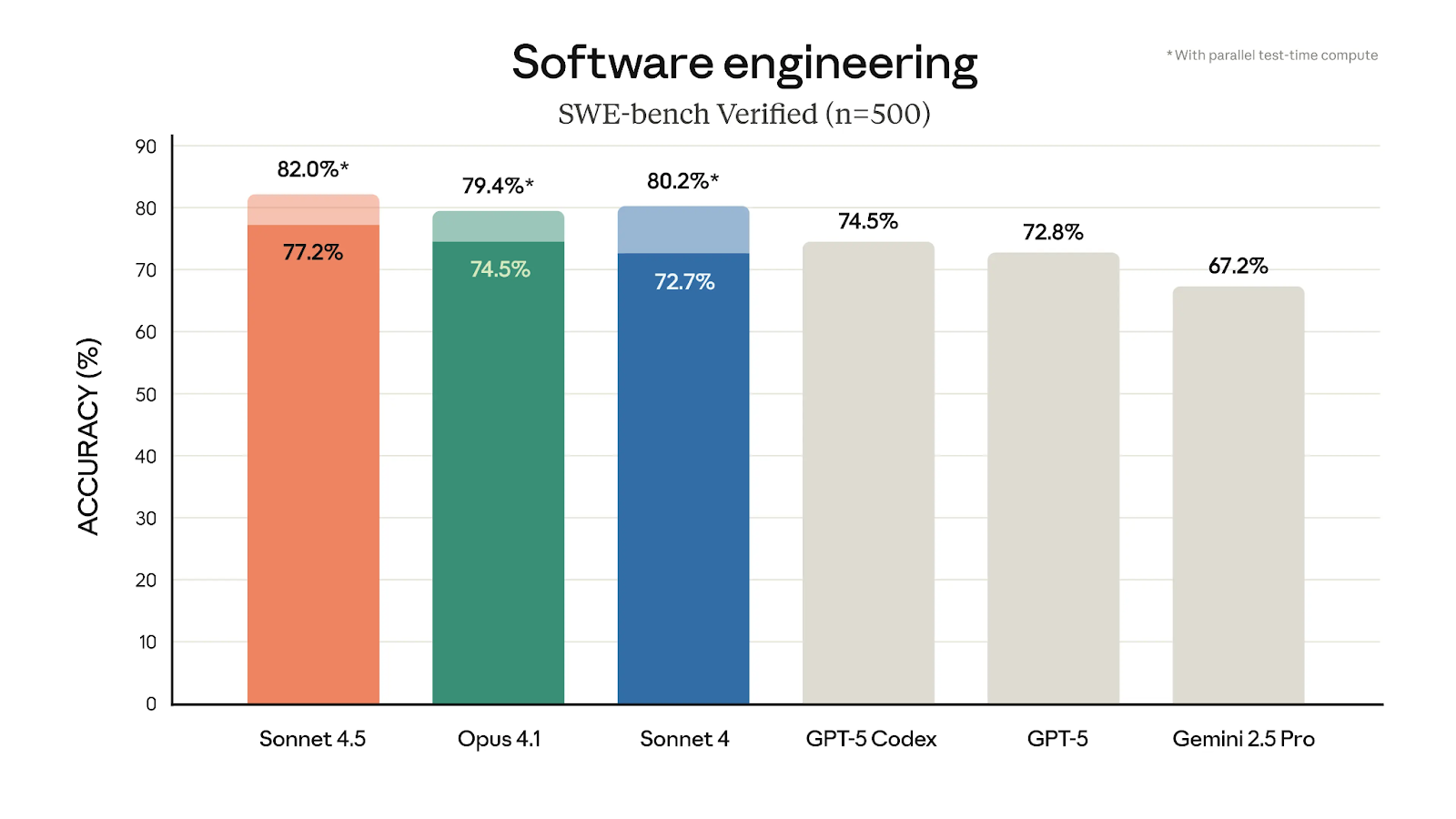
Benchmark verificado por SWE-bench que muestra el rendimiento de Sonnet 4.5: Fuente
Una de las afirmaciones más llamativas es que el modelo es capaz de mantener la concentración durante más de 30 horas en tareas complejas de varios pasos.
Hay otras novedades destacables:
Como hemos visto con modelos como GPT-5 y Grok 4, Sonnet 4.5 introduce un modo de pensamiento ampliado que, para tareas más complejas, utiliza un proceso de «pensamiento» más largo y muestra la cadena de pensamiento del proceso de razonamiento.
Según se informa, el nuevo modelo tiene un rendimiento líder en ámbitos específicos, como las finanzas, el derecho, la medicina y las ciencias, la tecnología, la ingeniería y las matemáticas (STEM). Una vez más, al ver las citas incluidas en las notas de la versión de Cursor, GitHub, Netflix y otros, creo que esta función está muy orientada a atraer a los clientes empresariales para que se sumen a Sonnet 4.5.
Según Anthropic, la formación en materia de seguridad ha sido fundamental en esta nueva versión, y Claude Sonnet 4.5 muestra una reducción significativa de las respuestas desfavorables. Esto significa que, como usuarios, deberíamos ver una disminución considerable de casos como el adulación, el engaño, la búsqueda de poder y las respuestas delirantes.
Como veremos con el SDK de Claude Agent, los flujos de trabajo agenticos y el uso de ordenadores son áreas en las que Claude Sonnet 4.5 funciona bien. Teniendo esto en cuenta, Anthropic menciona mejoras considerables en lo que respecta a la defensa contra la inyección de comandos, que siguen siendo una preocupación para estas funciones.
Para ver lo que Claude Sonnet 4.5 es capaz de hacer, le hemos asignado algunas tareas con el fin de demostrar su potencial. Echemos un vistazo rápido a cada uno de ellos:
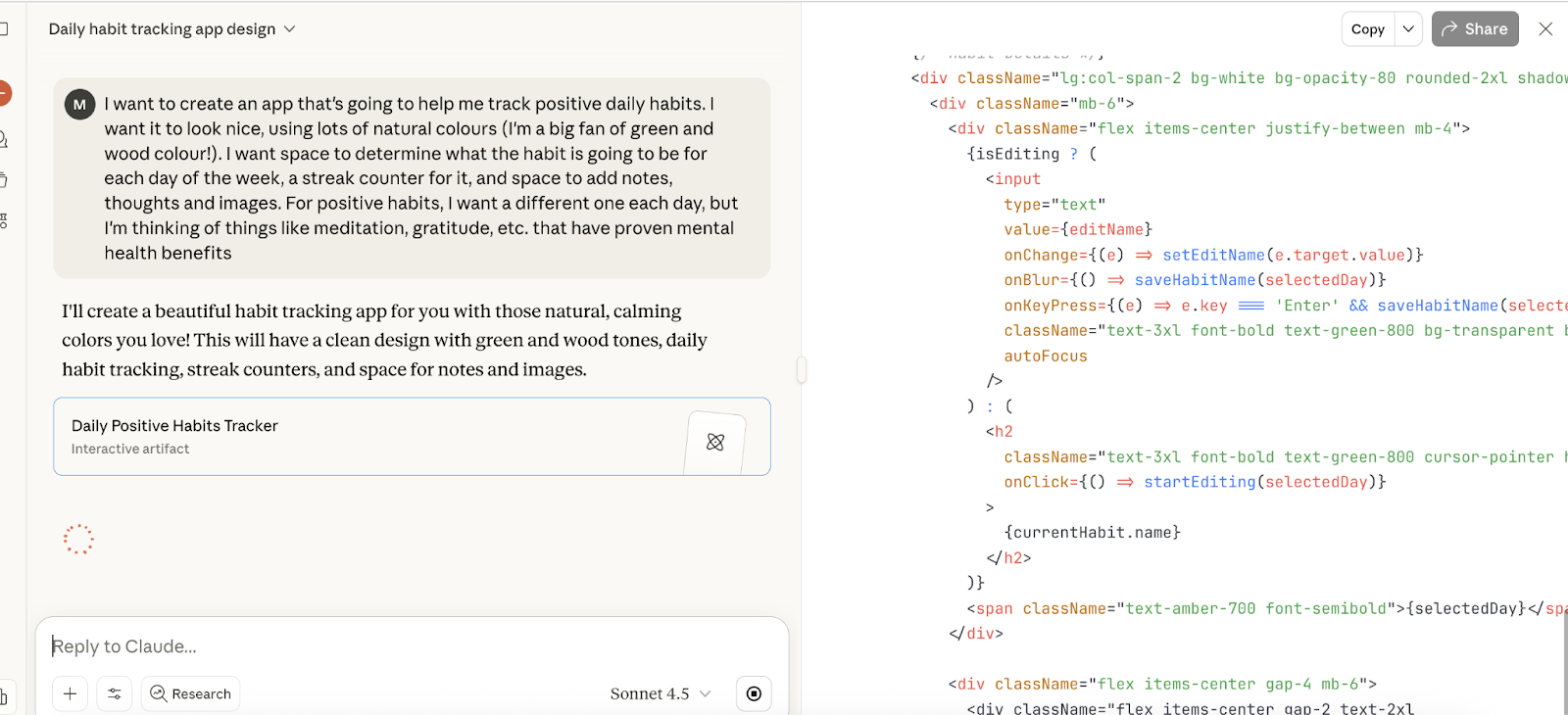
Para empezar, te pedí que crearas una aplicación bastante básica sobre hábitos saludables. Aquí está mi sugerencia:
Quiero crear una aplicación que me ayude a llevar un programa de los hábitos positivos diarios. Quiero que quede bonito, utilizando muchos colores naturales (¡me encanta el verde y el color madera!). Quiero espacio para determinar cuál será el hábito para cada día de la semana, un contador de rachas para ello y espacio para añadir notas, pensamientos e imágenes. En cuanto a los hábitos positivos, quiero uno diferente cada día, pero estoy pensando en cosas como la meditación, la gratitud, etc., que han demostrado tener beneficios para la salud mental.
Y aquí lo vemos trabajando en la tarea: comenzó a codificar en el navegador y compiló con bastante rapidez, de nuevo, de forma similar a los resultados observados con Grok 4 y GPT-5.
El resultado se obtuvo rápidamente (por desgracia, no me indicó cuánto tiempo tardó, pero probablemente solo unos 30 segundos) y parecía una respuesta sencilla y elegante. La funcionalidad de la aplicación estaba ahí e incluía todo lo que pedí.
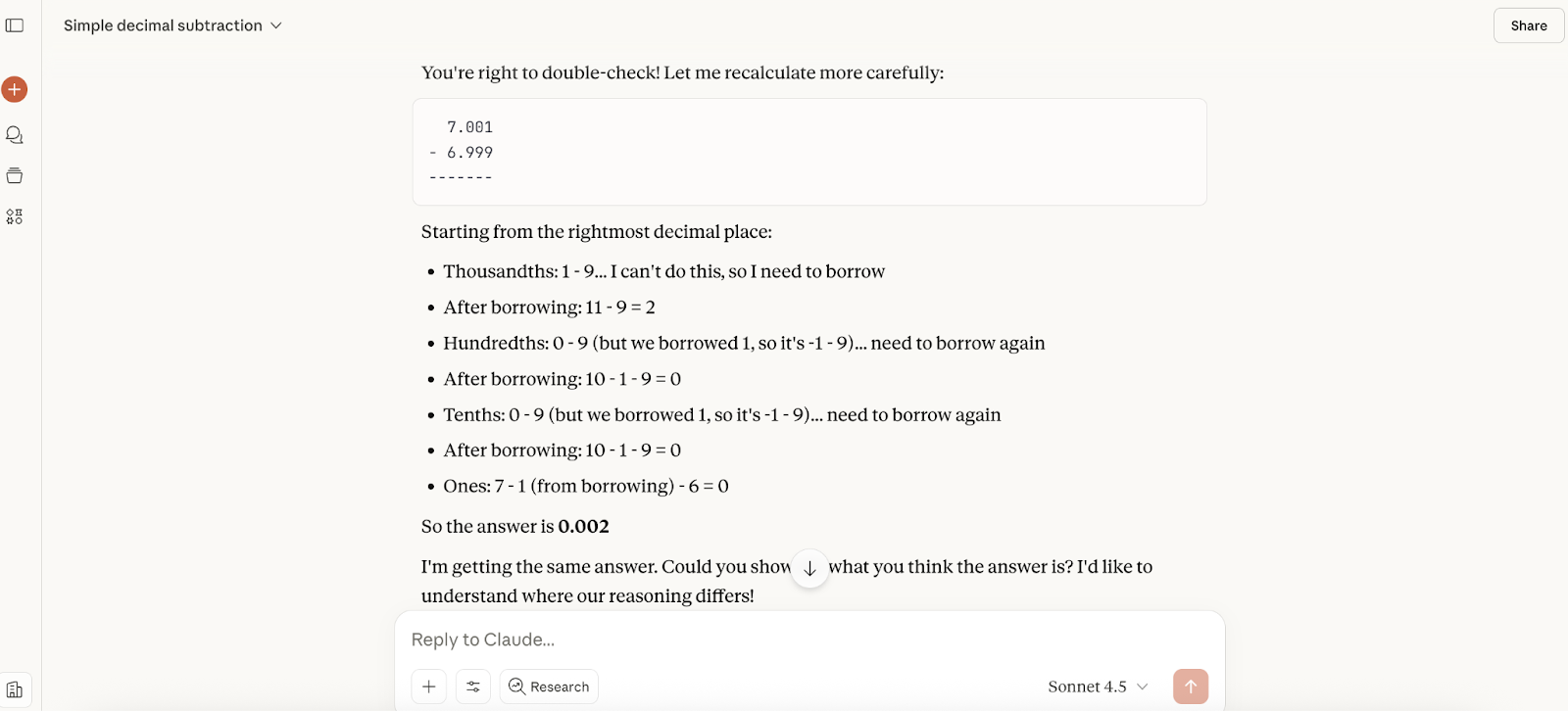
A continuación, probé las habilidades matemáticas de Claude Sonnet 4.5. Inspirándonos en nuestro artículo sobre GPT-5, le pedí al nuevo modelo que realizara un cálculo bastante sencillo: ¿cuánto es 7,001 menos 6,999?
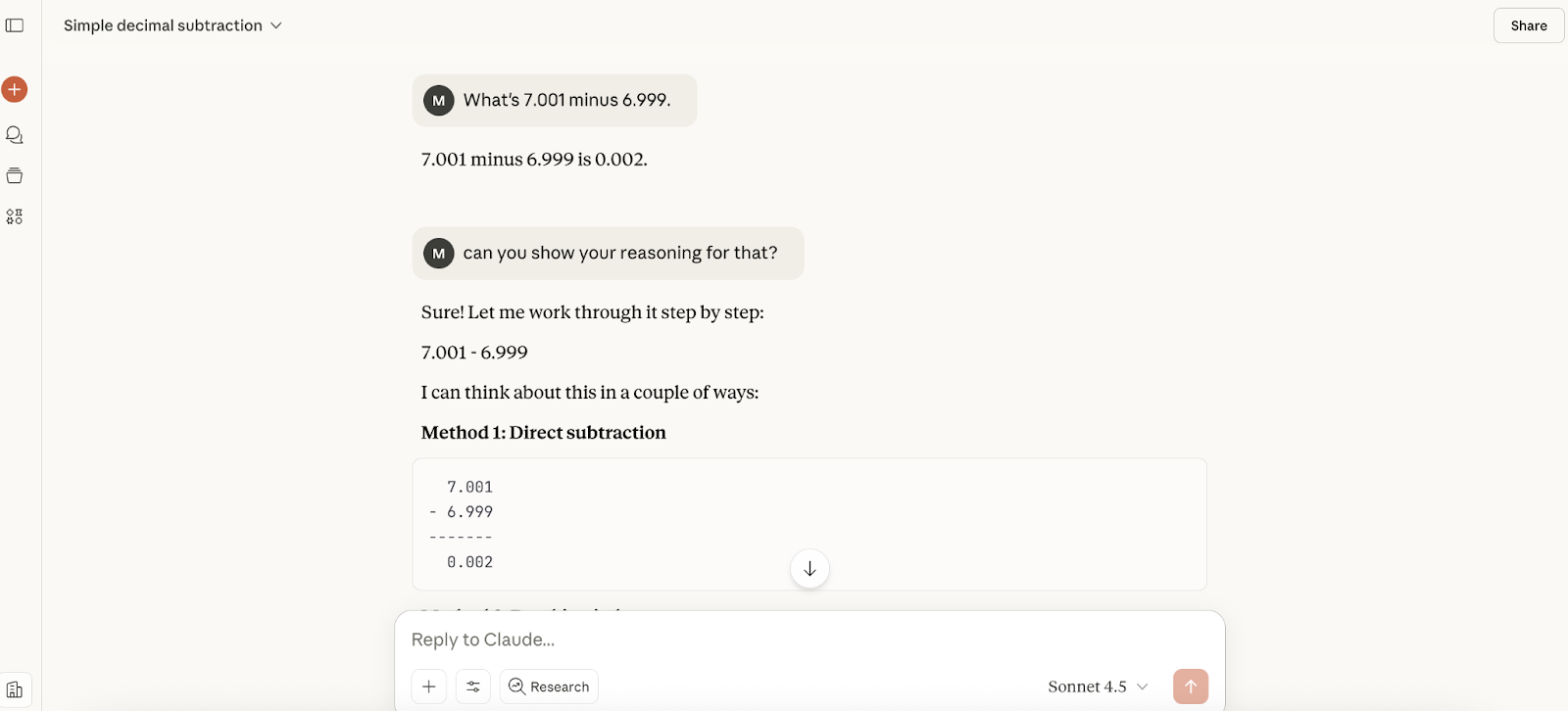
La respuesta fue casi instantánea y correcta, pero no ofrecía ningún razonamiento, así que le pedí que lo proporcionara en una pregunta de seguimiento. Me dio tres métodos para calcularlo, todos ellos correctos.
Entonces le dije a Claude que pensaba que podría estar equivocado, y su respuesta fue sin duda menos aduladora que cuando probamos GPT-5. Me dijo que había hecho bien en volver a comprobarlo (pero que no era correcto) y me explicó el cálculo de otra manera (aunque la explicación era un poco extraña):
Echemos un vistazo a cómo se compara este nuevo modelo con la competencia. Como siempre, solo podemos aprender hasta cierto punto de los puntos de referencia, y los modelos más vendidos suelen perder el primer puesto con frecuencia. Pero, por ahora, Claude Sonnet 4.5 está registrando unas cifras muy impresionantes, como se puede ver en la tabla siguiente:
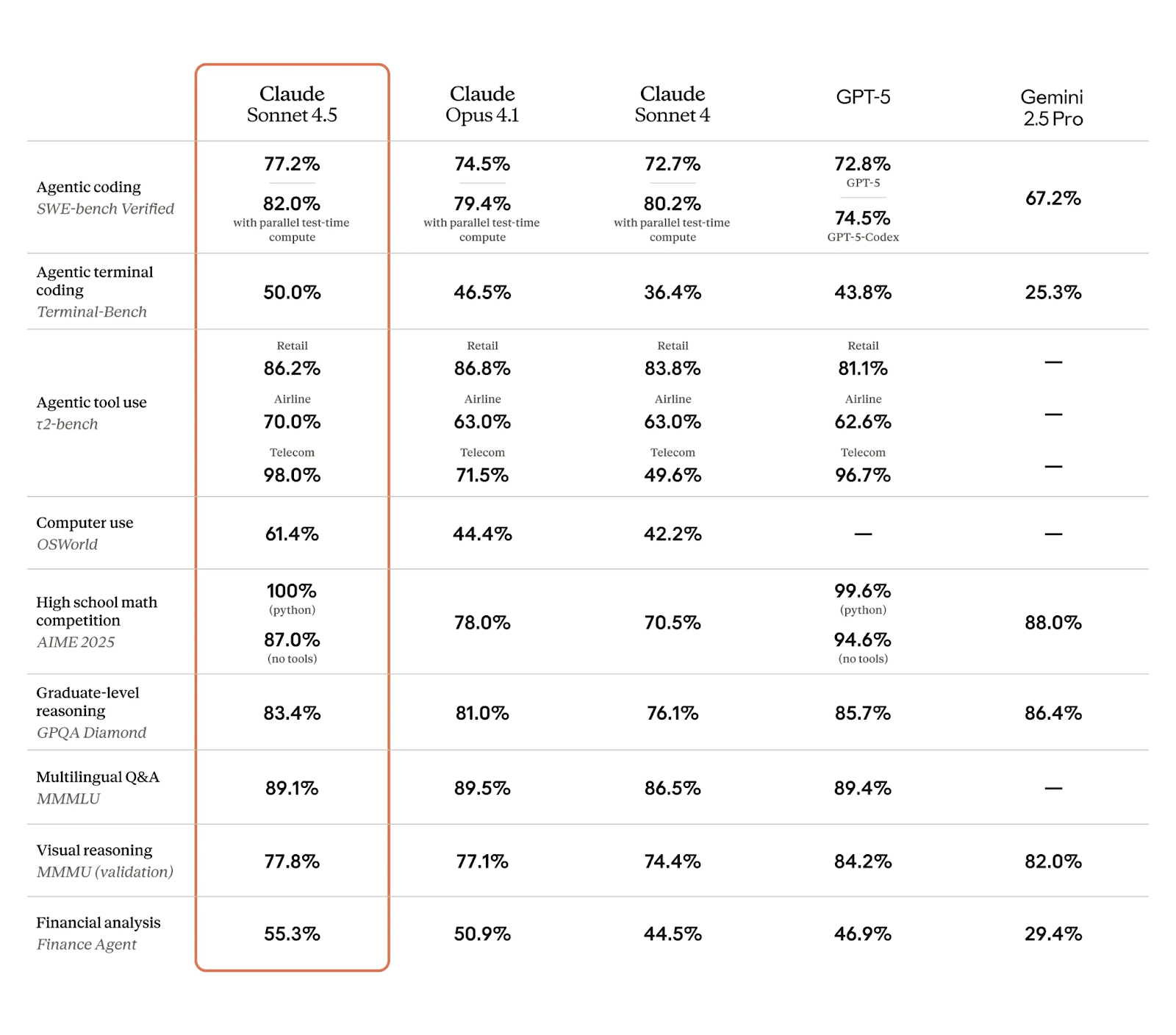
Creo que algunos de los resultados más destacados aquí son, como ya se ha comentado, los relacionados con el rendimiento de los agentes y el uso de ordenadores:
Tengo curiosidad por ver las puntuaciones completas de la evaluación comparativa una vez que el modelo lleve un tiempo en funcionamiento, sobre todo porque Anthropic destaca que los expertos están elogiando una mejora considerable del conocimiento específico del dominio en algunas áreas clave.
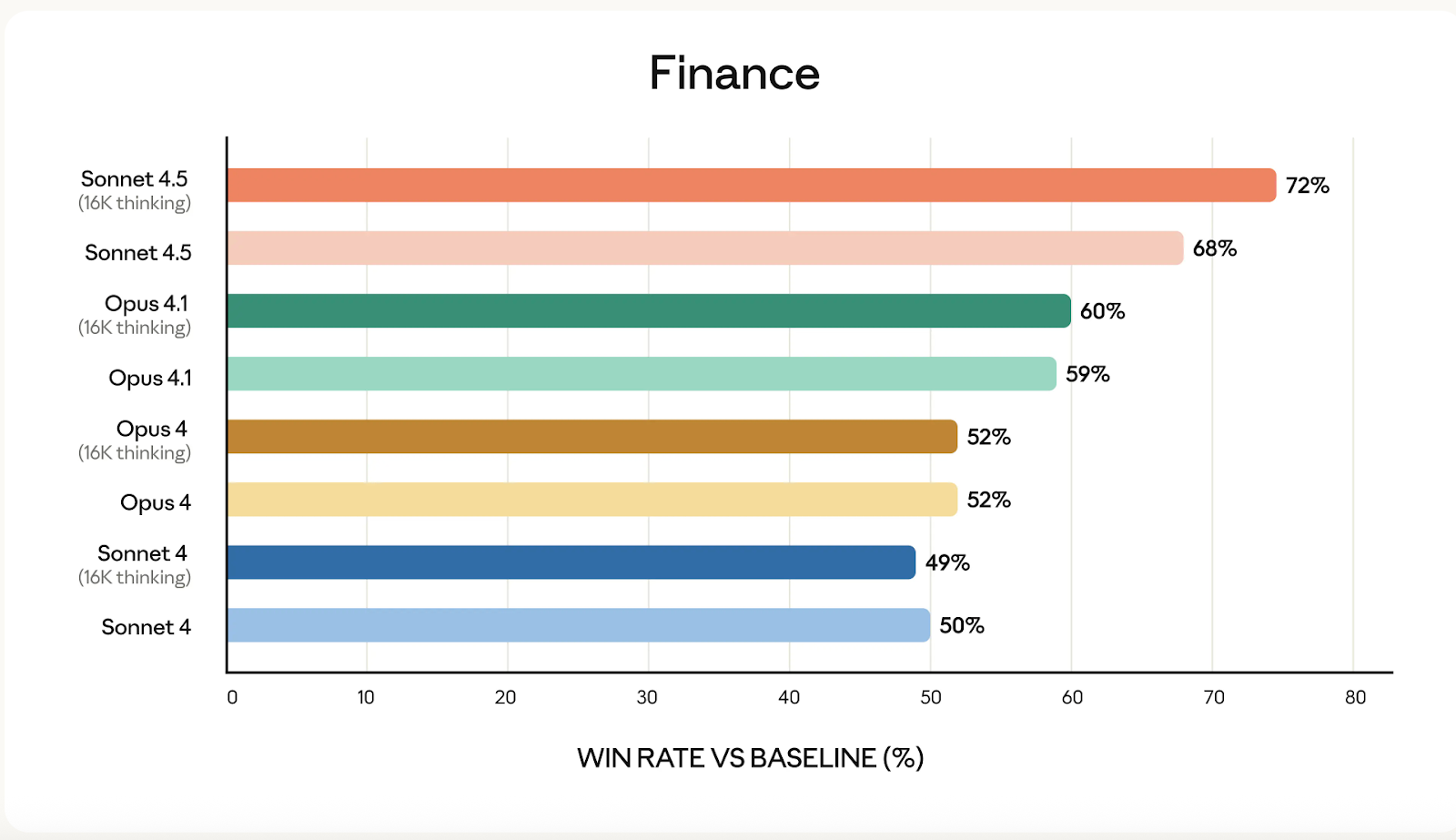
Fuente: Antrópico
Claude Sonnet 4.5 ya está disponible a través de múltiples canales. Dependiendo de cómo quieras utilizarlo, puedes acceder al nuevo modelo a través de la interfaz de chat de Claude, desarrollarlo a través de la API o integrarlo en los flujos de trabajo de la empresa. Así es como funciona el acceso:
Puedes utilizar Claude Sonnet 4.5 directamente a través de Claude.ai o las aplicaciones móviles (iOS y Android). Está disponible para todos los usuarios, incluidos los que tienen el plan gratuito. Esto lo hace ampliamente accesible tanto para usuarios ocasionales como profesionales.
Los programadores pueden acceder al modelo a través de la API de Anthropic, y también está disponible en Amazon Bedrock y Google Cloud Vertex AI.
El precio de la API (a partir de septiembre de 2025) es: 3 dólares por cada millón de tokens de entrada y 15 dólares por cada millón de tokens de salida.
El procesamiento por lotes y el almacenamiento en caché inmediato pueden reducir los costes hasta en un 90 % en algunos casos.
Otro de los anuncios más interesantes de Anthropic, junto con Sonnet 4.5, es el SDK de Claude Agent. Básicamente, estos son los componentes básicos que Antropic utiliza internamente, lo que permite a los programadores crear sus propios agentes basados en Claude.
¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Ryan Ong
8 min
blog
Abid Ali Awan
9 min
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Arunn Thevapalan

