
Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
38.2K
La generación aumentada por recuperación (RAG) es una de las técnicas más interesantes de la IA en la actualidad. Combina la precisión de recuperar información real de conjuntos de datos masivos con la capacidad de razonamiento de los grandes modelos lingüísticos. ¿El resultado? Respuestas que no solo son precisas, sino también muy relevantes. Por eso RAG impulsa todo, desde chatbots y motores de búsqueda hasta contenido personalizado.
Pero aquí está el problema: construir un prototipo es solo la mitad del trabajo. El verdadero reto reside enla implementación de un modelo de negocio de suscripción ( ): convertir tu idea en un producto fiable y escalable.
En este artículo, te mostraré cómo crear e implementar un sistema RAG utilizando LangChain y FastAPI. Aprenderás cómo pasar de un prototipo funcional a una aplicación a gran escala lista para usuarios reales.
¡Vamos a ello!
Como analizamos en otra guía, la generación aumentada por recuperación, o RAG, es un método bastante avanzado en el procesamiento del lenguaje natural que realmente mejora lo que pueden hacer los modelos de lenguaje.
En lugar de basarse únicamente en lo que el modelo ya sabe, RAG va más allá y recopila información nueva y relevante de fuentes externas antes de generar una respuesta.
Así es como funciona: cuando un usuario hace una pregunta, el sistema no se basa únicamente en los datos preaprendidos del modelo. Primero sale, busca en un gran conjunto de documentos o fuentes de datos, toma los fragmentos más relevantes y luego los introduce en el modelo de lenguaje. Con tu conocimiento integrado y esta información recién obtenida, el modelo puede crear una respuesta mucho más precisa y actualizada.
RAG combina la recuperación y la generación, por lo que las respuestas no solo son inteligentes, sino que también se basan en información real y objetiva. Esto lo hace perfecto para cosas como responder preguntas, chatbots o incluso generar contenido en el que es realmente importante obtener la información correcta y comprender el contexto.
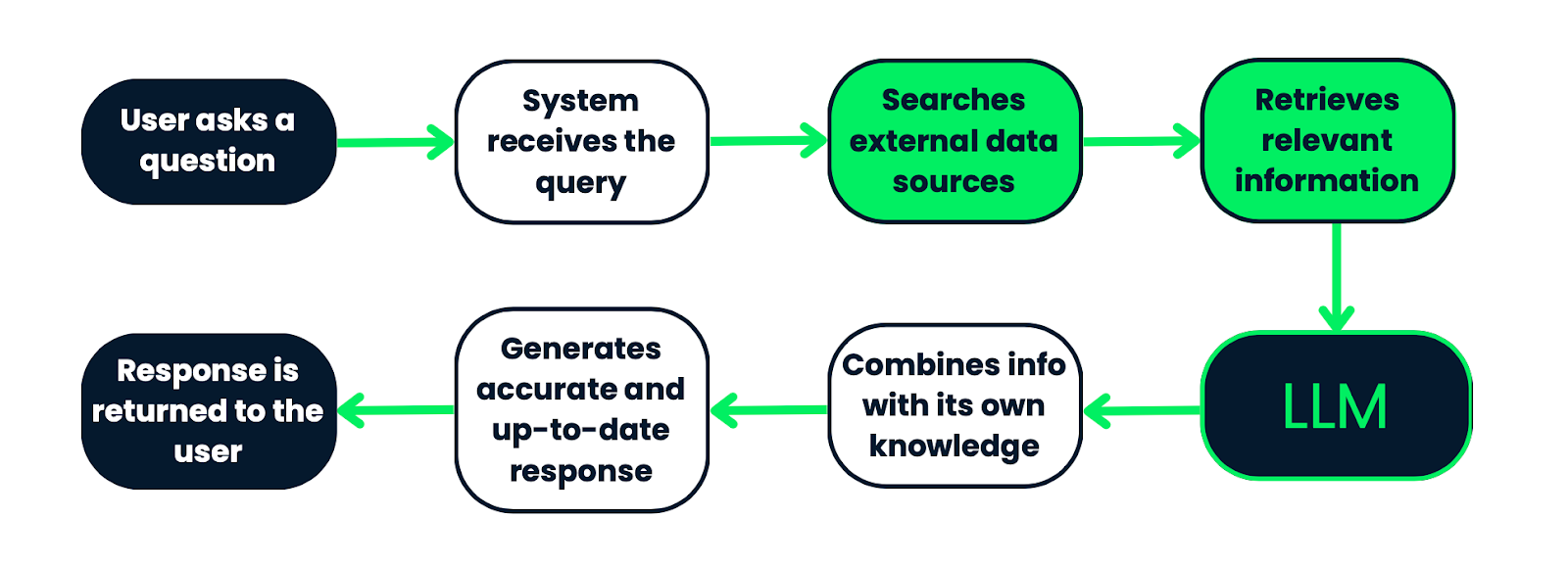
Flujo de trabajo de un sistema RAG. Comienza con una consulta del usuario, que es procesada por el sistema para buscar información relevante en fuentes de datos externas. A continuación, la información recuperada se introduce en un LLM, que la combina con sus conocimientos previos para generar una respuesta precisa y actualizada. Por último, la respuesta se devuelve al usuario. Este proceso garantiza que las respuestas se basen en datos objetivos y contextualmente relevantes.
Cuando estás creando un sistema RAG, hay algunas partes esenciales para ponerlo en marcha: cargadores de documentos, división de texto, indexación, modelos de recuperación y modelos generativos. Analicémoslo:
El primer paso es preparar tus datos. Eso es lo que hacen los cargadores de documentos, la división de texto y la indexación:
Estos son el núcleo del sistema RAG. Son responsables de buscar entre todos esos datos indexados para encontrar lo que necesitas.
Ahora, aquí es donde ocurre la magia. Una vez recuperados los datos relevantes, los modelos generativos toman el control y producen una respuesta final.
|
Componente |
Descripción |
|
Cargadores de documentos |
Importa datos de fuentes como archivos de texto, PDF o bases de datos, y convierte la información a un formato utilizable por el sistema. |
|
División de texto |
Chops carga los datos en fragmentos más pequeños, lo que facilita la búsqueda y el procesamiento dentro de los límites de los modelos de lenguaje. |
|
Indexación |
Organiza los datos divididos en representaciones vectoriales, lo que permite realizar búsquedas rápidas y eficientes para encontrar información relevante para una consulta. |
|
Tiendas Vector |
Bases de datos especializadas que almacenan representaciones vectoriales y utilizan la búsqueda por similitud vectorial para recuperar la información más relevante en función de la consulta. |
|
Perros cobradores |
Busca componentes que conviertan la consulta en un vector, busca en el almacén de vectores y recupera los fragmentos de datos más relevantes para el siguiente paso. |
|
Modelos lingüísticos |
Genera respuestas coherentes y adecuadas al contexto utilizando tanto los datos recuperados como tus conocimientos internos. |
|
Generación de respuestas contextuales |
Combina la pregunta del usuario con los datos recuperados para crear una respuesta detallada que responda a la pregunta e incorpore la información relevante. |
Antes de crear nuestro sistema RAG, debemos asegurarnos de que tu entorno de desarrollo esté correctamente configurado. Esto es lo que necesitarás:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsInstalar dependencias: Ahora, instala los paquetes necesarios utilizando pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
Un moderno marco web para crear API. |
Un servidor ASGI para dar servicio a tu aplicación FastAPI. |
La biblioteca principal que alimenta el sistema RAG. |
Utilizar modelos GPT para la generación de respuestas. |
Consejo profesional: Asegúrate de crear un archivo requirements.txt para especificar los paquetes necesarios para tu proyecto. Si utilizas: pip freeze > requirements.txt
Este comando generará un archivo requirements.txt que contiene todos los paquetes instalados y sus versiones, que puedes utilizar para implementar o compartir el entorno con otras personas.
Añade tu clave API de OpenAI: Para integrar el modelo de lenguaje OpenAI en tu sistema RAG, deberás proporcionar tu clave API de OpenAI:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Ahora, tu clave API de OpenAI se carga de forma segura desde el entorno y ya estás listo para empezar a utilizarla en tu sistema RAG.
PostgreSQL y PGVector (opcional): Si tienes pensado utilizar PGVector para el almacenamiento vectorial, asegúrate de instalar y configurar PostgreSQL en tu equipo. Puedes utilizar FAISS (que utilizaremos en este artículo) u otras bases de datos vectoriales compatibles con LangChain.
Docker (opcional): Docker puede ayudarte a contenerizar tu aplicación para garantizar una implementación coherente en todos los entornos. Si tienes pensado utilizar Docker, asegúrate de que también está instalado en tu equipo.
El primer paso para crear un sistema RAG es preparar los datos que el sistema utilizará para recuperar información relevante. Esto implica cargar documentos en el sistema, procesarlos y, a continuación, asegurarse de que estén en un formato que permita indexarlos y recuperarlos fácilmente.
LangChain proporciona varios cargadores de documentos para gestionar diferentes fuentes de datos, como archivos de texto, PDF o páginas web. Puedes utilizar estos cargadores para introducir tus documentos en el sistema.
Me fascinan los osos polares, así que he decidido subir el siguiente archivo de texto (mi_documento.txt) que contiene esta información:«Osos polares: Los gigantes del Ártico
Los osos polares (Ursus maritimus) son los carnívoros terrestres más grandes del planeta y se han adaptado perfectamente a la vida en el frío extremo del Ártico. Conocidos por su espeso pelaje blanco, que les ayuda a camuflarse en el paisaje nevado, los osos polares son poderosos cazadores que dependen del hielo marino para cazar focas, su principal fuente de alimento.
Lo fascinante de los osos polares es su increíble capacidad de adaptación al entorno. Debajo de ese espeso pelaje hay una capa de grasa que puede alcanzar hasta 11 cm de grosor, lo que proporciona aislamiento y reservas de energía durante los duros meses de invierno. Sus grandes patas les ayudan a caminar tanto sobre el hielo como sobre el agua, lo que los convierte en excelentes nadadores, capaces de recorrer grandes distancias en busca de alimento o nuevos territorios.
Desafortunadamente, los osos polares se enfrentan a graves amenazas debido al cambio climático. A medida que el Ártico se calienta, el hielo marino se derrite antes en el año y se forma más tarde, lo que reduce el tiempo que tienen los osos polares para cazar focas. Sin suficiente comida, muchos osos luchan por sobrevivir y su población está disminuyendo en algunas zonas.
Los osos polares desempeñan un papel crucial en el mantenimiento de la salud del ecosistema ártico, y vuestra difícil situación sirve como un poderoso recordatorio de los amplios efectos del cambio climático en la fauna silvestre del mundo. Se están llevando a cabo iniciativas de conservación para proteger su hábitat y garantizar que estas majestuosas criaturas sigan prosperando en libertad».
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Aquí hay un archivo de texto sencillo cargado en el sistema, solo como ejemplo pedagógico, ¡pero puedes añadir cualquier tipo de documento que desees! Por ejemplo, puedes añadir documentación interna de tu organización. La variable documents ahora contiene el contenido del archivo, listo para ser procesado.
Los documentos grandes suelen dividirse en fragmentos más pequeños para facilitar su indexación y recuperación. Este proceso es muy importante porque los fragmentos más pequeños son más fáciles de manejar para el modelo lingüístico y permiten una recuperación más precisa. Puedes obtener más información en nuestra guía sobre estrategias de fragmentación para IA y RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Aquí, el texto se divide en fragmentos de 500 caracteres con un solapamiento de 50 caracteres entre fragmentos. Esta superposición ayuda a mantener el contexto entre los fragmentos durante la recuperación.
Una vez preparados los datos, el siguiente paso es indexarlos para poder recuperarlos de forma eficiente. La indexación consiste en convertir los fragmentos de texto en incrustaciones vectoriales y almacenarlos en un almacén vectorial.
LangChain admite la creación de incrustaciones vectoriales utilizando varios modelos, como los modelos OpenAI o HuggingFace. Estas incrustaciones representan el significado semántico de los fragmentos de texto, lo que las hace adecuadas para búsquedas por similitud.
En términos sencillos, las incrustaciones son básicamente una forma de tomar texto, como un párrafo de un documento, y convertirlo en números que un modelo de IA pueda entender. Estos números, o vectores, representan el significado del texto de una manera que facilita su procesamiento por parte de los sistemas de IA.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Estamos utilizando las incrustaciones de OpenAI para gestionar esa transformación. Primero, incorporamos la herramienta de incrustación de OpenAI y, a continuación, la inicializamos para que esté lista para su uso.
Después de generar las incrustaciones, el siguiente paso es almacenarlas en un almacén de vectores como PGVector, FAISS o cualquier otro compatible con LangChain. Esto permite recuperar de forma rápida y precisa los documentos relevantes cuando se realiza una consulta.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)En este caso, estamos utilizando FAISS, una excelente herramienta diseñada para realizar búsquedas en grandes conjuntos de vectores. FAISS nos ayuda a encontrar los vectores más similares muy rápidamente.
Entonces, esto es lo que está pasando: Incorporamos FAISS de LangChain y lo utilizamos para crear lo que se denomina un almacén vectorial. Es como una base de datos especial diseñada para almacenar y buscar vectores de manera eficiente.
Lo bueno de esta configuración es que, cuando realicemos búsquedas más adelante, FAISS podrá examinar todos esos vectores, encontrar los que sean más similares a una consulta determinada y devolver los fragmentos de documento correspondientes.
Una vez indexados los datos, ya puedes implementar el componente de recuperación, que se encarga de obtener la información relevante en función de las consultas de los usuarios.
Ahora estamos configurando un recuperador. Es el componente que revisa los documentos indexados y encuentra los más relevantes para la consulta de un usuario.
Ahora bien, lo interesante es que no estás buscando al azar, sino que estás buscando de forma inteligente gracias al poder de las incrustaciones, por lo que los resultados que obtienes son semánticamente similares a lo que el usuario está buscando. Analicemos la línea de código:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Primero, convertimos el almacén de vectores en un recuperador. ¿Sabes que ya tienes esta tienda vectorial FAISS repleta de incrustaciones de documentos? Bueno, ahora les estamos diciendo: «Oye, adelante, úsalo para buscar cosas cuando un usuario me haga una pregunta».
Ahora, search_type es donde ocurre la magia. El recuperador puede realizar búsquedas de diferentes maneras, y aquí tienes varias opciones. La búsqueda por similitud es el pan de cada día de la recuperación de información. Comprueba qué documentos son los más cercanos en significado a la consulta.
Por lo tanto, cuando dices «search_type='similarity'», le estás indicando al recuperador: «Busca los documentos más similares a la consulta basándote en las incrustaciones que hemos generado».
Con search_kwargs={«k»: 5} ajustas los detalles. El valor k indica al recuperador cuántos documentos debe extraer del almacén de vectores. En este caso, k=5 significa «Dame los 5 documentos más relevantes».
Esto es muy eficaz porque ayuda a reducir el ruido. En lugar de obtener un montón de resultados que tal vez sean más o menos relevantes, solo obtienes la información más importante.
En esta parte del código, estamos configurando el motor central de tu sistema RAG utilizando LangChain. Ya tienes tu recuperador, que puede extraer los documentos relevantes basándose en una consulta.
Ahora, estamos añadiendo el LLM y utilizándolo para generar la respuesta basándonos en los documentos recuperados.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQAAquí estamos importando dos elementos clave:
llm = OpenAI(openai_api_key=openai_api_key)Esta línea inicializa el LLM utilizando tu clave API de OpenAI. Piensa en ello como en cargar el cerebro de tu sistema: es el modelo que tomará el texto, lo comprenderá y generará respuestas.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Aquí es donde las cosas empiezan a ponerse realmente emocionantes. Estamos creando la cadena de control de calidad, que lo une todo. El método RetrievalQA.from_chain_type() crea una cadena de preguntas y respuestas, lo que equivale a decir: «Combina el recuperador y el LLM para crear un sistema que responda a preguntas basándose en los documentos recuperados».
A continuación, indicamos a la cadena que utilice el LLM de OpenAI que acabamos de inicializar para generar respuestas. Después conectaremos el recuperador que construiste anteriormente. El recuperador es responsable de encontrar los documentos relevantes basándose en la consulta del usuario.
A continuación, establecemos chain_type="stuff": Vale, ¿qué es «cosas» aquí? En realidad, es un tipo de cadena en LangChain. «Cosas» significa que estamos cargando todos los documentos relevantes recuperados en el LLM y haciendo que genere una respuesta basada en todo ello.
Es como dejar un montón de notas sobre el escritorio del LLM y decir: «Toma, usa toda esta información para responder a la pregunta».
Hay otros tipos de cadenas (como «map_reduce» o «refine»), pero «stuff» es la más sencilla y directa.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Aquí es donde realmente hacemos una pregunta al sistema y obtenemos una respuesta. El método invoke() activa todo el proceso.
Toma tu consulta, la envía al recuperador para que busque los documentos relevantes y, a continuación, pasa esos documentos al LLM, que genera la respuesta final.
print(response)Esto último imprime la respuesta generada por el LLM. A partir de los documentos recuperados, el sistema genera una respuesta completa y bien documentada a la consulta, que se imprime.
El guion final queda así:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Ahora es el momento de crear una API para interactuar con tu sistema RAG. Pero, ¿por qué es necesario este paso en la implementación?
Imagina que has seguido este tutorial y has configurado este increíble sistema RAG personalizado para tus documentos y necesidades: recopila información relevante, procesa consultas y genera respuestas inteligentes. Pero, ¿cómo se permite que los usuarios u otros sistemas interactúen con él?
FastAPI es tu intermediario. Crea una forma sencilla y estructurada para que los usuarios o las aplicaciones hagan preguntas a tu sistema RAG y obtengan respuestas.
FastAPI es asíncrono y de alto rendimiento. Esto significa que puede gestionar muchas solicitudes a la vez sin ralentizarse, lo cual es muy importante cuando se trata de sistemas de IA que pueden necesitar recuperar grandes cantidades de datos o ejecutar consultas complejas.
En esta sección, modificaremos el script anterior y crearemos otros adicionales para garantizar que tu sistema RAG sea accesible, escalable y esté listo para gestionar el tráfico real.Comencemos por crear las rutas que gestionarán las solicitudes entrantes al sistema RAG.
En tu directorio de trabajo, crea un archivo main.py. Este es tu punto de entrada a la aplicación FastAPI. Este será tu cerebro FastAPI: este archivo reunirá todas las rutas API, las dependencias y el sistema RAG.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)Es una configuración bastante sencilla, pero limpia. Lo que estamos haciendo aquí es configurar una instancia de FastAPI y, a continuación, extraer todas las rutas (o rutas API) de otro archivo, que crearemos a continuación.
Aquí es donde todo cobra sentido. Vamos a escribir una función que ejecute tu sistema RAG cuando un usuario envíe una consulta.
async def get_rag_response(query: str):Esta función está marcada como « async », lo que significa que es asíncrona. Esto significa que puede ocuparse de otras cosas mientras espera una respuesta.
Esta función resulta especialmente útil cuando se trabaja con sistemas basados en la recuperación, en los que la obtención de documentos o la consulta de un LLM puede llevar bastante tiempo. De esta manera, FastAPI puede procesar otras solicitudes mientras esta se ejecuta en segundo plano.
retriever = setup_rag_system()Aquí estamos llamando a la función ` setup_rag_system() `, que, como hemos comentado anteriormente, inicializa todo el proceso de recuperación. Esto significa:
Este recuperador se encargará de buscar los fragmentos de texto relevantes en función de la consulta del usuario.
Ahora, cuando un usuario formula una pregunta, el recuperador revisa todos los documentos del almacén vectorial y obtiene los más relevantes en función de la consulta.
retrieved_docs = retriever.get_relevant_documents(query)Este método invoke(query) recupera los documentos relevantes. Entre bastidores, se compara la consulta con los vectores de incrustación y se extraen las coincidencias más relevantes en función de su similitud.
Ahora que tenemos los documentos pertinentes, tenemos que darles formato para el LLM.
context = "\n".join([doc.page_content for doc in retrieved_docs])Aquí, tomamos todos los documentos recuperados y combinamos su contenido en una sola cadena. Esto es importante porque el LLM espera trabajar con un fragmento de texto limpio, no con un montón de fragmentos separados.
Estamos utilizando la función « join() » de Python para unir estos fragmentos de documentos en un bloque de información coherente. El contenido de cada documento se almacena en el campo « doc.page_content » (\n).
Ahora estamos creando el mensaje para el LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]La indicación está estructurada de tal manera que le indica al LLM que utilice la información recuperada para responder a la consulta del usuario.
Ahora es el momento de generar una respuesta.
generated_response = llm.generate(prompt) # Pass as a list of stringsAquí, el modelo OpenAI tiene ahora la tarea de tomar la indicación y generar una respuesta contextualizada basada tanto en la pregunta como en los documentos relevantes.
Por último, devolvemos la respuesta generada a quien haya llamado a la función (ya sea un usuario, una aplicación frontend u otro sistema).
return generated_responseEsta respuesta está completamente formada, contextualizada y lista para ser utilizada en aplicaciones del mundo real.
En resumen, esta función realiza el ciclo completo de recuperación y generación. Aquí tienes un breve resumen del proceso:
1. Configura el recuperador para que encuentre documentos relevantes.
2. Esos documentos se extraen en función de la consulta.
3. El contexto de esos documentos está preparado para el LLM.
4. El LLM genera una respuesta final utilizando ese contexto.
5. La respuesta se devuelve al usuario.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyA continuación, creemos el archivo endpoints.py. Aquí es donde definiremos las rutas reales que los usuarios llamarán para interactuar con tu sistema RAG.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Creamos un objeto ` APIRouter ` para gestionar nuestras rutas API. El punto final /query/ está definido para aceptar una solicitud **GET** con una cadena de consulta. Llama a la función get_rag_response desde tu archivo rag.py, que gestiona todo el proceso RAG (recuperación de documentos + generación de lenguaje). Si algo sale mal, generamos un error HTTP 500 con un mensaje detallado.
Una vez configurado todo esto, ya puedes ejecutar tu aplicación FastAPI utilizando Uvicorn. Este es el servidor web que permitirá a los usuarios acceder a tu API.
Ve al terminal y ejecuta:
uvicorn app.main:app --reloadapp.main:app indica a Uvicorn que busque la instancia app en el archivo main.py y --reload habilita la recarga automática si realizas algún cambio en tu código.
Una vez que el servidor esté en funcionamiento, abre tu navegador y ve a http://127.0.0.1:8000/docs. FastAPI genera automáticamente la documentación Swagger UI para tu API, ¡para que puedas probarla directamente desde tu navegador!
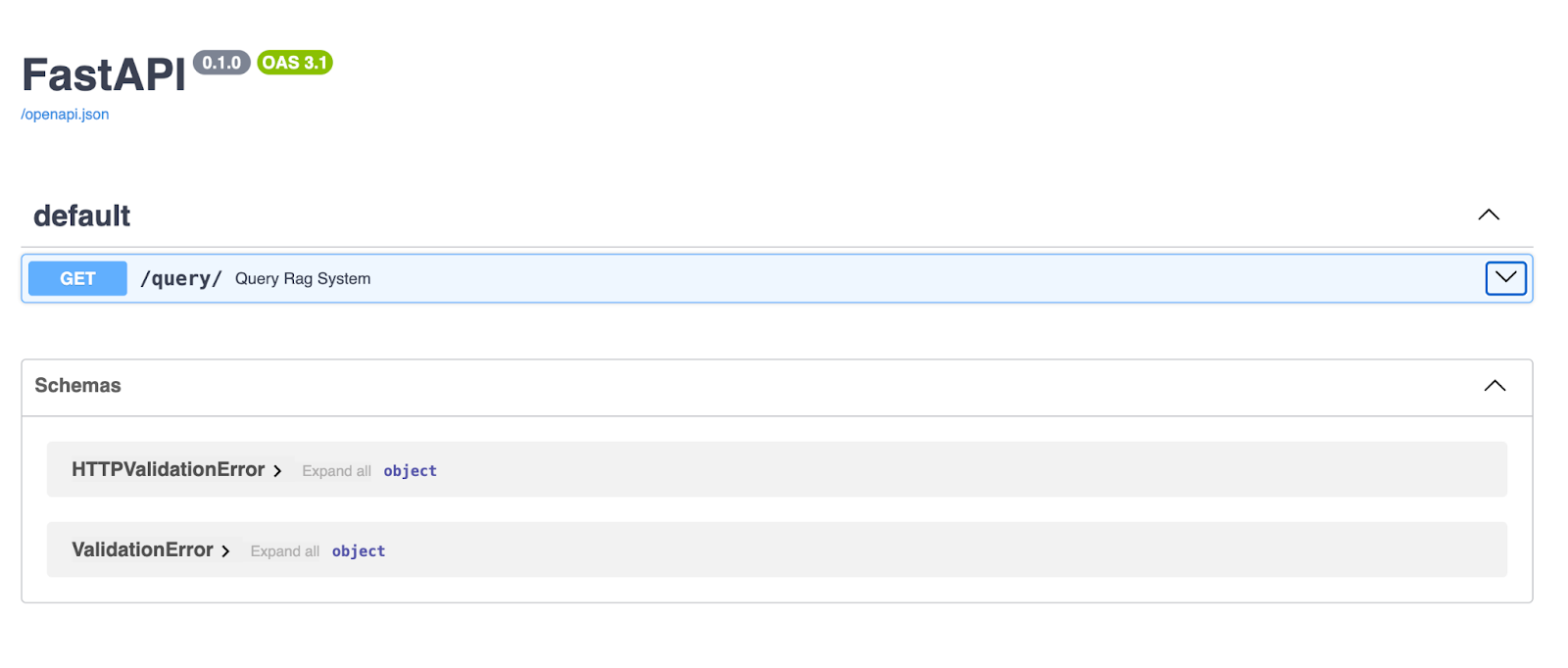
La interfaz de usuario Swagger de FastAPI proporciona una interfaz limpia e interactiva para explorar y probar los puntos finales de tu API. Aquí, el punto final /query/ permite a los usuarios introducir una cadena de consulta y recibir una respuesta generada por el canal RAG.
Con tu servidor FastAPI en funcionamiento, dirígete a tu navegador o utiliza Postman o Curl para realizar una solicitud GET a tu punto final /query/.
En tu navegador, a través de Swagger:
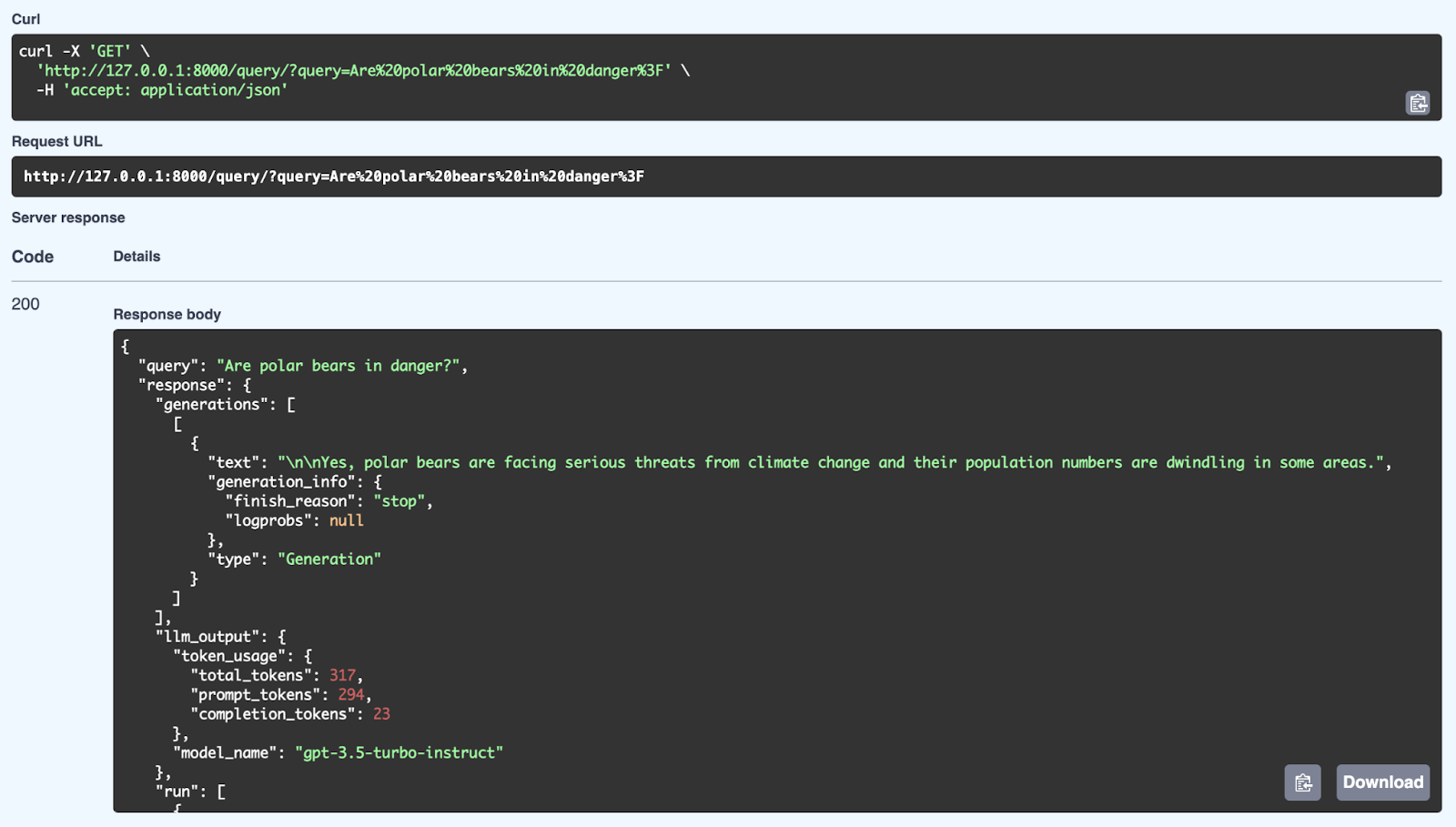
Aquí podemos ver una respuesta satisfactoria del sistema RAG utilizando una consulta: «¿Están en peligro los osos polares?». El sistema recupera información relevante de su base de conocimientos y genera una respuesta coherente utilizando el modelo GPT-3.5 Turbo-Instruct. La respuesta detallada incluye no solo la respuesta (Sí, los osos polares se enfrentan a graves amenazas debido al cambio climático y su población está disminuyendo), sino también metadatos como el uso de tokens (número de tokens procesados) y el modelo utilizado para la generación. La API es capaz de proporcionar respuestas bien estructuradas y sensibles al contexto mediante el uso de mecanismos de recuperación y generación a través de FastAPI.
Hablemos ahora de las ventajas del procesamiento asíncrono en FastAPI y por qué marca tanta diferencia a la hora de gestionar las solicitudes de API del mundo real.
Ya tienes tu sistema RAG en funcionamiento. La API recibe preguntas, recupera información relevante de tu base de conocimientos y, a continuación, genera respuestas con un modelo de lenguaje.
Ahora bien, si todo ese proceso fuera sincrónico, el sistema se quedaría ahí, esperando a que cada tarea se completara antes de pasar a la siguiente. Por ejemplo, mientras recupera documentos, no podrá procesar ninguna solicitud nueva.
|
E/S sin bloqueo |
Rendimiento mejorado |
Mejor experiencia de usuario |
|
Las funciones asíncronas permiten al servidor gestionar varias solicitudes a la vez, en lugar de esperar a que una termine antes de iniciar otra. |
Para tareas como recuperar documentos de un almacén vectorial o generar texto, el procesamiento asíncrono garantiza que la API pueda gestionar cargas elevadas de forma eficiente. |
Los clientes obtienen respuestas más rápidas y tu API sigue respondiendo incluso en condiciones de uso intensivo. |
Hablemos de las estrategias de implementación, un paso muy importante para convertir tu sistema RAG de un prototipo a un producto totalmente operativo. El objetivo es asegurarse de que tu sistema esté empaquetado, implementado y listo para escalar, de modo que pueda gestionar usuarios reales.
En primer lugar, hablemos de Docker. Docker es como una caja mágica que empaqueta todo lo que necesita tu sistema RAG (su código, dependencias, configuraciones) y lo envuelve todo en un pequeño y ordenado contenedor.
Esto garantiza que, independientemente de dónde implementes tu aplicación, esta se comporte exactamente igual. Puedes ejecutar tu aplicación en diferentes entornos, pero como está en un contenedor, no tienes que preocuparte por el problema de «funciona en mi máquina».

Creas un archivo Dockerfile, que es un conjunto de instrucciones que le indican a Docker cómo configurar el entorno de tu aplicación, instalar los paquetes necesarios y comenzar a ejecutarla. Una vez que esté listo, puedes crear una imagen de Docker a partir de él y ejecutar tu aplicación dentro de un contenedor. Es eficiente, repetible y muy fácil de transportar.
Ahora, una vez que tu sistema esté empaquetado y listo para funcionar, es probable que quieras implementarlo en la nube. Aquí es donde la cosa se pone interesante, porque implementar tu sistema RAG en la nube significa que se puede acceder a él desde cualquier parte del mundo. Además, te ofrece escalabilidad, fiabilidad y acceso a otros servicios de nube que pueden mejorar tu sistema.
Veamos otras dos plataformas en la nube muy populares, Azure y Google Cloud:
AWS ofrece herramientas como Elastic Beanstalk, que facilitan mucho la implementación. Básicamente, tú entregas tu contenedor Docker y AWS se encarga del escalado, el equilibrio de carga y la supervisión. Si necesitas más control, puedes utilizar Amazon ECS, que te permite ejecutar tus contenedores Docker en un clúster de servidores y ampliarlos o reducirlos según tus necesidades.
Heroku es otra opción que simplifica la implementación. Solo tienes que enviar tu código y Heroku se encarga de la infraestructura por ti. Es una excelente opción si no deseas profundizar demasiado en los detalles técnicos de la gestión de recursos en la nube.
Azure ofrece Azure App Service, que te permite implementar y gestionar tu sistema RAG con facilidad, proporcionando soporte integrado para el autoescalado, el equilibrio de carga y la implementación continua.
Para obtener más flexibilidad, puedes usar Azure Kubernetes Service (AKS) para administrar tus contenedores Docker a escala, lo que garantiza que tu sistema pueda manejar un tráfico elevado con la capacidad de ajustar dinámicamente los recursos según sea necesario.
GCP cuenta con Google Cloud Run, una plataforma totalmente gestionada que te permite implementar tus contenedores y escalarlos automáticamente en función del tráfico.
Si deseas tener un mayor control sobre tu infraestructura, puedes optar por Google Kubernetes Engine (GKE), que te permite gestionar y escalar tus contenedores Docker en varios nodos, con la ventaja añadida de una profunda integración con la nube de Google, como las API de inteligencia artificial y machine learning.
Cada plataforma tiene sus puntos fuertes, tanto si buscas simplicidad y automatización como un control más detallado sobre tu implementación.
En este artículo hemos tratado muchos temas y hemos explicado el proceso de creación de un sistema RAG utilizando LangChain y FastAPI. Los sistemas RAG suponen un gran avance en el procesamiento del lenguaje natural, ya que incorporan información externa, lo que permite a la IA generar respuestas más precisas, relevantes y contextualmente adecuadas.
Con LangChain, contamos con un marco sólido que se encarga de todo, desde cargar documentos, dividir texto y crear incrustaciones, hasta recuperar información basada en las consultas de los usuarios.
A continuación, FastAPI entra en escena para ofreceros un marco web rápido y preparado para la asincronía, lo que os ayuda a implementar el sistema RAG como una API escalable.
En conjunto, estas herramientas facilitan la creación de aplicaciones de IA capaces de gestionar consultas complejas, ofrecer respuestas precisas y, en última instancia, proporcionar una mejor experiencia de usuario.
Ahora es el momento de que apliques lo que has aprendido aplicarlo a tus propios proyectos.
Piensa en las posibilidades: consultar la base de conocimientos interna de tu propia empresa, automatizar los procesos de revisión de documentos o crear chatbots inteligentes para la atención al cliente.
No lo olvides: ¡hay muchas formas de ampliar esta configuración! Podrías experimentar con solicitudes POST para enviar estructuras de datos más complejas, o incluso explorar conexiones WebSocket para interacciones en tiempo real.
Te animo a que profundices, experimentes y veas adónde te puede llevar esto. ¡Esto es solo el comienzo de lo que puedes lograr con LangChain, FastAPI y las modernas herramientas de IA! Aquí tienes algunos recursos que te recomiendo:
Los mejores cursos de DataCamp
Curso
Curso
Curso