
Cours
Entraîner efficacement des modèles d’IA avec PyTorch
4 h
1.2K
L'utilisation de modèles linguistiques de grande envergure implique des coûts réels. Vous payez pour chaque jeton traité, chaque cycle GPU utilisé et chaque couche de complexité ajoutée à un modèle. Même si les prix ont baissé, la facture reste élevée lorsque vous travaillez avec des applications volumineuses, des invites longues ou des mises à jour fréquentes.
J'ai constaté à quel point cela peut rapidement devenir problématique. Les équipes supposent que les coûts resteront gérables, mais se rendent compte par la suite qu'elles dépensent leur budget dans des modèles surdimensionnés, des invites inefficaces ou du matériel inutilisé.
C'est pourquoi j'ai rassemblé 10 méthodes pratiques pour réduire les coûts liés aux déductions. De la quantification et l'élagage au traitement par lots, en passant par la mise en cache et l'ingénierie rapide, ce sont des approches que j'utilise pour maintenir les LLM à un coût raisonnable sans trop compromettre les performances.
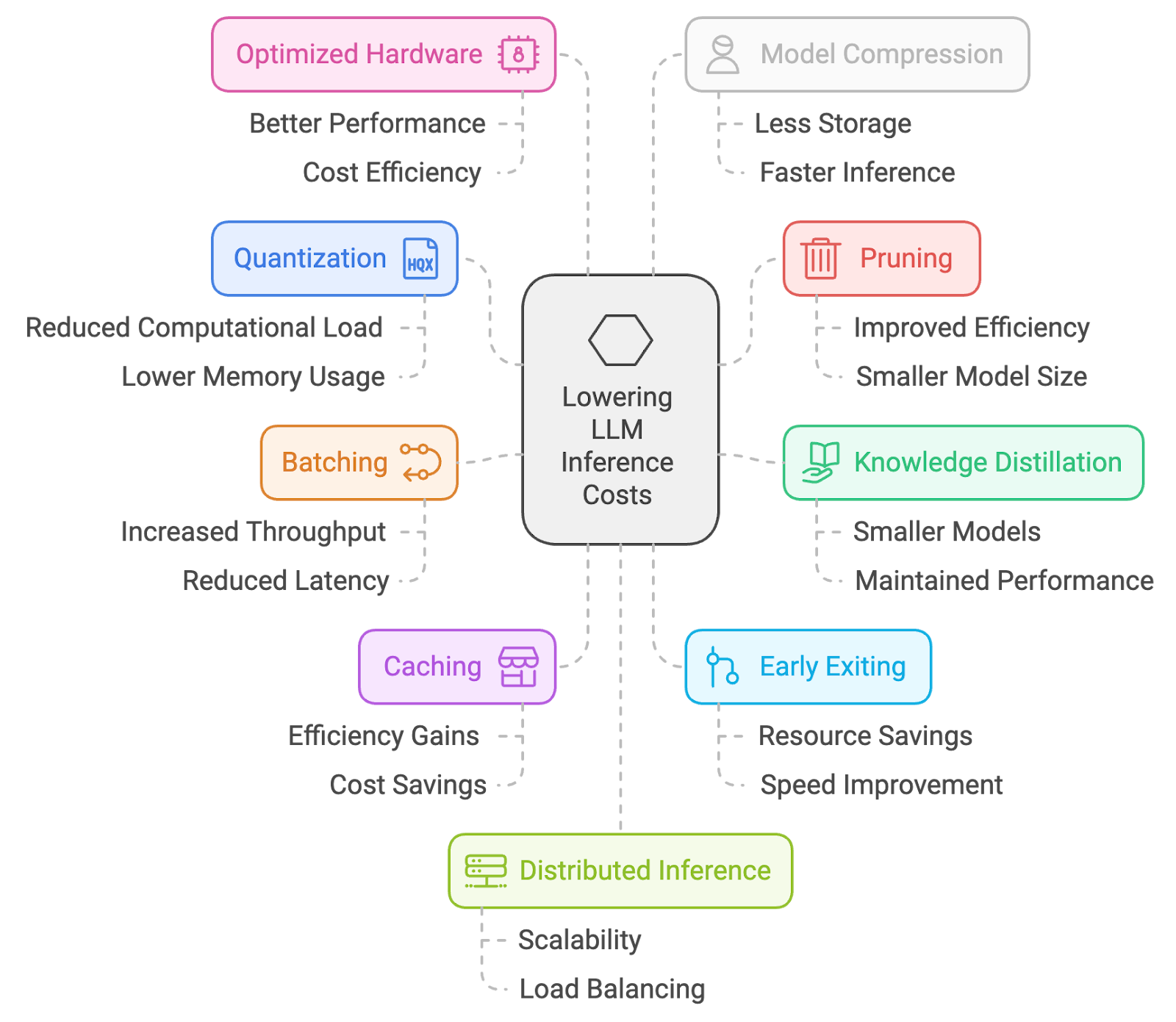
La quantification est un processus qui consiste à réduire la précision des poids et des activations du modèle, généralement en passant de nombres à virgule flottante 32 bits à des représentations à plus faible nombre de bits (par exemple, 16 bits ou même 8 bits). Cela réduit l'empreinte mémoire et les besoins en calcul, ce qui permet une inférence plus rapide sur les appareils aux ressources limitées.
Voici comment procéder :
Comment cela peut vous aider :
Le principal compromis est une perte potentielle de précision. Bien que les techniques de quantification modernes soient très performantes, il existe toujours un risque de légère baisse de la précision du modèle.
La taille est une technique qui consiste à supprimer les poids moins importants ou redondants d'un réseau neuronal. En supprimant les connexions qui ont un impact minimal sur les performances du modèle, l'élagage réduit la taille et la complexité computationnelle du modèle, ce qui accélère l'inférence.
Voici comment procéder :
Comment cela peut vous aider :
Tout comme pour la quantification, le principal compromis réside dans une perte potentielle de précision. Une taille trop sévère peut entraîner une baisse notable des performances. Il est essentiel de trouver le juste équilibre.
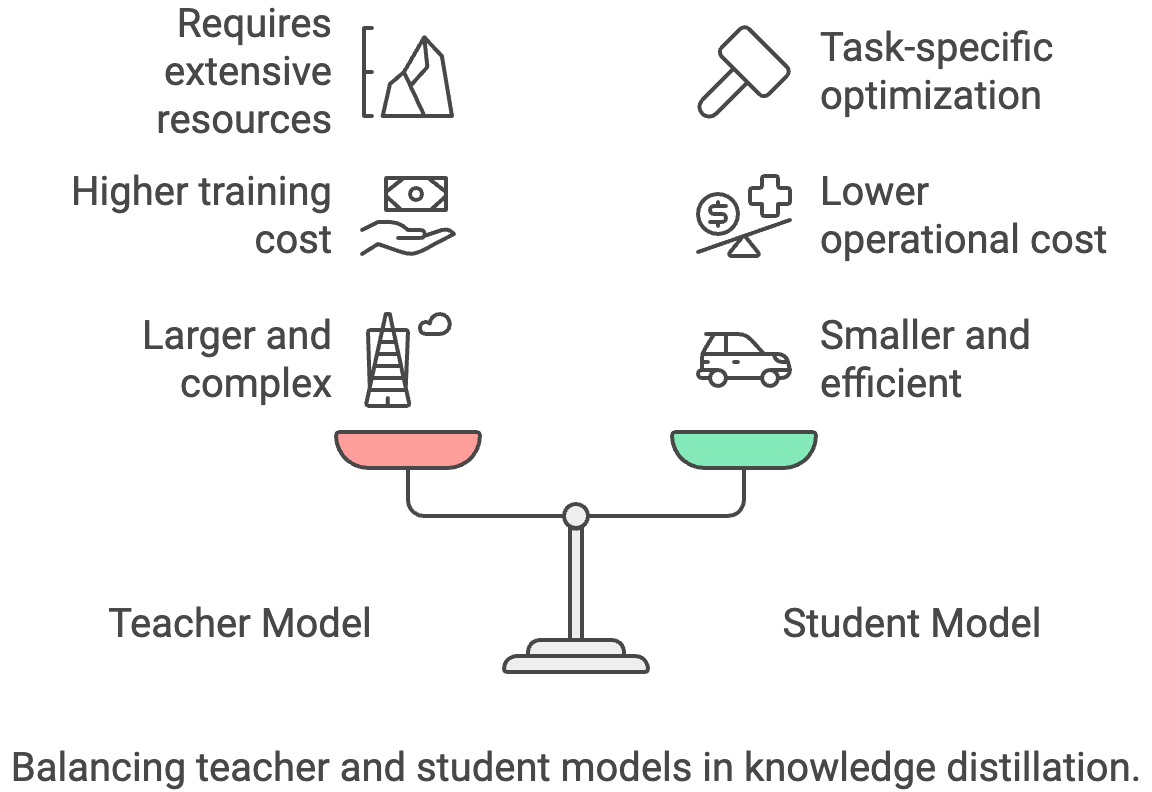
La distillation des connaissances est un processus qui consiste à transférer des connaissances d'un modèle « enseignant » vaste et complexe vers un modèle « élève » plus petit et plus efficace. Le modèle étudiant apprend à imiter le comportement de l'enseignant, ce qui lui permet d'atteindre des performances comparables avec une taille plus petite et une inférence plus rapide.
Voici comment procéder :
Comment cela peut vous aider :
Le principal compromis réside dans le fait que vous devez avoir accès à un modèle d'enseignant performant, dont la formation ou l'utilisation peut s'avérer coûteuse.
Le traitement par lots consiste à traiter simultanément plusieurs échantillons d'entrée dans un lot pendant l'inférence. Cela améliore l'efficacité en utilisant les capacités de traitement parallèle du matériel, ce qui accélère l'inférence globale.
Voici comment procéder :
Comment cela peut vous aider :
Cependant, le traitement par lots peut entraîner une latence supplémentaire pour les requêtes individuelles, car le système peut attendre d'avoir accumulé suffisamment d'entrées avant de les traiter. Pour les applications en temps réel ou à faible latence, ce délai supplémentaire peut nuire à l'expérience utilisateur s'il n'est pas soigneusement réglé. Le traitement dynamique par lots contribue à atténuer le problème, mais ajoute à la complexité du système. Il existe également un risque d'inefficacité du traitement par lots lorsque le trafic est irrégulier, ce qui peut réduire les économies attendues.
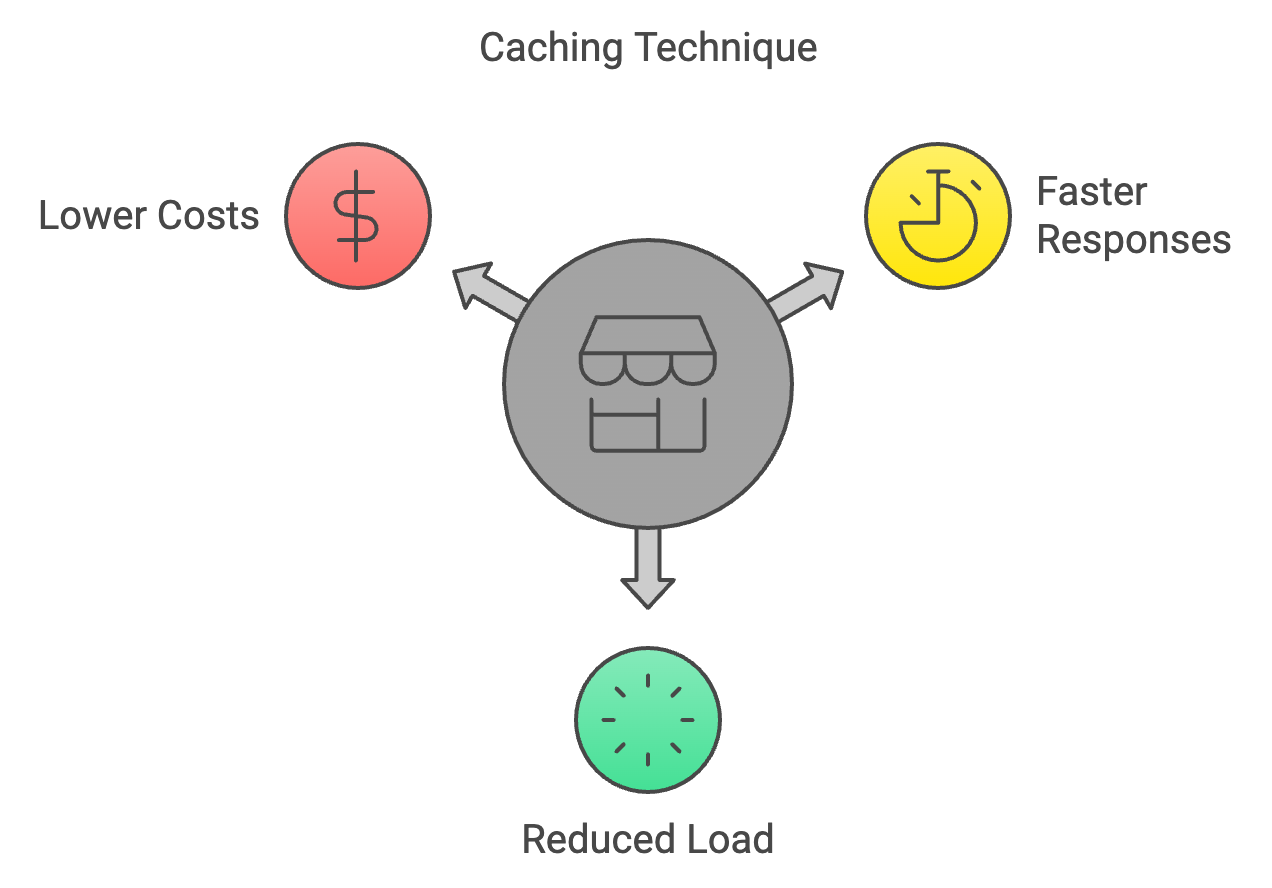
La mise en cache est une technique qui consiste à stocker les résultats de calculs précédents et à les réutiliser lorsque les mêmes entrées apparaissent à nouveau lors de l'inférence. Cela permet d'éviter les calculs redondants et d'accélérer le processus d'inférence.
Voici comment procéder :
Comment cela peut vous aider :
Cependant, la mise en cache n'est utile que lorsque les entrées se répètent ou se chevauchent. Dans le cas de charges de travail très variables, les taux de réussite peuvent être faibles et les coûts liés à la maintenance d'un cache peuvent dépasser les avantages. Des résultats obsolètes ou périmés peuvent également entraîner des problèmes de cohérence si les résultats mis en cache ne reflètent plus les données les plus pertinentes. De plus, la mise en œuvre et l'ajustement des stratégies d'éviction du cache ajoutent à la complexité technique, en particulier dans les systèmes distribués où la synchronisation du cache devient un défi.
La sortie anticipée consiste à interrompre le calcul prématurément pendant l'inférence si le modèle est suffisamment sûr de sa prédiction. Cela permet d'économiser des ressources informatiques et d'accélérer l'inférence pour les cas plus simples où un passage complet vers l'avant n'est pas nécessaire.
Voici comment procéder :
Comment cela peut vous aider :
Le compromis est que la sortie précoce peut entraîner une légère baisse de la précision dans certains cas, en particulier pour les entrées complexes.
Cette technique implique l'utilisation d'architectures matérielles spécialisées et d'accélérateurs conçus pour des calculs d'IA efficaces. Il s'agit notamment des GPU, des TPU et d'autres puces IA dédiées qui offrent des améliorations significatives en termes de performances par rapport aux CPU à usage général pour les tâches d'inférence.
Voici comment procéder :
Comment cela peut vous aider :
Cependant, le matériel spécialisé nécessite souvent un investissement initial important et peut vous contraindre à utiliser l'écosystème d'un fournisseur particulier. Les GPU, TPU ou accélérateurs personnalisés peuvent également être plus difficiles à provisionner de manière cohérente dans le cloud, en particulier pendant les pics de demande. Les déploiements sur site présentent des défis en matière de maintenance et d'évolutivité, tandis que les options cloud peuvent entraîner des coûts de location récurrents plus élevés. Enfin, l'adaptation des logiciels afin d'exploiter pleinement le matériel spécialisé peut accroître la complexité technique et nécessiter une optimisation continue.
La compression de modèle désigne l'utilisation de plusieurs techniques pour réduire la taille et la complexité d'un modèle sans compromettre de manière significative ses performances. Cela peut impliquer l'élagage, la quantification, la distillation des connaissances ou d'autres méthodes visant à créer un modèle plus compact et plus efficace pour une inférence plus rapide.
Voici comment procéder :
Comment cela peut vous aider :
La compression des modèles peut entraîner une perte de précision si les techniques sont appliquées de manière trop agressive ou sans réglage minutieux. La combinaison de méthodes telles que l'élagage, la quantification et la distillation augmente la complexité du système et peut nécessiter des cycles supplémentaires de réentraînement ou de réglage fin. Les modèles compressés peuvent également être moins flexibles pour le transfert vers de nouvelles tâches, car les optimisations réduisent souvent l'éventail des scénarios dans lesquels le modèle fonctionne bien. Dans certains cas, le temps d'ingénierie et la charge de calcul consacrés à la compression peuvent compenser les économies réalisées à court terme.
L'inférence distribuée est une approche qui consiste à répartir la charge de travail d'inférence entre plusieurs machines ou appareils. Cela permet le traitement parallèle de tâches d'inférence à grande échelle, réduisant ainsi la latence et améliorant le débit.
Voici comment procéder :
Comment cela peut vous aider :
L'inférence distribuée introduit une complexité significative dans le système, car la coordination des calculs entre plusieurs machines nécessite une orchestration, une synchronisation et une tolérance aux pannes robustes. Les contraintes liées à la latence du réseau et à la bande passante peuvent compromettre les gains de performance, en particulier lorsque de grandes quantités de données intermédiaires doivent être échangées. Cela augmente également les coûts d'infrastructure, car il est nécessaire de fournir et d'entretenir du matériel supplémentaire et des mécanismes d'équilibrage de charge. Le débogage et la surveillance des systèmes distribués peuvent s'avérer plus complexes, ce qui rend la fiabilité plus difficile à garantir par rapport aux configurations à nœud unique.
L'ingénierie des invites est un processus qui consiste à élaborer avec soin des invites d'entrée afin de guider les grands modèles linguistiques (LLM) vers la génération des résultats souhaités. En formulant des invites claires, concises et spécifiques, les utilisateurs peuvent améliorer la qualité et la contrôlabilité des réponses du LLM, les rendant ainsi plus pertinentes et utiles pour des tâches spécifiques.
Voici comment procéder :
Comment cela peut vous aider :
L'ingénierie rapide nécessite des expérimentations et des itérations continues, ce qui peut être chronophage et inégal selon les cas d'utilisation. Les invites bien conçues peuvent ne pas être généralisables, ce qui vous obligera à les repenser lorsque les tâches ou les modèles changeront. Les améliorations apportées à la conception des questions peuvent également être fragiles : de légères modifications dans la formulation ou des mises à jour du modèle peuvent modifier les résultats de manière imprévisible. Enfin, s'appuyer excessivement sur l'ingénierie rapide sans techniques complémentaires telles que la gestion du contexte ou le réglage fin peut limiter l'évolutivité et les économies à long terme.
L'ingénierie contextuelle consiste à concevoir des systèmes qui contrôlent les informations auxquelles un LLM a accès avant de générer une réponse. Au lieu de regrouper toutes les informations dans la fenêtre contextuelle, vous sélectionnez et organisez uniquement les détails les plus pertinents, tels que l'historique de l'utilisateur, les documents récupérés ou les résultats des outils, afin que le modèle puisse raisonner plus efficacement.
Comment cela fonctionne :
Comment cela peut vous aider :
Le compromis est que la mise en place de systèmes contextuels efficaces nécessite un effort d'ingénierie en amont. Il est nécessaire de mettre en place des pipelines de récupération, de synthèse et de validation. Une conception inadéquate peut entraîner des lacunes contextuelles qui nuisent aux performances. Cependant, lorsqu'elle est bien exécutée, l'ingénierie contextuelle rend les applications de grande envergure à la fois plus fiables et plus abordables.
Réduire les coûts d'inférence LLM ne se résume pas à une seule astuce. Il s'agit de combiner les approches qui conviennent à votre charge de travail. Des techniques telles que la quantification, l'élagage et la distillation des connaissances permettent de réduire la taille des modèles. Le traitement par lots, la mise en cache et l'inférence distribuée améliorent la manière dont les requêtes sont traitées. Le choix du matériel et la compression des modèles améliorent encore l'efficacité, tandis que l'ingénierie contextuelle et rapide réduit l'utilisation inutile de jetons à la source.
Les compromis sont réels : chaque méthode comporte une certaine complexité, une perte potentielle de précision ou des frais généraux liés à l'infrastructure. Cependant, les bénéfices s'accumulent. En appliquant ne serait-ce que quelques-unes de ces techniques, vous pouvez maintenir les modèles à un coût abordable, adapter leur utilisation sans coûts excessifs et créer des systèmes qui restent viables à mesure que les modèles et les applications se développent.
Apprenez l'IA grâce à ces cours.
Cours
Cours
Cours