
Kurs
Effizientes KI-Modelltraining mit PyTorch
4 Std.
1.2K
Große Sprachmodelle zu betreiben, kostet echt Geld. Du bezahlst für jeden verarbeiteten Token, jeden verwendeten GPU-Zyklus und jede zusätzliche Komplexitätsebene eines Modells. Auch wenn die Preise gesunken sind, wird die Rechnung schnell hoch, wenn du mit großen Anwendungen, langen Eingabeaufforderungen oder häufigen Updates arbeitest.
Ich hab schon gesehen, wie schnell das zum Problem wird. Die Teams denken, dass die Kosten im Griff bleiben, merken dann aber, dass sie ihr Budget für überdimensionierte Modelle, ineffiziente Eingabeaufforderungen oder ungenutzte Hardware verschwenden.
Deshalb hab ich 10 praktische Tipps, um die Kosten für Schlussfolgerungen zu senken. Von Quantisierung und Pruning bis hin zu Batching, Caching und Prompt Engineering – das sind die Methoden, die ich tatsächlich nutze, um LLMs bezahlbar zu halten, ohne dabei zu viele Leistungseinbußen hinnehmen zu müssen.
Quantisierung ist ein Prozess, bei dem die Genauigkeit von Modellgewichten und Aktivierungen reduziert wird, normalerweise von 32-Bit-Gleitkommazahlen auf Darstellungen mit weniger Bits (z. B. 16 Bit oder sogar 8 Bit). Das spart Speicherplatz und Rechenleistung, sodass man auf Geräten mit wenig Ressourcen schneller Ergebnisse kriegt.
So geht's:
Wie es hilft:
Der Hauptkompromiss ist, dass es vielleicht nicht mehr ganz so genau ist. Auch wenn moderne Quantisierungstechniken ziemlich gut sind, kann es immer zu einem leichten Rückgang der Modellgenauigkeit kommen.
Das Beschneiden ist eine Technik, um unwichtige oder überflüssige Gewichte aus einem neuronalen Netzwerk zu entfernen. Durch das Entfernen von Verbindungen, die kaum Einfluss auf die Leistung des Modells haben, wird die Größe und die Rechenkomplexität des Modells reduziert, was zu einer schnelleren Inferenz führt.
So geht's:
Wie es hilft:
Ähnlich wie bei der Quantisierung ist der Hauptkompromiss ein möglicher Genauigkeitsverlust. Ein zu starker Rückschnitt kann die Leistung echt beeinträchtigen. Es ist echt wichtig, die richtige Balance zu finden.
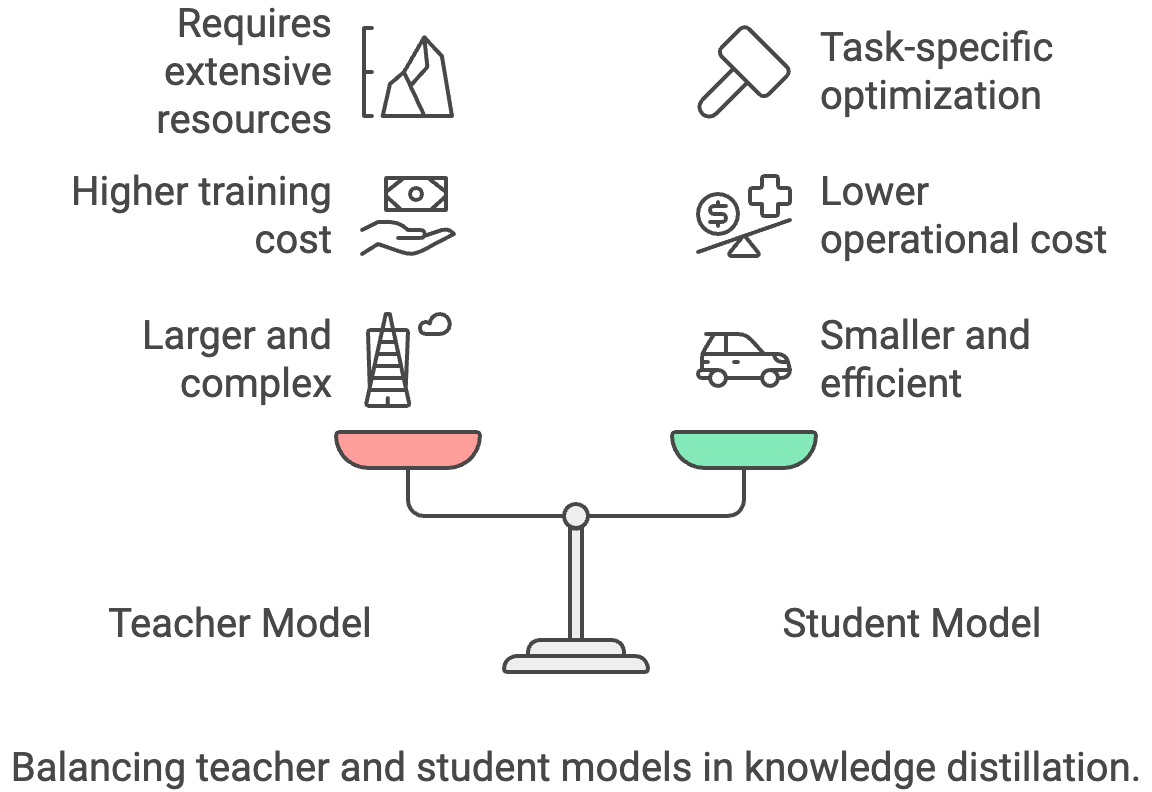
Wissensdestillation ist ein Prozess, bei dem Wissen von einem großen, komplexen „Lehrer”-Modell auf ein kleineres, effizienteres „Schüler”-Modell übertragen wird. Das Studentenmodell lernt, das Verhalten des Lehrers nachzumachen, sodass es mit einer kleineren Größe und schnellerer Schlussfolgerung eine vergleichbare Leistung bringen kann.
So geht's:
Wie es hilft:
Der Hauptkompromiss ist, dass du Zugang zu einem leistungsstarken Lehrer-Modell brauchst, dessen Training oder Nutzung teuer sein kann.
Beim Batching werden mehrere Eingabeproben während der Inferenz gleichzeitig in einem Stapel verarbeitet. Das macht die Sache effizienter, weil die Hardware parallel arbeiten kann, was die Inferenz insgesamt schneller macht.
So geht's:
Wie es hilft:
Allerdings kann das Batching zusätzliche Verzögerungen bei einzelnen Anfragen verursachen, weil das System vielleicht wartet, bis genug Eingaben gesammelt sind, bevor es sie verarbeitet. Bei Echtzeit- oder Anwendungen mit geringer Latenz kann diese zusätzliche Verzögerung die Benutzererfahrung beeinträchtigen, wenn sie nicht sorgfältig abgestimmt wird. Dynamisches Batching hilft, das Problem zu lösen, macht das System aber komplizierter. Es besteht auch das Risiko einer ineffizienten Stapelverarbeitung bei ungleichmäßiger Auslastung, was die erwarteten Kosteneinsparungen verringern kann.
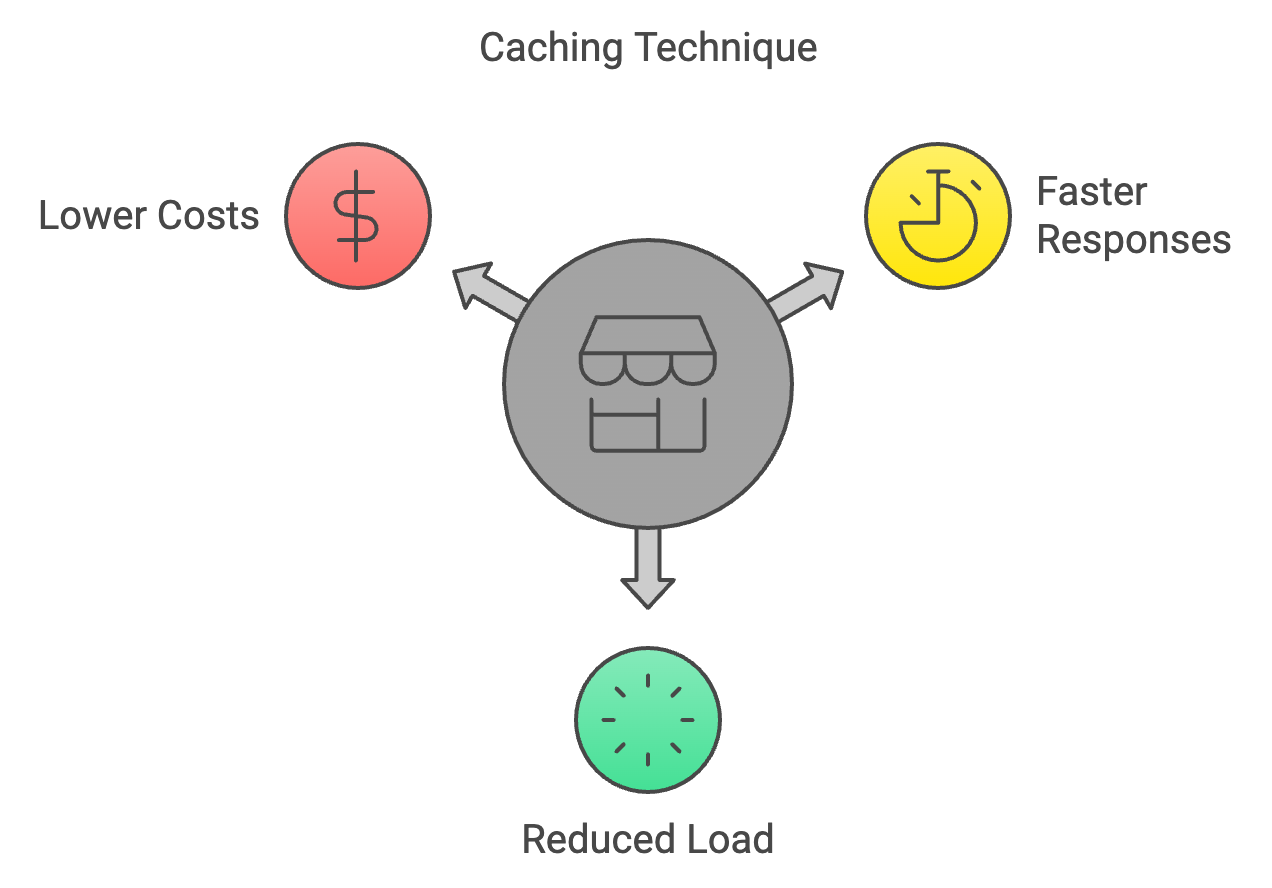
Caching ist eine Technik, bei der die Ergebnisse früherer Berechnungen gespeichert und wiederverwendet werden, wenn man bei der Inferenz wieder auf die gleichen Eingaben stößt. Dadurch werden unnötige Berechnungen vermieden und der Inferenzprozess beschleunigt.
So geht's:
Wie es hilft:
Caching ist aber nur dann sinnvoll, wenn sich Eingaben wiederholen oder überschneiden. Bei stark schwankenden Arbeitslasten können die Trefferquoten niedrig sein, und der Aufwand für die Pflege eines Caches kann die Vorteile überwiegen. Veraltete oder nicht mehr aktuelle Ergebnisse können auch zu Konsistenzproblemen führen, wenn die zwischengespeicherten Ausgaben nicht mehr die relevantesten Daten zeigen. Außerdem macht das Einrichten und Optimieren von Strategien zum Löschen von Cache-Daten die Technik komplizierter, vor allem in verteilten Systemen, wo die Synchronisierung des Caches echt schwierig ist.
Frühes Beenden heißt, dass die Berechnung während der Inferenz vorzeitig gestoppt wird, wenn das Modell von seiner Vorhersage ziemlich überzeugt ist. Das spart Rechenleistung und macht die Schlussfolgerung bei einfacheren Fällen schneller, wo man nicht den ganzen Vorwärtsdurchlauf braucht.
So geht's:
Wie es hilft:
Der Nachteil ist, dass ein frühes Beenden in manchen Fällen zu einer etwas geringeren Genauigkeit führen kann, vor allem bei komplizierten Eingaben.
Bei dieser Technik werden spezielle Hardware-Architekturen und Beschleuniger genutzt, die für effiziente KI-Berechnungen entwickelt wurden. Dazu gehören GPUs, TPUs und andere spezielle KI-Chips, die im Vergleich zu Allzweck-CPUs bei Inferenzaufgaben deutlich besser abschneiden.
So geht's:
Wie es hilft:
Spezialisierte Hardware braucht aber oft viel Geld im Voraus und kann dich an ein bestimmtes Anbieter-System binden. GPUs, TPUs oder benutzerdefinierte Beschleuniger können auch schwieriger konsistent in der Cloud bereitgestellt werden, vor allem bei Spitzenauslastung. Lokale Installationen bringen Probleme bei Wartung und Skalierung mit sich, während Cloud-Optionen höhere laufende Mietkosten verursachen können. Schließlich kann die Anpassung von Software zur vollständigen Nutzung spezieller Hardware die technische Komplexität erhöhen und eine kontinuierliche Optimierung erfordern.
Modellkomprimierung heißt, mehrere Techniken zu nutzen, um die Größe und Komplexität eines Modells zu reduzieren, ohne dass die Leistung stark darunter leidet. Das kann zum Beispiel das Beschneiden, Quantisieren, die Wissensdestillation oder andere Methoden sein, die ein kompakteres und effizienteres Modell für schnellere Schlussfolgerungen schaffen sollen.
So geht's:
Wie es hilft:
Modellkompression kann die Genauigkeit beeinträchtigen, wenn die Techniken zu aggressiv oder ohne sorgfältige Abstimmung angewendet werden. Wenn man Methoden wie Pruning, Quantisierung und Destillation kombiniert, wird das System komplizierter und man muss es vielleicht nochmal trainieren oder anpassen. Komprimierte Modelle können auch weniger flexibel für die Übertragung auf neue Aufgaben sein, weil Optimierungen oft den Bereich der Szenarien einschränken, in denen das Modell gut funktioniert. Manchmal kann die Zeit, die man für die Komprimierung braucht, und der Rechenaufwand die kurzfristigen Einsparungen wieder aufheben.
Verteilte Inferenz ist ein Ansatz, um die Inferenz-Arbeitslast auf mehrere Maschinen oder Geräte zu verteilen. Dadurch können große Inferenzaufgaben parallel bearbeitet werden, was die Latenzzeit verkürzt und den Durchsatz verbessert.
So geht's:
Wie es hilft:
Verteilte Inferenz macht das System ziemlich kompliziert, weil die Koordination der Berechnungen über mehrere Maschinen hinweg eine robuste Orchestrierung, Synchronisation und Fehlertoleranz braucht. Netzwerklatenz und Bandbreitenbeschränkungen können die Leistungssteigerungen zunichte machen, vor allem wenn viele Zwischendaten ausgetauscht werden müssen. Außerdem steigen die Infrastrukturkosten, weil man zusätzliche Hardware und Mechanismen für den Lastausgleich bereitstellen und warten muss. Das Debuggen und Überwachen von verteilten Systemen kann schwieriger sein, was die Zuverlässigkeit im Vergleich zu Einzelsystemen zu einer Herausforderung macht.
Prompt Engineering ist ein Prozess, bei dem Eingabeaufforderungen sorgfältig erstellt werden, um große Sprachmodelle (LLMs) dazu zu bringen, die gewünschten Ergebnisse zu generieren. Durch klare, prägnante und spezifische Eingabeaufforderungen können Nutzer die Qualität und Steuerbarkeit von LLM-Antworten verbessern, sodass diese für bestimmte Aufgaben relevanter und nützlicher werden.
So geht's:
Wie es hilft:
Prompt Engineering braucht ständige Experimente und Iterationen, was echt zeitaufwendig sein kann und je nach Anwendungsfall unterschiedlich ist. Gut gemachte Eingabeaufforderungen lassen sich vielleicht nicht verallgemeinern, sodass du sie neu gestalten musst, wenn sich Aufgaben oder Modelle ändern. Verbesserungen beim Prompt-Design können auch anfällig sein – kleine Änderungen im Wortlaut oder Modellaktualisierungen können die Ergebnisse auf unvorhersehbare Weise verändern. Zu viel auf Prompt Engineering zu setzen, ohne ergänzende Techniken wie Kontextmanagement oder Feinabstimmung, kann die Skalierbarkeit und langfristige Kosteneinsparungen einschränken.
Kontext-Engineering ist die Praxis, Systeme zu entwickeln, die steuern, welche Informationen ein LLM sieht, bevor es eine Antwort generiert. Anstatt alles in das Kontextfenster zu stopfen, wählst du nur die relevantesten Details aus und ordnest sie – wie zum Beispiel den Benutzerverlauf, abgerufene Dokumente oder Tool-Ausgaben –, damit das Modell effizienter arbeiten kann.
So geht's:
Wie es hilft:
Der Nachteil ist, dass man für den Aufbau guter Kontextsysteme erst mal viel Entwicklungsarbeit investieren muss. Du brauchst Pipelines für das Abrufen, Zusammenfassen und Validieren, und ein schlechtes Design kann zu Kontextlücken führen, die die Leistung beeinträchtigen. Aber wenn man es richtig macht, macht Context Engineering große Anwendungen zuverlässiger und günstiger.
Die Senkung der LLM-Inferenzkosten ist keine einfache Sache. Es geht darum, Ansätze zu kombinieren, die für deine Arbeitslast sinnvoll sind. Techniken wie Quantisierung, Pruning und Wissensdestillation machen Modelle kleiner. Batching, Caching und verteilte Inferenz machen die Bearbeitung von Anfragen besser. Die Wahl der Hardware und die Modellkomprimierung machen die Effizienz noch besser, während Prompt- und Context-Engineering unnötige Token-Nutzung an der Quelle reduzieren.
Die Kompromisse sind echt: Jede Methode bringt Komplexität, mögliche Genauigkeitsverluste oder Infrastruktur-Overhead mit sich. Aber die Gewinne summieren sich. Schon wenn du ein paar dieser Techniken anwendest, kannst du Modelle bezahlbar halten, die Nutzung ohne ausufernde Kosten skalieren und Systeme aufbauen, die auch bei wachsenden Modellen und Anwendungen nachhaltig bleiben.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Vinod Chugani
14 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Allan Ouko

