Kursus
Unsupervised Learning in Python
4 Hr
179.3K

Pembelajaran mesin adalah subbidang dari kecerdasan buatan yang berfokus untuk memahami dan membangun metode yang meniru cara manusia belajar. Metode-metode ini mencakup penggunaan algoritme dan data untuk meningkatkan kinerja pada sejumlah tugas dan biasanya termasuk dalam salah satu dari tiga jenis pembelajaran yang paling umum:
Scikit-learn, juga dikenal sebagai sklearn, adalah pustaka pembelajaran mesin Python yang tangguh dan bersifat open-source. Pustaka ini dibuat untuk membantu menyederhanakan proses penerapan model pembelajaran mesin dan statistik di Python.
Pustaka ini memungkinkan praktisi dengan cepat mengimplementasikan beragam algoritme pembelajaran mesin terawasi dan tanpa pengawasan melalui antarmuka yang konsisten. Sklearn dibangun di atas SciPy dan bekerja pada semua jenis data numerik yang disimpan sebagai array NumPy, matriks jarang SciPy, dan semua tipe data lain yang dapat dikonversi menjadi array numerik seperti Pandas DataFrame.
Dalam tutorial sklearn praktis ini, kita akan membahas berbagai aspek siklus hidup pembelajaran mesin, seperti pemrosesan data, pelatihan model, dan evaluasi model.
Lihat workspace DataCamp ini untuk mengikuti kodenya.
Aspek pertama dari sklearn yang akan kita jelajahi adalah data; Scikit-learn menyertakan beberapa dataset pembelajaran mesin standar, sehingga Anda tidak perlu mengunduhnya dari situs web atau basis data eksternal.
Contoh dataset mainan yang tersedia di sklearn termasuk dataset iris untuk klasifikasi dan dataset diabetes untuk regresi. Untuk contoh kita, kita akan menggunakan dataset wine.
Mari muat ke memori:
from sklearn.datasets import load_wine
wine_data = load_wine() Menjalankan kode di atas mengembalikan objek mirip kamus yang berisi data beserta metadata tentang data yang dikandungnya.
Data yang kita butuhkan ada di atribut .data yang dikembalikan oleh load_wine(). Kita dapat mengaksesnya sebagai atribut dari instance wine_data sebagai berikut:
wine_data.dataIni mengembalikan array N x M di mana N adalah jumlah sampel dan M adalah jumlah fitur.
Mari gunakan pengetahuan ini untuk memuat data kita ke intu sebuah pandas DataFrame, yang jauh lebih mudah untuk dimanipulasi dan dianalisis.
import pandas as pd
from sklearn.datasets import load_wine
wine_data = load_wine()
# Convert data to pandas dataframe
wine_df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
# Add the target label
wine_df["target"] = wine_data.target
# Take a preview
wine_df.head()
Sekarang Anda siap melakukan eksplorasi data.
Pandas DataFrame didefinisikan sebagai struktur data berlabel dua dimensi yang terdiri dari kolom, yang dapat berisi jenis data yang berbeda. Cara termudah untuk memvisualisasikan DataFrame adalah menganggapnya sebagai tiga komponen yang digabungkan; komponen tersebut adalah 1) data, 2) indeks, dan 3) kolom.
Eksplorasi data bukan fokus utama artikel ini, tetapi ini adalah langkah yang sangat penting dalam proyek data apa pun – Anda dapat mempelajarinya lebih lanjut di tutorial Exploratory Data Analysis Python kami. Kita akan melakukan eksplorasi singkat untuk mendapatkan gambaran yang lebih baik tentang isi dataset; ini akan memberi kita ide yang lebih baik tentang cara memproses data.
Hal pertama yang akan kita lakukan adalah memanggil metode info() pada pandas DataFrame kita; ini akan mencetak ringkasan singkat data wine yang terdapat dalam DataFrame.
wine_df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 178 non-null float64
1 malic_acid 178 non-null float64
2 ash 178 non-null float64
3 alcalinity_of_ash 178 non-null float64
4 magnesium 178 non-null float64
5 total_phenols 178 non-null float64
6 flavanoids 178 non-null float64
7 nonflavanoid_phenols 178 non-null float64
8 proanthocyanins 178 non-null float64
9 color_intensity 178 non-null float64
10 hue 178 non-null float64
11 od280/od315_of_diluted_wines 178 non-null float64
12 proline 178 non-null float64
13 target 178 non-null int64
dtypes: float64(13), int64(1)
memory usage: 19.6 KB
"""Setelah menjalankan sel ini, Anda akan mengetahui:
Kita juga dapat memanggil metode describe() pada DataFrame untuk mendapatkan statistik deskriptif tentang setiap fitur dalam dataset.
Sebagai contoh:
wine_df.describe() 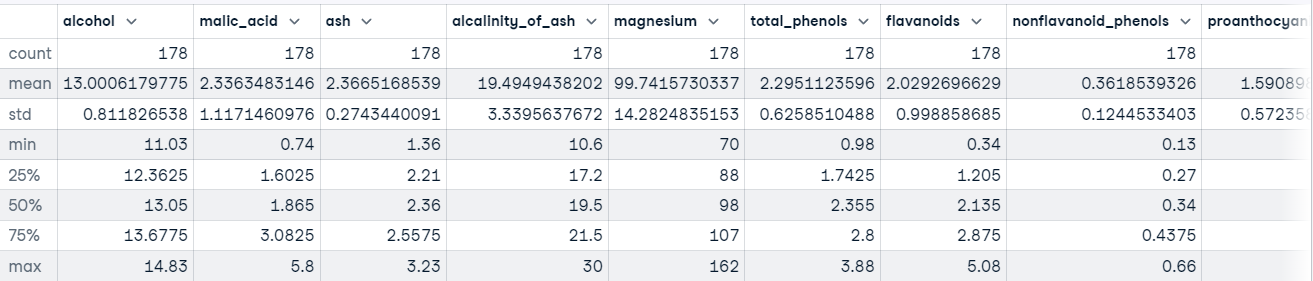
Anda juga perlu memahami jenis nilai yang terdapat pada setiap fitur. Cara tercepat untuk mengetahuinya adalah menggunakan metode head() untuk menampilkan lima baris pertama data atau metode tail() untuk melihat lima baris terakhir data.
wine_df.tail()
Menjalankan kode ini menunjukkan bahwa fitur kita berada pada skala yang berbeda-beda, yang dapat menimbulkan masalah saat menggunakan algoritme berbasis Gradient Descent seperti regresi logistik, dan saat menggunakan algoritme berbasis jarak seperti support vector machine. Ini karena algoritme tersebut sensitif terhadap rentang titik data.
Dalam alur kerja pembelajaran mesin yang normal, proses ini akan jauh lebih panjang, tetapi kita akan langsung ke pemrosesan data agar kembali ke fokus utama tutorial ini, yaitu Scikit-learn.
Anda dapat mempelajari lebih lanjut tentang Pandas di Python Pandas Tutorial: The Ultimate Guide for Beginners.
Kita sudah cukup memahami tampilan data kita. Ketika Anda sudah sampai di titik ini, biasanya berarti Anda siap mulai menyiapkan data untuk dimasukkan ke model pembelajaran mesin.
Pemrosesan data adalah langkah penting dalam alur kerja pembelajaran mesin karena data dari dunia nyata berantakan. Data mungkin berisi:
Semua ini harus ditangani sebelum data dimasukkan ke model pembelajaran mesin; jika tidak, model akan memasukkan kesalahan tersebut ke dalam fungsi pendekatannya – model akan belajar membuat kesalahan pada instance baru. Inilah yang membentuk ungkapan terkenal dalam pembelajaran mesin, “Garbage in, garbage out.”
Alasan lainnya adalah model pembelajaran mesin umumnya memerlukan data numerik.
Selain data kita berada pada skala yang berbeda, sekilas tidak ada banyak masalah lain. Untuk mengatasi hal ini, mari menstandarkan fitur menggunakan kelas StandardScaler dari sklearn; ini akan menstandarkan fitur agar memiliki mean 0 dan simpangan baku 1.
Berikut kodenya:
from sklearn.preprocessing import StandardScaler
# Split data into features and label
X = wine_df[wine_data.feature_names].copy()
y = wine_df["target"].copy()
# Instantiate scaler and fit on features
scaler = StandardScaler()
scaler.fit(X)
# Transform features
X_scaled = scaler.transform(X.values)
# View first instance
print(X_scaled[0])
"""
[ 1.51861254 -0.5622498 0.23205254 -1.16959318 1.91390522 0.80899739
1.03481896 -0.65956311 1.22488398 0.25171685 0.36217728 1.84791957
1.01300893]
"""Mari lanjut ke pelatihan model.
Sebelum model pembelajaran mesin dapat membuat prediksi, model harus dilatih pada sekumpulan data untuk mempelajari fungsi pendekatan.
Namun bagaimana kita tahu apakah model berkinerja baik pada data yang belum pernah dilihat sebelumnya? Kita tidak akan tahu kecuali kita mengujinya.
Salah satu cara menguji model pembelajaran mesin sebelum menempatkannya di lingkungan yang berdampak pada orang lain adalah dengan membagi data pelatihan menjadi set pelatihan dan pengujian, lalu menggunakan set pengujian untuk mengevaluasi apa yang telah dipelajari model; ini dikenal sebagai evaluasi offline.
Ada beberapa cara untuk membagi data menjadi train dan test set, tetapi scikit-learn memiliki fungsi bawaan untuk melakukannya bagi kita yang disebut train_test_split().
Kita akan menggunakan fungsi ini untuk membagi data sehingga 70% digunakan untuk melatih model dan 30% digunakan untuk mengevaluasi kemampuan model menggeneralisasi ke instance yang belum pernah dilihat.
from sklearn.model_selection import train_test_split
# Split data into train and test
X_train_scaled, X_test_scaled, y_train, y_test = train_test_split(X_scaled,
y,
train_size=.7,
random_state=25)
# Check the splits are correct
print(f"Train size: {round(len(X_train_scaled) / len(X) * 100)}% \n\
Test size: {round(len(X_test_scaled) / len(X) * 100)}%")
"""
Train size: 70%
Test size: 30%
Sekarang mari membangun beberapa model.
Berkat sklearn, membangun model pembelajaran mesin sangatlah sederhana.
Kita akan membangun tiga model untuk memprediksi kelas wine:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# Instnatiating the models
logistic_regression = LogisticRegression()
svm = SVC()
tree = DecisionTreeClassifier()
# Training the models
logistic_regression.fit(X_train_scaled, y_train)
svm.fit(X_train_scaled, y_train)
tree.fit(X_train_scaled, y_train)
# Making predictions with each model
log_reg_preds = logistic_regression.predict(X_test_scaled)
svm_preds = svm.predict(X_test_scaled)
tree_preds = tree.predict(X_test_scaled)Langkah berikutnya adalah mengevaluasi bagaimana model menggeneralisasi ke instance yang belum pernah dilihat.
Evaluasi model dilakukan untuk menguji seberapa baik model menggeneralisasi ke instance yang belum pernah dilihat. Scikit-learn menyediakan beragam metrik klasifikasi dan regresi untuk mengevaluasi kinerja model terlatih.
Untuk kasus penggunaan kita, kita akan menggunakan classification_report() dari modul metrics untuk membuat laporan teks yang menampilkan metrik klasifikasi utama seperti precision, recall, f1_score, accuracy, dll.
Berikut tampilannya dalam kode:
from sklearn.metrics import classification_report
# Store model predictions in a dictionary
# this makes it easier to iterate through each model
# and print the results.
model_preds = {
"Logistic Regression": log_reg_preds,
"Support Vector Machine": svm_preds,
"Decision Tree": tree_preds
}
for model, preds in model_preds.items():
print(f"{model} Results:\n{classification_report(y_test, preds)}", sep="\n\n")
"""
Logistic Regression Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 0.92 0.96 25
2 0.86 1.00 0.92 12
accuracy 0.96 54
macro avg 0.95 0.97 0.96 54
weighted avg 0.97 0.96 0.96 54
Support Vector Machine Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 25
2 1.00 1.00 1.00 12
accuracy 1.00 54
macro avg 1.00 1.00 1.00 54
weighted avg 1.00 1.00 1.00 54
Decision Tree Results:
precision recall f1-score support
0 0.94 0.94 0.94 17
1 0.96 0.88 0.92 25
2 0.86 1.00 0.92 12
accuracy 0.93 54
macro avg 0.92 0.94 0.93 54
weighted avg 0.93 0.93 0.93 54
"""Sekilas, tampaknya support vector machine adalah model terbaik. Dalam alur kerja khas, ini akan memantik rasa ingin tahu terhadap model – apakah model benar-benar sebagus yang ditunjukkan, atau ada kesalahan di suatu tempat? Anda sebaiknya terdorong untuk mempelajari lebih lanjut tentang model Anda dan apa yang mereka pelajari, karena ini akan memberi Anda wawasan lebih baik tentang kekuatan dan kelemahannya.
Mengetahui informasi ini sangat berharga bagi para pemangku kepentingan karena memungkinkan mereka menemukan solusi untuk mengompensasi area di mana model kurang optimal.
Pustaka scikit-learn terdiri dari beberapa modul yang memudahkan penerapan model pembelajaran mesin. Modul-modul ini mencakup alat prapemrosesan untuk membantu Anda menyiapkan data agar dapat dimasukkan ke model pembelajaran mesin, model yang dapat Anda gunakan untuk menemukan pola dalam data, dan metrik evaluasi yang dapat Anda gunakan untuk menilai kinerja model Anda.
Dalam tutorial ini, kita baru sedikit mengulas kemampuan sklearn. Untuk menggali lebih dalam tentang apa yang dapat Anda lakukan dengan pustaka ini, kami memiliki beberapa sumber daya untuk memulai. Berikut beberapa di antaranya:
Pelajari lebih lanjut tentang Python dan Pembelajaran Mesin
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
