Cursus
Unsupervised Learning in Python
4 Hr
178.8K

Machine learning is een deelgebied van artificial intelligence dat zich richt op het begrijpen en bouwen van methoden die nabootsen hoe mensen leren. Deze methoden gebruiken algoritmen en data om de prestaties op een reeks taken te verbeteren en vallen vaak in een van de drie meest voorkomende soorten learning:
Scikit-learn, ook bekend als sklearn, is een open-source, robuuste Python-bibliotheek voor machine learning. De bibliotheek is gemaakt om het implementeren van machinelearning- en statistische modellen in Python te vereenvoudigen.
De bibliotheek stelt je in staat om snel een breed scala aan supervised en unsupervised machinelearning-algoritmen te implementeren via een consistente interface. Sklearn is gebouwd bovenop SciPy en werkt met allerlei soorten numerieke data die zijn opgeslagen als NumPy-arrays, SciPy-sparse matrices en alle andere datatypes die kunnen worden omgezet naar numerieke arrays, zoals Pandas DataFrames.
In deze hands-on sklearn-tutorial behandelen we verschillende aspecten van de machinelearning-levenscyclus, zoals dataverwerking, modeltraining en modelevaluatie.
Bekijk deze DataCamp Workspace om mee te coderen.
Het eerste aspect van sklearn dat we verkennen is de data; scikit-learn wordt geleverd met een aantal standaard machinelearning-datasets, wat betekent dat je ze niet hoeft te downloaden van een externe website of database.
Voorbeelden van de toy-datasets die in sklearn beschikbaar zijn, zijn de iris-dataset voor classificatie en de diabetes-dataset voor regressie. Voor ons voorbeeld gebruiken we de wijn-dataset.
Laten we die in het geheugen laden:
from sklearn.datasets import load_wine
wine_data = load_wine() Het uitvoeren van de bovenstaande code retourneert een dictionary-achtig object met de data en metadata over de inhoud.
De data die we nodig hebben staat in het .data-attribuut dat wordt geretourneerd door load_wine(). We kunnen dit benaderen als een attribuut van de wine_data-instantie als volgt:
wine_data.dataDit retourneert een N x M-array, waarbij N het aantal samples is en M het aantal features.
Laten we deze kennis gebruiken om onze data in een pandas DataFrame te laden, wat veel makkelijker te manipuleren en analyseren is.
import pandas as pd
from sklearn.datasets import load_wine
wine_data = load_wine()
# Convert data to pandas dataframe
wine_df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
# Add the target label
wine_df["target"] = wine_data.target
# Take a preview
wine_df.head()
Nu ben je klaar om wat data-exploratie te doen.
Pandas DataFrames zijn tweedimensionale gelabelde datastructuren die bestaan uit kolommen, die verschillende datatypen kunnen bevatten. De eenvoudigste manier om een DataFrame te begrijpen is om het te zien als drie samengevoegde componenten: 1) data, 2) een index en 3) kolommen.
Data-exploratie is niet de hoofdfocus van dit artikel, maar het is een enorm belangrijke stap in elk dataproject – je kunt er meer over leren in onze Python Exploratory Data Analysis-tutorial. We doen een korte verkenning om een beter beeld te krijgen van wat onze dataset bevat; dit geeft ons een beter idee van hoe we de data moeten verwerken.
Het eerste wat we gaan doen is de info()-methode aanroepen op ons pandas DataFrame; dit print een beknopte samenvatting van de wijndata in het DataFrame.
wine_df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 178 non-null float64
1 malic_acid 178 non-null float64
2 ash 178 non-null float64
3 alcalinity_of_ash 178 non-null float64
4 magnesium 178 non-null float64
5 total_phenols 178 non-null float64
6 flavanoids 178 non-null float64
7 nonflavanoid_phenols 178 non-null float64
8 proanthocyanins 178 non-null float64
9 color_intensity 178 non-null float64
10 hue 178 non-null float64
11 od280/od315_of_diluted_wines 178 non-null float64
12 proline 178 non-null float64
13 target 178 non-null int64
dtypes: float64(13), int64(1)
memory usage: 19.6 KB
"""Na het uitvoeren van deze cel leer je:
We kunnen ook de methode describe() aanroepen op ons DataFrame om beschrijvende statistieken te krijgen voor elke feature in de dataset.
Bijvoorbeeld:
wine_df.describe() 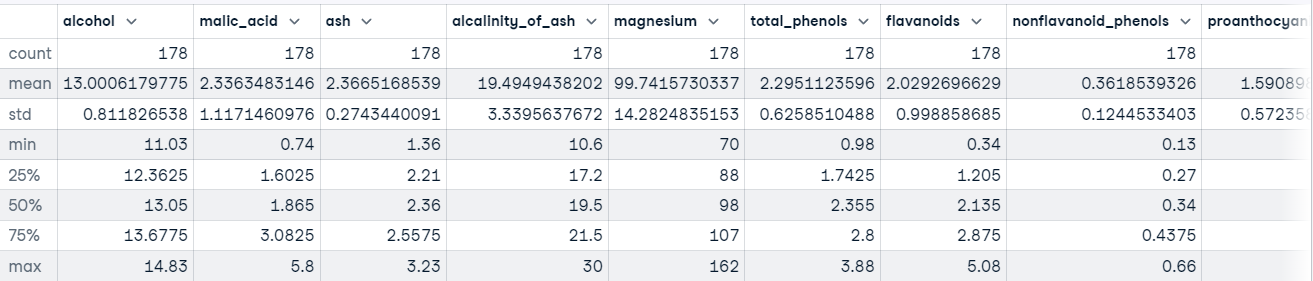
Je wilt ook een idee krijgen van het type waarden in elke feature. De snelste manier is de methode head() om de eerste vijf rijen te tonen of tail() om de laatste vijf rijen te bekijken.
wine_df.tail()
Het uitvoeren van deze code laat zien dat onze features op verschillende schalen staan, wat problemen kan veroorzaken bij algoritmen die op Gradient Descent zijn gebaseerd, zoals logistieke regressie, en bij afstandsgebaseerde algoritmen zoals support vector machines. Dat komt doordat ze gevoelig zijn voor de schaal van datapunten.
In een normale machinelearning-workflow is dit proces veel uitgebreider, maar we slaan door naar de dataverwerking om weer aan te sluiten bij de hoofdfocus van deze tutorial, scikit-learn.
Je kunt meer leren over Pandas in Python Pandas Tutorial: The Ultimate Guide for Beginners.
We hebben een redelijk beeld van hoe onze data eruitziet. Als je dit punt bereikt hebt, betekent het meestal dat je klaar bent om de data voor te bereiden om in een machinelearningmodel te voeren.
Dataverwerking is een cruciale stap in de machinelearning-workflow omdat data uit de echte wereld rommelig is. Die kan bevatten:
Dit moet je aanpakken voordat je de data aan een model voert; anders neemt het model deze fouten op in zijn approximatiefunctie – het leert fouten maken op nieuwe voorbeelden. Hier komt het bekende machinelearning-gezegde vandaan: “Garbage in, garbage out.”
Een andere reden is dat machinelearningmodellen doorgaans numerieke data vereisen.
Behalve dat onze data op verschillende schalen staat, lijkt er op het eerste gezicht weinig mis. Om dit probleem te verhelpen, standaardiseren we de features met sklearn’s StandardScaler -klasse; dit zorgt ervoor dat features een gemiddelde van 0 en een standaarddeviatie van 1 hebben.
Hier is de code:
from sklearn.preprocessing import StandardScaler
# Split data into features and label
X = wine_df[wine_data.feature_names].copy()
y = wine_df["target"].copy()
# Instantiate scaler and fit on features
scaler = StandardScaler()
scaler.fit(X)
# Transform features
X_scaled = scaler.transform(X.values)
# View first instance
print(X_scaled[0])
"""
[ 1.51861254 -0.5622498 0.23205254 -1.16959318 1.91390522 0.80899739
1.03481896 -0.65956311 1.22488398 0.25171685 0.36217728 1.84791957
1.01300893]
"""Laten we doorgaan met het trainen van het model.
Voordat een machinelearningmodel voorspellingen kan doen, moet het worden getraind op een dataset om een approximatiefunctie te leren.
Maar hoe weten we of het model goed presteert op data die het nog niet heeft gezien? Dat weten we niet, tenzij we het testen.
Een manier om een model te testen voordat je het inzet in een omgeving waar het impact heeft, is door de trainingsdata te splitsen in een train- en testset en de testset te gebruiken om te evalueren wat het model heeft geleerd; dit heet offline-evaluatie.
Er zijn verschillende manieren om data in train- en testsets te splitsen, maar scikit-learn heeft een ingebouwde functie die dit voor ons doet: train_test_split().
We gebruiken deze functie om onze data zo te splitsen dat 70% wordt gebruikt om het model te trainen en 30% om het generalisatievermogen naar onbekende voorbeelden te evalueren.
from sklearn.model_selection import train_test_split
# Split data into train and test
X_train_scaled, X_test_scaled, y_train, y_test = train_test_split(X_scaled,
y,
train_size=.7,
random_state=25)
# Check the splits are correct
print(f"Train size: {round(len(X_train_scaled) / len(X) * 100)}% \n\
Test size: {round(len(X_test_scaled) / len(X) * 100)}%")
"""
Train size: 70%
Test size: 30%
Laten we nu wat modellen bouwen.
Dankzij sklearn is het bouwen van een machinelearningmodel extreem eenvoudig.
We gaan drie modellen bouwen om de klasse van wijn te voorspellen:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# Instnatiating the models
logistic_regression = LogisticRegression()
svm = SVC()
tree = DecisionTreeClassifier()
# Training the models
logistic_regression.fit(X_train_scaled, y_train)
svm.fit(X_train_scaled, y_train)
tree.fit(X_train_scaled, y_train)
# Making predictions with each model
log_reg_preds = logistic_regression.predict(X_test_scaled)
svm_preds = svm.predict(X_test_scaled)
tree_preds = tree.predict(X_test_scaled)De volgende stap is evalueren hoe de modellen generaliseren naar onbekende voorbeelden.
Modelevaluatie wordt gedaan om te testen hoe goed het model generaliseert naar onbekende voorbeelden. Scikit-learn biedt allerlei classificatie- en regressiemetrieken om de prestaties van een getraind model te evalueren.
Voor ons gebruik gaan we classification_report() uit de metrics-module gebruiken om een tekstueel rapport te maken met de belangrijkste classificatiemetrieken, zoals precision, recall, f1_score, accuracy, enz.
Zo ziet dat eruit in code:
from sklearn.metrics import classification_report
# Store model predictions in a dictionary
# this makes it easier to iterate through each model
# and print the results.
model_preds = {
"Logistic Regression": log_reg_preds,
"Support Vector Machine": svm_preds,
"Decision Tree": tree_preds
}
for model, preds in model_preds.items():
print(f"{model} Results:\n{classification_report(y_test, preds)}", sep="\n\n")
"""
Logistic Regression Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 0.92 0.96 25
2 0.86 1.00 0.92 12
accuracy 0.96 54
macro avg 0.95 0.97 0.96 54
weighted avg 0.97 0.96 0.96 54
Support Vector Machine Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 25
2 1.00 1.00 1.00 12
accuracy 1.00 54
macro avg 1.00 1.00 1.00 54
weighted avg 1.00 1.00 1.00 54
Decision Tree Results:
precision recall f1-score support
0 0.94 0.94 0.94 17
1 0.96 0.88 0.92 25
2 0.86 1.00 0.92 12
accuracy 0.93 54
macro avg 0.92 0.94 0.93 54
weighted avg 0.93 0.93 0.93 54
"""Op het eerste gezicht lijkt de support vector machine het beste model. In een typische workflow wekt dit nieuwsgierigheid naar het model – is het echt zo goed als het lijkt, of hebben we ergens een fout gemaakt? Je zou benieuwd moeten zijn naar je modellen en wat ze leren, want dat geeft je beter inzicht in hun sterke en zwakke punten.
Deze informatie is uiterst waardevol voor stakeholders, omdat ze zo oplossingen kunnen vinden om tekortkomingen van het model te compenseren.
De scikit-learn-bibliotheek bestaat uit verschillende modules die het implementeren van machinelearningmodellen eenvoudig maken. Deze modules variëren van preprocessingtools om je data klaar te maken voor een model, tot modellen om patronen in je data te vinden en evaluatiemetrieken om de prestaties van je model te beoordelen.
In deze tutorial hebben we slechts aan de oppervlakte gekrabd van wat sklearn kan. Om dieper te duiken in wat je met de bibliotheek kunt doen, hebben we verschillende resources om je op weg te helpen. Hier zijn er een paar om mee te beginnen:
Leer meer over Python en machine learning
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
