Courses
Unsupervised Learning bằng Python
4 giờ
179.2K

Học máy là một phân ngành của trí tuệ nhân tạo tập trung vào việc hiểu và xây dựng các phương pháp mô phỏng cách con người học. Những phương pháp này bao gồm việc dùng thuật toán và dữ liệu để cải thiện hiệu suất trên một tập tác vụ, và thường rơi vào một trong ba loại học phổ biến nhất:
Scikit-learn, còn gọi là sklearn, là một thư viện học máy Python mã nguồn mở, mạnh mẽ. Nó được tạo ra để đơn giản hóa quá trình triển khai các mô hình học máy và thống kê trong Python.
Thư viện cho phép người dùng nhanh chóng triển khai hàng loạt thuật toán học máy có giám sát và không giám sát thông qua một giao diện thống nhất. Sklearn được xây dựng trên SciPy và hoạt động với mọi loại dữ liệu số được lưu dưới dạng mảng NumPy, ma trận thưa SciPy, và các kiểu dữ liệu khác có thể chuyển đổi thành mảng số như Pandas DataFrame.
Trong hướng dẫn thực hành sklearn này, chúng ta sẽ bao quát nhiều khía cạnh của vòng đời học máy, như xử lý dữ liệu, huấn luyện mô hình, và đánh giá mô hình.
Hãy xem workspace của DataCamp này để theo dõi phần mã.
Khía cạnh đầu tiên của sklearn mà chúng ta sẽ khám phá là dữ liệu; Scikit-learn đi kèm một số tập dữ liệu học máy tiêu chuẩn, nghĩa là bạn không cần tải chúng từ website hay cơ sở dữ liệu bên ngoài.
Ví dụ về các tập dữ liệu mẫu có sẵn trong sklearn gồm tập iris cho phân loại và tập diabetes cho hồi quy. Trong ví dụ này, chúng ta sẽ dùng tập dữ liệu rượu vang.
Hãy nạp nó vào bộ nhớ:
from sklearn.datasets import load_wine
wine_data = load_wine() Chạy đoạn mã trên trả về một đối tượng giống từ điển chứa dữ liệu cùng siêu dữ liệu về chính dữ liệu đó.
Dữ liệu chúng ta cần nằm trong thuộc tính .data do load_wine() trả về. Ta có thể truy cập nó như một thuộc tính của thể hiện wine_data như sau:
wine_data.dataĐiều này trả về một mảng N x M, trong đó N là số mẫu và M là số đặc trưng.
Hãy dùng thông tin này để nạp dữ liệu của chúng ta vào một Pandas DataFrame, vốn dễ thao tác và phân tích hơn.
import pandas as pd
from sklearn.datasets import load_wine
wine_data = load_wine()
# Convert data to pandas dataframe
wine_df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
# Add the target label
wine_df["target"] = wine_data.target
# Take a preview
wine_df.head()
Giờ bạn đã sẵn sàng khám phá dữ liệu.
Pandas DataFrame được định nghĩa là cấu trúc dữ liệu hai chiều có nhãn gồm các cột, có thể chứa các kiểu dữ liệu khác nhau. Cách dễ nhất để hình dung một DataFrame là xem nó như ba thành phần hợp lại; đó là 1) dữ liệu, 2) chỉ mục, và 3) các cột.
Khám phá dữ liệu không phải trọng tâm của bài viết này nhưng là bước cực kỳ quan trọng trong bất kỳ dự án dữ liệu nào – bạn có thể tìm hiểu thêm trong hướng dẫn Phân tích Khám phá Dữ liệu bằng Python. Chúng ta sẽ khám phá ngắn gọn để hiểu rõ hơn tập dữ liệu chứa gì; điều này sẽ giúp ta biết cách xử lý dữ liệu tốt hơn.
Đầu tiên, chúng ta sẽ gọi phương thức info() trên DataFrame của pandas; thao tác này sẽ in ra tóm tắt súc tích về dữ liệu rượu vang có trong DataFrame.
wine_df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 178 non-null float64
1 malic_acid 178 non-null float64
2 ash 178 non-null float64
3 alcalinity_of_ash 178 non-null float64
4 magnesium 178 non-null float64
5 total_phenols 178 non-null float64
6 flavanoids 178 non-null float64
7 nonflavanoid_phenols 178 non-null float64
8 proanthocyanins 178 non-null float64
9 color_intensity 178 non-null float64
10 hue 178 non-null float64
11 od280/od315_of_diluted_wines 178 non-null float64
12 proline 178 non-null float64
13 target 178 non-null int64
dtypes: float64(13), int64(1)
memory usage: 19.6 KB
"""Sau khi chạy ô này, bạn sẽ biết:
Chúng ta cũng có thể gọi phương thức describe() trên DataFrame để lấy các thống kê mô tả về từng đặc trưng trong tập dữ liệu.
Ví dụ:
wine_df.describe() 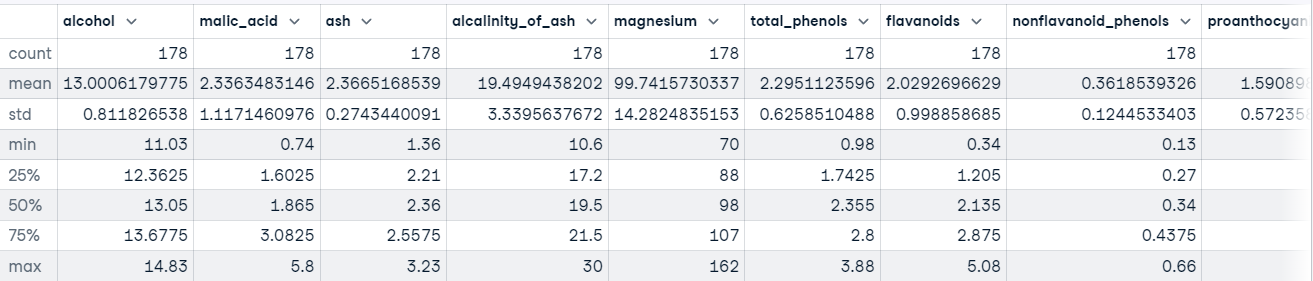
Bạn cũng muốn hình dung sơ bộ loại giá trị trong mỗi đặc trưng. Cách nhanh nhất là dùng phương thức head() để hiển thị năm hàng đầu tiên hoặc tail() để xem năm hàng cuối cùng.
wine_df.tail()
Chạy đoạn mã này cho thấy các đặc trưng của chúng ta đang ở các thang đo khác nhau, điều này có thể gây vấn đề khi làm việc với các thuật toán dựa trên Gradient Descent như hồi quy logistic, và với các thuật toán dựa trên khoảng cách như máy vector hỗ trợ. Nguyên nhân là chúng nhạy cảm với miền giá trị của các điểm dữ liệu.
Trong một quy trình học máy thông thường, bước này sẽ được triển khai kỹ lưỡng hơn, nhưng chúng ta sẽ chuyển nhanh sang phần xử lý dữ liệu để bám sát trọng tâm chính của hướng dẫn này, Scikit-learn.
Bạn có thể tìm hiểu thêm về Pandas trong Python Pandas Tutorial: Hướng dẫn Tối ưu cho Người Mới Bắt đầu.
Chúng ta đã có cái nhìn tạm ổn về dữ liệu. Khi đến giai đoạn này, thường có nghĩa là bạn sẵn sàng bắt đầu chuẩn bị dữ liệu để đưa vào mô hình học máy.
Xử lý dữ liệu là bước sống còn trong quy trình học máy vì dữ liệu ngoài đời thực rất lộn xộn. Nó có thể chứa:
Bạn phải xử lý tất cả những điều này trước khi đưa dữ liệu vào mô hình học máy; nếu không, mô hình sẽ đưa các sai sót đó vào hàm xấp xỉ của mình – nó sẽ “học” để mắc lỗi trên các trường hợp mới. Đây chính là nguồn gốc câu nói nổi tiếng trong học máy, “Rác vào, rác ra.”
Một lý do khác là các mô hình học máy thường yêu cầu dữ liệu số.
Ngoài việc dữ liệu của chúng ta nằm trên các thang đo khác nhau, thoạt nhìn chưa thấy vấn đề gì đáng kể. Để khắc phục, hãy chuẩn hóa các đặc trưng bằng lớp StandardScaler của sklearn; cách này sẽ chuẩn hóa đặc trưng sao cho có trung bình 0 và độ lệch chuẩn 1.
Mã như sau:
from sklearn.preprocessing import StandardScaler
# Split data into features and label
X = wine_df[wine_data.feature_names].copy()
y = wine_df["target"].copy()
# Instantiate scaler and fit on features
scaler = StandardScaler()
scaler.fit(X)
# Transform features
X_scaled = scaler.transform(X.values)
# View first instance
print(X_scaled[0])
"""
[ 1.51861254 -0.5622498 0.23205254 -1.16959318 1.91390522 0.80899739
1.03481896 -0.65956311 1.22488398 0.25171685 0.36217728 1.84791957
1.01300893]
"""Hãy chuyển sang huấn luyện mô hình.
Trước khi một mô hình học máy có thể dự đoán, nó phải được huấn luyện trên một tập dữ liệu để học hàm xấp xỉ.
Nhưng làm sao biết mô hình hoạt động tốt với dữ liệu chưa từng thấy? Ta sẽ không biết trừ khi kiểm thử.
Một cách để kiểm thử mô hình học máy trước khi đưa vào môi trường tác động đến người khác là tách dữ liệu huấn luyện thành tập huấn luyện và tập kiểm thử và dùng tập kiểm thử để đánh giá những gì mô hình đã học; điều này gọi là đánh giá ngoại tuyến.
Có nhiều cách để chia dữ liệu thành tập train và test, nhưng scikit-learn có sẵn một hàm thực hiện giúp chúng ta là train_test_split().
Chúng ta sẽ dùng hàm này để chia dữ liệu sao cho 70% dùng để huấn luyện mô hình và 30% dùng để đánh giá khả năng khái quát hóa tới các trường hợp chưa thấy của mô hình.
from sklearn.model_selection import train_test_split
# Split data into train and test
X_train_scaled, X_test_scaled, y_train, y_test = train_test_split(X_scaled,
y,
train_size=.7,
random_state=25)
# Check the splits are correct
print(f"Train size: {round(len(X_train_scaled) / len(X) * 100)}% \n\
Test size: {round(len(X_test_scaled) / len(X) * 100)}%")
"""
Train size: 70%
Test size: 30%
Bây giờ hãy xây dựng vài mô hình.
Nhờ sklearn, xây dựng một mô hình học máy trở nên cực kỳ đơn giản.
Chúng ta sẽ xây dựng ba mô hình để dự đoán hạng rượu vang:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# Instnatiating the models
logistic_regression = LogisticRegression()
svm = SVC()
tree = DecisionTreeClassifier()
# Training the models
logistic_regression.fit(X_train_scaled, y_train)
svm.fit(X_train_scaled, y_train)
tree.fit(X_train_scaled, y_train)
# Making predictions with each model
log_reg_preds = logistic_regression.predict(X_test_scaled)
svm_preds = svm.predict(X_test_scaled)
tree_preds = tree.predict(X_test_scaled)Bước tiếp theo là đánh giá mức độ mô hình khái quát hóa với các trường hợp chưa thấy.
Đánh giá mô hình nhằm kiểm tra mô hình khái quát hóa tốt thế nào với các trường hợp chưa thấy. Scikit-learn cung cấp nhiều thước đo phân loại và hồi quy để đánh giá hiệu suất của mô hình đã huấn luyện.
Với bài toán của chúng ta, sẽ dùng classification_report() từ mô-đun metrics để tạo báo cáo văn bản hiển thị các chỉ số phân loại chính như precision, recall, f1_score, accuracy, v.v.
Mã trông như sau:
from sklearn.metrics import classification_report
# Store model predictions in a dictionary
# this makes it easier to iterate through each model
# and print the results.
model_preds = {
"Logistic Regression": log_reg_preds,
"Support Vector Machine": svm_preds,
"Decision Tree": tree_preds
}
for model, preds in model_preds.items():
print(f"{model} Results:\n{classification_report(y_test, preds)}", sep="\n\n")
"""
Logistic Regression Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 0.92 0.96 25
2 0.86 1.00 0.92 12
accuracy 0.96 54
macro avg 0.95 0.97 0.96 54
weighted avg 0.97 0.96 0.96 54
Support Vector Machine Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 25
2 1.00 1.00 1.00 12
accuracy 1.00 54
macro avg 1.00 1.00 1.00 54
weighted avg 1.00 1.00 1.00 54
Decision Tree Results:
precision recall f1-score support
0 0.94 0.94 0.94 17
1 0.96 0.88 0.92 25
2 0.86 1.00 0.92 12
accuracy 0.93 54
macro avg 0.92 0.94 0.93 54
weighted avg 0.93 0.93 0.93 54
"""Nhìn qua, có vẻ máy vector hỗ trợ là mô hình tốt nhất. Trong một quy trình điển hình, điều này sẽ khơi gợi sự tò mò về mô hình – liệu nó thực sự tốt như kết quả thể hiện, hay chúng ta đã mắc lỗi ở đâu đó? Bạn nên hứng thú tìm hiểu thêm về các mô hình và những gì chúng học được, vì điều này sẽ giúp bạn hiểu rõ điểm mạnh và điểm yếu của chúng.
Biết được thông tin này cực kỳ hữu ích cho các bên liên quan vì nó giúp họ tìm giải pháp bù đắp cho những chỗ mô hình còn hạn chế.
Thư viện scikit-learn bao gồm nhiều mô-đun giúp triển khai các mô hình học máy trở nên dễ dàng. Các mô-đun này trải dài từ công cụ tiền xử lý giúp bạn chuẩn bị dữ liệu để đưa vào mô hình học máy, đến các mô hình bạn có thể dùng để tìm mẫu trong dữ liệu, và các thước đo đánh giá để kiểm định hiệu suất mô hình.
Trong hướng dẫn này, chúng ta mới chỉ chạm tới bề mặt khả năng của sklearn. Để đào sâu hơn những gì bạn có thể làm với thư viện, chúng tôi có một số tài nguyên để bạn bắt đầu. Dưới đây là vài tài nguyên khởi đầu:
Tìm hiểu thêm về Python và Học máy
Courses
Courses
Courses