
Cours
Retrieval Augmented Generation (RAG) avec LangChain
3 h
13.7K
Lorsque j'ai commencé à explorer les systèmes de génération augmentée par la récupération (RAG), j'ai rapidement compris que l'un des facteurs les plus négligés, mais néanmoins essentiels, influençant leurs performances était le découpage en morceaux.
À la base, le découpage consiste à diviser de grandes quantités d'informations, telles que des documents, des transcriptions ou des manuels techniques, en segments plus petits et plus faciles à gérer. Ces segments peuvent ensuite être traités, intégrés et récupérés par des systèmes d'intelligence artificielle.
Dans le cadre de mon travail sur les modèles linguistiques modernes et leurs contraintes contextuelles, je constate que la compréhension et l'application de stratégies de segmentation efficaces sont essentielles pour toute personne qui développe des pipelines RAG, des systèmes de recherche sémantique ou des applications de traitement de documents.
Dans ce guide, je vous présenterai le concept de chunking, j'expliquerai son importance dans les applications d'IA, je décrirai son rôle dans le pipeline RAG et j'aborderai l'impact de différentes stratégies sur la précision de la recherche. J'aborderai également les considérations pratiques liées à la mise en œuvre, les méthodes d'évaluation, les cas d'utilisation spécifiques à un domaine et les meilleures pratiques qui peuvent vous aider à choisir l'approche la mieux adaptée à votre projet.
Si vous débutez dans le domaine des applications RAG et IA, je vous recommande de suivre l'un de nos cours, tel que Retrieval Augmented Generation (RAG) avec LangChain, Certification sur les principes fondamentaux de l'IAou Stratégie en matière d'intelligence artificielle (IA).
L'importance du découpage en blocs va bien au-delà de la simple organisation des données ; elle influence fondamentalement la manière dont les systèmes d'IA comprennent et récupèrent les informations.
Les grands modèles linguistiques et les pipelines RAG nécessitent un découpage en morceaux en raison de leurs limites inhérentes en matière de fenêtres contextuelles et de contraintes informatiques.
Lorsque je traite des documents volumineux sans les diviser en segments appropriés, le système perd souvent des relations contextuelles importantes et éprouve des difficultés à identifier les informations pertinentes lors de la recherche. Un découpage efficace améliore directement la précision de la recherche en créant des segments sémantiquement cohérents qui correspondent aux modèles de requête et à l'intention de l'utilisateur.
D'après mon expérience, des stratégies de segmentation bien mises en œuvre améliorent considérablement les capacités de recherche sémantique en conservant le flux logique des informations tout en garantissant que chaque segment contient suffisamment de contexte pour permettre des intégrations pertinentes. Cette approche permet aux modèles d'intégration de saisir des relations nuancées et d'effectuer des correspondances de similarité plus précises lors de la recherche.
D'autre part, des stratégies de segmentation inadéquates peuvent entraîner des répercussions négatives en cascade tout au long du processus d'IA. Des divisions arbitraires peuvent rompre des liens essentiels entre les concepts, conduisant à des réponses incomplètes ou trompeuses. Lorsque les segments sont trop volumineux, les systèmes de recherche ont des difficultés à identifier les passages pertinents spécifiques, tandis que les segments trop petits manquent souvent de contexte pour permettre une compréhension précise. Ces problèmes entraînent en fin de compte une baisse de la satisfaction des utilisateurs et compromettent la fiabilité du système.
Le chunking occupe une position essentielle dans le pipeline RAG, servant de pont entre l'ingestion de documents bruts et la récupération de connaissances significatives. Dans le pipeline RAG de bout en bout, le découpage en morceaux se produit généralement après le prétraitement des documents, mais avant la génération d'intégration. Le processus de segmentation alimente directement l'étape d'intégration, au cours de laquelle chaque segment est converti en représentations vectorielles qui capturent la signification sémantique.altPipeline RAG d'alt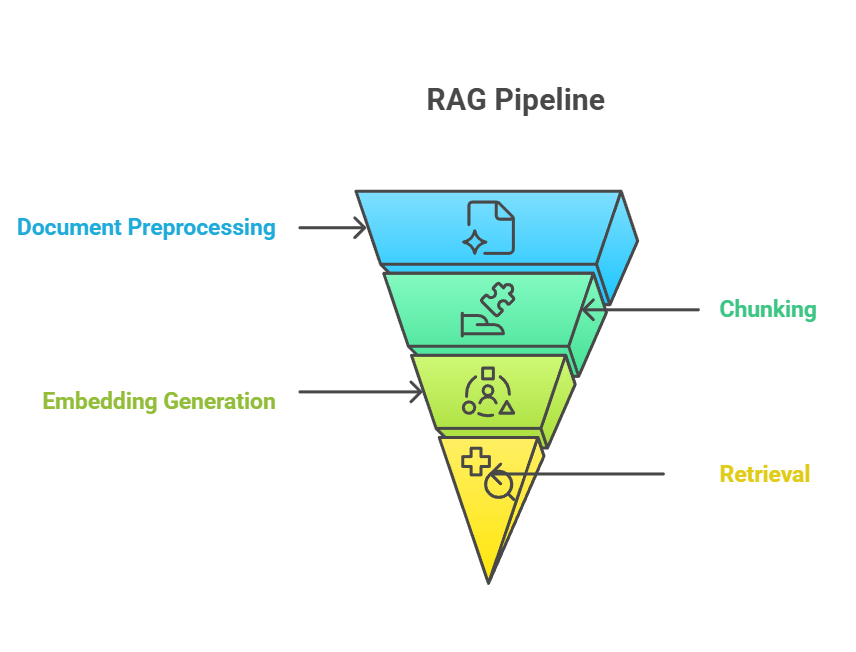
Pipeline RAG
La relation entre le découpage, l'intégration et la récupération forme un système étroitement lié où l'efficacité de chaque composante dépend de la performance des autres.
Lorsque je crée des segments bien structurés, les modèles d'intégration peuvent générer des représentations vectorielles plus riches, qui permettent à leur tour d'obtenir des résultats de recherche plus précis lorsqu'un utilisateur effectue une requête. Cette synergie signifie que les améliorations apportées au découpage se traduisent souvent par des gains de performance mesurables sur l'ensemble du pipeline.
Cela dit, certaines approches plus récentes remettent en question cet ordre traditionnel. Par exemple, le post-chunking intègre d'abord des documents entiers et ne les découpe en morceaux qu'au moment de la requête, en mettant les résultats en cache pour un accès plus rapide ultérieurement. Cette méthode évite le prétraitement des documents qui pourraient ne jamais être interrogés tout en permettant un découpage spécifique à la requête, mais elle introduit une latence lors du premier accès et nécessite une infrastructure supplémentaire.
De même, le fractionnement tardif diffère la segmentation fine jusqu'à la récupération. Au lieu de précalculer les intégrations pour de nombreux petits segments, le système stocke des représentations plus grossières (par exemple, des documents ou des sections entiers) et les divise de manière dynamique lorsqu'une requête est reçue. Cela permet de conserver un contexte plus large tout en réduisant le traitement initial, bien que cela introduise une latence lors de la première requête et nécessite une infrastructure supplémentaire.
Quelle que soit l'approche adoptée, les stratégies de segmentation doivent s'adapter à la fenêtre contextuelle du modèle linguistique utilisé, c'est-à-dire la quantité maximale de texte qu'un modèle peut traiter et prendre en compte à un moment donné.
Maintenant que vous avez une idée de ce qu'est le découpage en morceaux et de sa place dans le processus, il est temps d'examiner les principes fondamentaux qui guident les stratégies efficaces de découpage en morceaux. La compréhension de ces principes fondamentaux constitue la base de l'application du chunking dans un large éventail d'applications d'IA et de RAG.
Le découpage en morceaux est nécessaire car les modèles linguistiques ont une fenêtre contextuelle limitée. L'objectif principal est de créer des segments qui ont un sens indépendamment les uns des autres tout en préservant collectivement la structure et l'intention globales du document, le tout dans la fenêtre contextuelle du modèle.
Cependant, la fenêtre contextuelle n'est pas le seul élément à prendre en considération. Lorsque je conçois des stratégies de segmentation, je me concentre sur trois principes fondamentaux :
Ces principes fonctionnent conjointement pour rendre les segments à la fois utiles pour le modèle et efficaces pour les pipelines de récupération. Une fois ces bases établies, je peux maintenant passer en revue les stratégies de segmentation les plus couramment utilisées dans la pratique.
Le paysage des stratégies de segmentation offre diverses approches adaptées à différents types de contenu, applications et exigences de performance. Dans l'image ci-dessous, vous pouvez observer un aperçu des principales méthodes de segmentation, que j'aborderai plus en détail dans les sections suivantes.
Aperçu des stratégies de segmentation
Cet aperçu complet illustre l'évolution des approches simples basées sur des règles vers des techniques sophistiquées basées sur l'intelligence artificielle, chacune offrant des avantages distincts pour des applications et des exigences de performance spécifiques.
Examinons de plus près les stratégies de découpage les plus couramment utilisées. Chaque méthode présente des avantages, des limites et des scénarios d'application spécifiques. En comprenant ces différences, je suis en mesure de sélectionner l'approche la plus appropriée pour un projet spécifique, plutôt que d'opter systématiquement pour des solutions universelles. Nous commencerons par l'approche la plus simple : le découpage en morceaux de taille fixe.
Le découpage en morceaux de taille fixe est la méthode la plus simple. Il divise le texte en segments en fonction des caractères, des mots ou des tokens, sans tenir compte du sens ou de la structure.
Le principal avantage du découpage en morceaux de taille fixe réside dans son efficacité informatique : il est rapide, prévisible et facile à mettre en œuvre. L'inconvénient est qu'il ignore souvent la structure sémantique, ce qui peut réduire la précision de la recherche. J'utilise généralement cette méthode lorsque la simplicité et la rapidité priment sur la précision sémantique, et lorsque la structure du document n'est pas importante. Afin d'améliorer les performances, j'ajoute fréquemment un chevauchement entre les segments pour préserver le contexte au-delà des limites.
Une méthode pour pallier certaines de ces lacunes consiste à utiliser le découpage en segments basé sur les phrases, qui respecte les limites naturelles du langage, généralement en détectant les signes de ponctuation tels que les points ou les points d'interrogation.
Cette approche préserve la lisibilité et garantit que chaque bloc reste autonome. Par rapport au découpage en morceaux de taille fixe, cette méthode produit des segments plus faciles à interpréter pour les humains et les modèles. Cependant, la longueur des phrases varie, de sorte que la taille des segments peut être inégale et ne pas toujours refléter les relations sémantiques plus profondes.
Je considère que le découpage en phrases est particulièrement utile pour les applications qui reposent sur le flux du langage naturel, telles que la traduction automatique, l'analyse des sentiments ou les tâches de résumé. Cependant, lorsque les documents présentent une structure plus complexe que de simples phrases, le découpage récursif constitue une alternative flexible.
Le découpage récursif est une technique plus avancée que les méthodes précédentes. Il applique les règles de fractionnement étape par étape jusqu'à ce que chaque morceau respecte la limite de taille définie. Par exemple, je pourrais d'abord diviser par en-têtes de section, puis par paragraphes, et enfin par phrases. Le processus se poursuit jusqu'à ce que chaque pièce soit maniable et respecte les dimensions prédéfinies.
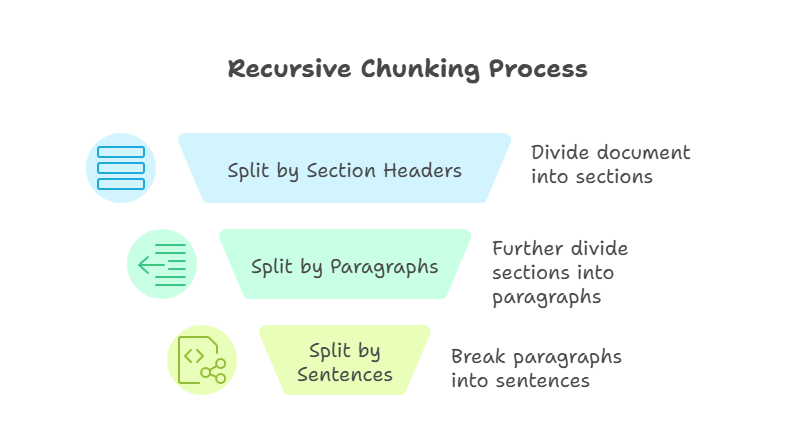
Découpage récursif
Le principal avantage de cette approche réside dans sa flexibilité. En fonctionnant de manière descendante, le découpage récursif préserve la structure du document tout en garantissant la compatibilité avec les fenêtres contextuelles du modèle. Cependant, le découpage récursif peut être plus complexe à mettre en œuvre, et la qualité des résultats dépend de la qualité de la structure du document source.
Je recourt fréquemment au découpage récursif lorsque je travaille sur des manuels techniques ou d'autres documents présentant une hiérarchie claire.
Alors que les méthodes récursives s'appuient sur la structure, le découpage sémantique met l'accent sur le sens, en divisant le texte en fonction des limites conceptuelles. Le découpage sémantique est une technique sensible au sens qui utilise des intégrations ou la similarité sémantique pour diviser le texte lorsque des changements de sujet se produisent. Au lieu de frontières arbitraires, les segments sont définis par leur signification.
Une approche consiste à diviser le texte en phrases et à mesurer la similarité sémantique entre elles (par exemple, la similarité cosinus sur les plongements), en marquant les nouveaux segments lorsque la cohérence diminue. Les implémentations plus avancées utilisent des méthodes de regroupement ou des modèles de détection des limites supervisés, qui permettent de mieux saisir les changements de sujet dans les documents complexes.
Segmentation sémantique
Cette méthode préserve la cohérence sémantique, garantissant que chaque segment couvre une seule idée ou un seul thème. Les techniques peuvent inclure l'intégration de la similarité, le regroupement ou d'autres calculs de distance sémantique pour détecter les points de rupture naturels.
Le principal avantage réside dans la précision : le découpage sémantique crée des segments qui correspondent étroitement à l'intention de l'utilisateur lors de la recherche. Le principal inconvénient réside dans le coût de calcul, car il nécessite l'intégration du texte lors du prétraitement. J'utilise le découpage sémantique lorsque la précision est plus importante que la vitesse, comme dans les systèmes RAG spécifiques aux domaines juridique ou médical.
Contrairement au découpage sémantique, qui met l'accent sur la cohérence sémantique, le découpage par fenêtre glissante privilégie la continuité en superposant les segments, déplaçant une fenêtre à travers le texte. Par exemple, si j'utilise une taille de bloc (fenêtre) de 500 tokens avec un pas de 250, chaque bloc chevauche la moitié du bloc précédent.
Ce chevauchement préserve le contexte entre les limites des blocs, réduisant ainsi le risque de perdre des informations importantes aux extrémités. Cela améliore également la précision de la recherche, car plusieurs fragments qui se chevauchent peuvent apparaître en réponse à une requête. Le compromis est la redondance : le chevauchement augmente les coûts de stockage et de traitement. Les fenêtres coulissantes sont particulièrement utiles pour les textes non structurés tels que les journaux de discussion ou les transcriptions de podcasts.
Découpage par fenêtres glissantes
Lorsque je mets en œuvre cette stratégie, j'utilise généralement un chevauchement de 20 à 50 % entre les segments afin de préserver le contexte d'un segment à l'autre, en particulier dans les textes techniques ou conversationnels. Les tailles de blocs de 200 à 400 jetons sont couramment utilisées par défaut dans des frameworks tels que LangChain, bien qu'elles puissent être ajustées en fonction des limites du contexte du modèle et du type de document. Je recommande cette approche pour les applications où la préservation du contexte est essentielle et où l'efficacité du stockage est moins importante.
Lorsque la continuité n'est pas suffisante et que la structure du document doit être préservée, le découpage hiérarchique et contextuel entre en jeu.
Le découpage hiérarchique préserve la structure complète d'un document, des sections jusqu'aux phrases. Au lieu de produire une liste plate de morceaux, il construit une arborescence qui reflète la hiérarchie d'origine. Chaque bloc a unerelation parent-enfant avec les niveaux situés au-dessus et en dessous. Par exemple, une section peut contenir plusieurs paragraphes (parent → enfants), et chaque paragraphe peut contenir plusieurs phrases.
Lors de la récupération, cette structure permet une navigation flexible. Si une requête correspond à un segment au niveau de la phrase, le système peut s'étendre vers le haut pour fournir un contexte supplémentaire à partir de son paragraphe parent ou même de la section entière. À l'inverse, si une requête générale correspond à un bloc au niveau de la section, le système peut approfondir la recherche jusqu'au paragraphe ou à la phrase enfant le plus pertinent. Cette recherche à plusieurs niveaux améliore à la fois la précision et le rappel, car le modèle peut adapter la portée du contenu renvoyé.
Chunking hiérarchique
L', ou segmentation contextuelle, va plus loin en enrichissant les segments avec des métadonnées telles que des titres, des horodatages ou des références sources. Ces informations supplémentaires fournissent des indications importantes qui aident les systèmes de recherche à lever l'ambiguïté des résultats. Par exemple, deux documents peuvent contenir des phrases presque identiques, mais leurs titres de section ou leurs horodatages peuvent déterminer lequel est le plus pertinent pour une requête. Les métadonnées facilitent également le traçage des réponses jusqu'à leur source, ce qui est particulièrement utile dans les domaines réglementés ou soumis à des exigences de conformité.
Segmentation contextuelle
Le principal avantage du découpage hiérarchique et contextuel réside dans sa précision et sa flexibilité. Le compromis réside dans une complexité accrue tant au niveau du prétraitement que de la logique de recherche, car le système doit gérer les relations entre les segments au lieu de les traiter comme des unités indépendantes. Je recommande ces approches pour des domaines tels que les contrats juridiques, les rapports financiers ou les spécifications techniques, où il est essentiel de préserver la structure et la traçabilité.
Tous les documents ne suivent pas une hiérarchie stricte, c'est pourquoi le découpage par thème ou par modalité offre une manière plus flexible de regrouper les contenus connexes.
Le regroupement par thème regroupe le texte par unités thématiques à l'aide d'algorithmes tels que l'allocation latente de Dirichlet (LDA) pour la modélisation par sujet ou des méthodes de regroupement basées sur l'intégration afin d'identifier les limites sémantiques.
Au lieu d'utiliser des tailles fixes ou des balises structurelles, l'objectif est de regrouper tout le contenu lié à un thème au même endroit. Cette approche est particulièrement efficace pour les contenus longs, tels que les rapports de recherche ou les articles qui abordent différents sujets. Étant donné que chaque segment reste centré sur un thème unique, les résultats de recherche sont plus en adéquation avec l'intention de l'utilisateur et moins susceptibles d'inclure des informations non pertinentes.
L' du découpage spécifique à chaque modalité adapte les stratégies aux différents types de contenu, garantissant ainsi que les informations sont segmentées de manière à respecter la structure de chaque support. Par exemple :
Chunking thématique et spécifique à la modalité
Les métadonnées jouent un rôle particulièrement important dans le découpage spécifique à une modalité. Par exemple, associer des en-têtes de colonnes aux lignes d'un tableau, relier des légendes à des zones d'images ou ajouter des étiquettes de locuteurs et des horodatages aux transcriptions aide les systèmes de recherche à localiser le bon fragment et à l'interpréter correctement. Cet enrichissement améliore à la fois la précision et la confiance des utilisateurs, car les résultats sont accompagnés de signaux contextuels qui expliquent leur pertinence.
Je recommande d'appliquer un découpage spécifique à chaque modalité lorsque vous travaillez avec des pipelines multimodaux ou des documents non traditionnels qui ne s'adaptent pas parfaitement aux stratégies basées sur le texte. Il garantit que chaque type de contenu est représenté de manière à optimiser la qualité de la recherche et la facilité d'utilisation.
Au-delà de ces méthodes fondées sur des règles et le sens, des approches de pointe telles que le chunking dynamique basé sur l'IA et le chunking agentique repoussent encore plus loin les limites.
L', qui repose sur l'intelligence artificielle, utilise un modèle linguistique de grande envergure pour déterminer directement les limites des segments, plutôt que de s'appuyer sur des règles prédéfinies. Le LLM analyse le document, identifie les points de rupture naturels et ajuste la taille des blocs de manière adaptative.
Les sections denses peuvent être divisées en morceaux plus petits, tandis que les sections plus légères peuvent être regroupées. Il en résulte des segments sémantiquement cohérents qui capturent des concepts complets, améliorant ainsi la précision de la recherche. Cette méthode est appropriée lorsque vous travaillez avec des documents complexes et de grande valeur, tels que des contrats juridiques, des manuels de conformité ou des documents de recherche, pour lesquels la précision de la recherche est plus importante que le débit ou le coût.
D'autre part, le découpage agentique s'appuie sur cette idée en introduisant un raisonnement à un niveau supérieur. Au lieu de simplement laisser le LLM diviser le texte, un agent IA évalue le document et l'intention de l'utilisateur, puis détermine comment le segmenter.
L'agent peut adopter différentes stratégies pour différentes sections. Par exemple, décomposer un rapport médical en fonction des antécédents du patient, des résultats de laboratoire et des notes du médecin, tout en appliquant une segmentation sémantique aux descriptions narratives. Il pourrait également enrichir certaines parties avec des métadonnées telles que des horodatages, des codes de diagnostic ou des identifiants de cliniciens.
De cette manière, le découpage agentique agit comme une couche d'orchestration : l'agent sélectionne ou combine dynamiquement les approches de découpage, plutôt que d'appliquer une seule méthode à l'ensemble du document. Le résultat est un découpage plus personnalisé et plus adapté au contexte, mais au prix d'une plus grande complexité et d'exigences informatiques plus élevées.
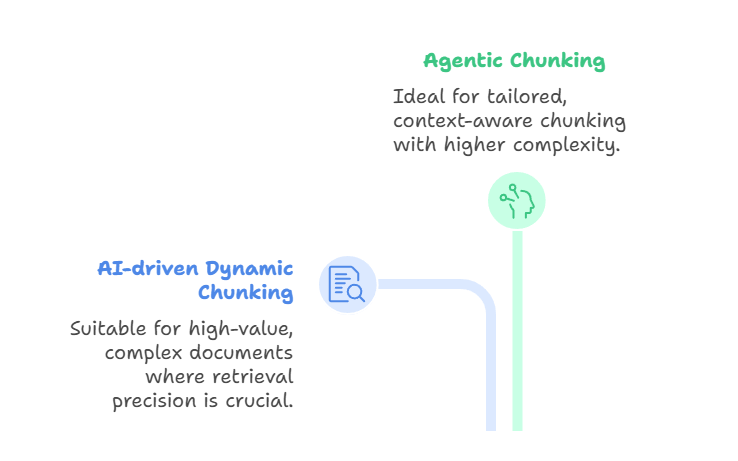
Chunking dynamique basé sur l'agent et l'IA
Les deux méthodes sont innovantes et performantes, mais elles traitent des problèmes différents. Le découpage dynamique basé sur l'IA se concentre sur la production de limites sémantiquement alignées lors de l'ingestion, tandis que le découpage agentique se concentre sur la sélection et la combinaison intelligentes de stratégies de découpage pour chaque document unique. Ils sont liés au «late chunking » d' , mentionné au début de l'article, qui prend en charge les modèles à contexte long en intégrant d'abord un document entier, puis en appliquant le chunking au niveau de l'intégration.
Ces approches fournissent des segments hautement adaptatifs et sémantiquement pertinents. Les compromis sont importants : Le découpage basé sur l'IA est coûteux et peut être plus lent, tandis que le découpage agentique ajoute une couche supplémentaire de complexité et d'infrastructure. Le découpage dynamique basé sur l'IA est particulièrement adapté aux scénarios dans lesquels le contenu doit être segmenté de manière significative à la volée, tandis que le découpage agentique est plus efficace lorsque les documents varient considérablement et nécessitent un raisonnement stratégique.
Une fois que j'ai sélectionné une stratégie de segmentation, l'étape suivante consiste à réfléchir aux détails de mise en œuvre. Des facteurs pratiques tels que la taille des blocs, la gestion des chevauchements et le comptage des jetons influencent directement les performances du système. Si elles sont trop grandes, les parties peuvent dépasser les limites du contexte ; si elles sont trop petites, elles perdent leur sens.
La compatibilité est un autre aspect important. Les différents modèles et solutions d'intégration ont des schémas de tokenisation et des fenêtres contextuelles uniques, je m'assure donc que mon processus de segmentation tient compte de ces différences.
En ce qui concerne l'infrastructure, la gestion de la mémoire et l'efficacité computationnelle sont des aspects qui ne peuvent être négligés ; le chevauchement augmente la redondance, et les méthodes récursives ou sémantiques peuvent ajouter une surcharge de traitement. Les étapes de post-traitement telles que l'expansion des blocs ou l'enrichissement des métadonnées peuvent contribuer à récupérer le contexte, mais elles introduisent également une certaine complexité.
Une fois ces bases établies, il est essentiel d'évaluer l'efficacité des stratégies de segmentation dans la pratique.
L'efficacité du chunking n'est pas seulement une question de théorie, c'est quelque chose qui doit être mesuré à l'aide d'indicateurs clairs.
Par exemple, Précision contextuelle mesure le nombre de fragments récupérés qui sont réellement pertinents pour la requête, tandis que le rappel contextuel mesure le nombre de fragments pertinents de la base de connaissances qui ont été récupérés avec succès.
Ensemble, ils déterminent si une stratégie de regroupement aide le chercheur à trouver les informations appropriées.
Le contexte de pertinence est étroitement lié à la pertinence contextuelle. pertinence contextuelle, qui se concentre sur la pertinence des extraits récupérés par rapport à l'intention de l'utilisateur, ce qui la rend particulièrement utile lors du réglage des paramètres de récupération tels que les valeurs top-K.
Autres mesures spécifiques aux blocs, telles que l' l'utilisation des segments, mesurent la quantité de contenu d'un chunk que le modèle a réellement utilisée pour générer sa réponse ; si l'utilisation est faible, le chunk est peut-être trop large ou trop bruité.
D'autre part, l'attribution des segments ( ) évalue si le système identifie correctement les segments qui ont contribué à la réponse finale. Ces évaluations au niveau des blocs permettent de confirmer que les blocs sont non seulement récupérés, mais également appliqués de manière significative.
L'optimisation joue également un rôle essentiel et implique souvent de trouver un équilibre entre rapidité et précision. Il est essentiel d'expérimenter différentes tailles de blocs, différents pourcentages de chevauchement et différents paramètres de récupération afin d'améliorer à la fois l'efficacité computationnelle et la richesse sémantique. De plus, les tests A/B sont essentiels car ils fournissent des informations concrètes, tandis que les ajustements itératifs garantissent que la stratégie s'améliore au fil du temps au lieu de stagner.
Bien que l'optimisation des performances puisse améliorer les systèmes à usage général, les applications spécifiques à un domaine présentent leurs propres défis.
Les différentes industries ont des exigences différentes en matière de stratégies de segmentation. Dans le domaine financier, les documents tels que les rapports annuels ou les déclarations sont denses et techniques. Il est donc impératif de choisir une stratégie de segmentation qui préserve les tableaux numériques, les en-têtes et les notes de bas de page. Les documents juridiques et techniques présentent des défis similaires : la précision et la structure sont indispensables, ce qui rend les approches hiérarchiques ou enrichies par le contexte particulièrement précieuses.
Les documents médicaux et multimodaux présentent des besoins émergents. Un dossier patient peut regrouper des notes cliniques, des résultats d'analyses et des données d'imagerie, tandis que les documents multimodaux peuvent intégrer du texte avec des graphiques ou des transcriptions audio. Ici, le regroupement spécifique à chaque modalité garantit que chaque type de données est segmenté de manière à préserver le sens tout en maintenant l'alignement entre les modalités.
Quel que soit le domaine, le respect d'un ensemble de bonnes pratiques rend les stratégies de segmentation plus fiables et plus faciles à maintenir.
Le choix de la stratégie de segmentation appropriée dépend de plusieurs facteurs : le type de contenu, la complexité de la requête, les ressources disponibles et la taille de la fenêtre contextuelle du modèle. Je m'appuie rarement sur une seule méthode pour tous les cas. Au contraire, j'adapte l'approche aux besoins du système.
L'optimisation itérative est essentielle à la réussite à long terme. L'efficacité du chunking doit être testée en continu, en validant les résultats à l'aide de requêtes réelles et en effectuant des ajustements en fonction des commentaires reçus. La validation croisée permet de s'assurer que les améliorations ne sont pas seulement des succès ponctuels, mais qu'elles se vérifient dans différents cas d'utilisation.
Enfin, je recommande de considérer le découpage en blocs comme un système évolutif. Une documentation adéquate, des tests réguliers et une maintenance continue contribuent à prévenir les dérives et à garantir la robustesse des pipelines à mesure que les données et les modèles évoluent.
Le chunking peut sembler être un détail du prétraitement, mais comme vous l'avez vu tout au long de ce guide, il influence fondamentalement les performances des systèmes de génération augmentée par la récupération. Des méthodes à taille fixe et basées sur des phrases aux stratégies avancées sémantiques, agentives et basées sur l'IA, chaque approche offre des compromis entre simplicité, précision, efficacité et adaptabilité.
Il n'existe pas de méthode unique qui convienne à tous les cas de figure. La stratégie de segmentation appropriée dépend du type de contenu, des capacités du modèle linguistique et des objectifs de l'application. En accordant une attention particulière à des principes tels que la cohérence sémantique, la préservation du contexte et l'efficacité informatique, il est possible de concevoir des segments qui améliorent la précision de la recherche, optimisent les performances et garantissent des résultats plus fiables.
À l'avenir, les stratégies de segmentation deviendront probablement encore plus dynamiques, adaptatives et sensibles aux modèles. À mesure que les modèles à contexte long évoluent et que les outils d'évaluation gagnent en maturité, je m'attends à ce que le découpage en morceaux passe d'une étape de prétraitement statique à un processus intelligent et sensible au contexte qui apprend continuellement à partir de l'utilisation.
Pour toute personne qui développe des systèmes RAG, la maîtrise du découpage en morceaux est essentielle pour créer des pipelines de récupération précis, efficaces et prêts pour l'avenir.
Pour continuer à vous informer, veuillez consulter les ressources suivantes :
Meilleurs cours DataCamp
Cours
Cours
Cours