
Curso
Retrieval Augmented Generation (RAG) con LangChain
3 h
13.7K
Cuando empecé a explorar los sistemas de generación aumentada por recuperación (RAG), rápidamente me di cuenta de que uno de los factores más ignorados, pero críticos, que influyen en su rendimiento es la fragmentación.
En esencia, el chunking es el proceso de dividir grandes cantidades de información, como documentos, transcripciones o manuales técnicos, en segmentos más pequeños y manejables. A continuación, los sistemas de IA pueden procesar, integrar y recuperar estos segmentos.
Al trabajar con modelos lingüísticos modernos y sus limitaciones contextuales, considero que comprender y aplicar estrategias de fragmentación eficaces es esencial para cualquiera que desarrolle canalizaciones RAG, sistemas de búsqueda semántica o aplicaciones de procesamiento de documentos.
En esta guía, te explicaré el concepto de fragmentación, te explicaré por qué es importante en las aplicaciones de IA, describiré su función en el proceso RAG y analizaré cómo las diferentes estrategias pueden afectar a la precisión de la recuperación. También abordaré consideraciones prácticas de implementación, métodos de evaluación, casos de uso específicos del dominio y mejores prácticas que pueden ayudarte a seleccionar el enfoque adecuado para tu proyecto.
Si eres nuevo en RAG y las aplicaciones de IA, te recomiendo que realices uno de nuestros cursos, como Retrieval Augmented Generation (RAG) con LangChain, Certificación en Fundamentos de IAo Estrategia de inteligencia artificial (IA).
La importancia de la fragmentación va mucho más allá de la simple organización de datos; determina fundamentalmente la forma en que los sistemas de IA comprenden y recuperan la información.
Los modelos lingüísticos grandes y los procesos RAG requieren fragmentación debido a sus limitaciones inherentes en las ventanas de contexto y las restricciones computacionales.
Cuando procesas documentos grandes sin fragmentarlos adecuadamente, el sistema suele perder relaciones contextuales importantes y tiene dificultades para identificar la información relevante durante la recuperación. La fragmentación eficaz mejora directamente la precisión de la recuperación al crear segmentos semánticamente coherentes que se alinean con los patrones de consulta y la intención del usuario.
Según mi experiencia, las estrategias de fragmentación bien implementadas mejoran significativamente las capacidades de búsqueda semántica, ya que mantienen el flujo lógico de la información y garantizan que cada fragmento contenga suficiente contexto para realizar integraciones significativas. Este enfoque permite que los modelos integrados capturen relaciones matizadas y facilita una comparación de similitudes más precisa durante la recuperación.
Por otro lado, las estrategias de fragmentación deficientes generan un efecto dominó negativo en todo el proceso de IA. Las divisiones arbitrarias pueden romper relaciones fundamentales entre conceptos, lo que da lugar a respuestas incompletas o engañosas. Cuando los fragmentos son demasiado grandes, los sistemas de recuperación tienen dificultades para identificar pasajes específicos relevantes, mientras que los fragmentos demasiado pequeños a menudo carecen del contexto suficiente para una comprensión precisa. Estos problemas acaban reduciendo la satisfacción de los usuarios y comprometiendo la fiabilidad del sistema.
El chunking ocupa una posición fundamental en el proceso RAG, ya que sirve de puente entre la ingesta de documentos sin procesar y la recuperación de conocimientos significativos. En el proceso RAG de extremo a extremo, la fragmentación suele producirse después del preprocesamiento del documento, pero antes de la generación de la incrustación. El proceso de fragmentación alimenta directamente el paso de incrustación, en el que cada fragmento se convierte en representaciones vectoriales que capturan el significado semántico.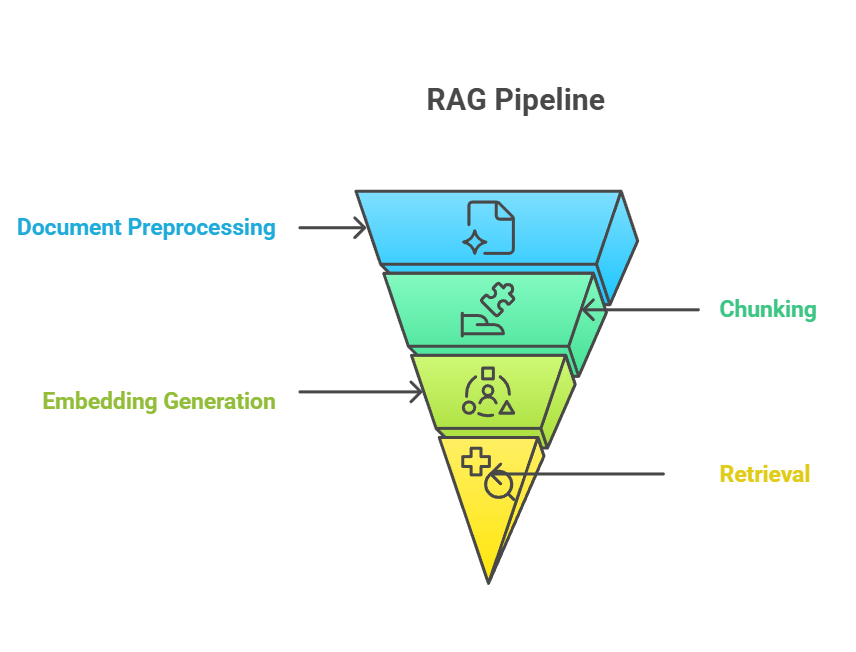
Tubería RAG
La relación entre la fragmentación, la integración y la recuperación forma un sistema estrechamente vinculado en el que la eficacia de cada componente depende del rendimiento de los demás.
Cuando creo fragmentos bien estructurados, los modelos de incrustación pueden generar representaciones vectoriales más ricas, lo que a su vez permite obtener resultados de búsqueda más precisos cuando un usuario realiza una consulta. Esta sinergia significa que las mejoras en la fragmentación a menudo se traducen en ganancias de rendimiento medibles en todo el proceso.
Dicho esto, algunos enfoques más recientes cuestionan este orden tradicional. Por ejemplo, el post-chunking incrusta primero documentos completos y solo los divide en fragmentos en el momento de la consulta, almacenando los resultados en caché para un acceso más rápido posteriormente. Este método evita el preprocesamiento de documentos que quizá nunca se consulten, al tiempo que permite la fragmentación específica para cada consulta, pero introduce latencia en el primer acceso y requiere infraestructura adicional.
Del mismo modo, la fragmentación tardía aplaza la segmentación detallada hasta la recuperación. En lugar de precalcular incrustaciones para muchos fragmentos pequeños, el sistema almacena representaciones más generales (por ejemplo, documentos completos o secciones) y las divide dinámicamente cuando llega una consulta. Esto permite conservar un contexto más amplio y reducir el procesamiento inicial, aunque introduce latencia en la primera consulta y requiere infraestructura adicional.
Independientemente del enfoque, las estrategias de fragmentación deben adaptarse a la ventana contextual del modelo lingüístico utilizado, es decir, la cantidad máxima de texto que un modelo puede procesar y considerar al mismo tiempo.
Ahora que ya tienes una idea de lo que es el chunking y dónde encaja en el proceso, es hora de examinar los principios básicos que guían las estrategias eficaces de chunking. Comprender estos fundamentos proporciona la base para aplicar el chunking en una amplia gama de aplicaciones de IA y RAG.
El chunking es necesario porque los modelos lingüísticos tienen una ventana de contexto limitada. El objetivo principal es crear fragmentos que tengan sentido por separado, pero que en conjunto mantengan la estructura y el propósito generales del documento, todo ello dentro de la ventana de contexto del modelo.
Sin embargo, la ventana de contexto no es lo único que hay que tener en cuenta. Cuando diseño estrategias de fragmentación, me centro en tres principios básicos:
Estos principios funcionan conjuntamente para que los fragmentos sean útiles para el modelo y eficientes para los procesos de recuperación. Con esta base, ahora puedo repasar las estrategias de fragmentación más comunes que se utilizan en la práctica.
El panorama de las estrategias de fragmentación ofrece diversos enfoques adaptados a diferentes tipos de contenido, aplicaciones y requisitos de rendimiento. En la imagen siguiente, puedes ver una descripción general de los principales métodos de fragmentación, que trataré con más detalle en las siguientes secciones.
Resumen de las estrategias de fragmentación
Esta visión general completa muestra la evolución desde los enfoques simples basados en reglas hasta las sofisticadas técnicas impulsadas por la inteligencia artificial, cada una de las cuales ofrece ventajas distintas para aplicaciones y requisitos de rendimiento específicos.
Echemos un vistazo más de cerca a las estrategias de fragmentación más utilizadas. Cada método tiene sus propias ventajas, limitaciones y situaciones en las que resulta más adecuado. Al comprender estas diferencias, puedo elegir el enfoque adecuado para un proyecto específico en lugar de recurrir a soluciones estándar para todos los casos. Comenzaremos con el enfoque más sencillo: la división en fragmentos de tamaño fijo.
El fragmentado de tamaño fijo es el método más sencillo. Divide el texto en fragmentos basándose en caracteres, palabras o tokens, sin tener en cuenta el significado ni la estructura.
La principal ventaja del fragmentado de tamaño fijo es la eficiencia computacional: es rápido, predecible y fácil de implementar. El inconveniente es que a menudo ignora la estructura semántica, lo que puede reducir la precisión de la recuperación. Normalmente utilizo este método cuando la simplicidad y la rapidez prevalecen sobre la precisión semántica, y cuando la estructura del documento no es importante. Para mejorar el rendimiento, a menudo añado solapamientos entre fragmentos para preservar el contexto a través de los límites.
Una forma de solucionar algunas de estas deficiencias es utilizar la fragmentación basada en frases, que respeta los límites del lenguaje natural, normalmente detectando signos de puntuación como puntos o signos de interrogación.
Este enfoque preserva la legibilidad y garantiza que cada fragmento sea autónomo. En comparación con el fragmentado de tamaño fijo, produce segmentos que son más fáciles de interpretar tanto para los seres humanos como para los modelos. Sin embargo, la longitud de las oraciones varía, por lo que el tamaño de los fragmentos puede ser desigual y es posible que no siempre reflejen relaciones semánticas más profundas.
Considero que la división en fragmentos basados en frases es más útil para aplicaciones que dependen del flujo del lenguaje natural, como la traducción automática, el análisis de opiniones o las tareas de resumen. Pero cuando los documentos tienen más estructura que simples oraciones, la fragmentación recursiva ofrece una alternativa flexible.
La fragmentación recursiva es una técnica más avanzada que los métodos anteriores. Aplica reglas de división de forma gradual hasta que cada fragmento se ajusta a un límite de tamaño definido. Por ejemplo, primero podría dividir por encabezados de sección, luego por párrafos y, por último, por oraciones. El proceso continúa hasta que cada pieza sea manejable y tenga el tamaño predefinido.
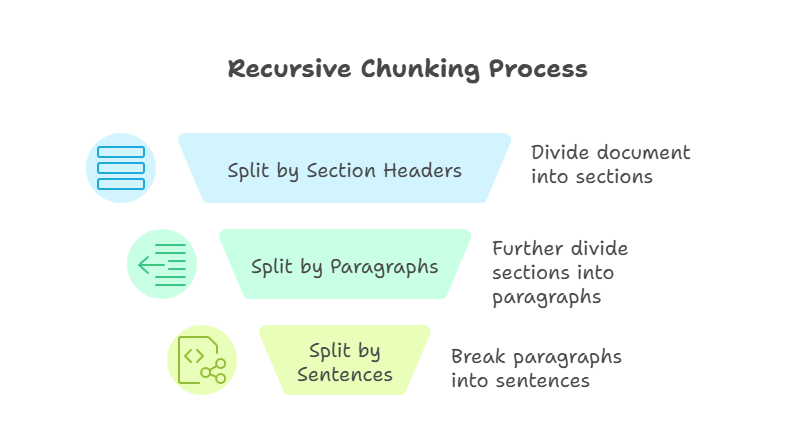
Fragmentación recursiva
La principal ventaja de este enfoque es la flexibilidad. Al trabajar de arriba hacia abajo, la fragmentación recursiva conserva la estructura del documento y garantiza la compatibilidad con las ventanas de contexto del modelo. Sin embargo, la fragmentación recursiva puede ser más compleja de implementar, y la calidad de los resultados depende de lo bien estructurado que esté el documento original.
A menudo recurro al fragmentado recursivo cuando trabajo con manuales técnicos u otros documentos que tienen jerarquías claras.
Mientras que los métodos recursivos se basan en la estructura, la fragmentación semántica cambia el enfoque hacia el significado, dividiendo el texto en función de los límites conceptuales. La fragmentación semántica es una técnica que tiene en cuenta el significado y utiliza incrustaciones o similitudes semánticas para dividir el texto cuando se producen cambios de tema. En lugar de límites arbitrarios, los fragmentos se definen por su significado.
Un enfoque consiste en dividir el texto en oraciones y medir la similitud semántica entre ellas (por ejemplo, similitud coseno en incrustaciones), marcando nuevos fragmentos cuando la coherencia disminuye. Las implementaciones más avanzadas utilizan métodos de agrupación o modelos supervisados de detección de límites, que captan mejor los cambios de tema en documentos complejos.
Fragmentación semántica
Este método mantiene la coherencia semántica, asegurando que cada fragmento cubra una sola idea o tema. Las técnicas pueden incluir la similitud de incrustación, la agrupación u otros cálculos de distancia semántica para detectar puntos de ruptura naturales.
La mayor ventaja es la precisión: la fragmentación semántica crea fragmentos que se ajustan estrechamente a la intención del usuario durante la recuperación. El principal inconveniente es el coste computacional, ya que requiere incrustar texto durante el preprocesamiento. Utilizo la fragmentación semántica cuando la precisión es más importante que la velocidad, como en los sistemas RAG específicos para los ámbitos jurídico o médico.
A diferencia del fragmentado semántico, que hace hincapié en la coherencia semántica, el fragmentado de ventana deslizante enfatiza la continuidad mediante la superposición de fragmentos, desplazando una ventana a lo largo del texto. Por ejemplo, si utilizas un tamaño de fragmento (ventana) de 500 tokens con un paso de 250, cada fragmento se superpone a la mitad con el anterior.
Esta superposición preserva el contexto a través de los límites de los fragmentos, lo que reduce el riesgo de perder información importante en los bordes. También mejora la precisión de la recuperación, ya que pueden aparecer múltiples fragmentos superpuestos en respuesta a una consulta. La contrapartida es la redundancia: la superposición aumenta los costes de almacenamiento y procesamiento. Las ventanas deslizantes son especialmente útiles para texto no estructurado, como registros de chat o transcripciones de podcasts.
Fragmentación por ventana deslizante
Cuando implemento esta estrategia, suelo utilizar un solapamiento del 20-50 % entre los fragmentos para preservar el contexto a través de los límites, especialmente en textos técnicos o conversacionales. Los tamaños de fragmentos de 200 a 400 tokens son los valores predeterminados habituales en marcos como LangChain, aunque se pueden ajustar en función de los límites del contexto del modelo y el tipo de documento. Recomiendo este enfoque para aplicaciones en las que la conservación del contexto es fundamental y la eficiencia del almacenamiento es menos importante.
Cuando la continuidad no es suficiente y hay que preservar la estructura del documento, entran en juego la fragmentación jerárquica y contextual.
La fragmentación jerárquica conserva la estructura completa de un documento, desde las secciones hasta las frases. En lugar de generar una lista plana de fragmentos, construye un árbol que refleja la jerarquía original. Cada fragmento tiene unarelación padre-hijo con los niveles superiores e inferiores. Por ejemplo, una sección contiene varios párrafos (padre → hijos), y cada párrafo puede contener varias oraciones.
Durante la recuperación, esta estructura permite una navegación flexible. Si una consulta coincide con un fragmento a nivel de frase, el sistema puede expandirse hacia arriba para proporcionar contexto adicional de su párrafo principal o incluso de toda la sección. Por el contrario, si una consulta amplia coincide con un fragmento a nivel de sección, el sistema puede profundizar en el párrafo o la frase secundaria más relevante. Esta recuperación multinivel mejora tanto la precisión como la recuperación, ya que el modelo puede adaptar el alcance del contenido devuelto.
Fragmentación jerárquica
La fragmentación contextual va un paso más allá al enriquecer los fragmentos con metadatos como encabezados, marcas de tiempo o referencias de origen. Esta información adicional proporciona señales importantes que ayudan a los sistemas de recuperación a desambiguar los resultados. Por ejemplo, dos documentos pueden contener frases casi idénticas, pero los títulos de sus secciones o las marcas de tiempo pueden determinar cuál de ellos es más relevante para una consulta. Los metadatos también facilitan el rastreo de las respuestas hasta su fuente, lo que resulta especialmente valioso en ámbitos regulados o sujetos a normas de cumplimiento.
Fragmentación contextual
La principal ventaja de la fragmentación jerárquica y contextual es la precisión y la flexibilidad. La contrapartida es una mayor complejidad tanto en el preprocesamiento como en la lógica de recuperación, ya que el sistema debe gestionar las relaciones entre los fragmentos en lugar de tratarlos como unidades independientes. Recomiendo estos enfoques para ámbitos como los contratos legales, los informes financieros o las especificaciones técnicas, en los que es esencial preservar la estructura y la trazabilidad.
No todos los documentos siguen una jerarquía estricta, por lo que la división en fragmentos basados en temas o modalidades específicas ofrece una forma más flexible de agrupar contenidos relacionados.
Fragmentación por temas Agrupa el texto por unidades temáticas utilizando algoritmos como la asignación latente de Dirichlet (LDA) para el modelado de temas o métodos de agrupación basados en la incrustación para identificar límites semánticos.
En lugar de tamaños fijos o marcadores estructurales, el objetivo es mantener todo el contenido relacionado con un tema en un solo lugar. Este enfoque funciona bien para contenidos extensos, como informes de investigación o artículos que abordan temas distintos. Dado que cada fragmento se centra en un único tema, los resultados de la búsqueda se ajustan más a la intención del usuario y es menos probable que incluyan material no relacionado.
La fragmentación específica por modalidad adapta las estrategias a los diferentes tipos de contenido, garantizando que la información se segmente de forma que respete la estructura de cada medio. Por ejemplo:
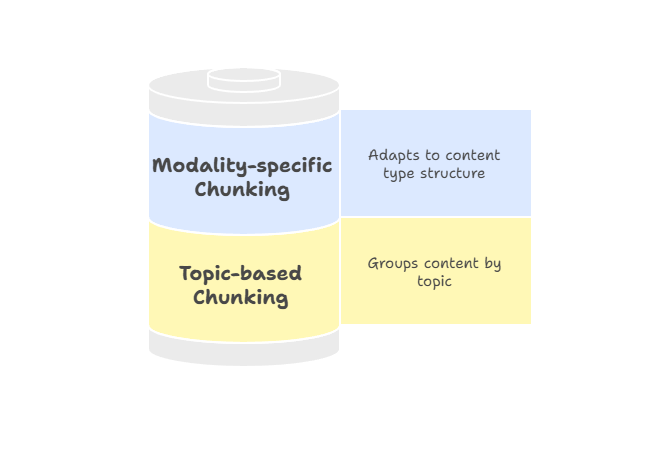
Fragmentación basada en temas y específica por modalidad
Los metadatos desempeñan un papel especialmente importante en la fragmentación específica de cada modalidad. Por ejemplo, adjuntar encabezados de columna a las filas de las tablas, vincular leyendas a regiones de imágenes o añadir etiquetas de hablantes y marcas de tiempo a las transcripciones ayuda a los sistemas de recuperación a localizar el fragmento adecuado e interpretarlo correctamente. Este enriquecimiento mejora tanto la precisión como la confianza de los usuarios, ya que los resultados se presentan acompañados de señales contextuales que explican su relevancia.
Recomiendo aplicar la fragmentación específica por modalidad cuando trabajes con procesos multimodales o documentos no tradicionales que no encajan perfectamente en estrategias basadas en texto. Garantiza que cada tipo de contenido se represente de forma que se maximice la calidad de la recuperación y la facilidad de uso.
Más allá de estos métodos basados en reglas y significados, enfoques de vanguardia como el fragmentado dinámico impulsado por IA y el fragmentado agencial amplían aún más los límites.
El fragmentado dinámico impulsado por IA utiliza un gran modelo lingüístico para determinar directamente los límites de los fragmentos, en lugar de basarse en reglas predefinidas. El LLM escanea el documento, identifica los puntos de ruptura naturales y ajusta el tamaño de los fragmentos de forma adaptativa.
Las secciones densas pueden dividirse en fragmentos más pequeños, mientras que las secciones más ligeras pueden agruparse. Esto da como resultado fragmentos semánticamente coherentes que capturan conceptos completos, lo que mejora la precisión de la recuperación. Este método es adecuado cuando se trabaja con documentos complejos y de gran valor, como contratos legales, manuales de cumplimiento normativo o trabajos de investigación, en los que la precisión en la recuperación es más importante que el rendimiento o el coste.
Por otro lado, la fragmentación agencial se basa en esta idea introduciendo un razonamiento a un nivel superior. En lugar de dejar que el LLM divida el texto, un agente de IA evalúa el documento y la intención del usuario y decide cómo dividirlo.
El agente puede elegir diferentes estrategias para diferentes secciones. Por ejemplo, desglosar un informe médico por historial del paciente, resultados de laboratorio y notas del médico, al tiempo que se aplica la segmentación semántica a las descripciones narrativas. También podría enriquecer ciertos fragmentos con metadatos como marcas de tiempo, códigos de diagnóstico o identificadores de médicos.
De esta manera, la fragmentación agencial actúa como una capa de coordinación: el agente selecciona o combina enfoques de fragmentación de forma dinámica, en lugar de aplicar un único método en todo el documento. El resultado es una fragmentación más personalizada y sensible al contexto, aunque a costa de una mayor complejidad y requisitos computacionales.
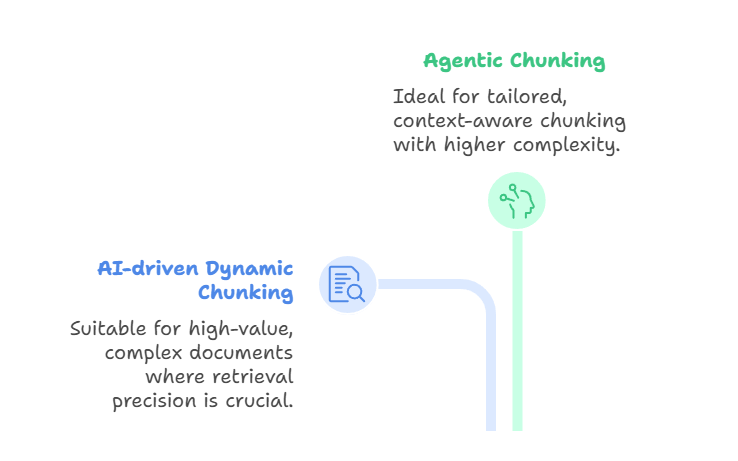
Fragmentación dinámica impulsada por agentes y IA
Ambos métodos son innovadores y potentes, pero abordan problemas diferentes. El fragmentado dinámico impulsado por IA se centra en producir límites alineados semánticamente durante la ingestión, mientras que el fragmentado agencial se centra en seleccionar y combinar de forma inteligente estrategias de fragmentado para cada documento único. Están relacionados conel «late chunking» (fragmentación tardía) de , mencionado al principio del artículo, que admite modelos de contexto largo mediante la incrustación de un documento completo primero y la aplicación de la fragmentación a nivel de incrustación después.
Estos enfoques proporcionan fragmentos altamente adaptables y con conciencia semántica. Las ventajas e inconvenientes son importantes: El chunking impulsado por IA es caro y puede ser más lento, mientras que el chunking agencial añade otra capa de complejidad e infraestructura. El fragmentado dinámico impulsado por IA es más adecuado para situaciones en las que el contenido debe segmentarse de forma significativa sobre la marcha, mientras que el fragmentado agencial destaca cuando los documentos varían mucho y requieren un razonamiento a nivel estratégico.
Una vez que hayas elegido una estrategia de fragmentación, el siguiente paso es pensar en los detalles de implementación. Factores prácticos como el tamaño de los fragmentos, la gestión de solapamientos y el recuento de tokens influyen directamente en el rendimiento del sistema. Si son demasiado grandes, los fragmentos pueden exceder los límites del contexto; si son demasiado pequeños, pierden significado.
La compatibilidad es otra cuestión clave. Los diferentes modelos y soluciones de incrustación tienen esquemas de tokenización y ventanas de contexto únicos, por lo que me aseguro de que tu proceso de fragmentación tenga en cuenta estas diferencias.
En cuanto a la infraestructura, no se pueden pasar por alto la gestión de la memoria y la eficiencia computacional; la superposición aumenta la redundancia, y los métodos recursivos o semánticos pueden añadir una sobrecarga de procesamiento. Los pasos de posprocesamiento, como la expansión de fragmentos o el enriquecimiento de metadatos, pueden ayudar a recuperar el contexto, pero también añaden complejidad.
Una vez sentadas estas bases, es importante medir la eficacia real de las estrategias de fragmentación en la práctica.
La eficacia del chunking no es solo teoría, es algo que debe medirse con métricas claras.
Por ejemplo, Precisión del contexto mide cuántos de los fragmentos recuperados son realmente relevantes para la consulta, mientras que la la recuperación contextual mide cuántos fragmentos relevantes de la base de conocimientos se recuperaron correctamente.
Juntos, revelan si una estrategia de fragmentación ayuda al recuperador a encontrar la información correcta.
Estrechamente relacionado con esto está la relevancia del contexto, que se centra en la adecuación de los fragmentos recuperados a la intención del usuario, lo que resulta especialmente útil a la hora de ajustar la configuración de la recuperación, como los valores top-K.
Otras métricas específicas de los fragmentos, como la utilización de fragmentos, miden cuánto contenido de un fragmento ha utilizado realmente el modelo para generar su respuesta; si la utilización es baja, es posible que el fragmento sea demasiado amplio o ruidoso.
Por otro lado, la atribución de fragmentos evalúa si el sistema identifica correctamente qué fragmentos contribuyeron a la respuesta final. Estas evaluaciones a nivel de fragmentos ayudan a confirmar si los fragmentos no solo se recuperan, sino que también se aplican de manera significativa.
La optimización también desempeña un papel fundamental y, a menudo, implica encontrar el equilibrio entre velocidad y precisión. Es fundamental experimentar con tamaños de fragmentos, porcentajes de superposición y parámetros de recuperación para mejorar tanto la eficiencia computacional como la riqueza semántica. Además, las pruebas A/B son necesarias, ya que proporcionan información concreta, mientras que los ajustes iterativos garantizan que la estrategia mejore con el tiempo en lugar de estancarse.
Si bien el ajuste del rendimiento puede mejorar los sistemas de uso general, las aplicaciones específicas de cada dominio presentan sus propios retos únicos.
Las diferentes industrias plantean diferentes exigencias en cuanto a las estrategias de fragmentación. En finanzas, los documentos como los informes anuales o las presentaciones son densos y técnicos, por lo que es obligatorio elegir una estrategia de fragmentación que conserve las tablas numéricas, los encabezados y las notas al pie. Los documentos jurídicos y técnicos plantean retos similares: la precisión y la estructura son innegociables, lo que hace que los enfoques jerárquicos o enriquecidos por el contexto sean especialmente valiosos.
Los documentos médicos y multimodales introducen nuevas necesidades. Un historial clínico puede combinar notas clínicas, resultados de laboratorio y datos de imágenes, mientras que los documentos multimodales pueden integrar texto con gráficos o transcripciones de audio. Aquí, la fragmentación específica por modalidad garantiza que cada tipo de datos se segmente de forma que se conserve el significado y se mantenga la alineación entre las modalidades.
Independientemente del ámbito, seguir una serie de prácticas recomendadas hace que las estrategias de fragmentación sean más fiables y fáciles de mantener.
La selección de la estrategia de fragmentación adecuada depende de varios factores: el tipo de contenido, la complejidad de la consulta, los recursos disponibles y el tamaño de la ventana de contexto del modelo. Rara vez utilizo un único método para todos los casos, sino que adapto el enfoque a las necesidades del sistema.
La optimización iterativa es fundamental para el éxito a largo plazo. La eficacia del chunking debe comprobarse continuamente, validando los resultados con consultas reales y realizando ajustes en función de los comentarios recibidos. La validación cruzada ayuda a garantizar que las mejoras no sean solo éxitos puntuales, sino que se mantengan en diferentes casos de uso.
Por último, recomiendo considerar el chunking como un sistema en evolución. Una buena documentación, pruebas periódicas y un mantenimiento continuo ayudan a evitar desviaciones y garantizan que los procesos sigan siendo sólidos a medida que cambian tanto los datos como los modelos.
El chunking puede parecer un detalle del preprocesamiento, pero, como has podido ver a lo largo de esta guía, determina fundamentalmente el rendimiento de los sistemas de generación aumentada por recuperación. Desde métodos basados en frases y tamaños fijos hasta estrategias avanzadas semánticas, agentivas e impulsadas por la inteligencia artificial, cada enfoque ofrece ventajas e inconvenientes en cuanto a simplicidad, precisión, eficiencia y adaptabilidad.
No hay un método único que funcione para todos los casos. La estrategia de fragmentación adecuada depende del tipo de contenido, las capacidades del modelo lingüístico y los objetivos de la aplicación. Prestando atención a principios como la coherencia semántica, la preservación contextual y la eficiencia computacional, puedes diseñar fragmentos que mejoren la precisión de la recuperación, optimicen el rendimiento y garanticen resultados más fiables.
De cara al futuro, es probable que las estrategias de fragmentación se vuelvan aún más dinámicas, adaptables y conscientes de los modelos. A medida que los modelos de contexto largo evolucionen y las herramientas de evaluación maduren, espero que el chunking pase de ser un paso de preprocesamiento estático a un proceso inteligente y sensible al contexto que aprenda continuamente del uso.
Para cualquiera que construya con sistemas RAG, dominar el chunking es esencial para crear canales de recuperación que sean precisos, eficientes y estén preparados para el futuro.
Para seguir aprendiendo, asegúrate de consultar los siguientes recursos:
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Javier Canales Luna
10 min
blog
Austin Chia
blog
Abid Ali Awan
10 min
blog
Natasha Al-Khatib
14 min
blog
Vinod Chugani
14 min
Tutorial
Ryan Ong

