
Kurs
Retrieval Augmented Generation (RAG) mit LangChain
3 Std.
13.7K
Als ich anfing, mich mit RAG-Systemen (Retrieval-Augmented Generation) zu beschäftigen, wurde mir schnell klar, dass einer der am meisten übersehenen, aber entscheidenden Faktoren, die ihre Leistung beeinflussen, das Chunking ist.
Im Grunde geht es beim Chunking darum, große Informationsmengen, wie Dokumente, Transkripte oder technische Handbücher, in kleinere, überschaubarere Teile aufzuteilen. Diese Teile können dann von KI-Systemen verarbeitet, eingebettet und abgerufen werden.
Da ich mit modernen Sprachmodellen und ihren kontextuellen Einschränkungen arbeite, finde ich, dass das Verstehen und Anwenden von effektiven Chunking-Strategien für jeden wichtig ist, der RAG-Pipelines, semantische Suchsysteme oder Anwendungen zur Dokumentenverarbeitung entwickelt.
In diesem Leitfaden zeige ich dir das Konzept des Chunkings, erkläre, warum es in KI-Anwendungen wichtig ist, beschreibe seine Rolle in der RAG-Pipeline und diskutiere, wie sich verschiedene Strategien auf die Genauigkeit der Suche auswirken können. Ich werde auch praktische Überlegungen zur Umsetzung, Bewertungsmethoden, domänenspezifische Anwendungsfälle und bewährte Verfahren ansprechen, die dir bei der Auswahl des richtigen Ansatzes für dein Projekt helfen können.
Wenn du noch keine Erfahrung mit RAG- und KI-Anwendungen hast, empfehle ich dir, einen unserer Kurse zu besuchen, zum Beispiel Retrieval Augmented Generation (RAG) mit LangChainoder „AI Fundamentals Certification“oder Strategie für künstliche Intelligenz (KI).
Die Bedeutung von Chunking geht weit über die einfache Datenorganisation hinaus; es beeinflusst grundlegend, wie KI-Systeme Infos verstehen und abrufen.
Große Sprachmodelle und RAG-Pipelines brauchen Chunking, weil sie bei Kontextfenstern und Rechenanforderungen eingeschränkt sind.
Wenn ich große Dokumente ohne ordentliche Aufteilung bearbeite, verliert das System oft wichtige Zusammenhänge und hat Probleme, beim Abrufen relevante Infos zu finden. Effektives Chunking macht die Suchgenauigkeit besser, indem es sinnvolle Segmente bildet, die zu den Suchmustern und der Absicht der Nutzer passen.
Ich hab die Erfahrung gemacht, dass gut umgesetzte Chunking-Strategien die semantischen Suchfunktionen echt verbessern, weil sie den logischen Informationsfluss beibehalten und gleichzeitig sicherstellen, dass jeder Chunk genug Kontext für sinnvolle Einbettungen hat. Mit diesem Ansatz können eingebettete Modelle feine Unterschiede in Beziehungen erfassen und beim Abruf genauere Ähnlichkeitsabgleiche machen.
Andererseits haben schlechte Chunking-Strategien negative Auswirkungen auf die ganze KI-Pipeline. Willkürliche Trennungen können wichtige Zusammenhänge zwischen Begriffen zerstören, was zu unvollständigen oder irreführenden Antworten führt. Wenn die Teile zu groß sind, haben Abrufsysteme Probleme, bestimmte relevante Passagen zu finden, während zu kleine Teile oft nicht genug Kontext haben, um richtig verstanden zu werden. Diese Probleme führen letztendlich zu weniger zufriedenen Nutzern und beeinträchtigen die Zuverlässigkeit des Systems.
Chunking ist echt wichtig in der RAG-Pipeline und verbindet die Rohdaten aus Dokumenten mit dem Abruf von sinnvollem Wissen. In der End-to-End-RAG-Pipeline passiert das Chunking normalerweise nach der Dokumentvorverarbeitung, aber vor der Embedding-Generierung. Der Chunking-Prozess geht direkt in den Einbettungsschritt über, wo jeder Chunk in Vektordarstellungen umgewandelt wird, die die semantische Bedeutung erfassen.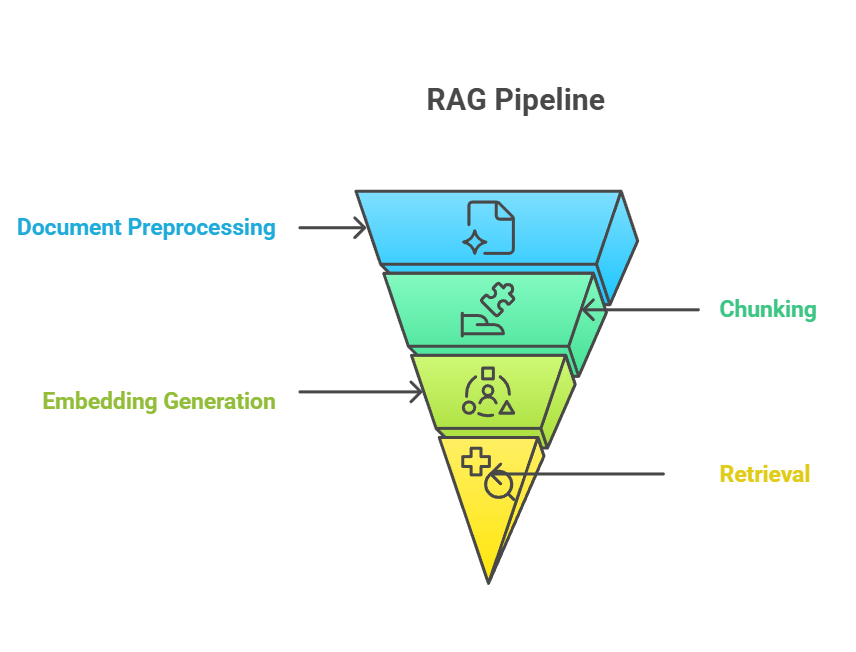
RAG-Pipeline
Die Beziehung zwischen Chunking, Einbettung und Abruf bildet ein eng gekoppeltes System, in dem die Effektivität jeder Komponente von der Leistung der anderen abhängt.
Wenn ich gut strukturierte Blöcke erstelle, können Einbettungsmodelle reichhaltigere Vektordarstellungen erzeugen, die wiederum genauere Suchergebnisse liefern, wenn jemand eine Anfrage stellt. Diese Synergie bedeutet, dass Verbesserungen beim Chunking oft zu messbaren Leistungssteigerungen in der gesamten Pipeline führen.
Allerdings stellen einige neuere Ansätze diese traditionelle Ordnung infrage. Zum Beispiel werden beim Post-Chunking zuerst ganze Dokumente eingebettet und erst bei der Abfrage in Chunks aufgeteilt, wobei die Ergebnisse zwischengespeichert werden, um später schneller draufzugreifen. Diese Methode vermeidet die Vorverarbeitung von Dokumenten, die vielleicht nie abgefragt werden, und ermöglicht gleichzeitig eine abfragespezifische Aufteilung in Blöcke. Allerdings führt sie zu einer Verzögerung beim ersten Zugriff und braucht zusätzliche Infrastruktur.
Genauso wird die späte Chunking wird die feine Segmentierung bis zum Abruf aufgeschoben. Anstatt Einbettungen für viele kleine Teile im Voraus zu berechnen, speichert das System gröbere Darstellungen (z. B. ganze Dokumente oder Abschnitte) und teilt sie dynamisch auf, wenn eine Anfrage eingeht. Dadurch bleibt der breitere Kontext erhalten, während der Vorab-Verarbeitungsaufwand reduziert wird, allerdings kommt es zu einer Latenz bei der ersten Abfrage und es ist zusätzliche Infrastruktur nötig.
Egal wie man es macht, Chunking-Strategien müssen sich an das Kontextfenster des verwendeten Sprachmodells anpassen – also die maximale Textmenge, die ein Modell auf einmal verarbeiten und berücksichtigen kann.
Jetzt, wo du weißt, was Chunking ist und wo es in der Pipeline reinkommt, ist es Zeit, die Kernprinzipien zu checken, die effektive Chunking-Strategien leiten. Das Verständnis dieser Grundlagen bildet die Basis für die Anwendung von Chunking in einer Vielzahl von KI- und RAG-Anwendungen.
Chunking ist wichtig, weil Sprachmodelle nur ein begrenztes Kontextfenster haben. Das Hauptziel ist, Teile zu machen, die für sich genommen Sinn ergeben, aber trotzdem die Gesamtstruktur und den Sinn des Dokuments zusammenhalten, und das alles innerhalb des Kontextfensters des Modells.
Aber das Kontextfenster ist nicht das Einzige, was man beachten muss. Wenn ich Strategien zum Chunking entwickle, achte ich auf drei wichtige Punkte:
Diese Prinzipien sorgen dafür, dass Chunks sowohl für das Modell nützlich als auch für Abruf-Pipelines effizient sind. Mit dieser Grundlage kann ich jetzt die gängigsten Chunking-Strategien durchgehen, die in der Praxis verwendet werden.
Die Welt der Chunking-Strategien hat viele verschiedene Ansätze, die auf unterschiedliche Inhaltstypen, Anwendungen und Leistungsanforderungen zugeschnitten sind. Auf dem Bild unten siehst du eine Übersicht über die wichtigsten Chunking-Methoden, auf die ich in den nächsten Abschnitten genauer eingehen werde.
Überblick über Chunking-Strategien
Dieser umfassende Überblick zeigt, wie sich einfache regelbasierte Ansätze zu ausgeklügelten KI-gesteuerten Techniken entwickelt haben, die alle ihre eigenen Vorteile für bestimmte Anwendungen und Leistungsanforderungen haben.
Schauen wir uns mal die gängigsten Chunking-Strategien genauer an. Jede Methode hat ihre eigenen Stärken, Einschränkungen und passt am besten zu bestimmten Situationen. Wenn ich diese Unterschiede verstehe, kann ich für ein bestimmtes Projekt den richtigen Ansatz wählen, anstatt einfach auf Standardlösungen zurückzugreifen. Wir fangen mit dem einfachsten Ansatz an: Chunking mit fester Größe.
Chunking mit fester Größe ist die einfachste Methode. Es teilt den Text in Teile auf, basierend auf Zeichen, Wörtern oder Tokens – ohne Rücksicht auf Bedeutung oder Struktur.
Der Hauptvorteil von Chunking mit fester Größe ist, dass es rechneteffizient ist – es ist schnell, vorhersehbar und einfach umzusetzen. Der Nachteil ist, dass dabei oft die semantische Struktur nicht berücksichtigt wird, was die Genauigkeit der Suche beeinträchtigen kann. Ich nutze diese Methode meistens, wenn Einfachheit und Schnelligkeit wichtiger sind als semantische Genauigkeit und wenn die Struktur des Dokuments nicht so wichtig ist. Um die Leistung zu verbessern, füge ich oft Überlappungen zwischen den Blöcken hinzu, damit der Kontext über die Grenzen hinweg erhalten bleibt.
Eine Möglichkeit, einige dieser Probleme zu lösen, ist die Verwendung von satzbasiertem Chunking, das die natürlichen Sprachgrenzen berücksichtigt, indem es normalerweise Satzzeichen wie Punkte oder Fragezeichen erkennt.
Dieser Ansatz sorgt dafür, dass alles gut lesbar bleibt und jeder Abschnitt für sich allein steht. Im Vergleich zum Chunking mit fester Größe erzeugt es Segmente, die für Menschen und Modelle leichter zu verstehen sind. Allerdings sind die Sätze unterschiedlich lang, sodass die Chunk-Größen ungleichmäßig sein können und sie nicht immer tiefere semantische Beziehungen erfassen.
Ich finde, dass das Chunking auf Satzbasis am nützlichsten für Anwendungen ist, die auf natürlichem Sprachfluss basieren, wie zum Beispiel maschinelle Übersetzung, Sentimentanalyse oder Zusammenfassungsaufgaben. Aber wenn Dokumente mehr Struktur haben als nur einfache Sätze, ist rekursives Chunking eine flexible Alternative.
Rekursives Chunking ist eine fortgeschrittenere Technik als die vorherigen Methoden. Es wendet die Teilungsregeln Schritt für Schritt an, bis jeder Teil innerhalb einer festgelegten Größenbeschränkung liegt. Ich könnte zum Beispiel erst nach Abschnittsüberschriften, dann nach Absätzen und schließlich nach Sätzen aufteilen. Der Prozess geht weiter, bis jedes Teil handhabbar ist und die vorgegebene Größe hat.
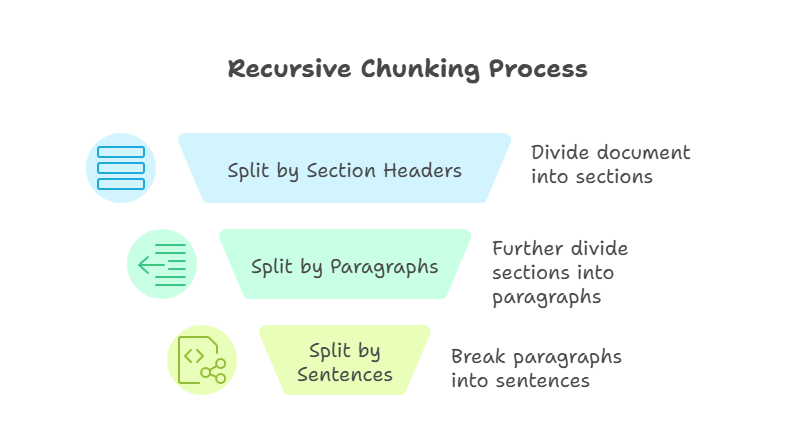
Rekursives Chunking
Der größte Vorteil von diesem Ansatz ist die Flexibilität. Durch die Top-Down-Arbeitsweise behält das rekursive Chunking die Dokumentstruktur bei und sorgt gleichzeitig für Kompatibilität mit den Kontextfenstern des Modells. Allerdings kann rekursives Chunking schwieriger umzusetzen sein, und die Qualität der Ergebnisse hängt davon ab, wie gut das Quelldokument aufgebaut ist.
Ich nutze oft rekursives Chunking, wenn ich mit technischen Handbüchern oder anderen Dokumenten arbeite, die klare Hierarchien haben.
Während rekursive Methoden auf Struktur setzen, geht es beim semantischen Chunking mehr um die Bedeutung, indem der Text nach konzeptionellen Grenzen aufgeteilt wird. Semantisches Chunking ist eine Technik, die auf Bedeutung achtet und Embeddings oder semantische Ähnlichkeit nutzt, um Text an Stellen zu teilen, wo Themenwechsel passieren. Anstatt willkürlicher Grenzen werden Blöcke durch ihre Bedeutung definiert.
Ein Ansatz besteht darin, den Text in Sätze zu zerlegen und die semantische Ähnlichkeit zwischen ihnen zu messen (z. B. Kosinusähnlichkeit bei Einbettungen), wobei neue Abschnitte markiert werden, wenn die Kohärenz nachlässt. Fortgeschrittenere Implementierungen nutzen Clustering-Methoden oder überwachte Modelle zur Grenzerkennung, die Themenwechsel in komplexen Dokumenten besser erfassen.
Semantisches Chunking
Diese Methode sorgt dafür, dass alles zusammenhängt, indem jeder Abschnitt nur eine Idee oder ein Thema abdeckt. Techniken können die Einbettung von Ähnlichkeiten, Clustering oder andere Berechnungen der semantischen Distanz umfassen, um natürliche Bruchstellen zu erkennen.
Der größte Vorteil ist die Präzision – beim semantischen Chunking werden Chunks erstellt, die beim Abruf genau auf die Absicht des Benutzers abgestimmt sind. Der größte Nachteil sind die Rechenkosten, weil man den Text schon während der Vorverarbeitung einbetten muss. Ich nutze semantisches Chunking, wenn Genauigkeit wichtiger ist als Geschwindigkeit, wie zum Beispiel in RAG-Systemen für bestimmte Bereiche wie Recht oder Medizin.
Im Gegensatz zum semantischen Chunking, bei dem es um die Bedeutung geht, geht's beim Sliding-Window-Chunking darum, dass die Teile zusammenhängen, indem man sie überlappt und ein Fenster über den Text schiebt. Wenn ich zum Beispiel eine Chunk-Größe (Fenster) von 500 Tokens mit einem Stride von 250 nehme, überlappt sich jeder Chunk zur Hälfte mit dem vorherigen.
Diese Überlappung sorgt dafür, dass der Kontext über die Grenzen der Blöcke hinweg erhalten bleibt, und verringert das Risiko, dass wichtige Infos an den Rändern verloren gehen. Außerdem wird die Genauigkeit der Suche verbessert, weil mehrere überlappende Teile als Antwort auf eine Anfrage angezeigt werden können. Der Nachteil ist Redundanz – Überschneidungen erhöhen die Kosten für Speicherplatz und Verarbeitung. Schiebefenster sind besonders praktisch für unstrukturierte Texte wie Chat-Protokolle oder Podcast-Transkripte.
Schiebefenster-Chunking
Wenn ich diese Strategie anwende, lasse ich die Textabschnitte normalerweise zu 20–50 % überlappen, damit der Kontext über die Grenzen hinweg erhalten bleibt, vor allem bei technischen Texten oder Gesprächen. Chunk-Größen von 200 bis 400 Tokens sind in Frameworks wie LangChain die üblichen Standardeinstellungen, können aber je nach Modellkontextbeschränkungen und Dokumenttyp angepasst werden. Ich empfehle diesen Ansatz für Anwendungen, bei denen die Beibehaltung des Kontexts wichtig ist und die Speichereffizienz weniger wichtig ist.
Wenn Kontinuität nicht reicht und die Dokumentstruktur erhalten bleiben muss, kommen hierarchisches und kontextuelles Chunking ins Spiel.
Beim hierarchischen Chunking- us bleibt die ganze Struktur eines Dokuments erhalten, von den Abschnitten bis hin zu den Sätzen. Anstatt eine flache Liste von Blöcken zu erstellen, baut es einen Baum auf, der die ursprüngliche Hierarchie zeigt. Jeder Chunk hat eine„ “-Beziehung zwischen Eltern und Kindern mit den Ebenen darüber und darunter. Zum Beispiel hat ein Abschnitt mehrere Absätze (übergeordnet → untergeordnet), und jeder Absatz kann mehrere Sätze haben.
Beim Abrufen macht diese Struktur die Navigation echt flexibel. Wenn eine Suchanfrage zu einem Satzteil passt, kann das System nach oben erweitern, um mehr Kontext aus dem übergeordneten Absatz oder sogar dem ganzen Abschnitt zu liefern. Wenn eine allgemeine Suchanfrage zu einem Abschnitt passt, kann das System den relevantesten Absatz oder Satz herausgreifen. Diese mehrstufige Suche macht die Ergebnisse genauer und umfassender, weil das Modell den Umfang der angezeigten Inhalte anpassen kann.
Hierarchisches Chunking
Kontextuelles Chunking geht noch einen Schritt weiter, indem es Chunks mit Metadaten wie Überschriften, Zeitstempeln oder Quellenangaben anreichert. Diese zusätzlichen Infos liefern wichtige Hinweise, die Suchsystemen dabei helfen, Ergebnisse besser zu unterscheiden. Zum Beispiel können zwei Dokumente fast identische Sätze haben, aber ihre Abschnittsüberschriften oder Zeitstempel können entscheiden, welches für eine Suchanfrage relevanter ist. Metadaten machen es auch einfacher, Antworten zu ihrer Quelle zurückzuverfolgen, was besonders in regulierten oder compliance-orientierten Bereichen super nützlich ist.
Kontextuelles Chunking
Der Hauptvorteil von hierarchischem und kontextbezogenem Chunking ist, dass es genau und flexibel ist. Der Nachteil ist, dass es sowohl bei der Vorverarbeitung als auch bei der Suchlogik komplizierter wird, weil das System die Beziehungen zwischen den Blöcken verwalten muss, anstatt sie als unabhängige Einheiten zu behandeln. Ich empfehle diese Ansätze für Bereiche wie rechtliche Verträge, Finanzberichte oder technische Spezifikationen, wo es super wichtig ist, die Struktur und Rückverfolgbarkeit zu behalten.
Nicht alle Dokumente haben eine strenge Hierarchie, deshalb ist es manchmal flexibler, ähnliche Inhalte nach Themen oder Modalitäten zu gruppieren.
Themenbasiertes Chunking gruppiert Text nach Themenbereichen mit Algorithmen wie Latent Dirichlet Allocation (LDA) für die Themenmodellierung oder eingebettungsbasierten Clustering-Methoden, um semantische Grenzen zu erkennen.
Anstatt feste Größen oder Strukturmarkierungen zu verwenden, geht's darum, alle Inhalte zu einem Thema an einem Ort zu sammeln. Dieser Ansatz eignet sich gut für längere Texte wie Forschungsberichte oder Artikel, die zwischen verschiedenen Themen wechseln. Da sich jeder Abschnitt auf ein einziges Thema konzentriert, passen die Suchergebnisse besser zu dem, was der Nutzer sucht, und es ist weniger wahrscheinlich, dass sie irrelevante Inhalte enthalten.
Modalitätsspezifisches Chunking passt Strategien an verschiedene Inhaltstypen an und sorgt dafür, dass Informationen so segmentiert werden, dass die Struktur jedes Mediums berücksichtigt wird. Zum Beispiel:
Themenbasiertes und modalitätsspezifisches Chunking
Metadaten sind echt wichtig beim modalitätsspezifischen Chunking. Zum Beispiel hilft es den Suchsystemen, den richtigen Abschnitt zu finden und richtig zu verstehen, wenn man Spaltenüberschriften zu Zeilen einer Tabelle hinzufügt, Bildunterschriften mit Bildbereichen verknüpft oder Sprecherbezeichnungen und Zeitstempel zu Transkripten hinzufügt. Diese Verbesserung macht die Ergebnisse genauer und stärkt das Vertrauen der Nutzer, weil die Ergebnisse mit Infos zum Kontext kommen, die ihre Relevanz erklären.
Ich empfehle, modalitätsspezifisches Chunking zu nutzen, wenn du mit multimodalen Pipelines oder nicht-traditionellen Dokumenten arbeitest, die nicht so einfach in textbasierte Strategien passen. Es sorgt dafür, dass jeder Inhaltstyp so dargestellt wird, dass die Suchqualität und Benutzerfreundlichkeit optimal sind.
Über diese regel- und bedeutungsorientierten Methoden hinaus gehen innovative Ansätze wie KI-gesteuertes dynamisches Chunking und agentenbasiertes Chunking noch einen Schritt weiter.
Das KI-gesteuerte dynamische Chunking- us nutzt ein großes Sprachmodell, um Chunk-Grenzen direkt zu bestimmen, anstatt sich auf vordefinierte Regeln zu verlassen. Der LLM checkt das Dokument, findet natürliche Unterbrechungsstellen und passt die Größe der Teile automatisch an.
Dichte Abschnitte können in kleinere Teile aufgeteilt werden, während weniger dichte Abschnitte zusammengefasst werden können. Das führt zu sinnvollen Blöcken, die ganze Konzepte erfassen und die Genauigkeit beim Abrufen verbessern. Diese Methode ist super, wenn du mit hochwertigen, komplexen Dokumenten arbeitest – wie zum Beispiel Verträgen, Compliance-Handbüchern oder Forschungsarbeiten –, bei denen es mehr auf die Genauigkeit beim Abrufen ankommt als auf Durchsatz oder Kosten.
Andererseits bautdas agenzielle Chunking- , auf dieser Idee auf, indem es ein höheres Maß an logischem Denken einführt. Anstatt den Text einfach vom LLM aufteilen zu lassen, schaut sich ein KI-Agent das Dokument und die Absicht des Nutzers an und entscheidet, wie es aufgeteilt wird.
Der Agent kann für verschiedene Bereiche unterschiedliche Strategien wählen. Zum Beispiel kann man einen medizinischen Bericht nach Anamnese, Laborergebnissen und Arztnotizen aufschlüsseln und dabei semantische Segmentierung auf narrative Beschreibungen anwenden. Es könnte auch bestimmte Teile mit Metadaten wie Zeitstempeln, Diagnosecodes oder Identifikationsnummern von Ärzten anreichern.
So fungiert das agentische Chunking als eine Art Koordinationsschicht: Der Agent wählt oder kombiniert Chunking-Ansätze dynamisch, anstatt eine einzige Methode auf das ganze Dokument anzuwenden. Das Ergebnis ist eine passendere und kontextbewusstere Aufteilung, aber das geht auf Kosten von mehr Komplexität und höheren Rechenanforderungen.
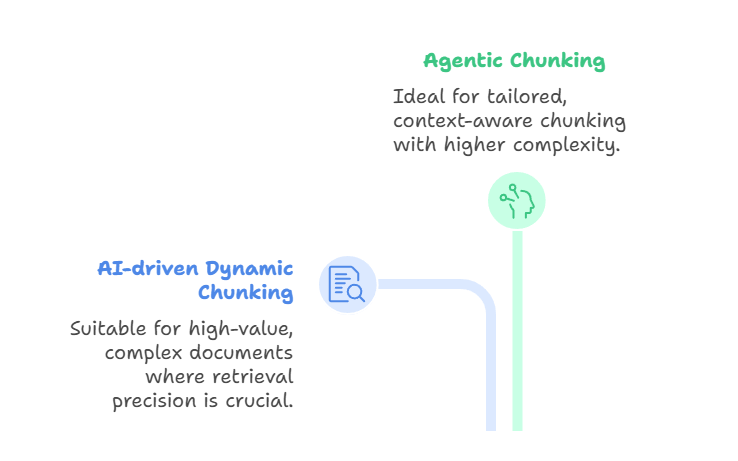
Agentisches und KI-gesteuertes dynamisches Chunking
Beide Methoden sind topaktuell und leistungsstark, aber sie lösen unterschiedliche Probleme. Beim KI-gesteuerten dynamischen Chunking geht's darum, beim Einlesen semantisch passende Grenzen zu finden, während es beim agentenbasierten Chunking darum geht, für jedes einzelne Dokument die besten Chunking-Strategien clever auszuwählen und zu kombinieren. Das hängt mit dem am Anfang des Artikels erwähnten „ -Late-Chunking” zusammen, das Modelle mit langem Kontext unterstützt, indem es zuerst das ganze Dokument einbettet und dann das Chunking auf der Einbettungsebene anwendet.
Diese Ansätze liefern super anpassungsfähige, semantisch bewusste Chunks. Die Kompromisse sind echt groß: KI-gesteuertes Chunking ist teuer und kann langsamer sein, während agentenbasiertes Chunking eine weitere Ebene der Komplexität und Infrastruktur hinzufügt. KI-gesteuertes dynamisches Chunking passt am besten, wenn Inhalte spontan sinnvoll aufgeteilt werden müssen, während agentenbasiertes Chunking super ist, wenn Dokumente sehr unterschiedlich sind und strategisches Denken brauchen.
Sobald ich mich für eine Chunking-Strategie entschieden habe, geht's weiter mit den Details der Umsetzung. Praktische Sachen wie die Größe der Datenblöcke, das Überlappungsmanagement und das Zählen von Tokens beeinflussen direkt, wie gut das System läuft. Zu groß, und die Teile können die Kontextgrenzen überschreiten; zu klein, und sie verlieren ihre Bedeutung.
Kompatibilität ist auch ein wichtiges Thema. Verschiedene Modelle und Einbettungslösungen haben ihre eigenen Tokenisierungsschemata und Kontextfenster, deshalb achte ich darauf, dass mein Chunking-Prozess diese Unterschiede berücksichtigt.
Bei der Infrastruktur darf man Speicherverwaltung und Recheneffizienz nicht vergessen; Überschneidungen machen die Sache unnötig kompliziert, und rekursive oder semantische Methoden können den Verarbeitungsaufwand erhöhen. Nachbearbeitungsschritte wie Chunk-Erweiterung oder Metadatenanreicherung können helfen, den Kontext wiederherzustellen, machen die Sache aber auch komplizierter.
Nachdem das alles klar ist, ist es wichtig zu checken, wie gut Chunking-Strategien in der Praxis wirklich funktionieren.
Die Effektivität von Chunking ist nicht nur Theorie – sie muss mit klaren Kennzahlen gemessen werden.
Zum Beispiel Kontextgenauigkeit misst wie viele der gefundenen Teile wirklich für die Anfrage wichtig sind, während die Kontextwiederauffindung misst, wie viele relevante Chunks aus der Wissensdatenbank erfolgreich gefunden wurden.
Zusammen zeigen sie, ob eine Chunking-Strategie dem Suchenden hilft, die richtigen Infos zu finden.
Eng damit verbunden ist die Kontextrelevanz, die sich darauf konzentriert, wie gut die gefundenen Teile mit dem, was der Nutzer eigentlich will, übereinstimmen. Das ist besonders nützlich, wenn man die Such-Einstellungen wie die Top-K-Werte anpasst.
Andere chunk-spezifische Metriken, wie zum Beispiel Chunk-Nutzung, wie viel vom Inhalt eines Chunks das Modell tatsächlich für seine Antwort benutzt hat; wenn die Nutzung niedrig ist, könnte der Chunk zu breit oder zu verrauscht sein.
Andererseits checktdie Chunk-Attributions , ob das System richtig erkennt, welche Chunks zur endgültigen Antwort beigetragen haben. Diese Bewertungen auf Chunk-Ebene helfen dabei, zu bestätigen, ob Chunks nicht nur abgerufen, sondern auch sinnvoll angewendet werden.
Optimierung ist auch super wichtig und heißt oft, dass man Geschwindigkeit und Genauigkeit unter einen Hut bringen muss. Es ist echt wichtig, mit Chunk-Größen, Überlappungsprozentsätzen und Abrufparametern rumzuexperimentieren, um sowohl die Recheneffizienz als auch die semantische Vielfalt zu verbessern. Außerdem sind A/B-Tests wichtig, weil sie echtes Feedback geben, und durch immer wiederholte Anpassungen wird die Strategie mit der Zeit besser, statt auf der Stelle zu treten.
Während man mit Performance-Tuning allgemeine Systeme verbessern kann, bringen domänenspezifische Anwendungen ihre eigenen Herausforderungen mit sich.
Verschiedene Branchen haben unterschiedliche Anforderungen an Chunking-Strategien. Im Finanzbereich sind Dokumente wie Jahresberichte oder Einreichungen ziemlich kompliziert und technisch, deshalb muss man eine Strategie wählen, die numerische Tabellen, Überschriften und Fußnoten beibehält. Rechtliche und technische Dokumente haben ähnliche Herausforderungen – Genauigkeit und Struktur sind super wichtig, was hierarchische oder kontextbezogene Ansätze besonders nützlich macht.
Medizinische und multimodale Dokumente bringen neue Anforderungen mit sich. Eine Patientenakte kann klinische Notizen, Laborergebnisse und Bilddaten zusammenfassen, während multimodale Dokumente Text mit Diagrammen oder Audio-Transkripten verbinden können. Hier sorgt das modalitätsspezifische Chunking dafür, dass jeder Datentyp so segmentiert wird, dass die Bedeutung erhalten bleibt und gleichzeitig die Übereinstimmung zwischen den Modalitäten gewährleistet ist.
Egal in welchem Bereich, wenn man sich an bewährte Vorgehensweisen hält, werden Chunking-Strategien zuverlässiger und einfacher zu pflegen.
Die richtige Chunking-Strategie hängt von ein paar Sachen ab: vom Inhaltstyp, wie kompliziert die Anfrage ist, den verfügbaren Ressourcen und der Größe des Kontextfensters des Modells. Ich verlasse mich selten auf eine einzige Methode für alle Fälle – stattdessen passe ich den Ansatz an die Anforderungen des Systems an.
Iterative Optimierung ist echt wichtig für langfristigen Erfolg. Die Effektivität des Chunkings muss ständig getestet werden, indem die Ergebnisse mit echten Abfragen überprüft und anhand des Feedbacks angepasst werden. Kreuzvalidierung hilft dabei, sicherzustellen, dass Verbesserungen nicht nur einmalige Erfolge sind, sondern in verschiedenen Anwendungsfällen funktionieren.
Zum Schluss empfehle ich, Chunking als ein sich entwickelndes System zu sehen. Gute Dokumentation, regelmäßige Tests und ständige Wartung helfen dabei, Abweichungen zu vermeiden und sicherzustellen, dass Pipelines robust bleiben, auch wenn sich Daten und Modelle ändern.
Chunking mag wie ein Detail der Vorverarbeitung klingen, aber wie du in diesem Leitfaden gesehen hast, beeinflusst es echt, wie Systeme mit abrufgestützter Generierung funktionieren. Von Methoden mit fester Größe und satzbasierten Methoden bis hin zu fortgeschrittenen semantischen, agentenbasierten und KI-gesteuerten Strategien bietet jeder Ansatz Kompromisse zwischen Einfachheit, Genauigkeit, Effizienz und Anpassungsfähigkeit.
Es gibt keine Methode, die für alle Fälle passt. Die richtige Chunking-Strategie hängt vom Inhaltstyp, den Möglichkeiten des Sprachmodells und den Zielen der Anwendung ab. Wenn du auf Sachen wie semantische Kohärenz, Beibehaltung des Kontexts und Recheneffizienz achtest, kannst du Chunks entwerfen, die die Genauigkeit der Suche verbessern, die Leistung optimieren und zuverlässigere Ergebnisse liefern.
In Zukunft werden Chunking-Strategien wahrscheinlich noch dynamischer, anpassungsfähiger und modellbewusster werden. Da sich Langzeitkontextmodelle weiterentwickeln und die Bewertungswerkzeuge immer besser werden, denke ich, dass Chunking sich von einem statischen Vorverarbeitungsschritt zu einem intelligenten, kontextsensitiven Prozess entwickeln wird, der ständig aus der Nutzung lernt.
Für alle, die mit RAG-Systemen arbeiten, ist es super wichtig, das Chunking zu beherrschen, um Abruf-Pipelines zu erstellen, die genau, effizient und zukunftsfähig sind.
Um weiterzulernen, schau dir unbedingt die folgenden Ressourcen an:
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Vinod Chugani
14 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Allan Ouko
