Kursus
Pengantar Python
4 Hr
6.9M
Algoritma fuzzy string matching berusaha menentukan tingkat kedekatan antara dua string yang berbeda. Ini dihitung menggunakan metrik jarak yang dikenal sebagai “edit distance.” Edit distance menentukan seberapa dekat dua string dengan mencari jumlah minimum “edit” yang diperlukan untuk mentransformasikan satu string menjadi string lainnya.
Jika edit distance menghitung jumlah operasi edit untuk memberi tahu kita berapa banyak operasi yang memisahkan satu string dari string lainnya, maka edit adalah operasi yang dilakukan pada sebuah string untuk mengubahnya menjadi string lain.
Ada empat jenis edit utama:
| Operasi Edit | Deskripsi | Contoh |
|---|---|---|
| Sisip (Insert) | Menambahkan satu huruf | "Londn" -> "London" |
| Hapus (Delete) | Menghapus satu huruf | "Londoon" -> "London" |
| Tukar (Switch) | Menukar dua huruf yang berdekatan | "Lnodon" -> "London" |
| Ganti (Replace) | Mengganti satu huruf dengan huruf lain | "Londin" -> "London" |
Keempat operasi edit ini memungkinkan kita memodifikasi string apa pun.
Mengombinasikan operasi edit memungkinkan Anda menemukan daftar kemungkinan string yang berjarak N edit, di mana N adalah jumlah operasi edit. Misalnya, edit distance antara “London” dan “Londin” adalah satu karena mengganti “i” dengan “o” menghasilkan kecocokan persis.
Lalu bagaimana tepatnya edit distance dihitung?
Ada berbagai variasi cara menghitung edit distance. Misalnya, ada Levenshtein distance, Hamming distance, Jaro distance, dan lainnya.
Dalam tutorial ini, kita hanya fokus pada Levenshtein distance.
Ini adalah metrik yang dinamai Vladimir Levenshtein, yang pada tahun 1965 awalnya mempertimbangkannya untuk mengukur perbedaan antara dua urutan kata. Kita dapat menggunakannya untuk menemukan jumlah minimum edit yang perlu Anda lakukan untuk mengubah satu urutan kata menjadi urutan lainnya.
Berikut perhitungannya secara formal:
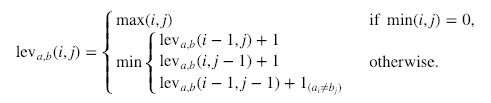
Di mana 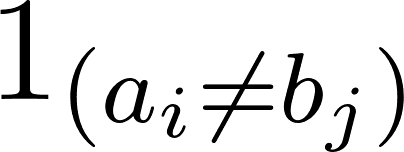 bernilai 0 ketika a=b dan 1 jika tidak.
bernilai 0 ketika a=b dan 1 jika tidak.
Penting untuk dicatat bahwa baris pada nilai minimum di atas masing-masing berkaitan dengan penghapusan, penyisipan, dan substitusi secara berurutan.
Kita juga dapat menghitung rasio kemiripan Levenshtein berdasarkan Levenshtein distance. Ini dapat dilakukan menggunakan rumus berikut:
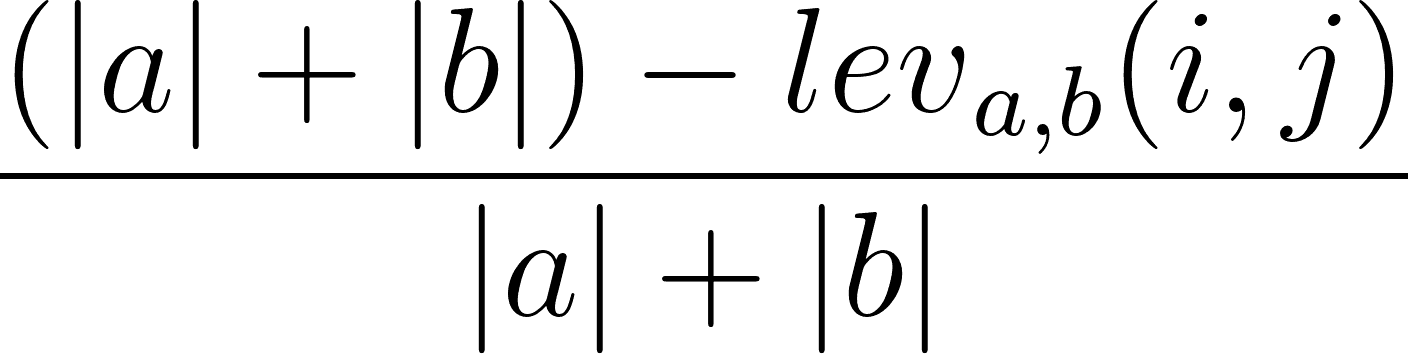
di mana |a| dan |b| adalah panjang urutan a dan urutan b, masing-masing.
Salah satu paket paling populer untuk fuzzy string matching di Python secara historis adalah FuzzyWuzzy. Namun, untuk menyelesaikan masalah lisensi dan memperbarui basis kode, proyek ini diganti nama pada 2021 menjadi TheFuzz. Pustaka ini tetap menjadi andalan bagi pemula karena kesederhanaannya dan akan kita gunakan dalam tutorial ini.
Awalnya dikembangkan oleh SeatGeek untuk membedakan apakah dua daftar tiket dengan nama serupa merujuk pada acara yang sama. Seperti pendahulunya, TheFuzz menggunakan Levenshtein edit distance untuk menghitung tingkat kedekatan antara dua string.
Pro Tip: Untuk Produksi, Gunakan RapidFuzz. Walau TheFuzz sangat baik untuk belajar dan dataset kecil, pustaka ini bisa lambat untuk pemrosesan data skala besar. Industri sebagian besar telah beralih ke pustaka yang lebih baru bernama RapidFuzz.
fuzz.ratio), sehingga Anda dapat dengan mudah beralih nanti.Untuk panduan ini, kita akan tetap menggunakan TheFuzz karena sudah pra-instal di banyak lingkungan dan sangat cocok untuk memahami konsep inti.
Pertama, kita harus memasang paket TheFuzz. Anda dapat melakukannya dengan pip menggunakan perintah berikut:
!pip install thefuzzCatatan: Pustaka ini sudah pra-instal di buku kerja DataLab.
Sekarang, mari lihat beberapa hal yang dapat kita lakukan dengan thefuzz.
Ikuti bersama kodenya di buku kerja DataLab.
Kita dapat menentukan rasio sederhana antara dua string menggunakan metode ratio() pada objek fuzz. Ini hanya menghitung edit distance berdasarkan urutan kedua string masukan difflib.ratio() – lihat dokumentasi difflib untuk mempelajari lebih lanjut.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""Dalam kode tersebut, kita menggunakan dua variasi nama saya untuk membandingkan skor kemiripan, yang hasilnya 86.
Mari kita bandingkan dengan partial ratio.
Untuk memeriksa partial ratio, yang perlu kita lakukan pada kode di atas adalah memanggil partial_ratio() pada objek fuzz alih-alih ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Kita melihat penurunan. Apa yang terjadi?
partial_ratio() berupaya menemukan seberapa mirip sebagian dua string. Dua string dianggap mirip sebagian jika memiliki sebagian kata dalam urutan yang sama.
partial_ratio() menghitung kemiripan dengan mengambil string terpendek, yang dalam skenario ini disimpan dalam variabel name, lalu membandingkannya dengan sub-string dengan panjang sama dalam string yang lebih panjang, yang disimpan dalam full_name.
Karena urutan berpengaruh pada partial ratio, skor kita turun dalam kasus ini. Jadi, untuk mendapatkan kecocokan 100%, Anda harus memindahkan bagian "K D" (menandakan nama tengah saya) ke akhir string. Misalnya:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""Lalu bagaimana jika kita ingin pencocok string fuzzy kita mengabaikan urutan?
Maka Anda mungkin ingin menggunakan “token sort ratio.”
Kita ingin mengabaikan urutan kata dalam string tetapi tetap menentukan seberapa mirip keduanya – token sort membantu Anda melakukan hal itu. Token sort tidak peduli urutan kemunculan kata. Ia mengakomodasi string yang mirip meski tidak dalam urutan yang sama seperti dijelaskan di atas.
Dengan demikian, kita seharusnya mendapatkan skor 100% menggunakan token sort ratio pada contoh terakhir:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""… dan seperti yang diharapkan, memang demikian.
Mari kembali ke variabel name dan full_name yang asli. Menurut Anda apa yang akan terjadi jika kita menggunakan token sort sekarang?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""Skornya turun.
Ini karena token sort hanya mengabaikan urutan. Jika ada kata yang tidak serupa di dalam string, hal itu akan menurunkan rasio kemiripan, seperti yang sudah kita lihat.
Tetapi ada solusi lain.
Metode token_set_ratio() sangat mirip dengan token_sort_ratio(), kecuali ia menghapus token yang sama sebelum menghitung seberapa mirip string-string tersebut: ini sangat membantu ketika panjang string berbeda jauh.
Karena variabel name dan full_name sama-sama memiliki “Kurtis Pykes” di dalamnya, kita bisa berharap kemiripan token set ratio menjadi 100%.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""Modul process memungkinkan pengguna mengekstrak teks dari suatu koleksi menggunakan fuzzy string matching. Memanggil metode extract() pada modul process akan mengembalikan string-string beserta skor kemiripan dalam sebuah vektor. Contohnya:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Kita dapat mengontrol panjang vektor yang dikembalikan oleh metode extract() dengan menetapkan parameter limit ke panjang yang diinginkan.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""Pada kasus ini, extract() mengembalikan tiga string yang paling dekat kecocokannya berdasarkan scorer yang kita tentukan.
Pada tabel di bawah, Anda dapat melihat perbandingan singkat berbagai teknik yang tersedia di TheFuzz:
| Teknik | Deskripsi | Contoh Kode |
|---|---|---|
| Simple Ratio | Menghitung kemiripan dengan mempertimbangkan urutan string masukan. | fuzz.ratio(name, full_name) |
| Partial Ratio | Menemukan kemiripan parsial dengan membandingkan string terpendek dengan sub-string. | fuzz.partial_ratio(name, full_name) |
| Token Sort Ratio | Mengabaikan urutan kata dalam string. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Token Set Ratio | Menghapus token yang sama sebelum menghitung kemiripan. | fuzz.token_set_ratio(name, full_name) |
Pada bagian ini, kita akan melihat cara melakukan fuzzy string matching pada dataframe pandas.
Misalkan Anda memiliki beberapa data yang diekspor ke dalam dataframe pandas, dan Anda ingin menggabungkannya dengan data yang sudah Anda miliki.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Ada masalah besar.
Data yang ada memiliki ejaan negara yang benar, tetapi data hasil ekspor tidak. Jika kita mencoba menggabungkan kedua dataframe pada kolom country, pandas tidak akan mengenali kata yang salah eja sebagai sama dengan kata yang dieja dengan benar. Jadi, hasil yang dikembalikan dari fungsi merge tidak akan sesuai harapan.
Berikut yang akan terjadi jika kita mencobanya:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Ini menggagalkan tujuan utama menggabungkan kedua dataframe tersebut.
Namun, kita dapat mengatasi masalah ini dengan fuzzy string matching.
Mari lihat seperti apa kodenya:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""Dalam kode ini, kita mengganti nilai yang salah eja pada kolom country di data ekspor menggunakan fungsi lambda yang rapi bersama metode process.extractOne(). Perhatikan, kita menggunakan indeks 0 pada hasil extractOne() untuk mengembalikan hanya string yang mirip alih-alih daftar yang berisi string dan nilai kemiripannya.
Berikutnya, kita menggabungkan dataframe pada kolom country menggunakan left join. Hasilnya adalah satu dataframe yang memuat negara dengan ejaan benar (termasuk perserikatan politik United Kingdom).
Meskipun solusi di atas cocok untuk tutorial ini dan dataset kecil, berhati-hatilah saat menerapkannya pada "Big Data".
Saat Anda menggunakan .apply() dengan fuzzy matching, komputer harus membandingkan setiap baris di dataframe A dengan setiap baris di dataframe B (Produk Kartesius).
Untuk dataset yang lebih besar dari beberapa ribu baris, pertimbangkan menggunakan RapidFuzz (yang menggunakan C++ untuk kecepatan) atau Splink (yang menggunakan "blocking" untuk mengurangi perbandingan).
Jika Anda butuh ringkasan cepat dari teknik-teknik di atas, Anda dapat menemukannya pada tabel berikut:
| Langkah | Deskripsi | Potongan Kode |
|---|---|---|
| Buat DataFrame | Definisikan data dengan kemungkinan salah eja. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Coba Merge dengan Error | Merge awal gagal karena string tidak cocok. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Perbaiki Salah Eja | Gunakan fuzzy matching untuk memperbaiki nama negara yang salah eja. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Merge Berhasil | Gabungkan dataframe setelah memperbaiki salah eja dengan fuzzy string matching. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
Dalam tutorial ini, Anda telah mempelajari:
Contoh-contoh yang disajikan di sini mungkin sederhana, tetapi cukup untuk mengilustrasikan cara menangani berbagai kasus yang menurut komputer adalah string tidak cocok. Ada banyak penerapan fuzzy matching di bidang seperti pemeriksa ejaan dan bioinformatika, di mana logika fuzzy digunakan untuk mencocokkan sekuens DNA.
Kursus Python
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
