Cursus
Introductie tot Python
4 Hr
6.9M
Het fuzzy string matching-algoritme probeert te bepalen hoe dicht twee verschillende strings bij elkaar liggen. Dit gebeurt met een afstandsmaat die de “edit distance” (bewerkingsafstand) wordt genoemd. De bewerkingsafstand bepaalt hoe dicht twee strings bij elkaar liggen door het minimumaantal “bewerkingen” te vinden dat nodig is om de ene string in de andere te veranderen.
Als de bewerkingsafstand het aantal bewerkingen telt om aan te geven hoeveel stappen de ene string van de andere verwijderd is, dan is een bewerking een operatie op een string om die in een andere string te transformeren.
Er zijn vier hoofdtypen bewerkingen:
| Bewerkingsactie | Beschrijving | Voorbeeld |
|---|---|---|
| Invoegen | Voeg een letter toe | "Londn" -> "London" |
| Verwijderen | Haal een letter weg | "Londoon" -> "London" |
| Wisselen | Verwissel twee aangrenzende letters | "Lnodon" -> "London" |
| Vervangen | Verander één letter in een andere | "Londin" -> "London" |
Met deze vier bewerkingen kun je elke string aanpassen.
Door bewerkingen te combineren, kun je de lijst ontdekken van mogelijke strings die N bewerkingen verwijderd zijn, waarbij N het aantal bewerkingen is. Zo is de bewerkingsafstand tussen “London” en “Londin” één, omdat het vervangen van de “i” door een “o” tot een exacte match leidt.
Maar hoe wordt die bewerkingsafstand nu precies berekend?
Er zijn verschillende manieren om de bewerkingsafstand te berekenen. Zo zijn er de Levenshtein-afstand, Hamming-afstand, Jaro-afstand en meer.
In deze tutorial richten we ons alleen op de Levenshtein-afstand.
Het is een maatstaf, genoemd naar Vladimir Levenshtein, die deze in 1965 introduceerde om het verschil tussen twee reeksen woorden te meten. We kunnen hem gebruiken om het minimumaantal bewerkingen te vinden dat nodig is om de ene woordreeks in de andere te veranderen.
Hier is de formele berekening:
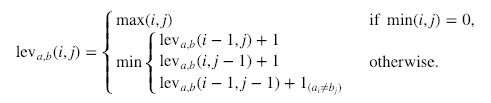
Waarbij 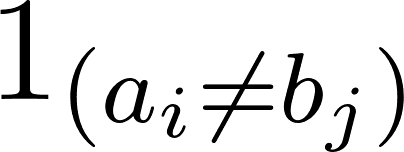 gelijk is aan 0 wanneer a=b en anders 1.
gelijk is aan 0 wanneer a=b en anders 1.
Belangrijk om te noteren is dat de rijen in het minimum hierboven respectievelijk overeenkomen met een verwijdering, een invoeging en een substitutie.
Je kunt ook de Levenshtein-similariteitsratio berekenen op basis van de Levenshtein-afstand. Dat kan met de volgende formule:
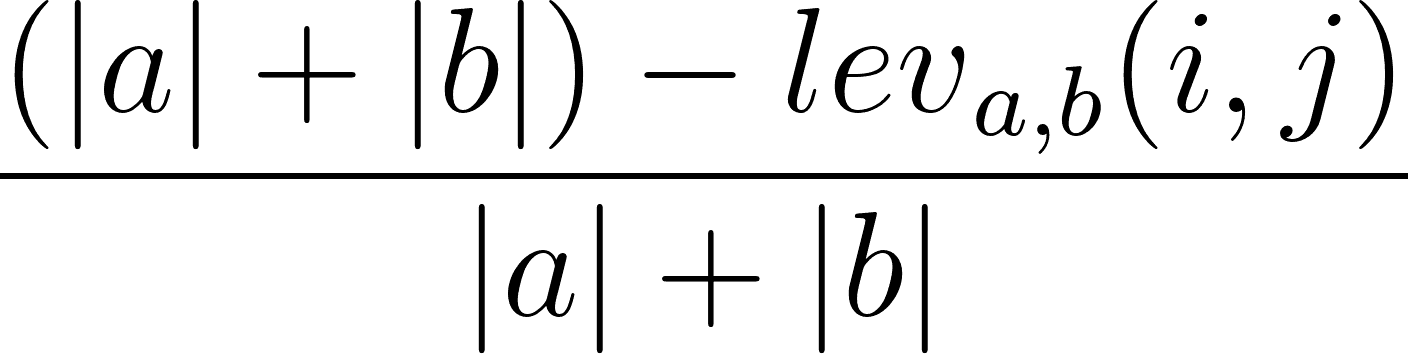
waar |a| en |b| de lengtes zijn van respectievelijk de a- en b-reeks.
Een van de populairste pakketten voor fuzzy string matching in Python was historisch gezien FuzzyWuzzy. Om licentieproblemen op te lossen en de codebase te updaten, werd het project in 2021 hernoemd naar TheFuzz. Het is dankzij de eenvoud nog steeds een veelgebruikte bibliotheek voor beginners en is de bibliotheek die we in deze tutorial gebruiken.
Het werd oorspronkelijk ontwikkeld door SeatGeek om te bepalen of twee ticketvermeldingen met vergelijkbare namen voor hetzelfde evenement waren. Net als zijn voorganger gebruikt TheFuzz de Levenshtein-bewerkingsafstand om te berekenen hoe dicht twee strings bij elkaar liggen.
Pro Tip: Gebruik RapidFuzz in productie. Hoewel TheFuzz uitstekend is om te leren en voor kleinere datasets, kan het traag zijn bij grootschalige gegevensverwerking. In de praktijk is men grotendeels overgestapt op een nieuwere bibliotheek genaamd RapidFuzz.
fuzz.ratio), zodat je later eenvoudig kunt overstappen.Voor deze gids blijven we bij TheFuzz, omdat het in veel omgevingen vooraf is geïnstalleerd en perfect is om de kernconcepten te begrijpen.
Allereerst moeten we het pakket TheFuzz installeren. Dat kan met pip via het volgende commando:
!pip install thefuzzLet op: Deze bibliotheek is vooraf geïnstalleerd in het DataLab-werkboek.
Laten we nu kijken wat we allemaal met thefuzz kunnen doen.
Volg mee met de code in dit DataLab-werkboek.
We kunnen de eenvoudige ratio tussen twee strings bepalen met de methode ratio() op het fuzz-object. Dit berekent simpelweg de bewerkingsafstand op basis van de volgorde van beide invoerstrings difflib.ratio() – zie de difflib-documentatie voor meer info.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""In de code gebruikten we twee varianten van mijn naam om de similariteitsscore te vergelijken, die 86 was.
Laten we dit vergelijken met de partial ratio.
Om de partial ratio te checken, hoeven we in de code hierboven alleen partial_ratio() aan te roepen op ons fuzz-object in plaats van ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""We zien een daling. Wat gebeurt hier?
Nou, partial_ratio() probeert te bepalen hoe gedeeltelijk vergelijkbaar twee strings zijn. Twee strings zijn gedeeltelijk vergelijkbaar als ze enkele woorden in dezelfde volgorde gemeen hebben.
partial_ratio() berekent de similariteit door de kortste string te nemen, die in dit scenario is opgeslagen in de variabele name, en deze te vergelijken met de substrings van dezelfde lengte in de langere string, die in full_name is opgeslagen.
Omdat volgorde ertoe doet bij partial ratio, daalde onze score in dit geval. Om 100% similariteit te krijgen, zou je het deel "K D" (mijn tweede naam) naar het einde van de string moeten verplaatsen. Bijvoorbeeld:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""Wat als we willen dat onze fuzzy string matcher de volgorde negeert?
Dan kun je de “token sort ratio” gebruiken.
We willen de volgorde van woorden in de strings negeren, maar nog steeds bepalen hoe vergelijkbaar ze zijn – token sort helpt je precies daarbij. Token sort kan het niet schelen in welke volgorde woorden voorkomen. Het houdt rekening met vergelijkbare strings die niet in dezelfde volgorde staan, zoals hierboven beschreven.
We zouden dus een score van 100% moeten krijgen met token sort ratio in het laatste voorbeeld:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""… en zoals verwacht, kregen we dat ook.
Laten we teruggaan naar de oorspronkelijke variabelen name en full_name. Wat denk je dat er gebeurt als we nu token sort gebruiken?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""De score daalt.
Dit komt doordat token sort alleen de volgorde negeert. Als er woorden in de strings staan die niet overeenkomen, beïnvloedt dat de similariteitsratio negatief, zoals we hierboven zagen.
Maar er is een workaround.
De methode token_set_ratio() lijkt sterk op token_sort_ratio(), behalve dat deze eerst gemeenschappelijke tokens verwijdert voordat de similariteit wordt berekend: dit is erg handig als de strings aanzienlijk in lengte verschillen.
Aangezien de variabelen name en full_name allebei “Kurtis Pykes” bevatten, kunnen we verwachten dat de token set ratio-similariteit 100% is.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""De process-module stelt je in staat tekst uit een collectie te extraheren met fuzzy string matching. De methode extract() op de process-module retourneert de strings met een similariteitsscore in een vector. Bijvoorbeeld:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""We kunnen de lengte van de vector die door extract() wordt geretourneerd, beheren door de parameter limit in te stellen op de gewenste lengte.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""In dit geval retourneert extract() de drie dichtstbijzijnde overeenkomende strings op basis van de door ons gekozen scorer.
In de tabel hieronder zie je een snelle vergelijking van de verschillende technieken die in TheFuzz beschikbaar zijn:
| Techniek | Beschrijving | Codevoorbeeld |
|---|---|---|
| Eenvoudige ratio | Bereken similariteit met inachtneming van de volgorde van invoerstrings. | fuzz.ratio(name, full_name) |
| Partial ratio | Vindt gedeeltelijke similariteit door de kortste string met substrings te vergelijken. | fuzz.partial_ratio(name, full_name) |
| Token sort ratio | Negeert de volgorde van woorden in strings. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Token set ratio | Verwijdert gemeenschappelijke tokens voordat de similariteit wordt berekend. | fuzz.token_set_ratio(name, full_name) |
In deze sectie bekijken we hoe je fuzzy string matching toepast op een pandas-dataframe.
Stel dat je data hebt geëxporteerd naar een pandas-dataframe en je die wilt joinen met je bestaande data.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Er is een groot probleem.
De bestaande data heeft de juiste spelling van de landen, maar de geëxporteerde data niet. Als we zouden proberen de twee dataframes te joinen op de kolom country, herkent pandas de verkeerd gespelde woorden niet als gelijk aan de correct gespelde woorden. Het resultaat van de merge-functie zal dus niet zijn wat je verwacht.
Dit is wat er gebeurt als we het proberen:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Dit gaat volledig voorbij aan het doel om deze dataframes te mergen.
Met fuzzy string matching kunnen we dit probleem echter omzeilen.
Zo ziet dat eruit in code:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""In deze code hebben we de verkeerd gespelde waarden in de kolom country van de geëxporteerde data hernoemd met een handige lambda-functie in combinatie met de methode process.extractOne(). Let op: we hebben een index van 0 gebruikt op het resultaat van extractOne() om alleen de vergelijkbare string terug te geven in plaats van een lijst met de string en de similariteitswaarde.
Vervolgens hebben we de dataframes gemerged op de kolom country met een left join. Het resultaat is één dataframe met de correct gespelde landen (inclusief de politieke unie van het Verenigd Koninkrijk).
Hoewel de oplossing hierboven perfect is voor deze tutorial en kleine datasets, wees voorzichtig bij toepassing op "Big Data".
Wanneer je .apply() gebruikt met fuzzy matching, moet de computer elke rij in dataframe A vergelijken met elke rij in dataframe B (een cartesisch product).
Voor datasets groter dan een paar duizend rijen, overweeg RapidFuzz (dat C++ gebruikt voor snelheid) of Splink (dat “blocking” gebruikt om het aantal vergelijkingen te verminderen).
Heb je een snelle samenvatting van de bovenstaande technieken nodig? Je vindt ze in de tabel hieronder:
| Stap | Beschrijving | Codefragment |
|---|---|---|
| DataFrames maken | Definieer data met mogelijke spelfouten. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Poging tot mergen met fouten | Eerste merge faalt door niet-overeenkomende strings. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Spelfouten corrigeren | Gebruik fuzzy matching om verkeerd gespelde landnamen te corrigeren. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Geslaagde merge | Merge de dataframes nadat de spelfouten zijn gecorrigeerd met fuzzy string matching. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
In deze tutorial heb je geleerd:
De voorbeelden hier zijn misschien eenvoudig, maar ze zijn voldoende om te laten zien hoe je verschillende gevallen aanpakt waarin een computer strings als niet-overeenkomend ziet. Fuzzy matching kent talloze toepassingen, zoals spellingscontrole en bio-informatica, waar fuzzy logica wordt gebruikt om DNA-sequenties te matchen.
Python-cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
