Corso
Introduzione a Python
4 h
6.9M
L’algoritmo di fuzzy string matching cerca di determinare il grado di vicinanza tra due stringhe diverse. Questo avviene usando una metrica di distanza nota come “edit distance”. La distanza di edit stabilisce quanto sono vicine due stringhe trovando il numero minimo di “modifiche” richieste per trasformare una stringa nell’altra.
Se la distanza di edit conta il numero di operazioni di modifica per dirci a quante operazioni una stringa è dall’altra, una “modifica” è un’operazione eseguita su una stringa per trasformarla in un’altra stringa.
Esistono quattro principali tipi di modifiche:
| Operazione di modifica | Descrizione | Esempio |
|---|---|---|
| Inserimento | Aggiungi una lettera | "Londn" -> "London" |
| Cancellazione | Rimuovi una lettera | "Londoon" -> "London" |
| Scambio | Scambia due lettere adiacenti | "Lnodon" -> "London" |
| Sostituzione | Cambia una lettera con un’altra | "Londin" -> "London" |
Queste quattro operazioni di modifica rendono possibile trasformare qualsiasi stringa.
Combinando le operazioni di modifica puoi scoprire l’elenco delle possibili stringhe a N modifiche di distanza, dove N è il numero di operazioni. Per esempio, la distanza di edit tra “London” e “Londin” è uno, poiché sostituendo la “i” con una “o” si ottiene una corrispondenza esatta.
Ma, ti chiedi, come si calcola esattamente la distanza di edit?
Esistono diverse varianti per calcolarla. Per esempio, ci sono la distanza di Levenshtein, la distanza di Hamming, la distanza di Jaro e altre.
In questo tutorial ci interessa solo la distanza di Levenshtein.
È una metrica che prende il nome da Vladimir Levenshtein, che la propose nel 1965 per misurare la differenza tra due sequenze di parole. Possiamo usarla per scoprire il numero minimo di modifiche necessarie per trasformare una sequenza di una parola nell’altra.
Ecco il calcolo formale:
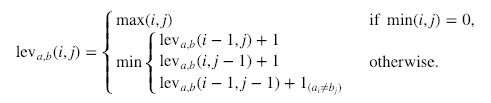
Dove 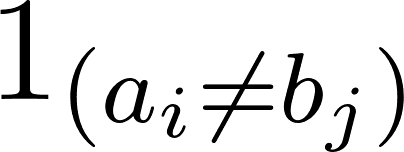 indica 0 quando a=b e 1 altrimenti.
indica 0 quando a=b e 1 altrimenti.
È importante notare che le righe nel minimo sopra corrispondono, in ordine, a una cancellazione, un inserimento e una sostituzione.
È anche possibile calcolare il rapporto di similarità di Levenshtein a partire dalla distanza di Levenshtein. Si può fare usando la seguente formula:
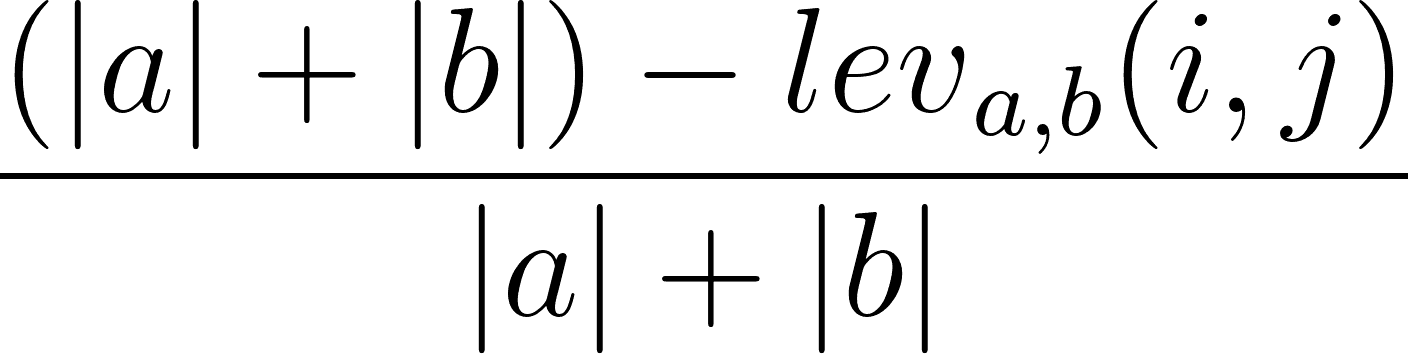
dove |a| e |b| sono rispettivamente le lunghezze della sequenza a e della sequenza b.
Uno dei pacchetti più popolari per il fuzzy string matching in Python è stato storicamente FuzzyWuzzy. Tuttavia, per risolvere questioni di licenza e aggiornare il codebase, nel 2021 il progetto è stato rinominato in TheFuzz. Rimane una libreria di riferimento per chi inizia grazie alla sua semplicità ed è quella che useremo in questo tutorial.
Fu sviluppata originariamente da SeatGeek per capire se due inserzioni di biglietti con nomi simili si riferissero allo stesso evento. Come la sua predecessora, TheFuzz usa la distanza di edit di Levenshtein per calcolare il grado di vicinanza tra due stringhe.
Consiglio pro: in produzione usa RapidFuzz. Sebbene TheFuzz sia ottima per imparare e per dataset piccoli, può essere lenta su elaborazioni su larga scala. L’industria si è in gran parte spostata verso una libreria più recente chiamata RapidFuzz.
fuzz.ratio), quindi puoi passare facilmente in seguito.Per questa guida, rimarremo su TheFuzz perché è preinstallata in molti ambienti ed è perfetta per comprendere i concetti di base.
Per prima cosa, dobbiamo installare il pacchetto TheFuzz. Puoi farlo con pip usando il seguente comando:
!pip install thefuzzNota: Questa libreria è preinstallata nel quaderno DataLab.
Ora, vediamo alcune cose che possiamo fare con thefuzz.
Segui il codice in questo quaderno DataLab.
Possiamo determinare il simple ratio tra due stringhe usando il metodo ratio() sull’oggetto fuzz. Questo calcola semplicemente la distanza di edit in base all’ordine di entrambe le stringhe di input difflib.ratio() – vedi la documentazione di difflib per saperne di più.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""Nel codice abbiamo usato due varianti del mio nome per confrontare il punteggio di similarità, che è risultato pari a 86.
Confrontiamolo con il partial ratio.
Per verificare il partial ratio, tutto ciò che dobbiamo fare è chiamare partial_ratio() sul nostro oggetto fuzz invece di ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Vediamo una diminuzione. Cosa succede?
Be’, partial_ratio() cerca di trovare quanto siano parzialmente simili due stringhe. Due stringhe sono parzialmente simili se hanno alcune parole in comune nello stesso ordine.
partial_ratio() calcola la similarità prendendo la stringa più corta, che in questo caso è nella variabile name, poi la confronta con le sottostringhe della stessa lunghezza nella stringa più lunga, memorizzata in full_name.
Poiché l’ordine conta nel partial ratio, il nostro punteggio è sceso in questo caso. Quindi, per ottenere una corrispondenza al 100%, dovresti spostare la parte "K D" (che indica il mio secondo nome) alla fine della stringa. Per esempio:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""E se volessimo che il nostro fuzzy string matcher ignorasse l’ordine?
Allora potresti usare il “token sort ratio”.
Ok, quindi vogliamo ignorare l’ordine delle parole nelle stringhe ma stabilire comunque quanto sono simili: token sort ti aiuta a fare proprio questo. Token sort non si preoccupa dell’ordine in cui compaiono le parole. Tiene conto di stringhe simili che non sono nello stesso ordine, come visto sopra.
Di conseguenza, dovremmo ottenere un punteggio del 100% usando il token sort ratio con l’esempio più recente:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""… e, come previsto, lo abbiamo ottenuto.
Torniamo alle variabili originali name e full_name. Cosa pensi succeda se usiamo ora il token sort?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""Il punteggio scende.
Questo perché token sort ignora solo l’ordine. Se ci sono parole dissimili nelle stringhe, ciò influirà negativamente sul rapporto di similarità, come abbiamo visto sopra.
Ma c’è un’alternativa.
Il metodo token_set_ratio() è molto simile a token_sort_ratio(), tranne per il fatto che rimuove i token comuni prima di calcolare quanto le stringhe siano simili: è estremamente utile quando le stringhe hanno lunghezze molto diverse.
Dal momento che le variabili name e full_name contengono entrambe “Kurtis Pykes”, possiamo aspettarci che la similarità con token set ratio sia del 100%.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""Il modulo process permette di estrarre testo da una collezione usando il fuzzy string matching. Chiamare il metodo extract() su process restituisce le stringhe con un punteggio di similarità in un vettore. Per esempio:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Possiamo controllare la lunghezza del vettore restituito da extract() impostando il parametro limit alla lunghezza desiderata.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""In questo caso, extract() restituisce le tre stringhe più vicine in base allo scorer che abbiamo definito.
Nella tabella seguente trovi un rapido confronto tra i diversi tipi di tecniche disponibili in TheFuzz:
| Tecnica | Descrizione | Esempio di codice |
|---|---|---|
| Simple Ratio | Calcola la similarità tenendo conto dell’ordine delle stringhe di input. | fuzz.ratio(name, full_name) |
| Partial Ratio | Trova la similarità parziale confrontando la stringa più corta con sottostringhe. | fuzz.partial_ratio(name, full_name) |
| Token Sort Ratio | Ignora l’ordine delle parole nelle stringhe. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Token Set Ratio | Rimuove i token comuni prima di calcolare la similarità. | fuzz.token_set_ratio(name, full_name) |
In questa sezione vedremo come fare fuzzy string matching su un dataframe pandas.
Supponiamo che tu abbia dei dati esportati in un dataframe pandas e voglia unirli a dati esistenti.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""C’è un grosso problema.
I dati esistenti hanno l’ortografia corretta dei paesi, ma i dati esportati no. Se provassimo a unire i due dataframe sulla colonna country, pandas non riconoscerebbe le parole con errori come uguali a quelle scritte correttamente. Di conseguenza, il risultato della funzione merge non sarebbe quello atteso.
Ecco cosa succederebbe se ci provassimo:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Questo vanifica l’intero scopo di tentare di unire questi dataframe.
Tuttavia, possiamo aggirare il problema con il fuzzy string matching.
Vediamo come si presenta in codice:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""In questo codice abbiamo rinominato i valori con errori nella colonna country dei dati esportati usando una comoda funzione lambda insieme al metodo process.extractOne(). Nota che abbiamo usato l’indice 0 sul risultato di extractOne() per restituire solo la stringa simile invece di una lista contenente stringa e valore di similarità.
Successivamente, abbiamo unito i dataframe sulla colonna country usando una left join. Il risultato è un singolo dataframe contenente i paesi scritti correttamente (inclusa l’unione politica del Regno Unito).
Sebbene la soluzione sopra sia perfetta per questo tutorial e per dataset piccoli, fai attenzione ad applicarla al “Big Data”.
Quando usi .apply() con fuzzy matching, il computer deve confrontare ogni singola riga del dataframe A con ogni riga del dataframe B (prodotto cartesiano).
Per dataset più grandi di qualche migliaio di righe, valuta di usare RapidFuzz (che usa C++ per la velocità) o Splink (che usa il “blocking” per ridurre i confronti).
Se ti serve un rapido riepilogo delle tecniche citate sopra, le trovi nella tabella seguente:
| Passo | Descrizione | Snippet di codice |
|---|---|---|
| Crea i DataFrame | Definisci dati con possibili errori di ortografia. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Tenta il merge con errori | Il merge iniziale fallisce a causa di stringhe non corrispondenti. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Correggi gli errori di ortografia | Usa il fuzzy matching per correggere i nomi dei paesi scritti male. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Merge riuscito | Unisci i dataframe dopo aver corretto gli errori usando il fuzzy string matching. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
In questo tutorial hai imparato:
Gli esempi presentati qui sono semplici, ma bastano per illustrare come gestire vari casi in cui il computer considera le stringhe come non corrispondenti. Ci sono diverse applicazioni del fuzzy matching in ambiti come il correttore ortografico e la bioinformatica, dove la logica fuzzy è usata per confrontare sequenze di DNA.
Corsi Python
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

