Courses
Nhập môn Python
4 giờ
6.9M
Thuật toán fuzzy string matching tìm cách xác định mức độ gần nhau giữa hai chuỗi khác nhau. Điều này được tìm ra bằng một thước đo khoảng cách gọi là “khoảng cách chỉnh sửa” (edit distance). Edit distance xác định độ gần của hai chuỗi bằng cách tìm số lượng “chỉnh sửa” tối thiểu cần để biến đổi một chuỗi thành chuỗi còn lại.
Nếu edit distance đếm số phép chỉnh sửa để cho biết một chuỗi cách chuỗi kia bao nhiêu phép, thì một edit là thao tác thực hiện trên một chuỗi để biến nó thành chuỗi khác.
Có bốn loại phép chỉnh sửa chính:
| Phép chỉnh sửa | Mô tả | Ví dụ |
|---|---|---|
| Chèn | Thêm một chữ cái | "Londn" -> "London" |
| Xóa | Loại bỏ một chữ cái | "Londoon" -> "London" |
| Hoán đổi | Đổi chỗ hai chữ cái liền kề | "Lnodon" -> "London" |
| Thay thế | Đổi một chữ cái thành chữ khác | "Londin" -> "London" |
Bốn phép chỉnh sửa này giúp bạn có thể sửa đổi bất kỳ chuỗi nào.
Kết hợp các phép chỉnh sửa cho phép bạn tìm danh sách các chuỗi có thể có cách N phép chỉnh sửa, với N là số thao tác chỉnh sửa. Ví dụ, khoảng cách chỉnh sửa giữa “London” và “Londin” là một vì thay “i” bằng “o” sẽ khớp chính xác.
Nhưng cụ thể edit distance được tính như thế nào?
Có nhiều biến thể để tính edit distance. Chẳng hạn, có khoảng cách Levenshtein, khoảng cách Hamming, khoảng cách Jaro, v.v.
Trong hướng dẫn này, chúng ta chỉ quan tâm đến khoảng cách Levenshtein.
Đây là một thước đo đặt theo tên Vladimir Levenshtein, người đã đề xuất vào năm 1965 để đo sự khác biệt giữa hai dãy từ. Ta có thể dùng nó để tìm số phép chỉnh sửa tối thiểu cần để biến một dãy một từ thành dãy còn lại.
Dưới đây là công thức chính thức:
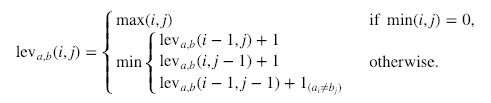
Trong đó 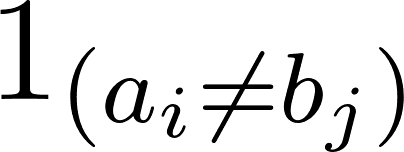 nhận giá trị 0 khi a=b và 1 trong các trường hợp khác.
nhận giá trị 0 khi a=b và 1 trong các trường hợp khác.
Lưu ý rằng ba hàng trong biểu thức cực tiểu ở trên lần lượt tương ứng với xóa, chèn và thay thế.
Cũng có thể tính tỷ lệ tương đồng Levenshtein dựa trên khoảng cách Levenshtein. Có thể thực hiện bằng công thức sau:
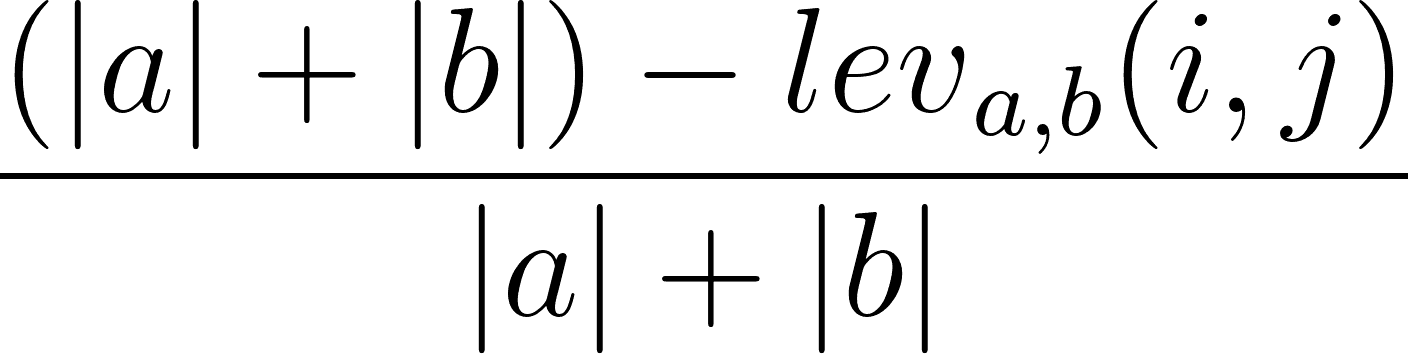
trong đó |a| và |b| là độ dài lần lượt của dãy a và dãy b.
Một trong những gói phổ biến nhất cho fuzzy string matching trong Python trước đây là FuzzyWuzzy. Tuy nhiên, để giải quyết vấn đề giấy phép và cập nhật mã nguồn, năm 2021 dự án được đổi tên thành TheFuzz. Thư viện này vẫn là lựa chọn hàng đầu cho người mới nhờ sự đơn giản và cũng là thư viện chúng ta dùng trong hướng dẫn này.
Nó được SeatGeek phát triển ban đầu để phân biệt liệu hai danh sách vé có tên tương tự có thuộc cùng một sự kiện hay không. Giống tiền thân, TheFuzz dùng khoảng cách chỉnh sửa Levenshtein để tính mức độ gần nhau giữa hai chuỗi.
Mẹo chuyên nghiệp: Dùng RapidFuzz cho môi trường sản xuất. Mặc dù TheFuzz rất tốt để học và cho bộ dữ liệu nhỏ, nó có thể chậm khi xử lý dữ liệu quy mô lớn. Ngành đã chuyển nhiều sang thư viện mới hơn tên là RapidFuzz.
fuzz.ratio), nên bạn có thể chuyển đổi dễ dàng sau này.Trong hướng dẫn này, chúng ta sẽ gắn với TheFuzz vì nó được cài sẵn trong nhiều môi trường và rất phù hợp để hiểu các khái niệm cốt lõi.
Trước tiên, chúng ta cần cài gói TheFuzz. Bạn có thể dùng pip với lệnh sau:
!pip install thefuzzLưu ý: Thư viện này được cài sẵn trong sổ tay DataLab.
Giờ, hãy xem chúng ta có thể làm gì với thefuzz.
Theo dõi mã trong sổ tay DataLab này.
Ta có thể xác định tỷ lệ đơn giản giữa hai chuỗi bằng phương thức ratio() trên đối tượng fuzz. Phương thức này chỉ tính edit distance dựa trên thứ tự của cả hai chuỗi đầu vào difflib.ratio() – xem tài liệu difflib để biết thêm.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""Trong đoạn mã, chúng ta dùng hai biến thể tên của tôi để so sánh điểm tương đồng, kết quả là 86.
Hãy so với partial ratio.
Để kiểm tra partial ratio, tất cả những gì cần làm là gọi partial_ratio() trên đối tượng fuzz thay cho ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Chúng ta thấy điểm giảm. Chuyện gì vậy?
partial_ratio() tìm xem hai chuỗi giống nhau một phần đến đâu. Hai chuỗi được coi là giống nhau một phần nếu chúng có một số từ theo cùng thứ tự.
partial_ratio() tính độ tương đồng bằng cách lấy chuỗi ngắn hơn, trong tình huống này được lưu trong biến name, rồi so sánh với các chuỗi con cùng độ dài trong chuỗi dài hơn, được lưu trong full_name.
Vì thứ tự quan trọng trong partial ratio, điểm của chúng ta giảm trong trường hợp này. Do đó, để đạt 100% tương đồng, bạn sẽ phải chuyển phần "K D" (tên đệm của tôi) xuống cuối chuỗi. Ví dụ:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""Vậy nếu ta muốn bộ so khớp fuzzy bỏ qua thứ tự thì sao?
Khi đó bạn có thể dùng “token sort ratio.”
Chúng ta muốn bỏ qua thứ tự các từ trong chuỗi nhưng vẫn xác định độ tương đồng – token sort giúp bạn làm đúng điều đó. Token sort không quan tâm thứ tự xuất hiện của từ. Nó tính đến các chuỗi tương tự dù không theo đúng thứ tự như trên.
Vì vậy, với ví dụ mới nhất, chúng ta sẽ nhận điểm 100% bằng token sort ratio:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""… và đúng như kỳ vọng, chúng ta đã được 100%.
Hãy quay lại các biến name và full_name ban đầu. Theo bạn điều gì sẽ xảy ra nếu giờ dùng token sort?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""Điểm giảm.
Đó là vì token sort chỉ bỏ qua thứ tự. Nếu có những từ không giống nhau giữa các chuỗi, chúng sẽ làm giảm tỷ lệ tương đồng, như ta đã thấy ở trên.
Nhưng có một cách xử lý.
Phương thức token_set_ratio() khá giống token_sort_ratio(), ngoại trừ việc nó loại bỏ các token chung trước khi tính độ tương đồng giữa các chuỗi: điều này cực kỳ hữu ích khi các chuỗi khác nhau đáng kể về độ dài.
Vì cả name và full_name đều có “Kurtis Pykes”, ta có thể kỳ vọng điểm tương đồng theo token set ratio là 100%.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""Mô-đun process cho phép trích xuất văn bản từ một tập hợp bằng fuzzy string matching. Gọi phương thức extract() trên mô-đun process sẽ trả về các chuỗi kèm điểm tương đồng trong một vector. Ví dụ:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Chúng ta có thể kiểm soát độ dài vector trả về bởi extract() bằng cách đặt tham số limit theo độ dài mong muốn.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""Trong trường hợp này, extract() trả về ba chuỗi khớp gần nhất dựa trên scorer đã định.
Bảng dưới đây cho thấy so sánh nhanh giữa các kỹ thuật có trong TheFuzz:
| Kỹ thuật | Mô tả | Ví dụ mã |
|---|---|---|
| Simple Ratio | Tính độ tương đồng có xét đến thứ tự của chuỗi đầu vào. | fuzz.ratio(name, full_name) |
| Partial Ratio | Tìm độ tương đồng một phần bằng cách so sánh chuỗi ngắn hơn với các chuỗi con. | fuzz.partial_ratio(name, full_name) |
| Token Sort Ratio | Bỏ qua thứ tự từ trong chuỗi. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Token Set Ratio | Loại bỏ các token chung trước khi tính độ tương đồng. | fuzz.token_set_ratio(name, full_name) |
Trong phần này, chúng ta sẽ xem cách thực hiện fuzzy string matching trên một pandas dataframe.
Giả sử bạn có một số dữ liệu đã xuất ra pandas dataframe và bạn muốn nối chúng với dữ liệu hiện có.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Có một vấn đề lớn.
Dữ liệu hiện có có chính tả đúng cho các quốc gia, nhưng dữ liệu xuất ra thì không. Nếu ta cố nối hai dataframe theo cột country, pandas sẽ không nhận các từ viết sai là bằng với từ viết đúng. Do đó, kết quả trả về từ hàm merge sẽ không như kỳ vọng.
Đây là điều sẽ xảy ra nếu chúng ta thử:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Điều này đi ngược lại mục đích ghép hai dataframe.
Tuy nhiên, ta có thể khắc phục bằng fuzzy string matching.
Hãy xem trong mã:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""Trong đoạn mã này, chúng ta đã đổi tên các giá trị viết sai trong cột country của dữ liệu xuất bằng một hàm lambda gọn kết hợp với phương thức process.extractOne(). Lưu ý, chúng ta dùng chỉ số 0 trên kết quả của extractOne() để chỉ trả về chuỗi tương tự thay vì danh sách gồm chuỗi và giá trị tương đồng.
Tiếp theo, chúng ta ghép các dataframe theo cột country bằng left join. Kết quả là một dataframe duy nhất chứa tên quốc gia với chính tả đúng (bao gồm cả liên minh chính trị Vương quốc Liên hiệp Anh và Bắc Ireland).
Mặc dù giải pháp trên hoàn hảo cho hướng dẫn này và các bộ dữ liệu nhỏ, hãy cẩn trọng khi áp dụng cho "Dữ liệu Lớn".
Khi bạn dùng .apply() với fuzzy matching, máy tính phải so sánh từng hàng trong dataframe A với từng hàng trong dataframe B (tích Descartes).
Với các bộ dữ liệu lớn hơn vài nghìn hàng, hãy cân nhắc dùng RapidFuzz (dùng C++ để tăng tốc) hoặc Splink (dùng "blocking" để giảm số phép so sánh).
Nếu bạn cần tóm tắt nhanh các kỹ thuật đã nêu, có thể xem trong bảng dưới đây:
| Bước | Mô tả | Đoạn mã |
|---|---|---|
| Tạo DataFrame | Định nghĩa dữ liệu có thể có lỗi chính tả. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Thử ghép nhưng lỗi | Ghép ban đầu thất bại do chuỗi không khớp. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Sửa lỗi chính tả | Dùng fuzzy matching để sửa tên quốc gia viết sai. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Ghép thành công | Ghép các dataframe sau khi sửa lỗi chính tả bằng fuzzy string matching. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
Trong hướng dẫn này, bạn đã học:
Các ví dụ ở đây có thể đơn giản, nhưng đủ để minh họa cách xử lý nhiều trường hợp máy tính cho là chuỗi không khớp. Có nhiều ứng dụng của fuzzy matching trong các lĩnh vực như kiểm tra chính tả và tin sinh học, nơi logic mờ được dùng để khớp chuỗi DNA.
Các khóa học Python
Courses
Courses
Courses