
Kursus
Penyebaran dan Siklus Hidup MLOps
4 Hr
11.9K
Terinspirasi oleh evolusi alami, GA secara efisien menjelajahi ruang solusi untuk menemukan solusi optimal atau mendekati optimal, bahkan untuk masalah kompleks dengan banyak komponen. Dengan meniru proses seleksi alam, GA dapat mengembangkan solusi seiring waktu, meningkatkan kinerjanya secara iteratif.
Algoritme genetika terinspirasi oleh proses seleksi alam dan genetika. Algoritme ini meniru cara organisme hidup berevolusi selama beberapa generasi untuk beradaptasi dan bertahan di lingkungannya. Memahami prinsip-prinsip biologi dasar di balik GA dapat membantu kita memahami cara kerja algoritme ini dan menggunakannya secara lebih strategis.
Seleksi alam adalah proses yang menyebabkan individu dengan kombinasi sifat yang lebih menguntungkan lebih mungkin bertahan hidup dan bereproduksi. Seiring waktu, sifat-sifat yang menguntungkan ini menjadi lebih umum dalam populasi.
Dalam konteks GA, konsep ini dicerminkan dengan memilih individu dengan skor kebugaran (fitness) lebih tinggi untuk bereproduksi. Dengan cara ini, mereka meneruskan sifat-sifat menguntungkan, atau "gen", ke generasi berikutnya.
Sifat-sifat organisme biologis dikodekan oleh gennya. Gen adalah bagian dari DNA, yang tersusun dalam kromosom.
GA meminjam banyak konsep dan terminologi yang sama. Solusi potensial untuk suatu masalah direpresentasikan sebagai "kromosom", yang biasanya dikodekan sebagai string atau array. Setiap elemen dalam kromosom sesuai dengan gen yang menentukan sifat tertentu dari solusi.
Crossover, atau rekombinasi, adalah operasi genetik yang menggabungkan bagian materi genetik dari dua kromosom induk menjadi kromosom baru yang memiliki bagian dari masing-masing induk. Paduan kromosom baru ini diteruskan ke anak. Inilah salah satu alasan mengapa Anda bisa mendapatkan warna mata ibu dan warna rambut ayah.
Dalam GA, crossover melibatkan pertukaran segmen dari kromosom induk untuk menciptakan individu baru. Operasi ini memperkenalkan variasi dan memungkinkan keturunan mewarisi sifat menguntungkan dari kedua orang tua.
Mutasi memperkenalkan perubahan acak pada gen suatu organisme, yang dapat menghasilkan sifat baru.
Dalam algoritme genetika, mutasi melibatkan perubahan acak pada satu atau lebih gen dalam kromosom. Ini membantu mempertahankan keragaman genetik dalam populasi dan memungkinkan algoritme menjelajahi area baru dalam ruang solusi.
Di alam, kebugaran individu ditentukan oleh kemampuannya untuk bertahan hidup dan bereproduksi. Jika Anda mati sebelum bereproduksi, kebugaran Anda adalah nol. Jika Anda memiliki 12 cucu, kebugaran Anda akan lebih tinggi daripada seseorang yang memiliki 2 cucu.
Dalam GA, kebugaran serupa, tetapi sedikit berbeda. Fungsi kebugaran mengevaluasi seberapa baik suatu solusi menyelesaikan masalah yang dihadapi. Solusi dengan skor kebugaran lebih tinggi lebih mungkin dipilih untuk bereproduksi, memastikan solusi yang lebih baik menyebar antargenerasi.
Algoritme genetika terinspirasi oleh evolusi. Akibatnya, komponen GA memiliki nama dan fungsi yang mirip dengan padanannya dalam biologi. Masing-masing komponen ini biasanya dikodekan sebagai fungsinya sendiri.
Populasi dalam algoritme genetika adalah sekumpulan kandidat solusi, sering disebut individu. Setiap individu direpresentasikan sebagai kromosom, yang dapat dikodekan sebagai string biner, array, atau struktur data lainnya.
Misalnya, setiap kromosom dapat merepresentasikan sekumpulan nilai masukan untuk fungsi yang perlu kita optimalkan. Atau setiap kromosom dapat merepresentasikan rute truk untuk pengemudi pengiriman.
Fungsi kebugaran mengevaluasi kemampuan setiap individu untuk menyelesaikan masalah yang kita minati. Fungsi ini memberikan nilai kebugaran kepada setiap individu, dengan nilai lebih tinggi untuk solusi yang lebih baik. Fungsi kebugaran memandu algoritme menuju solusi yang lebih baik.
Contohnya, dalam optimisasi fungsi matematika, fungsi kebugaran dapat mengembalikan nilai fungsi untuk masukan yang diberikan. Untuk contoh rute truk, fungsi kebugaran dapat mengembalikan kecepatan penyelesaian pengiriman.
Fungsi seleksi memilih individu dari populasi untuk bereproduksi berdasarkan kebugarannya. Individu dengan kebugaran lebih tinggi lebih mungkin dipilih untuk bereproduksi. Ini meniru seleksi alam, di mana individu yang paling beradaptasi lebih mungkin bertahan dan bereproduksi.
Ada beberapa metode seleksi. Metode umum termasuk seleksi roda rolet (roulette wheel), seleksi turnamen, dan seleksi berbasis peringkat.
Seleksi roda rolet memilih individu berdasarkan probabilitas yang proporsional dengan kebugarannya, mirip dengan memutar roda rolet.
Dalam seleksi turnamen, subset individu dipilih secara acak lalu individu paling bugar dari subset ini dipilih.
Seleksi berbasis peringkat memberi peringkat individu berdasarkan kebugarannya. Kemudian probabilitas seleksi diberikan berdasarkan peringkat ini, bukan nilai kebugaran mentah.
Setiap metode memiliki keunggulan sendiri dan harus dipilih berdasarkan kebutuhan spesifik masalah yang dihadapi.
Crossover menggabungkan informasi dari dua individu untuk membuat keturunan. Tujuannya adalah mewariskan sifat menguntungkan dari kedua orang tua. Teknik crossover umum mencakup single-point crossover, multi-point crossover, uniform crossover, dan blend crossover.
Single-point crossover melibatkan pemilihan satu titik acak dan menukar materi genetik dari dua induk pada titik tersebut untuk membuat dua keturunan. Multi-point crossover menggunakan beberapa titik untuk menukar segmen antarinduk, memungkinkan kombinasi genetik yang lebih kompleks.
Uniform crossover secara acak memutuskan induk mana yang akan menyumbang setiap gen, memberikan tingkat keragaman genetik yang tinggi. Blend crossover menghasilkan keturunan dengan mencampurkan gen orang tua menggunakan faktor pencampuran acak. Keputusan teknik mana yang akan digunakan sebaiknya didasarkan pada kompleksitas masalah dan tingkat keragaman yang diinginkan pada keturunan.
Mutasi memperkenalkan perubahan acak pada materi genetik keturunan. Ini membantu mempertahankan keragaman dalam populasi dan menjelajahi area baru dalam ruang solusi. Mutasi bisa sesederhana membalik bit dalam string biner atau melibatkan perubahan yang lebih kompleks bergantung pada skema pengodean.
Algoritme genetika melalui serangkaian langkah yang meniru proses evolusi alami untuk menemukan solusi optimal. Langkah-langkah ini memungkinkan populasi berevolusi antargenerasi, meningkatkan kualitas solusi. Berikut panduan umum bagaimana algoritme genetika berjalan:
Pertama, kita menghasilkan populasi awal individu secara acak. Langkah ini menciptakan kumpulan solusi potensial yang beragam untuk memulai algoritme.
Berikutnya, kita perlu menghitung kebugaran setiap individu dalam populasi. Di sini kita menggunakan fungsi kebugaran untuk mengevaluasi sebaik apa masing-masing solusi.
Menggunakan kriteria seleksi, kita memilih individu untuk bereproduksi berdasarkan kebugarannya. Langkah ini menentukan individu mana yang akan menjadi orang tua.
Selanjutnya adalah crossover. Dengan menggabungkan materi genetik dari orang tua terpilih, kita menerapkan teknik crossover untuk menghasilkan solusi baru atau keturunan.
Untuk mempertahankan keragaman dalam populasi, kita perlu memperkenalkan mutasi acak pada keturunan.
Berikutnya kita mengganti sebagian atau seluruh populasi lama dengan keturunan baru, dengan menentukan individu mana yang lanjut ke generasi berikutnya.
Langkah-langkah 2-6 sebelumnya diulang untuk sejumlah generasi tertentu atau sampai kondisi terminasi terpenuhi. Perulangan ini memungkinkan populasi berevolusi seiring waktu, semoga menghasilkan solusi yang baik.
Sekarang kita sudah memahami apa itu algoritme genetika dan secara umum cara kerjanya, mari kita membangun algoritme genetika sendiri untuk menyelesaikan masalah optimisasi sederhana.
Persamaan y=ax2+bx+c, saat digambarkan, membentuk parabola. Kita akan menggunakan algoritme genetika untuk menemukan kombinasi nilai a, b, dan c yang menghasilkan parabola paling datar. Berikut pratinjau yang akan kita capai:
Di bagian atas fungsi kita, kita akan mengimpor pustaka yang diperlukan. Kita akan menggunakan ‘random’ untuk menghasilkan nilai acak bagi populasi awal kita. Numpy umumnya berguna saat melakukan perhitungan matematika, menurut saya.
Dan saya sangat percaya bahwa Anda sebaiknya selalu membuat plot untuk memastikan kode melakukan apa yang Anda pikirkan. Jadi kita akan mengimpor ‘matplotlib.pyplot’ untuk membuat beberapa grafik.
Saya juga suka mencetak hasil penting dari setiap generasi (dengan asumsi jumlah generasi relatif kecil) untuk lebih memahami apa yang terjadi selama simulasi. Jadi kita akan mengimpor ‘PrettyTable’ untuk itu.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableBerikutnya kita perlu mendefinisikan fungsi kebugaran yang akan mengevaluasi kebugaran setiap solusi. Dalam kasus ini, kita ingin menemukan bentuk U tergambar yang paling datar. Jadi saya menghitung nilai y pada titik puncak (vertex) serta pada x=-1 dan x=1.
Lalu saya menghitung tingkat kelengkungan grafik sebagai selisih nilai y pada tiga titik ini. Karena kita ingin mendapatkan kurva paling datar, saya menegasikan nilai kelengkungan untuk menyelesaikan fungsi kebugaran.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessKita akan menggunakan pustaka ‘random’ untuk menghasilkan populasi solusi acak. Setiap individu dalam populasi ini adalah sekumpulan nilai untuk a, b, dan c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationFungsi seleksi akan menentukan individu mana yang bereproduksi untuk membuat populasi berikutnya. Dalam contoh ini, kita akan menggunakan proses seleksi turnamen, di mana subset individu acak dalam populasi diambil, dan individu dengan kebugaran terbesar dalam subset tersebut dipilih untuk bereproduksi.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedSelanjutnya, kita akan menulis fungsi singkat untuk menggunakan crossover guna membuat solusi baru berdasarkan solusi yang ada.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Kita juga membutuhkan fungsi mutasi untuk memperkenalkan keacakan pada generasi berikutnya. Ini penting untuk memastikan ada cukup keragaman di setiap generasi untuk dipilih.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Berikutnya kita perlu membuat loop utama yang akan menyatukan semua bagian ini untuk menjalankan algoritme kita. Karena kita juga perlu memplot hasil, saya akan menambahkan kode plotting di bagian ini, serta kode yang diperlukan untuk membuat tabel akhir kita.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Terakhir, kita perlu menyiapkan parameter untuk algoritme kita dan menjalankannya.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Dalam contoh ini, kita menetapkan jumlah generasi tertentu untuk menjalankan algoritme. Namun, kita juga bisa menyiapkan kondisi terminasi yang menghentikan program ketika kita mencapai nilai kebugaran target. Kodenya bisa terlihat seperti ini:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessBerikut adalah kode lengkapnya secara keseluruhan.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Mari kita gunakan keluaran kita untuk melihat bagaimana kinerja fungsi kita.
Pertama, dari tabel kita dapat melihat bahwa kita menyelesaikan 20 generasi dan kebugaran tampak meningkat dari nilai kebugaran yang relatif negatif menjadi kurang negatif di setiap generasi. Bagus!
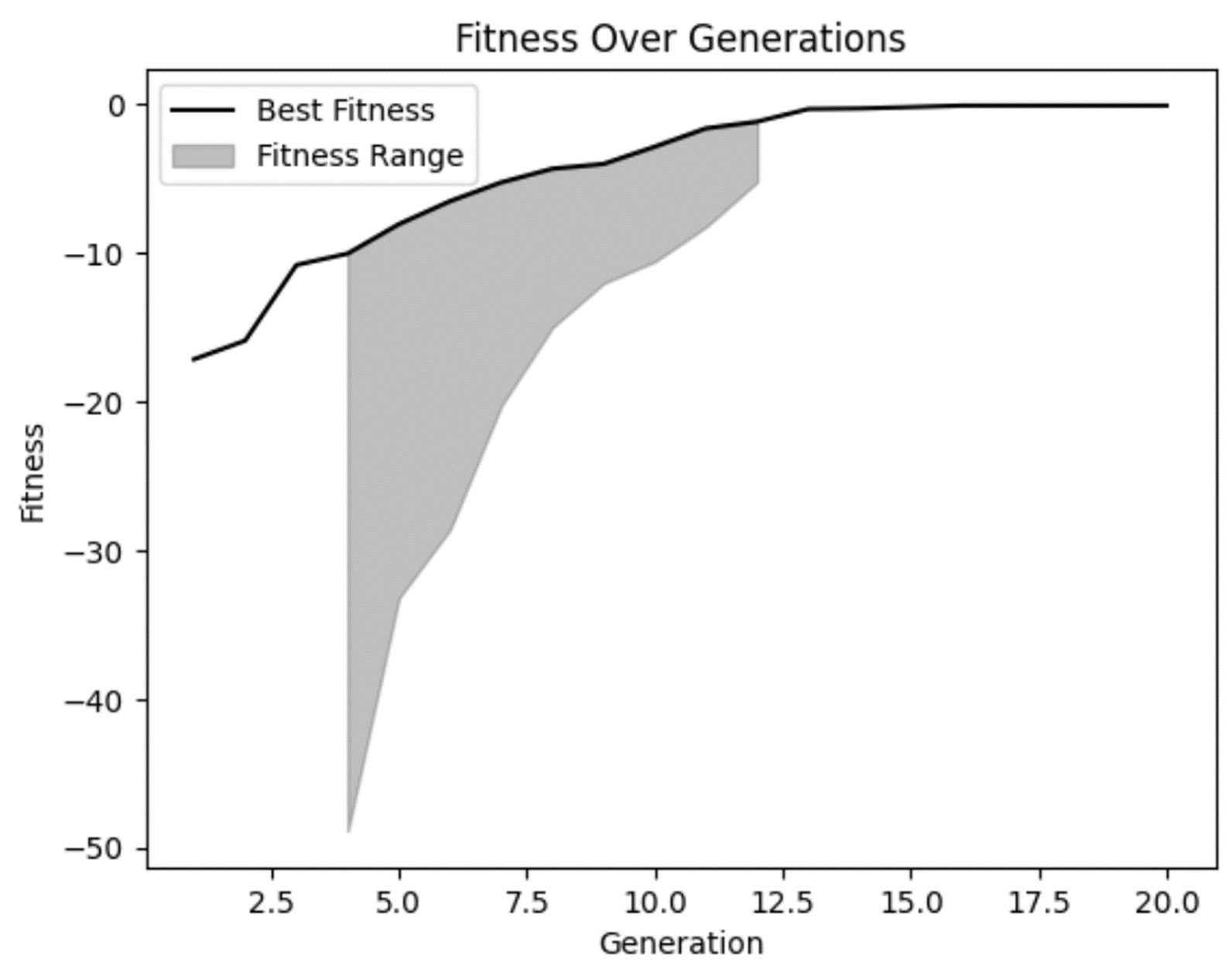
Dari grafik kebugaran, kita dapat mengonfirmasi dugaan bahwa kebugaran memang meningkat seiring waktu dan tampak sedikit mendatar pada generasi akhir. Namun kita juga melihat bahwa pada beberapa generasi awal ada solusi yang sangat buruk yang memang ditolak oleh model kita.
Kita juga dapat melihat bahwa pada beberapa generasi tidak ada banyak keragaman dalam rentang kebugaran. Walaupun itu tidak selalu buruk, ini adalah sesuatu yang perlu diwaspadai. Dalam beberapa kasus, ini bisa menjadi indikator konvergensi prematur, yaitu masalah yang terjadi ketika tidak ada cukup keragaman dalam populasi Anda.
Selanjutnya, mari kita plot persamaan dari setiap generasi untuk melihat apakah kita benar-benar membuatnya lebih datar.
Kita dapat melihat bahwa solusi generasi awal sangat melengkung, yang masuk akal. Persamaan ini menghasilkan grafik berbentuk U. Namun kita juga melihat bahwa generasi berikutnya menjadi semakin datar. Inilah yang kita cari!
Perlu dicatat bahwa kita secara eksplisit hanya melihat dalam batas yang dinyatakan, yaitu -50 hingga 50. Jika kita memperbesar rentang grafik ini, akan terlihat bahwa bahkan garis yang tampaknya datar ini tetap berbentuk U, hanya dengan dasar yang lebih lebar.
Contoh ini menyoroti pentingnya berhati-hati dengan asumsi dalam analisis agar mendukung prediksi kita. Model kita melakukan persis seperti yang kita inginkan, tetapi hanya dalam batas yang kita berikan. Jika kita ingin menemukan kombinasi variabel yang menghasilkan bentuk datar lebih jauh, maka kita perlu menjalankan ulang model dengan batas yang lebih lebar.
Kita dapat memplot masing-masing variabel untuk melihat seberapa besar perubahannya antargenerasi. Kita dapat melihat bahwa pada run simulasi ini, c bervariasi sangat besar di awal sementara a dan b berubah jauh lebih kecil. Grafik ini akan terlihat berbeda setiap kali kita menjalankan simulasi ini, bahkan jika kita tidak mengubah parameter apa pun karena populasi awal kita acak.
Grafik terakhir yang ingin saya lihat hanyalah cuplikan seluruh populasi dalam satu generasi: generasi terakhir. Karena setiap individu dalam populasi memiliki tiga parameter, saya memutuskan untuk memisahkannya menjadi tiga subplot alih-alih repot dengan plot tiga dimensi.
Yang benar-benar ingin saya lihat dari grafik ini adalah apakah ada keragaman yang baik dalam generasi ini. Tanpa tingkat keragaman yang memadai, kita bisa berakhir pada situasi di mana satu-satunya solusi yang tersedia adalah yang memiliki nilai kebugaran rendah, sehingga terjadi konvergensi prematur. Namun tampaknya grafik ini menunjukkan tingkat keragaman yang baik, jadi saya puas dengan hasil ini.
Algoritme genetika dapat digunakan dalam berbagai situasi. Namun ada beberapa pertimbangan yang perlu diingat.
Seperti halnya model apa pun, kinerja algoritme genetika bergantung pada berbagai parameter, terutama ukuran populasi, laju crossover, laju mutasi, dan parameter batas (bounding). Mengubah parameter-parameter ini akan mengubah kinerja model Anda.
Sebagai aturan praktis, ukuran populasi yang lebih besar akan membantu Anda menemukan solusi optimal lebih cepat karena ada lebih banyak opsi untuk dipilih. Namun, ukuran populasi yang lebih besar juga membutuhkan lebih banyak waktu dan sumber daya untuk dijalankan.
Laju crossover yang lebih tinggi dapat menghasilkan konvergensi lebih cepat dengan lebih sering menggabungkan sifat menguntungkan dari individu yang berbeda. Namun, laju crossover yang terlalu tinggi dapat mengganggu struktur populasi, yang mengarah ke konvergensi prematur.
Laju mutasi yang lebih tinggi membantu mempertahankan keragaman genetik, mencegah algoritme terjebak pada optimum lokal. Namun, jika laju mutasi terlalu tinggi, hal ini dapat mengganggu proses konvergensi dengan memperkenalkan terlalu banyak keacakan, sehingga menyulitkan algoritme untuk memperbaiki solusi.
Parameter batas mendefinisikan rentang di mana algoritme mencari solusi. Parameter ini penting untuk disetel pada masalah bisnis Anda. Area batas yang terlalu sempit dapat melewatkan solusi optimal untuk masalah Anda. Area batas yang terlalu luas akan memerlukan lebih banyak waktu dan sumber daya untuk dijalankan. Namun ada pertimbangan lain juga.
Misalnya, dalam contoh kode di atas, persamaan tersebut secara teoretis tidak memiliki batas. Namun secara praktis, kita tidak bisa meminta komputer menemukan busur paling datar dalam grafik yang tak terbatas. Jadi, batas diperlukan. Namun mengubah batas tersebut juga akan mengubah jawaban optimal. Menurut saya, menetapkan batas yang sesuai untuk kasus penggunaan spesifik Anda adalah hal yang sangat penting pada model apa pun.
Mungkin ada parameter penting lain untuk disetel pada model Anda. Bereksperimenlah dengan berbagai nilai untuk menemukan pengaturan terbaik bagi masalah Anda. Untuk mempelajari penyetelan GA secara khusus, lihat Informed Methods: Genetic Algorithms.
Pengodean adalah langkah penting dalam menyiapkan algoritme genetika. Ini melibatkan mengonversi solusi potensial ke dalam format yang dapat diproses algoritme. Misalnya, katakanlah kita merancang algoritme genetika untuk mengoptimalkan rute pengiriman bagi truk kita. Bagaimana Anda mengubah daftar lokasi pengiriman menjadi kromosom untuk dimasukkan ke GA? Pengodean mengubah daftar ini menjadi urutan yang dapat dimanipulasi algoritme, seperti daftar lokasi terurut yang merepresentasikan rute pengiriman yang mungkin.
Pengodean yang tepat memastikan algoritme genetika dapat secara efektif menjelajahi ruang solusi dan menggabungkan atau memutasi solusi dengan cara yang bermakna. Tanpanya, algoritme tidak akan dapat menangani data kompleks. Data seperti lokasi pengiriman, masalah penjadwalan, atau interaksi layanan pelanggan hanya dapat diakses komputer melalui pengodean.
Ada beberapa skema pengodean yang dapat dipilih. Anda dapat mempelajari lebih lanjut untuk memutuskan mana yang paling cocok untuk situasi Anda di Working with Categorical Data in Python atau How to Convert Strings to Bytes in Python.
Konvergensi prematur adalah masalah yang terjadi ketika populasi menjadi terlalu serupa. Ini dapat menyebabkan algoritme terjebak pada optimum lokal alih-alih menemukan optimum global. Intinya, jika tidak ada cukup keragaman dalam populasi, solusi menjadi “inbreeding” dan Anda tidak mendapatkan solusi terbaik.
Ada beberapa teknik yang bisa Anda coba untuk menghindari konvergensi prematur. Laju mutasi yang lebih tinggi dapat memperkenalkan lebih banyak keragaman ke dalam populasi, membantu menjelajahi area baru dalam ruang solusi. Anda juga dapat mencoba memulai dengan populasi awal yang lebih beragam untuk memastikan eksplorasi ruang solusi yang luas sejak awal.
Jika Anda masih menghadapi konvergensi prematur, Anda dapat mencoba menyesuaikan parameter seperti laju mutasi dan laju crossover secara dinamis berdasarkan kemajuan algoritme. Alternatifnya, Anda dapat menggunakan beberapa populasi (anggap sebagai pulau) yang sesekali saling bertukar individu untuk mempertahankan keragaman.
Anda dapat mempelajari lebih lanjut tentang konvergensi prematur dan kesalahan lain dalam machine learning di kursus Monitoring Machine Learning Concepts.
Di sisi lain, crossover dan mutasi yang kuat atau keacakan dalam seleksi dapat menyebabkan solusi bagus tidak ikut bereproduksi. Di sinilah elitisme berperan. Elitisme adalah teknik di mana individu terbaik langsung dibawa ke generasi berikutnya untuk mempertahankan solusi yang baik. Ini membantu memastikan solusi terbaik tidak hilang selama proses evolusi.
Namun, berhati-hatilah jika Anda menggunakan elitisme. Jika elitisme digunakan tanpa keragaman populasi yang cukup tinggi, Anda mungkin berakhir pada konvergensi prematur. Jika masalah bisnis Anda memerlukan teknik elitisme, pastikan untuk memasangkannya dengan fungsi crossover dan mutasi yang cukup kuat serta ukuran populasi yang besar. Pendekatan ini membantu menjaga keseimbangan yang sehat antara eksploitasi solusi yang sudah diketahui dan eksplorasi kemungkinan baru.
Algoritme genetika adalah contoh hebat ilmu data yang mengambil inspirasi dari alam. Algoritme ini menawarkan metode yang kuat untuk menyelesaikan masalah optimisasi kompleks dengan meniru proses seleksi alam.
Jika Anda tertarik pada model lain yang terinspirasi biologi, pelajari jaringan saraf dan teknik deep learning lainnya di Introduction to Deep Learning in Python. Anda juga mungkin tertarik dengan kursus Generative AI Concepts dan AI Ethics dari DataCamp.
Jika Anda terinspirasi untuk mengerjakan proyek dengan data biologis, lihat Analyzing Genomic Data in R atau Biomedical Image Analysis in Python.
Pelajari AI dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
