
Courses
Triển khai và Vòng đời MLOps
4 giờ
11.9K
Lấy cảm hứng từ tiến hóa tự nhiên, GA khám phá không gian lời giải một cách hiệu quả để tìm ra lời giải tối ưu hoặc gần tối ưu, ngay cả với các bài toán phức tạp có nhiều thành phần biến động. Bằng cách mô phỏng quá trình chọn lọc tự nhiên, GA có thể tiến hóa các lời giải theo thời gian, cải thiện hiệu năng một cách lặp.
Thuật toán di truyền được lấy cảm hứng từ quá trình chọn lọc tự nhiên và di truyền học. Chúng mô phỏng cách sinh vật sống tiến hóa qua nhiều thế hệ để thích nghi và tồn tại trong môi trường. Hiểu các nguyên lý sinh học cơ bản đứng sau GA giúp ta nắm được cách các thuật toán này hoạt động và sử dụng chúng chiến lược hơn.
Chọn lọc tự nhiên là quá trình khiến các cá thể có tổ hợp đặc điểm thuận lợi hơn có nhiều khả năng sống sót và sinh sản. Theo thời gian, các đặc điểm có lợi này trở nên phổ biến hơn trong quần thể.
Trong bối cảnh GA, khái niệm này được phản chiếu bằng việc chọn các cá thể có điểm thích nghi cao hơn để sinh sản. Bằng cách đó, chúng truyền các đặc điểm thuận lợi, hay “gen”, sang thế hệ tiếp theo.
Đặc điểm của sinh vật được mã hóa bởi gen. Gen là một phần của DNA, được sắp xếp thành nhiễm sắc thể.
GA vay mượn nhiều khái niệm và thuật ngữ tương tự. Các lời giải tiềm năng cho một bài toán được biểu diễn như “nhiễm sắc thể”, thường được mã hóa dưới dạng chuỗi hoặc mảng. Mỗi phần tử trong nhiễm sắc thể tương ứng với một gen quyết định một đặc trưng cụ thể của lời giải.
Lai ghép, hay tái tổ hợp, là một thao tác di truyền kết hợp các phần vật chất di truyền của hai nhiễm sắc thể bố mẹ thành một nhiễm sắc thể mới chứa các phần của mỗi bên. “Bản phối” nhiễm sắc thể mới này được truyền cho con. Đây là một lý do vì sao bạn có thể mang màu mắt của mẹ và màu tóc của cha.
Trong GA, lai ghép liên quan đến việc trao đổi các đoạn của nhiễm sắc thể bố mẹ để tạo cá thể mới. Thao tác này đưa sự biến thiên vào quần thể và cho phép con cái thừa hưởng đặc điểm có lợi từ cả hai bố mẹ.
Đột biến đưa các thay đổi ngẫu nhiên vào gen của sinh vật, có thể dẫn đến các đặc điểm mới.
Trong thuật toán di truyền, đột biến liên quan đến việc thay đổi ngẫu nhiên một hoặc nhiều gen trong một nhiễm sắc thể. Điều này giúp duy trì đa dạng di truyền trong quần thể và cho phép thuật toán khám phá những vùng mới của không gian lời giải.
Trong tự nhiên, độ thích nghi của một cá thể được xác định bởi khả năng sống sót và sinh sản của nó. Nếu bạn chết trước khi sinh sản, độ thích nghi của bạn là bằng không. Nếu bạn có 12 đứa cháu thì độ thích nghi của bạn sẽ cao hơn người chỉ có 2 đứa cháu.
Trong GA, độ thích nghi tương tự nhưng hơi khác. Một hàm thích nghi đánh giá mức độ một lời giải giải quyết được bài toán. Những lời giải có điểm thích nghi cao hơn có nhiều khả năng được chọn để sinh sản, đảm bảo các lời giải tốt lan truyền qua các thế hệ.
Thuật toán di truyền lấy cảm hứng từ tiến hóa. Do đó, các thành phần của GA có tên gọi và chức năng tương tự với các đối tác sinh học. Mỗi thành phần này thường được lập trình thành một hàm riêng.
Quần thể trong một thuật toán di truyền là tập hợp các lời giải ứng viên, thường gọi là cá thể. Mỗi cá thể được biểu diễn như một nhiễm sắc thể, có thể được mã hóa thành chuỗi nhị phân, mảng, hoặc các cấu trúc dữ liệu khác.
Ví dụ, mỗi nhiễm sắc thể có thể đại diện cho một tập giá trị đầu vào cho một hàm cần tối ưu. Hoặc mỗi nhiễm sắc thể có thể biểu diễn một lộ trình xe tải cho tài xế giao hàng.
Hàm thích nghi đánh giá khả năng giải quyết vấn đề mà chúng ta quan tâm của từng cá thể. Nó gán một giá trị thích nghi cho mỗi cá thể, với giá trị cao hơn ứng với lời giải tốt hơn. Hàm thích nghi dẫn dắt thuật toán tới các lời giải tốt hơn.
Chẳng hạn, trong ví dụ tối ưu hóa hàm toán học, hàm thích nghi có thể trả về giá trị của hàm ứng với các đầu vào cho trước. Với ví dụ lộ trình xe tải, hàm thích nghi có thể trả về tốc độ hoàn tất giao hàng.
Hàm chọn lọc chọn các cá thể trong quần thể để sinh sản dựa trên độ thích nghi của chúng. Cá thể có độ thích nghi cao hơn có nhiều khả năng được chọn hơn. Điều này mô phỏng chọn lọc tự nhiên, nơi các cá thể thích nghi tốt hơn có khả năng sống sót và sinh sản cao hơn.
Có một vài phương pháp chọn lọc khác nhau. Các phương pháp phổ biến gồm chọn lọc vòng quay roulette, chọn lọc đấu giải và chọn lọc dựa trên xếp hạng.
Chọn lọc vòng quay roulette là chọn cá thể dựa trên xác suất tỷ lệ với độ thích nghi của chúng, tương tự như quay bánh roulette.
Trong chọn lọc đấu giải, một tập con cá thể được chọn ngẫu nhiên và cá thể có độ thích nghi cao nhất trong tập này được chọn.
Chọn lọc dựa trên xếp hạng sắp các cá thể theo độ thích nghi. Sau đó xác suất chọn được gán dựa trên thứ hạng thay vì giá trị thích nghi thô.
Mỗi phương pháp có ưu điểm riêng và nên được chọn dựa trên yêu cầu cụ thể của bài toán.
Lai ghép kết hợp thông tin từ hai cá thể để tạo con. Mục tiêu là thừa hưởng các đặc điểm có lợi từ cả hai bố mẹ. Các kỹ thuật lai ghép phổ biến gồm lai ghép một điểm, đa điểm, đều và lai ghép pha trộn.
Lai ghép một điểm chọn một điểm ngẫu nhiên và hoán đổi vật chất di truyền từ hai bố mẹ tại điểm đó để tạo hai con. Lai ghép đa điểm dùng nhiều điểm để hoán đổi các đoạn giữa bố mẹ, cho phép các tổ hợp di truyền phức tạp hơn.
Lai ghép đều quyết định ngẫu nhiên bố mẹ nào sẽ đóng góp mỗi gen, mang lại mức đa dạng di truyền cao. Lai ghép pha trộn tạo con bằng cách pha trộn các gen của bố mẹ với một hệ số pha trộn ngẫu nhiên. Quyết định dùng kỹ thuật nào nên dựa trên độ phức tạp của bài toán và mức đa dạng mong muốn ở thế hệ con.
Đột biến đưa các thay đổi ngẫu nhiên vào vật chất di truyền của con cái. Điều này giúp duy trì đa dạng trong quần thể và khám phá các vùng mới của không gian lời giải. Đột biến có thể đơn giản như lật một bit trong chuỗi nhị phân hoặc liên quan đến thay đổi phức tạp hơn tùy theo sơ đồ mã hóa.
Một thuật toán di truyền trải qua một loạt bước mô phỏng các quá trình tiến hóa tự nhiên để tìm lời giải tối ưu. Những bước này cho phép quần thể tiến hóa qua các thế hệ, cải thiện chất lượng lời giải. Sau đây là hướng dẫn tổng quát về cách một GA vận hành:
Đầu tiên, chúng ta tạo một quần thể ban đầu gồm các cá thể ngẫu nhiên. Bước này tạo ra một tập hợp đa dạng các lời giải tiềm năng để bắt đầu thuật toán.
Tiếp theo, chúng ta cần tính độ thích nghi của mỗi cá thể trong quần thể. Ở đây ta dùng hàm thích nghi để đánh giá mức độ tốt của từng lời giải.
Sử dụng tiêu chí chọn lọc, chúng ta chọn các cá thể để sinh sản dựa trên độ thích nghi của chúng. Bước này xác định những cá thể sẽ làm bố mẹ.
Tiếp đến là lai ghép. Bằng cách kết hợp vật chất di truyền của các bố mẹ đã chọn, chúng ta áp dụng kỹ thuật lai ghép để tạo ra các lời giải mới hay con cái.
Để duy trì đa dạng trong quần thể, chúng ta cần đưa các đột biến ngẫu nhiên vào con cái.
Tiếp theo, chúng ta thay thế một phần hoặc toàn bộ quần thể cũ bằng thế hệ con mới, bằng cách xác định những cá thể nào bước vào thế hệ kế tiếp.
Các bước 2–6 được lặp lại trong một số thế hệ cố định hoặc cho đến khi thỏa điều kiện dừng. Vòng lặp này cho phép quần thể tiến hóa theo thời gian, hy vọng dẫn đến một lời giải tốt.
Giờ khi đã nắm chắc thuật toán di truyền là gì và nhìn chung hoạt động ra sao, hãy xây dựng một GA của riêng mình để giải một bài toán tối ưu đơn giản.
Phương trình y=ax2+bx+c, khi vẽ đồ thị, tạo thành một parabol. Chúng ta sẽ dùng GA để tìm tổ hợp giá trị cho a, b và c sao cho parabol phẳng nhất. Đây là phần xem trước kết quả chúng ta sẽ đạt được:
Ở đầu hàm, chúng ta sẽ nhập các thư viện cần thiết. Chúng ta sẽ dùng ‘random’ để tạo các giá trị ngẫu nhiên cho quần thể khởi đầu. Numpy nói chung rất hữu ích khi làm toán, theo quan điểm của tôi.
Và tôi tin rằng bạn luôn nên vẽ biểu đồ để đảm bảo mã của mình làm đúng như bạn nghĩ. Vì vậy chúng ta sẽ nhập ‘matplotlib.pyplot’ để vẽ một số đồ thị.
Tôi cũng thích in ra các kết quả quan trọng của mỗi thế hệ (giả sử số thế hệ tương đối nhỏ) để hiểu rõ hơn điều gì đã xảy ra trong mô phỏng. Vì vậy chúng ta sẽ nhập ‘PrettyTable’ cho mục đích đó.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableTiếp theo, chúng ta cần định nghĩa hàm thích nghi sẽ đánh giá độ thích nghi của mọi lời giải. Trong trường hợp này, chúng ta muốn tìm đồ thị hình chữ U phẳng nhất. Vì vậy tôi tính giá trị y tại đỉnh và tại x=-1 và x=1.
Sau đó tôi tính độ “cong” của đồ thị là chênh lệch giá trị y tại ba điểm này. Vì chúng ta muốn đường cong phẳng nhất, tôi lấy đối của độ cong để hoàn thiện hàm thích nghi.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessChúng ta sẽ dùng thư viện ‘random’ để tạo một quần thể các lời giải ngẫu nhiên. Mỗi cá thể trong quần thể này là một bộ giá trị cho a, b và c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationHàm chọn lọc sẽ quyết định cá thể nào sinh sản để tạo quần thể kế tiếp. Trong ví dụ này, chúng ta sẽ dùng quá trình chọn lọc đấu giải, nơi một tập con ngẫu nhiên các cá thể trong quần thể được chọn, và các cá thể có độ thích nghi lớn nhất trong tập đó sẽ được chọn để sinh sản.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedTiếp theo, chúng ta sẽ viết một hàm nhanh để dùng lai ghép tạo các lời giải mới dựa trên các lời giải hiện có.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Chúng ta cũng cần một hàm đột biến để đưa tính ngẫu nhiên vào các thế hệ sau. Điều này quan trọng để đảm bảo có đủ đa dạng trong mỗi thế hệ để lựa chọn.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Tiếp theo chúng ta cần tạo vòng lặp chính để ghép tất cả các phần này lại và chạy thuật toán. Vì chúng ta cũng cần vẽ kết quả, tôi sẽ thêm mã vẽ đồ thị trong phần này, cùng với mã cần để tạo bảng cuối cùng.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Cuối cùng, chúng ta cần thiết lập các tham số cho thuật toán và chạy nó.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Trong ví dụ này, chúng ta đặt số thế hệ cụ thể để thuật toán chạy. Tuy nhiên, ta cũng có thể thiết lập điều kiện dừng để dừng chương trình khi đạt tới một giá trị thích nghi mục tiêu. Nó có thể trông như sau:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessDưới đây là toàn bộ mã hoàn chỉnh.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Hãy dùng các đầu ra để xem hàm của chúng ta hoạt động ra sao.
Đầu tiên, ta thấy từ bảng rằng chúng ta đã hoàn thành 20 thế hệ và độ thích nghi dường như tăng từ một giá trị âm tương đối sang âm ít hơn qua mỗi thế hệ. Tuyệt!
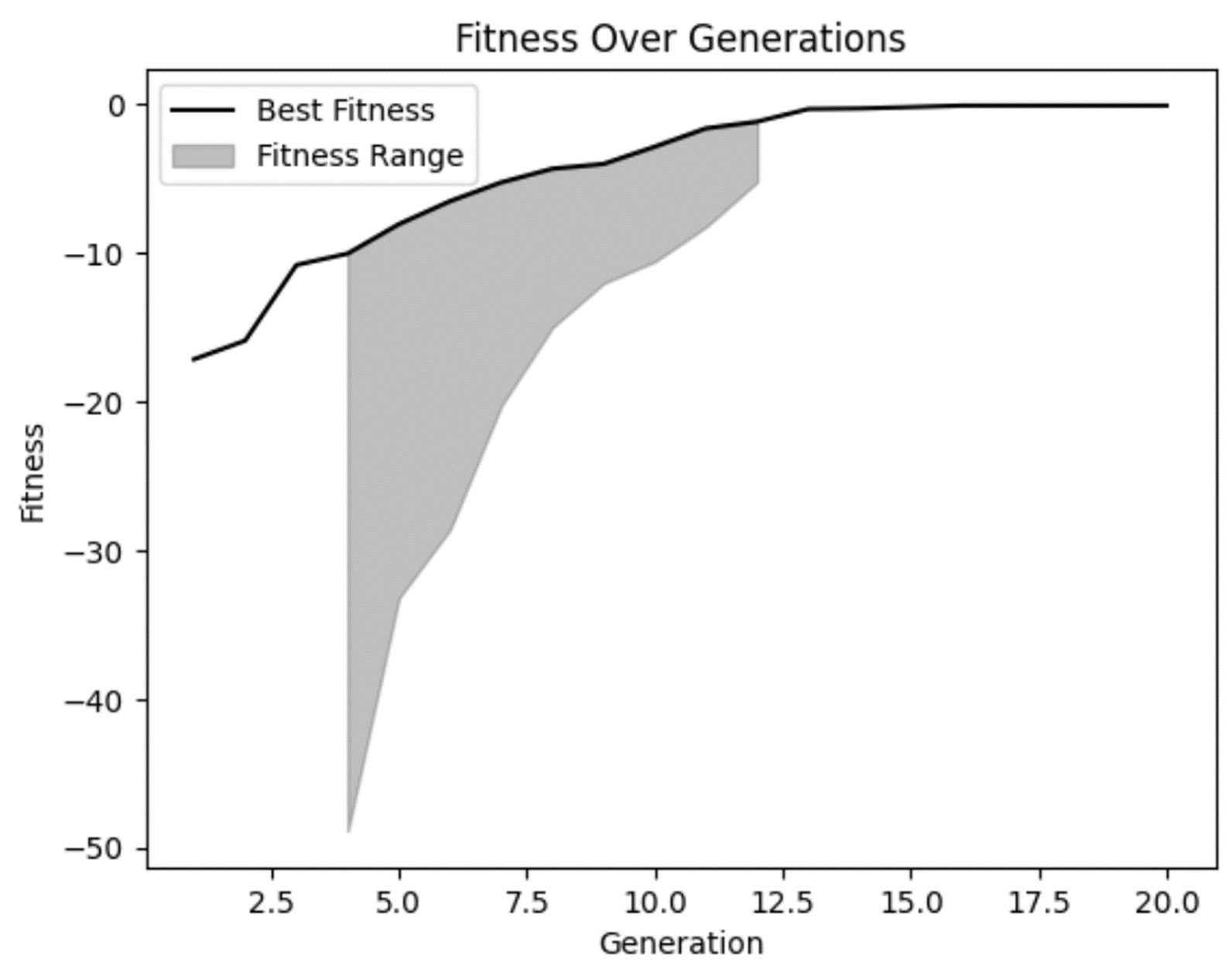
Từ đồ thị độ thích nghi, chúng ta có thể xác nhận nghi ngờ rằng độ thích nghi đã cải thiện theo thời gian và dường như phẳng hơn ở các thế hệ sau. Nhưng ta cũng thấy rằng ở một số thế hệ đầu có những lời giải rất tệ mà mô hình đã đúng khi loại bỏ.
Chúng ta cũng thấy rằng ở vài thế hệ, không có nhiều đa dạng trong phạm vi độ thích nghi. Dù điều đó không nhất thiết là xấu, nhưng cũng cần lưu ý. Trong một số trường hợp, đây có thể là dấu hiệu của hội tụ sớm, vấn đề xảy ra khi quần thể không đủ đa dạng.
Tiếp theo, hãy vẽ các phương trình của mỗi thế hệ để xem chúng ta có thực sự làm phẳng được hay không.
Chúng ta thấy rằng các lời giải ở thế hệ đầu rất cong, điều này hợp lý. Phương trình này tạo đồ thị hình chữ U. Nhưng cũng thấy rằng các thế hệ sau ngày càng phẳng hơn. Đó chính xác là điều chúng ta tìm kiếm!
Cũng đáng lưu ý rằng chúng ta chỉ xem xét trong các giới hạn đặt ra là -50 đến 50. Nếu phóng to phạm vi đồ thị, ta sẽ thấy ngay cả những đường tưởng như phẳng này vẫn là chữ U, chỉ là đáy rộng hơn.
Ví dụ này nhấn mạnh tầm quan trọng của việc thận trọng với các giả định trong phân tích để đảm bảo chúng hỗ trợ các dự đoán của ta. Mô hình đã làm đúng như chúng ta muốn, nhưng chỉ trong phạm vi chúng ta đưa ra. Nếu muốn tìm tổ hợp biến tạo đường phẳng ở xa hơn, ta sẽ cần chạy lại mô hình với giới hạn rộng hơn.
Chúng ta có thể vẽ từng biến để xem chúng thay đổi bao nhiêu qua các thế hệ. Có thể thấy trong lần chạy mô phỏng này, c biến thiên mạnh lúc đầu trong khi a và b thay đổi nhẹ hơn nhiều. Đồ thị này sẽ trông khác mỗi lần chạy mô phỏng, ngay cả khi chúng ta không đổi tham số, vì quần thể khởi đầu là ngẫu nhiên.
Đồ thị cuối cùng tôi muốn xem là ảnh chụp của toàn bộ quần thể trong một thế hệ: thế hệ cuối. Vì mỗi cá thể trong quần thể có ba tham số, tôi quyết định tách chúng thành ba biểu đồ con thay vì loay hoay với đồ thị 3 chiều.
Điều tôi thực sự muốn thấy từ các đồ thị này là liệu có đủ đa dạng trong thế hệ này không. Nếu không có mức đa dạng đủ tốt, ta có thể rơi vào tình huống chỉ có các lời giải với giá trị thích nghi thấp, dẫn đến hội tụ sớm. Nhưng có vẻ đồ thị này cho thấy mức đa dạng tốt, nên tôi hài lòng với kết quả này.
Thuật toán di truyền có thể được dùng trong rất nhiều tình huống. Nhưng có vài điểm cần ghi nhớ.
Như với mọi mô hình, hiệu năng của GA phụ thuộc vào nhiều tham số, đáng chú ý là kích thước quần thể, tỉ lệ lai ghép, tỉ lệ đột biến và các tham số giới hạn. Thay đổi các tham số này sẽ thay đổi cách mô hình của bạn vận hành.
Như một quy tắc ngón tay cái, quần thể lớn hơn sẽ giúp bạn tìm lời giải tối ưu nhanh hơn vì có nhiều lựa chọn hơn. Tuy nhiên, quần thể lớn hơn cũng đòi hỏi nhiều thời gian và tài nguyên để chạy.
Tỉ lệ lai ghép cao hơn có thể dẫn đến hội tụ nhanh hơn bằng cách kết hợp các đặc điểm có lợi từ các cá thể khác nhau thường xuyên hơn. Tuy nhiên, tỉ lệ lai ghép quá cao có thể phá vỡ cấu trúc quần thể, dẫn đến hội tụ sớm.
Tỉ lệ đột biến cao hơn giúp duy trì đa dạng di truyền, ngăn thuật toán mắc kẹt tại cực trị cục bộ. Tuy nhiên, nếu tỉ lệ đột biến quá cao, nó có thể phá vỡ quá trình hội tụ bằng cách đưa quá nhiều ngẫu nhiên, khiến thuật toán khó tinh chỉnh lời giải.
Các tham số giới hạn xác định phạm vi trong đó thuật toán tìm kiếm lời giải. Chúng quan trọng để điều chỉnh theo bài toán kinh doanh cụ thể của bạn. Phạm vi quá hẹp có thể bỏ lỡ lời giải tối ưu. Phạm vi quá rộng sẽ tốn nhiều thời gian và tài nguyên để chạy. Nhưng còn các yếu tố khác nữa.
Chẳng hạn, trong ví dụ mã ở trên, phương trình đó về lý thuyết là không giới hạn. Nhưng trên thực tế, chúng ta không thể yêu cầu máy tính tìm cung phẳng nhất trên một đồ thị vô hạn. Vì vậy, ranh giới là cần thiết. Nhưng thay đổi ranh giới cũng sẽ làm thay đổi đáp án tối ưu. Theo ý tôi, việc thiết lập ranh giới phù hợp cho trường hợp sử dụng cụ thể của bạn là điều bắt buộc với bất kỳ mô hình nào.
Có thể còn những tham số quan trọng khác cần điều chỉnh trong mô hình của bạn. Hãy thử nghiệm với các giá trị khác nhau để tìm thiết lập tốt nhất cho vấn đề của bạn. Để tìm hiểu về điều chỉnh GA cụ thể, hãy xem Phương pháp có thông tin: Thuật toán Di truyền.
Mã hóa là bước quan trọng khi thiết lập một GA. Nó liên quan đến việc chuyển các lời giải tiềm năng sang định dạng mà thuật toán có thể xử lý. Ví dụ, giả sử chúng ta đang thiết kế một GA để tối ưu lộ trình giao hàng cho xe tải. Làm sao bạn biến danh sách địa điểm giao hàng thành một nhiễm sắc thể để đưa vào GA? Mã hóa sẽ chuyển danh sách này thành một chuỗi mà thuật toán có thể thao tác, chẳng hạn như danh sách sắp thứ tự các điểm thể hiện một lộ trình giao hàng khả dĩ.
Mã hóa phù hợp đảm bảo GA có thể khám phá hiệu quả không gian lời giải và kết hợp hay đột biến lời giải một cách có ý nghĩa. Không có nó, thuật toán sẽ không thể xử lý dữ liệu phức tạp. Dữ liệu như địa điểm giao hàng, bài toán lập lịch hay tương tác dịch vụ khách hàng chỉ có thể truy cập được với máy tính thông qua mã hóa.
Có một số sơ đồ mã hóa để lựa chọn. Bạn có thể tìm hiểu thêm để quyết định cái nào phù hợp nhất cho tình huống của mình tại Làm việc với dữ liệu phân loại trong Python hoặc Cách chuyển chuỗi thành bytes trong Python.
Hội tụ sớm là vấn đề xảy ra khi quần thể trở nên quá giống nhau. Điều này có thể khiến thuật toán mắc kẹt tại cực trị cục bộ thay vì tìm cực trị toàn cục. Về cơ bản, nếu quần thể không đủ đa dạng, các lời giải trở nên “cận huyết” và bạn không nhận được lời giải tốt nhất.
Có một vài kỹ thuật bạn có thể thử để tránh hội tụ sớm. Tỉ lệ đột biến cao hơn có thể đưa thêm đa dạng vào quần thể, giúp khám phá các vùng mới của không gian lời giải. Bạn cũng có thể bắt đầu với một quần thể khởi đầu đa dạng hơn để đảm bảo khám phá rộng từ đầu.
Nếu vẫn gặp hội tụ sớm, bạn có thể thử điều chỉnh động các tham số như tỉ lệ đột biến và lai ghép dựa trên tiến độ của thuật toán. Ngoài ra, bạn có thể dùng nhiều quần thể (nghĩ như các hòn đảo) đôi khi trao đổi cá thể để duy trì đa dạng.
Bạn có thể tìm hiểu thêm về hội tụ sớm và các sai lầm học máy khác trong khóa học Giám sát các khái niệm Học máy.
Mặt khác, lai ghép và đột biến mạnh hoặc bất kỳ sự ngẫu nhiên nào trong chọn lọc có thể khiến các lời giải tốt không được sinh sản. Khi đó chủ nghĩa tinh anh có thể hữu ích. Elitism là kỹ thuật trong đó các cá thể tốt nhất được chuyển thẳng sang thế hệ kế tiếp để bảo toàn lời giải tốt. Điều này giúp đảm bảo các lời giải tốt nhất không bị mất trong quá trình tiến hóa.
Tuy nhiên, hãy thận trọng nếu dùng elitism. Nếu áp dụng elitism mà không có đủ đa dạng quần thể, bạn có thể rơi vào hội tụ sớm. Nếu bài toán kinh doanh của bạn cần kỹ thuật elitism, hãy ghép nó với các hàm lai ghép và đột biến đủ mạnh và kích thước quần thể lớn. Cách tiếp cận này giúp duy trì cân bằng lành mạnh giữa khai thác các lời giải đã biết và khám phá khả năng mới.
Thuật toán di truyền là một ví dụ tuyệt vời về khoa học dữ liệu lấy cảm hứng từ tự nhiên. Chúng cung cấp một phương pháp mạnh mẽ để giải các bài toán tối ưu hóa phức tạp bằng cách mô phỏng quá trình chọn lọc tự nhiên.
Nếu bạn quan tâm đến các mô hình lấy cảm hứng từ sinh học khác, hãy tìm hiểu mạng nơ-ron và các kỹ thuật học sâu khác trong Nhập môn Học sâu trong Python. Bạn cũng có thể quan tâm tới khóa học Khái niệm AI tạo sinh và Đạo đức AI của DataCamp.
Nếu bạn được truyền cảm hứng để làm một dự án với dữ liệu sinh học, hãy xem Phân tích dữ liệu hệ gen trong R hoặc Phân tích ảnh y sinh trong Python.
Học AI với những khóa học này!
Courses
Courses
Courses