
Corso
Deployment e ciclo di vita in MLOps
4 h
11.9K
Ispirati all'evoluzione naturale, i GA esplorano in modo efficiente lo spazio delle soluzioni per scoprire soluzioni ottimali o quasi ottimali, anche per problemi complessi con molte parti in gioco. Imitando il processo di selezione naturale, i GA possono far evolvere le soluzioni nel tempo, migliorandone iterativamente le prestazioni.
Gli algoritmi genetici sono stati ispirati dal processo di selezione naturale e dalla genetica. Imitano il modo in cui gli organismi viventi evolvono nel corso delle generazioni per adattarsi e sopravvivere nei loro ambienti. Capire i principi biologici di base alla base dei GA può aiutarci a comprendere come funzionano questi algoritmi e ad usarli in modo più strategico.
La selezione naturale è il processo per cui gli individui con combinazioni migliori di tratti favorevoli hanno maggiori probabilità di sopravvivere e riprodursi. Nel tempo, questi tratti vantaggiosi diventano più comuni nella popolazione.
Nel contesto dei GA, questo concetto si riflette selezionando per la riproduzione gli individui con punteggi di fitness più alti. In questo modo, trasmettono i loro tratti favorevoli, o "geni", alla generazione successiva.
I tratti di un organismo biologico sono codificati dai suoi geni. I geni fanno parte del DNA, che è organizzato in cromosomi.
I GA prendono in prestito molti degli stessi concetti e della stessa terminologia. Le soluzioni potenziali a un problema sono rappresentate come "cromosomi", in genere codificati come stringhe o array. Ogni elemento del cromosoma corrisponde a un gene che determina uno specifico tratto della soluzione.
Il crossover, o ricombinazione, è un'operazione genetica che combina parti del materiale genetico di due cromosomi genitori in un nuovo cromosoma che contiene parti di ciascun genitore. Questo nuovo mix di cromosoma viene trasmesso al figlio. È uno dei motivi per cui puoi avere il colore degli occhi di tua madre e il colore dei capelli di tuo padre.
Nei GA, il crossover consiste nello scambiare segmenti dei cromosomi dei genitori per creare nuovi individui. Questa operazione introduce variabilità e consente alla prole di ereditare tratti vantaggiosi da entrambi i genitori.
La mutazione introduce cambiamenti casuali nei geni di un organismo, che possono portare a nuovi tratti.
Negli algoritmi genetici, la mutazione consiste nell'alterare casualmente uno o più geni in un cromosoma. Questo aiuta a mantenere la diversità genetica all'interno della popolazione e consente all'algoritmo di esplorare nuove aree dello spazio delle soluzioni.
In natura, la fitness di un individuo è determinata dalla sua capacità di sopravvivere e riprodursi. Se muori prima di riprodurti, hai una fitness pari a zero. Se hai 12 nipoti la tua fitness sarà più alta rispetto a qualcuno che ne ha 2.
Nei GA, la fitness è simile, ma un po' diversa. Una funzione di fitness valuta quanto bene una soluzione risolve il problema in questione. Le soluzioni con punteggi di fitness più elevati hanno maggiori probabilità di essere selezionate per la riproduzione, assicurando che soluzioni migliori si propaghino attraverso le generazioni.
Gli algoritmi genetici sono stati ispirati dall'evoluzione. Di conseguenza, i componenti di un GA condividono nomi e funzioni simili a quelli delle loro controparti biologiche. Ognuno di questi componenti è di solito codificato come una propria funzione.
La popolazione in un algoritmo genetico è un insieme di soluzioni candidate, spesso chiamate individui. Ogni individuo è rappresentato come un cromosoma, che può essere codificato come stringhe binarie, array o altre strutture dati.
Per esempio, ogni cromosoma potrebbe rappresentare un insieme di valori di input per una funzione che dobbiamo ottimizzare. Oppure ogni cromosoma potrebbe rappresentare un percorso per i camion delle consegne.
La funzione di fitness valuta la capacità di ciascun individuo di risolvere il problema di nostro interesse. Assegna a ogni individuo un valore di fitness, con valori più alti per soluzioni migliori. La funzione di fitness guida l'algoritmo verso soluzioni migliori.
Ad esempio, nel nostro caso di ottimizzazione di una funzione matematica, la funzione di fitness potrebbe restituire il valore della funzione per gli input dati. Per il nostro esempio dei percorsi dei camion, la funzione di fitness potrebbe restituire la velocità di completamento delle consegne.
La funzione di selezione sceglie gli individui della popolazione che si riprodurranno in base alla loro fitness. Gli individui con fitness più alta hanno maggiori probabilità di essere scelti per la riproduzione. Questo imita la selezione naturale, dove gli individui meglio adattati hanno più probabilità di sopravvivere e riprodursi.
Esistono diversi metodi di selezione. I metodi più comuni includono la selezione a ruota della roulette, la selezione a torneo e la selezione basata sul rango.
Nella selezione a ruota della roulette gli individui sono selezionati in base a una probabilità proporzionale alla loro fitness, in modo simile a far girare una roulette.
Nella selezione a torneo si sceglie casualmente un sottoinsieme di individui e si seleziona l'individuo con la fitness più alta in questo sottoinsieme.
La selezione basata sul rango classifica gli individui in base alla loro fitness. Poi le probabilità di selezione sono assegnate in base a questi ranghi invece che ai valori di fitness grezzi.
Ogni metodo ha i suoi vantaggi e andrebbe scelto in base alle esigenze specifiche del problema da affrontare.
Il crossover combina le informazioni di due individui per creare discendenti. L'obiettivo è ereditare tratti vantaggiosi da entrambi i genitori. Le tecniche di crossover comuni includono il crossover a punto singolo, multi-punto, uniforme e blend.
Il crossover a punto singolo prevede la scelta di un punto casuale e lo scambio del materiale genetico di due genitori in quel punto per creare due figli. Il crossover multi-punto usa più punti per scambiare segmenti tra genitori, permettendo combinazioni genetiche più complesse.
Il crossover uniforme decide casualmente quale genitore contribuirà con ciascun gene, fornendo un alto livello di diversità genetica. Il crossover blend genera discendenti mescolando i geni dei genitori usando un fattore di mescolamento casuale. La scelta della tecnica dovrebbe basarsi sulla complessità del problema e sul livello di diversità desiderato nella prole.
La mutazione introduce cambiamenti casuali nel materiale genetico dei discendenti. Questo aiuta a mantenere la diversità nella popolazione ed esplorare nuove aree dello spazio delle soluzioni. Le mutazioni possono essere semplici come invertire un bit in una stringa binaria o comportare cambiamenti più complessi a seconda dello schema di codifica.
Un algoritmo genetico attraversa una serie di passaggi che imitano i processi evolutivi naturali per trovare soluzioni ottimali. Questi passaggi permettono alla popolazione di evolversi nel corso delle generazioni, migliorando la qualità delle soluzioni. Ecco una linea guida generale su come procede un algoritmo genetico:
Per prima cosa, generiamo una popolazione iniziale di individui casuali. Questo passaggio crea un insieme diversificato di possibili soluzioni per avviare l'algoritmo.
Successivamente, dobbiamo calcolare la fitness di ciascun individuo nella popolazione. Qui usiamo la funzione di fitness per valutare quanto è buona ogni soluzione.
Usando i criteri di selezione, selezioniamo gli individui per la riproduzione in base alla loro fitness. Questo passaggio determina chi saranno i genitori.
Segue il crossover. Combinando il materiale genetico dei genitori selezionati, applichiamo tecniche di crossover per generare nuove soluzioni o discendenti.
Per mantenere la diversità nella nostra popolazione, dobbiamo introdurre mutazioni casuali nella prole.
Poi sostituiamo parte o tutta la vecchia popolazione con la nuova prole, determinando quali individui passano alla generazione successiva.
I passaggi 2-6 precedenti vengono ripetuti per un certo numero di generazioni o fino al verificarsi di una condizione di terminazione. Questo ciclo consente alla popolazione di evolversi nel tempo, auspicabilmente portando a una buona soluzione.
Ora che abbiamo una buona comprensione di cosa sono gli algoritmi genetici e in generale come funzionano, costruiamo il nostro algoritmo genetico per risolvere un semplice problema di ottimizzazione.
L'equazione y=ax2+bx+c, quando tracciata, crea una parabola. Useremo un algoritmo genetico per trovare la combinazione di valori di a, b e c che risulti nella parabola più piatta. Ecco un'anteprima di ciò che otterremo:
All'inizio della nostra funzione, importeremo le librerie necessarie. Useremo 'random' per generare valori casuali per la nostra popolazione iniziale. Numpy è in generale utile quando si fa matematica, secondo me.
E sono fermamente convinta che dovresti sempre fare grafici per assicurarti che il tuo codice stia facendo ciò che pensi stia facendo. Quindi importeremo 'matplotlib.pyplot' per creare alcuni grafici.
Mi piace anche stampare i risultati importanti di ogni generazione (supponendo un numero relativamente piccolo di generazioni) per capire meglio cosa è successo durante la simulazione. Quindi importeremo 'PrettyTable' per questo.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableSuccessivamente dobbiamo definire la funzione di fitness che valuterà la fitness di ogni soluzione. In questo caso, vogliamo trovare la forma a U più piatta tracciata. Quindi ho calcolato il valore y al vertice e a x=-1 e x=1.
Poi ho calcolato la curvatura del grafico come differenza nel valore di y in questi tre punti. Poiché vogliamo ottenere la curva più piatta, ho negato la curvatura per completare la funzione di fitness.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessUseremo la libreria 'random' per generare una popolazione di soluzioni casuali. Ogni individuo in questa popolazione è un insieme di valori per a, b e c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationLa funzione di selezione determinerà quali individui si riproducono per creare la prossima popolazione. In questo esempio, useremo un processo di selezione a torneo, in cui si prende un sottoinsieme casuale di individui della popolazione e si selezionano per la riproduzione gli individui con la fitness più alta all'interno di quel sottoinsieme.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedOra scriveremo una rapida funzione per usare il crossover e creare nuove soluzioni a partire da soluzioni esistenti.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Abbiamo anche bisogno di una funzione di mutazione per introdurre casualità nelle generazioni successive. Questo è importante per garantire che in ogni generazione ci sia abbastanza diversità da cui selezionare.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Ora dobbiamo creare il ciclo principale che metterà insieme tutti questi pezzi per eseguire il nostro algoritmo. Poiché dobbiamo anche tracciare i risultati, aggiungerò in questa sezione il codice per i grafici, così come il codice necessario per creare la nostra tabella finale.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Infine, dobbiamo impostare i parametri per il nostro algoritmo ed eseguirlo.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")In questo esempio, abbiamo impostato un numero specifico di generazioni per l'esecuzione del nostro algoritmo. Tuttavia, avremmo potuto in alternativa impostare una condizione di terminazione che interrompesse il programma al raggiungimento di un valore di fitness target. Potrebbe essere qualcosa del genere:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessEcco il codice completo tutto insieme.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Usiamo i nostri output per vedere come si è comportata la nostra funzione.
Per prima cosa, dalla tabella vediamo che abbiamo completato 20 generazioni e la fitness sembra essere aumentata da un valore relativamente negativo a uno meno negativo a ogni generazione. Ottimo!
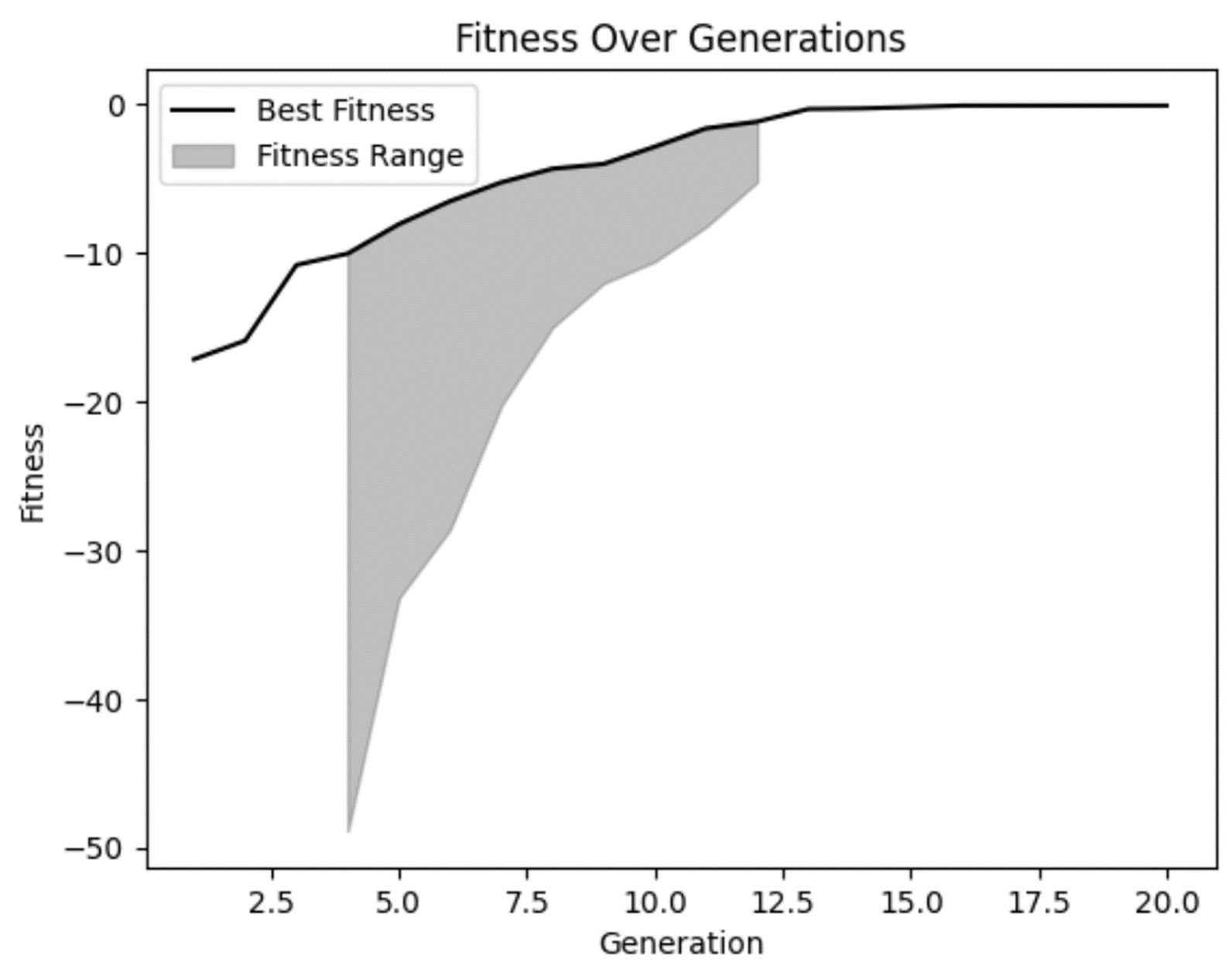
Dal nostro grafico della fitness, possiamo confermare il sospetto che la fitness è migliorata nel tempo e sembra essersi appiattita un po' nelle generazioni successive. Ma possiamo anche vedere che in alcune delle prime generazioni ci sono state soluzioni davvero pessime che il nostro modello ha giustamente scartato.
Possiamo anche notare che in diverse generazioni non c'era molta diversità nell'intervallo di fitness. Anche se non è necessariamente un male, è qualcosa da tenere d'occhio. In alcuni casi, questo può essere un indicatore di convergenza prematura, un problema che si verifica quando non c'è abbastanza diversità nella popolazione.
Successivamente, tracciamo le nostre equazioni di ogni generazione per vedere se le abbiamo davvero appiattite.
Possiamo vedere che le soluzioni delle prime generazioni sono molto curve, il che ha senso. Questa equazione produce un grafico a forma di U. Ma possiamo anche vedere che le generazioni successive sono diventate via via più piatte. È esattamente ciò che stavamo cercando!
Vale la pena notare che stiamo esplicitamente guardando solo entro i nostri limiti dichiarati di -50 - 50. Se ingrandissimo questo grafico, mostrerebbe che anche queste linee apparentemente piatte sono ancora forme a U, solo con basi più ampie.
Questo esempio evidenzia l'importanza di essere cauti con le nostre assunzioni nelle analisi per assicurarci che supportino le nostre previsioni. Il nostro modello ha fatto esattamente ciò che volevamo, ma solo entro i limiti che gli abbiamo dato. Se volessimo trovare una combinazione di variabili che crei una forma piatta più lontano, dovremmo rieseguire il modello con limiti più ampi.
Possiamo tracciare ciascuna delle variabili per vedere quanto sono cambiate attraverso le generazioni. Possiamo vedere che in questa esecuzione della simulazione, c è variata moltissimo all'inizio mentre a e b sono cambiati molto meno. Questo grafico avrà un aspetto diverso ogni volta che eseguiamo questa simulazione, anche se non cambiamo alcun parametro, perché la nostra popolazione iniziale è casuale.
L'ultimo grafico che voglio guardare è solo un'istantanea dell'intera popolazione in una generazione: l'ultima generazione. Poiché ogni individuo nella popolazione ha tre parametri, ho deciso di separarli in tre sottografi invece di mettermi a trafficare con grafici tridimensionali.
Quello che voglio davvero vedere da questi grafici è se c'è una buona diversità all'interno di questa generazione. Senza una buona quantità di diversità, potremmo finire in una situazione in cui le uniche soluzioni disponibili sono quelle con valori di fitness bassi, con conseguente convergenza prematura. Ma sembra che questi grafici mostrino una buona quantità di diversità, quindi sono soddisfatta di questo risultato.
Gli algoritmi genetici possono essere usati in un'ampia varietà di situazioni. Ma ci sono alcune considerazioni da tenere a mente.
Come per qualsiasi modello, le prestazioni di un algoritmo genetico dipendono da vari parametri, in particolare dimensione della popolazione, tasso di crossover, tasso di mutazione e parametri di delimitazione. Cambiare questi parametri cambierà le prestazioni del tuo modello.
Come regola generale, dimensioni maggiori della popolazione ti aiuteranno a trovare più rapidamente la soluzione ottimale perché ci sono più opzioni tra cui scegliere. Tuttavia, popolazioni più grandi richiedono anche più tempo e risorse per l'esecuzione.
Un tasso di crossover più alto può portare a una convergenza più rapida combinando più frequentemente tratti vantaggiosi di individui diversi. Tuttavia, un tasso di crossover troppo alto potrebbe disturbare la struttura della popolazione, portando a convergenza prematura.
Un tasso di mutazione più alto aiuta a mantenere la diversità genetica, impedendo all'algoritmo di bloccarsi in un ottimo locale. Tuttavia, se il tasso di mutazione è troppo alto, può disturbare il processo di convergenza introducendo troppa casualità, rendendo difficile per l'algoritmo affinare le soluzioni.
I parametri di delimitazione definiscono l'intervallo entro cui l'algoritmo cerca le soluzioni. È importante sintonizzarli sul tuo specifico problema di business. Un'area di delimitazione troppo stretta può far perdere soluzioni ottimali al tuo problema. Un'area di delimitazione troppo ampia richiederà più tempo e risorse per l'esecuzione. Ma ci sono anche altre considerazioni.
Per esempio, nel nostro esempio codificato sopra, quell'equazione teoricamente non ha limiti. Ma praticamente, non possiamo chiedere al computer di trovare l'arco più piatto in un grafico infinitamente grande. Quindi, i confini sono necessari. Ma cambiare quei confini cambierà anche la risposta ottimale. A mio avviso, stabilire confini appropriati per il tuo caso d'uso specifico è fondamentale con qualsiasi modello.
Potrebbero esserci altri parametri importanti da sintonizzare nel tuo modello specifico. Sperimenta con valori diversi per trovare le impostazioni migliori per il tuo problema. Per imparare a fare tuning dei GA nello specifico, dai un'occhiata a Metodi informati: algoritmi genetici.
L'encoding è un passaggio importante nell'impostazione di un algoritmo genetico. Comporta la conversione delle soluzioni potenziali in un formato che l'algoritmo può elaborare. Per esempio, supponiamo di progettare un algoritmo genetico per ottimizzare i percorsi di consegna dei nostri camion. Come trasformi un elenco di luoghi di consegna in un cromosoma da inserire in un GA? L'encoding trasforma questo elenco in una sequenza che l'algoritmo può manipolare, come un elenco ordinato di luoghi che rappresenta un possibile percorso di consegna.
Un encoding appropriato garantisce che l'algoritmo genetico possa esplorare efficacemente lo spazio delle soluzioni e combinare o mutare le soluzioni in modi significativi. Senza di esso, l'algoritmo non sarebbe in grado di gestire dati complessi. Dati come luoghi di consegna, problemi di pianificazione o interazioni con i clienti sono resi accessibili ai computer solo tramite encoding.
Esistono diversi schemi di encoding tra cui scegliere. Puoi saperne di più per decidere quale potrebbe essere il migliore per la tua situazione in Lavorare con dati categorici in Python o Come convertire stringhe in byte in Python.
La convergenza prematura è un problema che si verifica quando la popolazione diventa troppo simile. Questo può portare l'algoritmo a bloccarsi in un ottimo locale invece di trovare l'ottimo globale. In sostanza, se non c'è abbastanza diversità nella popolazione, le soluzioni diventano “consanguinee” e non ottieni la soluzione migliore.
Ci sono alcune tecniche che puoi provare per evitare la convergenza prematura. Un tasso di mutazione più alto può introdurre più diversità nella popolazione, aiutando a esplorare nuove aree dello spazio delle soluzioni. Puoi anche provare a partire con una popolazione iniziale più diversificata per garantire un'ampia esplorazione dello spazio delle soluzioni fin dall'inizio.
Se hai ancora a che fare con la convergenza prematura, puoi provare ad adattare dinamicamente parametri come tasso di mutazione e tasso di crossover in base all'avanzamento dell'algoritmo. In alternativa, puoi usare più popolazioni (pensale come isole) che occasionalmente si scambiano individui per mantenere la diversità.
Puoi saperne di più sulla convergenza prematura e su altri passi falsi nel machine learning nel corso Monitoring Machine Learning Concepts.
D'altra parte, un crossover e una mutazione forti o qualsiasi casualità nella selezione possono far sì che ottime soluzioni non finiscano per riprodursi. È qui che può entrare in gioco l'elitismo. L'elitismo è una tecnica in cui i migliori individui vengono trasferiti direttamente alla generazione successiva per preservare le buone soluzioni. Questo aiuta a garantire che le migliori soluzioni non vadano perse durante il processo evolutivo.
Tuttavia, fai attenzione se usi l'elitismo. Se l'elitismo è usato senza una diversità della popolazione sufficientemente alta, potresti finire invece con una convergenza prematura. Se il tuo problema di business richiede tecniche di elitismo, assicurati di abbinarle a funzioni di crossover e mutazione abbastanza forti e a una popolazione numerosa. Questo approccio aiuta a mantenere un sano equilibrio tra lo sfruttamento delle soluzioni note e l'esplorazione di nuove possibilità.
Gli algoritmi genetici sono un ottimo esempio di data science che trae ispirazione dal mondo naturale. Offrono un metodo potente per risolvere problemi complessi di ottimizzazione imitando il processo di selezione naturale.
Se ti interessano altri modelli ispirati alla biologia, scopri le reti neurali e altre tecniche di deep learning in Introduzione al deep learning in Python. Potrebbero anche interessarti il corso sui concetti di AI generativa di DataCamp e AI Ethics.
Se sei ispiratə a fare un progetto con dati biologici, dai un'occhiata a Analizzare dati genomici in R o Analisi di immagini biomediche in Python.
Impara l'AI con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

