
Cursus
MLOps-deployments en levenscyclus
4 Hr
11.9K
Geïnspireerd door natuurlijke evolutie verkennen GA’s efficiënt de oplossingsruimte om optimale of bijna-optimale oplossingen te vinden, zelfs voor complexe problemen met veel bewegende delen. Door het proces van natuurlijke selectie na te bootsen, kunnen GA’s oplossingen in de tijd laten evolueren en hun prestaties iteratief verbeteren.
Genetische algoritmen zijn geïnspireerd door het proces van natuurlijke selectie en genetica. Ze bootsen na hoe levende organismen over generaties evolueren om zich aan te passen en te overleven in hun omgeving. Inzicht in de basisprincipes van de biologie achter GA’s helpt ons te begrijpen hoe deze algoritmen werken en ze strategischer in te zetten.
Natuurlijke selectie is het proces waardoor individuen met betere combinaties van gunstige eigenschappen meer kans hebben om te overleven en zich voort te planten. Na verloop van tijd worden deze voordelige eigenschappen steeds vaker in de populatie aangetroffen.
In de context van GA’s komt dit terug in het selecteren van individuen met hogere fitnessscores voor reproductie. Zo geven ze hun gunstige eigenschappen, of “genen”, door aan de volgende generatie.
De eigenschappen van een biologisch organisme worden gecodeerd door zijn genen. Genen maken deel uit van DNA, dat is gerangschikt in chromosomen.
GA’s lenen veel van dezelfde concepten en terminologie. Potentiële oplossingen voor een probleem worden voorgesteld als “chromosomen”, die meestal worden gecodeerd als strings of arrays. Elk element in het chromosoom komt overeen met een gen dat een specifieke eigenschap van de oplossing bepaalt.
Crossover, of recombinatie, is een genetische bewerking die delen van het genetisch materiaal van twee ouderchromosomen combineert tot een nieuw chromosoom met delen van beide ouders. Deze nieuwe mix van chromosomen wordt doorgegeven aan het kind. Het is een van de redenen waarom je de oogkleur van je moeder en de haarkleur van je vader kunt hebben.
In GA’s houdt crossover in dat segmenten van de ouderchromosomen worden uitgewisseld om nieuwe individuen te creëren. Deze bewerking introduceert variatie en maakt het mogelijk dat nakomelingen voordelige eigenschappen van beide ouders erven.
Mutatie introduceert willekeurige veranderingen in de genen van een organisme, wat kan leiden tot nieuwe eigenschappen.
In genetische algoritmen houdt mutatie in dat één of meer genen in een chromosoom willekeurig worden gewijzigd. Dit helpt de genetische diversiteit binnen de populatie te behouden en stelt het algoritme in staat nieuwe gebieden van de oplossingsruimte te verkennen.
In de natuur wordt de fitness van een individu bepaald door zijn vermogen om te overleven en zich voort te planten. Als je sterft voordat je je voortplant, is je fitness nul. Als je 12 kleinkinderen hebt, is je fitness hoger dan die van iemand met 2 kleinkinderen.
In GA’s lijkt fitness hierop, maar is het net iets anders. Een fitnessfunctie beoordeelt hoe goed een oplossing het betreffende probleem oplost. Oplossingen met hogere fitnessscores hebben meer kans om geselecteerd te worden voor reproductie, waardoor betere oplossingen zich over generaties verspreiden.
Genetische algoritmen zijn geïnspireerd door evolutie. Bijgevolg hebben de componenten van een GA namen en functies die lijken op die van hun biologische tegenhangers. Elk van deze componenten wordt meestal als eigen functie gecodeerd.
De populatie in een genetisch algoritme is een set van kandidaatoplossingen, vaak individuen genoemd. Elk individu wordt weergegeven als een chromosoom, dat kan worden gecodeerd als binaire strings, arrays of andere datastructuren.
Zo kan elk chromosoom een set invoerwaarden vertegenwoordigen voor een functie die we moeten optimaliseren. Of elk chromosoom kan een vrachtroute vertegenwoordigen voor bezorgers.
De fitnessfunctie beoordeelt het vermogen van elk individu om het probleem waarin we geïnteresseerd zijn op te lossen. Ze kent een fitnesswaarde toe aan elk individu, met hogere waarden voor betere oplossingen. De fitnessfunctie stuurt het algoritme in de richting van betere oplossingen.
In ons voorbeeld van het optimaliseren van een wiskundige functie kan de fitnessfunctie bijvoorbeeld de waarde van de functie voor de gegeven inputs teruggeven. Voor ons voorbeeld met vrachtroutes kan de fitnessfunctie de snelheid van het afronden van de bezorging teruggeven.
De selectiefunctie kiest individuen uit de populatie om zich voort te planten op basis van hun fitness. Individuen met een hogere fitness worden vaker gekozen voor reproductie. Dit bootst natuurlijke selectie na, waarbij de best aangepaste individuen meer kans hebben om te overleven en zich voort te planten.
Er zijn verschillende selectiemethoden. Veelgebruikte methoden zijn roulettewielselectie, toernooiselectie en rangordeselectie.
Bij roulettewielselectie worden individuen geselecteerd op basis van een kans die evenredig is aan hun fitness, vergelijkbaar met het draaien aan een roulettewiel.
Bij toernooiselectie wordt willekeurig een subset van individuen gekozen en het fitste individu uit deze subset wordt geselecteerd.
Rangordeselectie rangschikt individuen op basis van hun fitness. Vervolgens worden selectieprobabiliteiten toegekend op basis van deze rangen in plaats van op ruwe fitnesswaarden.
Elke methode heeft zijn eigen voordelen en moet worden gekozen op basis van de specifieke eisen van het probleem.
Crossover combineert informatie van twee individuen om nakomelingen te creëren. Het doel is om gunstige eigenschappen van beide ouders te erven. Veelgebruikte crossovertechnieken zijn single-point crossover, multi-point crossover, uniforme crossover en blend-crossover.
Single-point crossover houdt in dat een willekeurig punt wordt gekozen en het genetisch materiaal van twee ouders op dat punt wordt verwisseld om twee nakomelingen te creëren. Multi-point crossover gebruikt meerdere punten om segmenten tussen ouders te wisselen, waardoor complexere genetische combinaties mogelijk zijn.
Uniforme crossover beslist willekeurig welke ouder elk gen zal bijdragen, wat zorgt voor een hoge mate van genetische diversiteit. Blend-crossover genereert nakomelingen door de genen van de ouders te mengen met behulp van een willekeurige mengfactor. De keuze voor een techniek moet worden gebaseerd op de complexiteit van het probleem en het gewenste niveau van diversiteit bij de nakomelingen.
Mutatie introduceert willekeurige veranderingen in het genetisch materiaal van de nakomelingen. Dit helpt de diversiteit in de populatie te behouden en nieuwe gebieden van de oplossingsruimte te verkennen. Mutaties kunnen zo eenvoudig zijn als het flippen van een bit in een binaire string, of complexer zijn afhankelijk van het coderingsschema.
Een genetisch algoritme doorloopt een reeks stappen die natuurlijke evolutionaire processen nabootsen om optimale oplossingen te vinden. Deze stappen laten de populatie over generaties evolueren en verbeteren de kwaliteit van de oplossingen. Hieronder staat een algemene leidraad voor hoe een genetisch algoritme verloopt:
Eerst genereren we een initiële populatie van willekeurige individuen. Deze stap creëert een diverse set potentiële oplossingen om het algoritme mee te starten.
Vervolgens moeten we de fitness van elk individu in de populatie berekenen. Hier gebruiken we de fitnessfunctie om te evalueren hoe goed elke oplossing is.
Met behulp van de selectiecriteria selecteren we individuen voor reproductie op basis van hun fitness. Deze stap bepaalt welke individuen ouders worden.
Daarna volgt crossover. Door het genetisch materiaal van geselecteerde ouders te combineren, passen we crossovertechnieken toe om nieuwe oplossingen of nakomelingen te genereren.
Om de diversiteit in onze populatie te behouden, introduceren we willekeurige mutaties in de nakomelingen.
Vervolgens vervangen we een deel of de hele oude populatie door de nieuwe nakomelingen, door te bepalen welke individuen doorgaan naar de volgende generatie.
De voorgaande stappen 2-6 worden herhaald voor een vastgesteld aantal generaties of totdat aan een stopconditie is voldaan. Deze lus laat de populatie in de tijd evolueren, hopelijk resulterend in een goede oplossing.
Nu we goed begrijpen wat genetische algoritmen zijn en in grote lijnen hoe ze werken, gaan we ons eigen genetisch algoritme bouwen om een eenvoudig optimalisatieprobleem op te lossen.
De vergelijking y=ax2+bx+c levert, wanneer je die uitzet, een parabool op. We zullen een genetisch algoritme gebruiken om de combinatie van waarden voor a, b en c te vinden die resulteert in de vlakste parabool. Hier is een voorproefje van wat we gaan bereiken:
Bovenaan onze functie importeren we de benodigde bibliotheken. We gebruiken ‘random’ om willekeurige waarden te genereren voor onze startpopulatie. Numpy is naar mijn mening sowieso handig bij wiskundig werk.
En ik ben er sterk van overtuigd dat je altijd grafieken moet maken om te controleren of je code doet wat jij denkt dat ze doet. Dus importeren we ‘matplotlib.pyplot’ om grafieken te maken.
Ik print ook graag belangrijke resultaten van elke generatie (ervan uitgaande dat het aantal generaties relatief klein is) om beter te begrijpen wat er tijdens de simulatie is gebeurd. Dus importeren we ‘PrettyTable’ daarvoor.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableVervolgens moeten we de fitnessfunctie definiëren die de fitness van elke oplossing zal beoordelen. In dit geval willen we de vlakste u-vorm vinden. Dus ik berekende de y-waarde bij de top en bij x=-1 en x=1.
Daarna berekende ik de kromming van de grafiek als het verschil in y-waarde op deze drie punten. Omdat we de vlakste kromme willen, heb ik de kromming negatief gemaakt om de fitnessfunctie af te ronden.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessWe gebruiken de ‘random’-bibliotheek om een populatie van willekeurige oplossingen te genereren. Elk individu in deze populatie is een set waarden voor a, b en c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationDe selectiefunctie bepaalt welke individuen zich voortplanten om de volgende populatie te creëren. In dit voorbeeld gebruiken we een toernooiselectieproces, waarbij een willekeurige subset van individuen uit de populatie wordt genomen en de individuen met de hoogste fitness binnen die subset worden geselecteerd voor reproductie.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedVervolgens schrijven we een korte functie om met crossover nieuwe oplossingen te creëren op basis van bestaande oplossingen.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2We hebben ook een mutatiefunctie nodig om willekeur toe te voegen aan volgende generaties. Dit is belangrijk om ervoor te zorgen dat er in elke generatie voldoende diversiteit is om uit te selecteren.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Vervolgens moeten we de hoofdlus maken die al deze onderdelen samenbrengt om ons algoritme te draaien. Omdat we onze resultaten ook moeten plotten, voeg ik in deze sectie de code voor het plotten toe, evenals de code die nodig is om onze eindtabel te maken.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Tot slot moeten we de parameters voor ons algoritme instellen en het uitvoeren.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")In dit voorbeeld hebben we een specifiek aantal generaties ingesteld waarin ons algoritme moet draaien. We hadden echter ook een stopconditie kunnen instellen die het programma stopt wanneer we een doel-fitnesswaarde bereiken. Dat zou er ongeveer zo uitzien:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessHier staat de volledige code bij elkaar.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Laten we onze outputs gebruiken om te zien hoe onze functie heeft gepresteerd.
Ten eerste zien we in onze tabel dat we 20 generaties hebben voltooid en dat de fitness per generatie leek toe te nemen van een relatief negatieve fitness naar een minder negatieve fitness. Mooi!
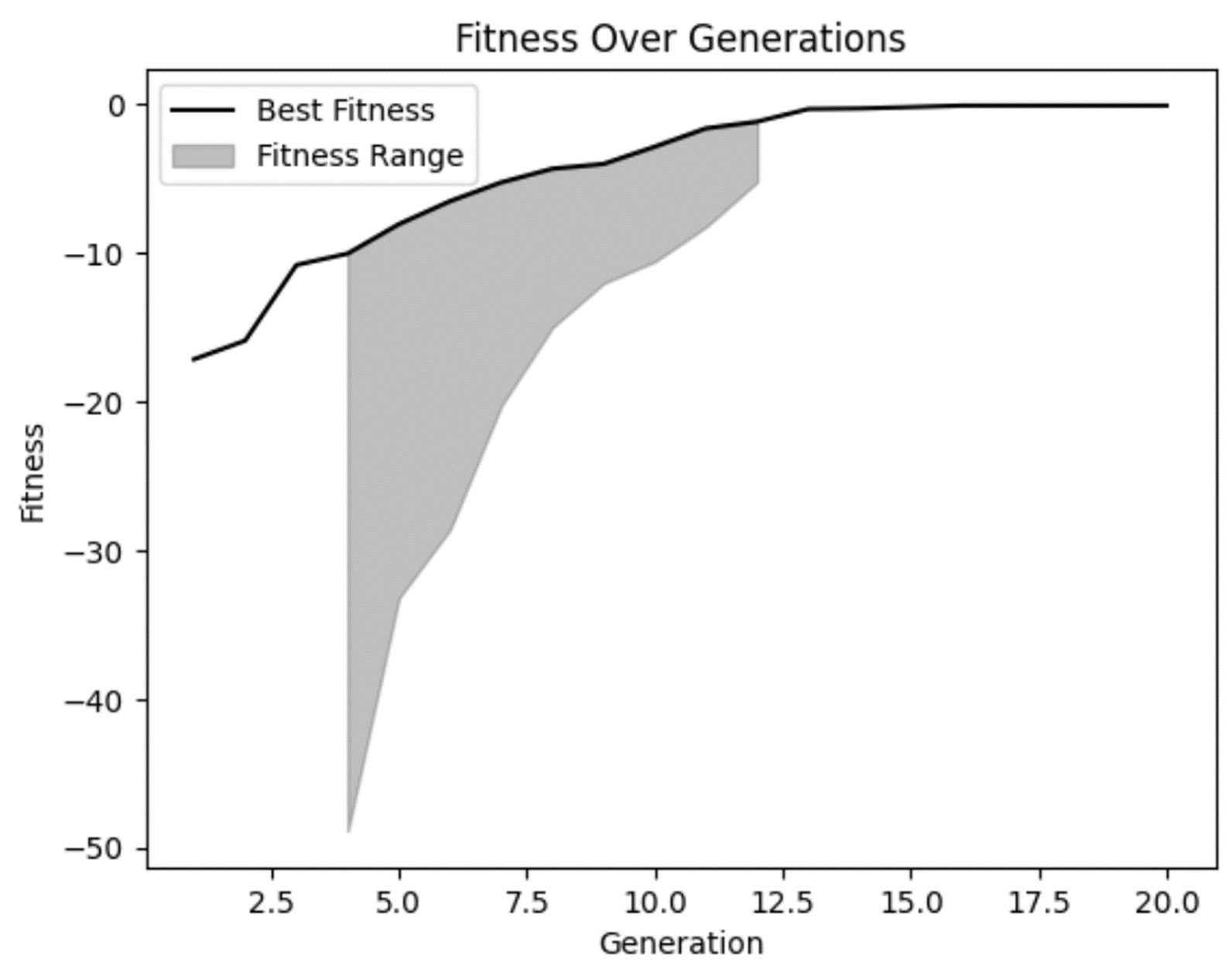
Uit onze fitnessgrafiek kunnen we onze vermoedens bevestigen dat de fitness in de tijd is verbeterd en in latere generaties wat is afgevlakt. Maar we zien ook dat er in enkele vroege generaties echt slechte oplossingen waren die ons model terecht verwierp.
We zien ook dat er in meerdere generaties niet veel diversiteit in fitnessbereik was. Hoewel dat niet per se slecht is, is het wel iets om op te letten. In sommige gevallen kan dit een indicatie zijn van voortijdige convergentie, een probleem dat optreedt wanneer er niet genoeg diversiteit in je populatie is.
Laten we vervolgens onze vergelijkingen per generatie plotten om te zien of we het echt hebben afgevlakt.
We zien dat onze vroege generatie-oplossingen erg krom zijn, wat logisch is. Deze vergelijking levert een U-vormige grafiek op. Maar we zien ook dat latere generaties steeds vlakker werden. Precies wat we zochten!
Het is wel de moeite waard te benadrukken dat we expliciet alleen binnen onze opgegeven grenzen van -50 tot 50 kijken. Als we zouden uitzoomen, zou de grafiek laten zien dat zelfs deze ogenschijnlijk vlakke lijnen nog steeds u-vormen zijn, maar dan met bredere bases.
Dit voorbeeld benadrukt hoe belangrijk het is om voorzichtig om te gaan met aannames in analyses, zodat ze onze verwachtingen ondersteunen. Ons model deed precies wat we wilden, maar alleen binnen de grenzen die we het gaven. Als we een combinatie van variabelen wilden vinden die verderop een vlakke vorm creëert, zouden we het model met ruimere grenzen moeten opnieuw uitvoeren.
We kunnen elk van de variabelen plotten om te zien hoeveel ze over de generaties veranderden. We zien dat in deze run van de simulatie c in het begin enorm varieerde, terwijl a en b veel minder dramatisch veranderden. Deze grafiek zal er elke keer anders uitzien als we de simulatie draaien, zelfs als we geen parameters wijzigen, omdat onze startpopulatie willekeurig is.
De laatste grafiek die ik wil bekijken is gewoon een momentopname van de hele populatie in één generatie: de laatste generatie. Omdat elk individu in de populatie drie parameters heeft, heb ik ze opgesplitst in drie subplots in plaats van te rommelen met 3D-plots.
Wat ik vooral wil zien in deze grafieken is of er voldoende diversiteit binnen deze generatie is. Zonder voldoende diversiteit kunnen we in een situatie belanden waarin de enige beschikbare oplossingen een lage fitness hebben, wat leidt tot voortijdige convergentie. Maar het lijkt erop dat deze grafieken een goede mate van diversiteit laten zien, dus ik ben blij met dit resultaat.
Genetische algoritmen kunnen in een breed scala aan situaties worden gebruikt. Maar er zijn enkele aandachtspunten om in gedachten te houden.
Zoals bij elk model hangt de prestatie van een genetisch algoritme af van verschillende parameters, met name populatiegrootte, crossoverfrequentie, mutatiefrequentie en begrenzingsparameters. Het wijzigen van deze parameters verandert hoe je model presteert.
Als vuistregel helpt een grotere populatiegrootte je om sneller de optimale oplossing te vinden, omdat er meer opties zijn om uit te kiezen. Grotere populaties vergen echter ook meer tijd en resources om te draaien.
Een hogere crossoverfrequentie kan leiden tot snellere convergentie doordat gunstige eigenschappen van verschillende individuen vaker worden gecombineerd. Maar een te hoge crossoverfrequentie kan de populatiestructuur verstoren, wat tot voortijdige convergentie kan leiden.
Een hogere mutatiefrequentie helpt genetische diversiteit te behouden en voorkomt dat het algoritme vastloopt in een lokaal optimum. Als de mutatiefrequentie echter te hoog is, kan dit het convergentieproces verstoren door te veel willekeur te introduceren, waardoor het moeilijk wordt om oplossingen te verfijnen.
Begrenzingsparameters definiëren het bereik waarbinnen het algoritme naar oplossingen zoekt. Deze zijn belangrijk om af te stemmen op jouw specifieke bedrijfsprobleem. Een te krap begrensd gebied kan optimale oplossingen missen. Een te breed begrensd gebied kost meer tijd en resources om te draaien. Maar er zijn nog andere overwegingen.
In ons gecodeerde voorbeeld hierboven heeft die vergelijking bijvoorbeeld theoretisch geen grenzen. Praktisch gezien kunnen we de computer echter niet vragen om de vlakste boog in een oneindig grote grafiek te vinden. Grenzen zijn dus noodzakelijk. Maar het veranderen van die grenzen zal ook het optimale antwoord veranderen. Naar mijn mening is het vaststellen van passende grenzen voor jouw specifieke usecase essentieel bij elk model.
Er kunnen andere belangrijke parameters zijn om in jouw model af te stemmen. Experimenteer met verschillende waarden om de beste instellingen voor jouw probleem te vinden. Wil je specifiek meer leren over het tunen van GA’s, bekijk dan Informed Methods: Genetic Algorithms.
Codering is een belangrijke stap bij het opzetten van een genetisch algoritme. Het houdt in dat potentiële oplossingen worden omgezet naar een formaat dat het algoritme kan verwerken. Stel bijvoorbeeld dat we een genetisch algoritme ontwerpen om bezorgroutes voor onze vrachtwagens te optimaliseren. Hoe zet je een lijst met bezorglocaties om in een chromosoom voor een GA? Codering transformeert deze lijst in een volgorde die het algoritme kan manipuleren, zoals een geordende lijst met locaties die een mogelijke bezorgroute vertegenwoordigt.
Een goede codering zorgt ervoor dat het genetisch algoritme de oplossingsruimte effectief kan verkennen en oplossingen op zinvolle manieren kan combineren of muteren. Zonder codering zou het algoritme geen complexe data aankunnen. Data zoals bezorglocaties, planningsproblemen of klantinteracties worden alleen via codering toegankelijk voor computers.
Er zijn verschillende coderingsschema’s om uit te kiezen. Je kunt meer leren en bepalen wat het beste is voor jouw situatie in Working with Categorical Data in Python of How to Convert Strings to Bytes in Python.
Voortijdige convergentie is een probleem dat optreedt wanneer de populatie te homogeen wordt. Dit kan ertoe leiden dat het algoritme vastloopt in een lokaal optimum in plaats van het globale optimum te vinden. In essentie: als er niet genoeg diversiteit in de populatie is, raken de oplossingen “ingeteeld” en krijg je niet de beste oplossing.
Er zijn een paar technieken die je kunt proberen om voortijdige convergentie te voorkomen. Een hogere mutatiefrequentie kan meer diversiteit in de populatie introduceren en helpen om nieuwe gebieden van de oplossingsruimte te verkennen. Je kunt ook beginnen met een meer diverse initiële populatie om vanaf het begin een brede verkenning van de oplossingsruimte te waarborgen.
Als je nog steeds te maken hebt met voortijdige convergentie, kun je proberen parameters zoals mutatie- en crossoverfrequentie dynamisch aan te passen op basis van de voortgang van het algoritme. Alternatief kun je meerdere populaties gebruiken (denk aan eilanden) die af en toe individuen uitwisselen om de diversiteit te behouden.
Je kunt meer leren over voortijdige convergentie en andere misstappen in machine learning in de Monitoring Machine Learning Concepts-cursus.
Aan de andere kant kunnen sterke crossover en mutatie of willekeur in de selectie betekenen dat goede oplossingen niet tot reproductie komen. Daar kan elitisme helpen. Elitisme is een techniek waarbij de beste individuen rechtstreeks worden meegenomen naar de volgende generatie om goede oplossingen te behouden. Dit helpt te waarborgen dat de beste oplossingen niet verloren gaan tijdens het evolutionaire proces.
Wees echter voorzichtig met elitisme. Als elitisme wordt gebruikt zonder voldoende populatiediversiteit, kun je alsnog eindigen met voortijdige convergentie. Als jouw bedrijfsprobleem om elitismetechnieken vraagt, zorg dan dat je het koppelt aan voldoende sterke crossover- en mutatiefuncties en een grote populatiegrootte. Deze aanpak helpt een gezonde balans te behouden tussen het benutten van bekende oplossingen en het verkennen van nieuwe mogelijkheden.
Genetische algoritmen zijn een fantastisch voorbeeld van data science die inspiratie haalt uit de natuurlijke wereld. Ze bieden een krachtige methode om complexe optimalisatieproblemen op te lossen door het proces van natuurlijke selectie na te bootsen.
Als je geïnteresseerd bent in andere door de biologie geïnspireerde modellen, leer dan over neurale netwerken en andere deep learning-technieken in Introduction to Deep Learning in Python. Je bent misschien ook geïnteresseerd in DataCamp’s Generative AI Concepts-cursus en AI Ethics.
Als je geïnspireerd bent om een project met biologische data te doen, bekijk dan Analyzing Genomic Data in R of Biomedical Image Analysis in Python.
Leer AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
