Kursus
Mengimpor Data Tingkat Menengah di Python
2 Hr
210.3K

Pandas adalah paket Python populer untuk data science, dan alasannya jelas: pustaka ini menawarkan struktur data yang kuat, ekspresif, dan fleksibel yang membuat manipulasi serta analisis data menjadi mudah, di antara banyak hal lainnya. DataFrame adalah salah satu strukturnya.
Tutorial ini membahas DataFrame pandas, dari manipulasi dasar hingga operasi lanjutan, dengan menjawab 11 pertanyaan paling populer agar Anda memahami—dan menghindari—keraguan para Pythonista sebelum Anda.
Untuk latihan lebih lanjut, coba bab pertama dari kursus Pandas DataFrames ini secara gratis!
Sebelum mulai, mari kilas balik singkat tentang apa itu DataFrame.
Mereka yang familiar dengan R mengenal data frame sebagai cara menyimpan data dalam grid persegi panjang yang mudah ditinjau. Setiap baris grid ini berkaitan dengan pengukuran atau nilai dari suatu instance, sedangkan setiap kolom adalah vektor yang memuat data untuk variabel tertentu. Ini berarti baris pada sebuah data frame tidak harus, namun dapat, berisi tipe nilai yang sama: bisa numerik, karakter, logis, dll.
DataFrame di Python sangat mirip: ia hadir bersama pustaka pandas, dan didefinisikan sebagai struktur data berlabel dua dimensi dengan kolom yang berpotensi bertipe berbeda.
Secara umum, Anda dapat mengatakan bahwa DataFrame pandas terdiri dari tiga komponen utama: data, indeks, dan kolom.
DataFrameSeries: array berlabel satu dimensi yang mampu menampung tipe data apa pun dengan label sumbu atau indeks. Contoh objek Series adalah satu kolom dari sebuah DataFrame.ndarray, yang bisa berupa record atau terstrukturndarray dua dimensindarray satu dimensi, list, kamus, atau Series.Catatan perbedaan antara np.ndarray dan np.array(). Yang pertama adalah tipe data sesungguhnya, sedangkan yang kedua adalah fungsi untuk membuat array dari struktur data lain.
Array terstruktur memungkinkan pengguna memanipulasi data berdasarkan field bernama: pada contoh di bawah, sebuah array terstruktur berisi tiga tuple dibuat. Elemen pertama tiap tuple akan disebut foo dan bertipe int, sedangkan elemen kedua bernama bar dan bertipe float.
Record array, di sisi lain, memperluas properti array terstruktur. Ia memungkinkan pengguna mengakses field dari array terstruktur melalui atribut alih-alih indeks. Anda lihat di bawah bahwa nilai foo diakses pada record array r2.
Contoh:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Jika Anda masih ragu tentang Pandas DataFrame dan bagaimana bedanya dengan struktur data lain seperti array NumPy atau Series, Anda dapat menonton presentasi singkat di bawah:
Perhatikan bahwa pada tulisan ini, sebagian besar waktu, pustaka yang Anda perlukan sudah dimuat. Pustaka Pandas biasanya diimpor dengan alias pd, sedangkan pustaka NumPy dimuat sebagai np. Ingat saat Anda menulis kode di lingkungan data science Anda sendiri, jangan lupa langkah impor ini, yang ditulis seperti ini:
import numpy as np
import pandas as pdSekarang setelah tidak ada keraguan tentang apa itu DataFrame, apa yang bisa dilakukan, dan bagaimana bedanya dengan struktur lain, saatnya menjawab pertanyaan paling umum yang dimiliki pengguna saat bekerja dengannya!
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeJelas, membuat DataFrame Anda adalah langkah pertama dalam hampir semua hal yang ingin Anda lakukan terkait pengolahan data di Python. Terkadang, Anda ingin memulai dari nol, tetapi Anda juga bisa mengonversi struktur data lain, seperti list atau array NumPy, menjadi Pandas DataFrame. Pada bagian ini, Anda hanya akan membahas yang terakhir. Namun, jika Anda ingin membaca lebih lanjut tentang membuat DataFrame kosong yang bisa Anda isi data nanti, buka bagian 7.
Di antara banyak hal yang bisa menjadi masukan untuk membuat sebuah ‘DataFrame’, sebuah ndarray NumPy adalah salah satunya. Untuk membuat data frame dari array NumPy, Anda cukup meneruskannya ke fungsi DataFrame() pada argumen data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Perhatikan bagaimana potongan kode di atas memilih elemen dari array NumPy untuk menyusun DataFrame: Anda terlebih dahulu memilih nilai yang terdapat dalam list yang dimulai dengan Row1 dan Row2, lalu Anda memilih indeks atau nomor baris Row1 dan Row2 dan kemudian nama kolom Col1 dan Col2.
Selanjutnya, Anda juga melihat bahwa pada contoh di atas, kita mencetak cuplikan kecil dari data. Ini bekerja sama seperti membuat subset array NumPy 2D: Anda terlebih dahulu menunjukkan baris yang ingin dilihat untuk data Anda, lalu kolom. Jangan lupa bahwa indeks mulai dari 0! Untuk data pada contoh di atas, Anda melihat pada baris di indeks 1 hingga akhir, dan Anda memilih semua elemen setelah indeks 1. Akibatnya, Anda memilih 1, 2, 3, dan 4.
Pendekatan ini untuk membuat DataFrame akan sama untuk semua struktur yang dapat diterima DataFrame() sebagai masukan.
Lihat contoh di bawah:
Ingat bahwa pustaka Pandas sudah diimpor sebagai pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Perhatikan bahwa indeks Series (dan DataFrame) Anda berisi key dari kamus asli, namun urut: Belgium akan menjadi indeks di 0, sedangkan United States akan menjadi indeks di 3.
Setelah Anda membuat DataFrame, Anda mungkin ingin mengetahui sedikit lebih banyak tentangnya. Anda dapat menggunakan properti shape atau fungsi len() dikombinasikan dengan properti .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Kedua opsi ini memberi Anda informasi yang sedikit berbeda tentang DataFrame Anda: properti shape akan memberi Anda dimensi DataFrame. Artinya Anda akan mengetahui lebar dan tinggi DataFrame. Di sisi lain, fungsi len(), dikombinasikan dengan properti index, hanya memberikan informasi tentang tinggi DataFrame Anda.
Ini semua sama sekali tidak luar biasa, karena Anda secara eksplisit memberikan properti index.
Anda juga bisa menggunakan df[0].count() untuk mengetahui lebih banyak tentang tinggi DataFrame Anda, tetapi ini akan mengecualikan nilai NaN (jika ada). Itulah mengapa memanggil .count() pada DataFrame tidak selalu menjadi opsi yang lebih baik.
Jika Anda menginginkan informasi lebih lanjut tentang kolom DataFrame Anda, Anda selalu dapat menjalankan list(my_dataframe.columns.values).
Sekarang setelah Anda menempatkan data ke dalam struktur Pandas DataFrame yang lebih nyaman, saatnya mulai bekerja sungguhan!
Bagian pertama ini akan memandu Anda melalui langkah awal bekerja dengan DataFrame di Python. Ini mencakup operasi dasar yang dapat Anda lakukan pada DataFrame yang baru dibuat: menambah, memilih, menghapus, mengganti nama, dan lainnya.
Sebelum mulai menambah, menghapus, dan mengganti nama komponen DataFrame, Anda perlu tahu dulu cara memilih elemen-elemen ini. Jadi, bagaimana caranya?
Meski Anda mungkin masih ingat caranya dari bagian sebelumnya: memilih indeks, kolom, atau nilai dari DataFrame tidaklah sulit, malah sebaliknya. Ini mirip dengan apa yang Anda lihat di bahasa lain (atau paket!) yang digunakan untuk analisis data. Jika Anda belum yakin, pertimbangkan hal berikut:
Di R, Anda menggunakan notasi [,] untuk mengakses nilai data frame.
Sekarang, misalkan Anda memiliki DataFrame seperti ini:
A B C
0 1 2 3
1 4 5 6
2 7 8 9Dan Anda ingin mengakses nilai yang berada pada indeks 0, di kolom ‘A’.
Ada berbagai opsi untuk mendapatkan kembali nilai 1 Anda:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Yang paling penting untuk diingat adalah .loc[] dan .iloc[]. Perbedaan halus antara keduanya akan dibahas pada bagian berikutnya.
Cukup tentang memilih nilai dari DataFrame. Bagaimana dengan memilih baris dan kolom? Dalam hal ini, Anda akan menggunakan:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Untuk saat ini, cukup tahu bahwa Anda bisa mengakses nilai dengan memanggil labelnya atau posisinya pada indeks atau kolom. Jika belum terlihat, lihat lagi perbedaan kecil pada perintah: satu kali Anda melihat [0][0], kali lain Anda melihat [0,'A'] untuk mengambil nilai 1 Anda.
Sekarang setelah Anda belajar cara memilih nilai dari DataFrame, saatnya bekerja sungguhan dan menambahkan indeks, baris, atau kolom!
Saat Anda membuat DataFrame, Anda memiliki opsi menambahkan masukan ke argumen ‘index’ untuk memastikan Anda mendapatkan indeks seperti yang diinginkan. Jika Anda tidak menentukan ini, DataFrame Anda secara default akan memiliki indeks bernilai numerik yang dimulai dari 0 dan berlanjut hingga baris terakhir DataFrame.
Namun, meski indeks Anda ditentukan secara otomatis, Anda tetap bisa menggunakan kembali salah satu kolom dan menjadikannya indeks. Anda dapat melakukannya dengan mudah dengan memanggil set_index() pada DataFrame. Coba di bawah ini!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9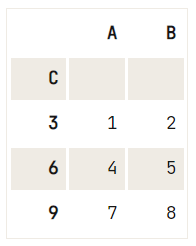
Sebelum sampai ke solusinya, ada baiknya memahami konsep loc dan bagaimana bedanya dengan atribut pengindeksan lain seperti .iloc[] dan .ix[]:
Semua ini mungkin tampak rumit. Mari ilustasikan dengan contoh kecil:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Perhatikan bahwa dalam kasus ini, Anda menggunakan contoh DataFrame yang tidak seluruhnya berbasis integer agar lebih mudah memahami perbedaannya. Anda jelas melihat bahwa meneruskan 2 ke .loc[] atau .iloc[]/.ix[] tidak memberikan hasil yang sama!
48 1
49 2
50 3.iloc[] akan melihat posisi dalam indeks. Ketika Anda meneruskan 2, Anda akan mendapatkan kembali:48 7
49 8
50 9.ix[] akan berperilaku sama seperti iloc dan melihat posisi dalam indeks. Anda akan mendapatkan hasil yang sama seperti .iloc[].Sekarang perbedaan antara .iloc[], .loc[] dan .ix[] sudah jelas, Anda siap mencoba menambahkan baris ke DataFrame!
Tip: sebagai konsekuensi dari apa yang baru Anda baca, Anda juga paham bahwa rekomendasi umum adalah menggunakan .loc untuk menyisipkan baris ke DataFrame. Itu karena jika Anda menggunakan df.ix[], Anda mungkin mencoba mereferensikan indeks bernilai numerik dengan nilai indeks dan tanpa sengaja menimpa baris yang sudah ada pada DataFrame. Hindari ini!
Cermati perbedaannya sekali lagi pada DataFrame di bawah:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Anda bisa melihat mengapa semua ini bisa membingungkan, bukan?
Dalam beberapa kasus, Anda ingin menjadikan indeks sebagai bagian dari DataFrame. Anda dapat melakukannya dengan mudah dengan mengambil sebuah kolom dari DataFrame atau merujuk ke kolom yang belum Anda buat dan menetapkannya ke properti .index, seperti ini:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2Dengan kata lain, Anda memberi tahu DataFrame bahwa ia harus mengambil kolom A sebagai indeksnya.
Namun, jika Anda ingin menambahkan kolom ke DataFrame, Anda juga bisa mengikuti pendekatan yang sama seperti saat Anda menambahkan indeks ke DataFrame: gunakan .loc[] atau .iloc[]. Dalam kasus ini, Anda menambahkan Series ke DataFrame yang sudah ada dengan bantuan .loc[]:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Ingat bahwa objek Series sangat mirip dengan kolom DataFrame. Itulah mengapa Anda dapat dengan mudah menambahkan Series ke DataFrame yang ada. Perhatikan juga bahwa pengamatan yang dibuat sebelumnya tentang .loc[] tetap berlaku, bahkan saat Anda menambahkan kolom ke DataFrame!
Ketika indeks Anda tidak tampak sesuai keinginan, Anda bisa memilih untuk mengatur ulangnya. Anda dapat melakukannya dengan mudah menggunakan .reset_index(). Namun, tetap waspada, karena Anda dapat meneruskan beberapa argumen yang bisa menentukan sukses tidaknya reset:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Anda bisa coba mengganti argumen drop dengan inplace pada contoh di atas dan lihat apa yang terjadi!
Perhatikan bagaimana Anda menggunakan argumen drop untuk menunjukkan bahwa Anda ingin menyingkirkan indeks yang ada. Jika Anda menggunakan inplace, indeks asli dengan bilangan pecahan akan ditambahkan sebagai kolom ekstra ke DataFrame.
Sekarang setelah Anda melihat cara memilih dan menambahkan indeks, baris, dan kolom ke DataFrame, saatnya mempertimbangkan kasus penggunaan lain: menghapus ketiganya dari struktur data Anda.
Jika Anda ingin menghapus indeks dari DataFrame, sebaiknya dipikir ulang karena DataFrame dan Series selalu memiliki indeks.
Namun, yang bisa Anda lakukan misalnya:
del df.index.name,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')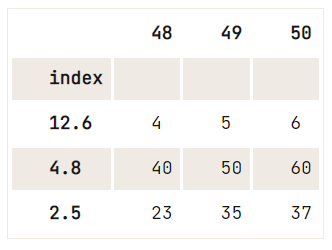
Sekarang setelah Anda tahu cara menghapus indeks dari DataFrame, Anda bisa lanjut menghapus kolom dan baris!
Untuk menyingkirkan (sebagian) kolom dari DataFrame, Anda dapat menggunakan metode drop():
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9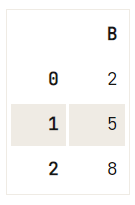
Anda mungkin berpikir sekarang: ini tidak terlalu langsung; Ada beberapa argumen ekstra yang diteruskan ke metode drop()!
axis bernilai 0 saat mengindikasikan baris dan 1 saat digunakan untuk menghapus kolom.inplace ke True untuk menghapus kolom tanpa harus menugaskan ulang DataFrame.Anda dapat menghapus baris duplikat dari DataFrame dengan menjalankan df.drop_duplicates(). Anda juga dapat menghapus baris dari DataFrame dengan hanya mempertimbangkan nilai duplikat yang ada pada satu kolom.
Cermati contoh ini:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37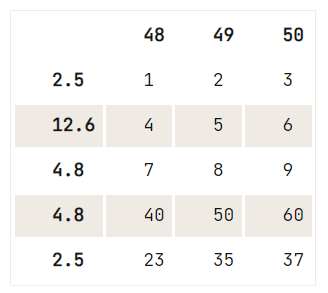
Jika tidak ada kriteria keunikan untuk penghapusan yang ingin Anda lakukan, Anda dapat menggunakan metode drop(), di mana Anda menggunakan properti index untuk menentukan indeks baris mana yang ingin Anda hapus dari DataFrame:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37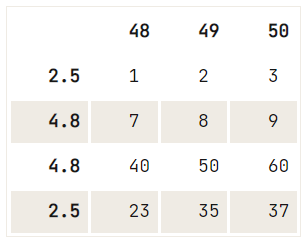
Setelah perintah ini, Anda mungkin ingin mengatur ulang indeks lagi.
Tip: coba atur ulang indeks DataFrame hasilnya sendiri! Jangan lupa gunakan argumen drop jika Anda anggap perlu.
Untuk memberikan nilai berbeda pada kolom atau nilai indeks DataFrame Anda, paling baik gunakan metode .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9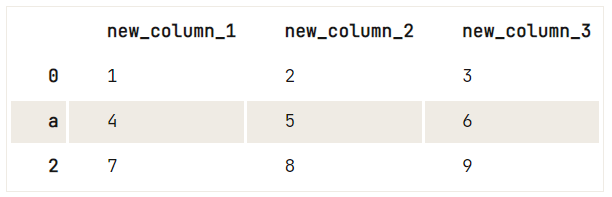
Tip: coba ubah argumen inplace pada tugas pertama (mengganti nama kolom) menjadi False dan lihat apa hasil skrip sekarang. Anda melihat bahwa kini DataFrame tidak ditugaskan ulang saat mengganti nama kolom. Akibatnya, tugas kedua mengambil DataFrame asli sebagai masukan dan bukan yang baru saja Anda dapatkan dari operasi rename() pertama.
Sekarang setelah Anda melewati set pertanyaan pertama tentang DataFrame Pandas, saatnya melampaui dasar-dasar dan benar-benar praktik karena masih banyak hal tentang DataFrame dibanding yang Anda lihat di bagian pertama.
Sering kali, Anda juga ingin melakukan beberapa operasi pada nilai aktual yang terdapat dalam DataFrame. Pada bagian berikut, Anda akan membahas beberapa cara untuk memformat nilai pada DataFrame pandas Anda
Untuk mengganti string tertentu dalam DataFrame, Anda dapat dengan mudah menggunakan replace(): teruskan nilai yang ingin Anda ubah, diikuti nilai penggantinya.
Seperti ini:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor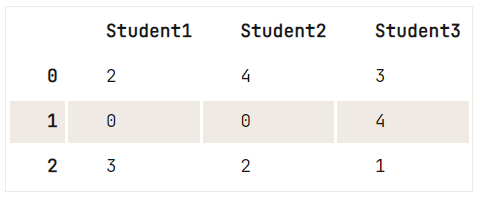
Perhatikan bahwa ada juga argumen regex yang dapat sangat membantu saat Anda berhadapan dengan kombinasi string yang aneh:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9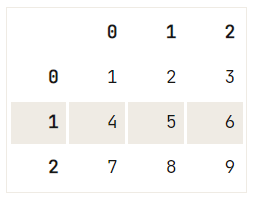
Singkatnya, replace() umumnya adalah yang Anda butuhkan saat ingin mengganti nilai atau string dalam DataFrame dengan yang lain!
Menghapus bagian yang tidak diinginkan dari string adalah pekerjaan yang merepotkan. Untungnya, ada solusi mudah!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Anda menggunakan map() pada kolom result untuk menerapkan fungsi lambda ke setiap elemen pada kolom tersebut. Fungsinya mengambil nilai string dan menghapus + atau - di sebelah kiri, serta menghapus salah satu dari enam karakter aAbBcC di sebelah kanan.
Ini sedikit tugas pemformatan yang lebih sulit. Namun, potongan kode berikut akan memandu Anda melalui langkah-langkahnya:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
Singkatnya, yang Anda lakukan adalah:
Ticket dari DataFrame df dan memecah string berdasarkan spasi. Ini akan memastikan dua tiket pada akhirnya berada di dua baris terpisah. Selanjutnya, Anda mengambil empat nilai ini (empat nomor tiket) dan menempatkannya ke objek Series: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN di sana! Anda harus menumpuk (stack) Series untuk memastikan tidak ada nilai NaN pada Series hasil.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket asli.Anda mungkin ingin menyesuaikan data pada DataFrame dengan menerapkan sebuah fungsi. Mari mulai menjawab pertanyaan ini dengan membuat fungsi lambda Anda sendiri:
doubler = lambda x: x*2Tip: jika Anda ingin tahu lebih banyak tentang fungsi di Python, pertimbangkan untuk mengikuti tutorial fungsi Python ini.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Perhatikan bahwa Anda juga dapat memilih baris dari DataFrame dan menerapkan fungsi lambda doubler padanya. Ingat bahwa Anda dapat dengan mudah memilih baris dari DataFrame dengan menggunakan .loc[] atau .iloc[].
Lalu, Anda akan mengeksekusi sesuatu seperti ini, tergantung apakah Anda ingin memilih indeks berdasarkan posisinya atau berdasarkan labelnya:
df.loc[0].apply(doubler)Perhatikan bahwa fungsi apply() hanya menerapkan fungsi doubler sepanjang sumbu DataFrame. Itu berarti Anda menargetkan indeks atau kolom. Atau, dengan kata lain, baris atau kolom.
Namun, jika Anda ingin menerapkannya ke setiap elemen atau secara element-wise, Anda dapat menggunakan fungsi map(). Anda bisa mengganti fungsi apply() pada potongan kode di atas dengan map(). Jangan lupa tetap meneruskan fungsi doubler agar nilainya dikalikan 2.
Misalkan Anda ingin menerapkan fungsi pengganda ini tidak hanya ke kolom A dari DataFrame, tetapi ke seluruhnya. Dalam kasus ini, Anda dapat menggunakan applymap() untuk menerapkan fungsi doubler ke setiap elemen di seluruh DataFrame:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Perhatikan bahwa pada kasus-kasus ini, kita bekerja dengan fungsi lambda atau fungsi anonim yang dibuat saat runtime. Namun, Anda juga dapat menulis fungsi sendiri. Misalnya:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Jika Anda menginginkan informasi lebih lanjut tentang alur kendali (flow of control) di Python, Anda selalu dapat melihat sumber kami yang lain.
Fungsi yang akan Anda gunakan adalah fungsi Pandas Dataframe(): fungsi ini mengharuskan Anda meneruskan data yang ingin Anda masukkan, indeks, dan kolom.
Ingat bahwa data yang terdapat di dalam data frame tidak harus homogen. Tipe datanya bisa berbeda-beda!
Ada beberapa cara menggunakan fungsi ini untuk membuat DataFrame kosong. Pertama, Anda dapat menggunakan numpy.nan untuk menginisialisasi data frame Anda dengan NaN. Perhatikan bahwa numpy.nan bertipe float.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNSaat ini, tipe data dari data frame diinferensikan secara default: karena numpy.nan bertipe float, data frame juga akan berisi nilai bertipe float. Namun, Anda juga dapat memaksa DataFrame menjadi tipe tertentu dengan menambahkan atribut dtype dan mengisinya dengan tipe yang diinginkan. Seperti pada contoh ini:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNPerhatikan bahwa jika Anda tidak menentukan label sumbu atau indeks, label tersebut akan dibuat dari data masukan berdasarkan aturan akal sehat.
Pandas dapat mengenalinya, tetapi Anda perlu sedikit membantu: tambahkan argumen parse_dates saat Anda membaca data dari, katakanlah, file comma-separated value (CSV):
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Namun, selalu ada format tanggal-waktu yang aneh.
Jangan khawatir! Dalam kasus seperti itu, Anda dapat membuat parser sendiri untuk menanganinya. Anda bisa, misalnya, membuat fungsi lambda yang mengambil DateTime Anda dan mengontrolnya dengan string format.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Mengubah bentuk (reshape) DataFrame berarti mentransformasikannya sehingga struktur hasilnya lebih cocok untuk analisis data Anda. Dengan kata lain, mengubah bentuk tidak terlalu berkaitan dengan pemformatan nilai yang terdapat dalam DataFrame, tetapi lebih pada mengubah bentuknya.
Ini menjawab kapan dan mengapa. Lalu bagaimana Anda akan mengubah bentuk DataFrame?
Ada tiga cara mengubah bentuk yang sering menimbulkan pertanyaan bagi pengguna: pivoting, stacking dan unstacking, serta melting.
Anda dapat menggunakan fungsi pivot() untuk membuat tabel turunan baru dari tabel asli. Saat menggunakan fungsi ini, Anda dapat meneruskan tiga argumen:
values: argumen ini memungkinkan Anda menentukan nilai dari DataFrame asli yang ingin Anda lihat pada tabel pivot.columns: apa pun yang Anda berikan ke argumen ini akan menjadi kolom di tabel hasil.index: apa pun yang Anda berikan ke argumen ini akan menjadi indeks di tabel hasil.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Saat Anda tidak secara khusus mengisi nilai apa yang diharapkan ada pada tabel hasil, Anda akan melakukan pivot berdasarkan beberapa kolom:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Perhatikan bahwa data Anda tidak boleh memiliki baris dengan nilai duplikat untuk kolom yang Anda tentukan. Jika tidak demikian, Anda akan mendapatkan pesan kesalahan. Jika Anda tidak bisa memastikan keunikan data, Anda sebaiknya menggunakan metode pivot_table sebagai gantinya:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Perhatikan argumen tambahan aggfunc yang diteruskan ke metode pivot_table. Argumen ini menunjukkan bahwa Anda menggunakan fungsi agregasi untuk menggabungkan beberapa nilai. Pada contoh ini, Anda dapat dengan jelas melihat bahwa fungsi mean digunakan.
stack() dan unstack() untuk Mengubah Bentuk Pandas DataFrameAnda sudah melihat contoh stacking pada bagian 5. Intinya, Anda mungkin masih ingat bahwa ketika Anda melakukan stack DataFrame, Anda membuatnya lebih tinggi. Anda memindahkan indeks kolom terdalam untuk menjadi indeks baris terdalam. Anda mengembalikan DataFrame dengan indeks yang memiliki level label baris terdalam yang baru.
Kembali ke penjelasan lengkap di bagian 5 jika Anda belum yakin cara kerjastack().
Kebalikan dari stacking disebut unstacking. Mirip dengan stack(), Anda menggunakan unstack() untuk memindahkan indeks baris terdalam agar menjadi indeks kolom terdalam.
Untuk penjelasan tentang pivoting, stacking, dan unstacking di pandas, lihat kursus Reshaping Data with pandas.
melt()Melting dianggap berguna dalam kasus di mana Anda memiliki data dengan satu atau lebih kolom sebagai variabel pengenal (identifier variables), sementara semua kolom lainnya dianggap sebagai variabel terukur (measured variables).
Variabel terukur ini semua “di-unpivot” ke sumbu baris. Artinya, sementara variabel terukur yang tersebar pada lebar DataFrame, melt akan memastikan variabel tersebut ditempatkan pada tingginya. Atau, dengan kata lain lagi, DataFrame Anda kini akan menjadi lebih panjang alih-alih lebih lebar.
Hasilnya, Anda memiliki dua kolom non-identifier, yaitu ‘variable’ dan ‘value’.
Mari ilustrasikan dengan contoh:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Jika Anda mencari lebih banyak cara untuk mengubah bentuk data, lihat dokumentasi.
Anda dapat mengiterasi baris-baris DataFrame dengan bantuan loop for dikombinasikan dengan pemanggilan iterrows() pada DataFrame Anda:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() memungkinkan Anda melakukan loop secara efisien pada baris DataFrame sebagai pasangan (index, Series). Dengan kata lain, ia memberikan tuple (index, row) sebagai hasil.
Saat Anda telah melakukan pengolahan dan manipulasi data dengan Pandas, Anda mungkin ingin mengekspor DataFrame ke format lain. Bagian ini akan membahas dua cara mengeluarkan DataFrame pandas Anda ke CSV atau ke file Excel.
Untuk menulis DataFrame sebagai file CSV, Anda dapat menggunakan to_csv():
import pandas as pd
df.to_csv('myDataFrame.csv')Potongan kode itu tampak sederhana, tetapi di sinilah kesulitan mulai bagi banyak orang karena Anda akan memiliki persyaratan khusus untuk keluaran data. Mungkin Anda tidak ingin koma sebagai pembatas, atau Anda ingin menentukan encoding tertentu.
Jangan khawatir! Anda dapat meneruskan beberapa argumen tambahan ke to_csv() untuk memastikan data Anda diekspor sesuai keinginan!
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN atau nilai yang hilang direpresentasikan, apakah ingin mengekspor header atau tidak, apakah ingin menulis nama baris atau tidak, apakah ingin kompresi, Anda dapat membaca opsi-opsinya.Serupa dengan apa yang Anda lakukan untuk mengekspor DataFrame ke CSV, Anda dapat menggunakan to_excel() untuk menulis tabel ke Excel. Namun, ini sedikit lebih rumit:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Perhatikan, bagaimanapun, bahwa seperti to_csv(), Anda memiliki banyak argumen tambahan seperti startcol, startrow, dan sebagainya, untuk memastikan Anda mengekspor data dengan benar. Anda dapat mempelajari lebih lanjut cara mengimpor data dari dan mengekspor data ke file CSV menggunakan pandas dalam tutorial kami.
Namun, jika Anda menginginkan informasi lebih lanjut tentang alat IO di Pandas, lihat dokumentasi DataFrame ke excel pandas.
Selesai! Anda telah berhasil menyelesaikan tutorial Pandas DataFrame!
Jawaban untuk 11 pertanyaan Pandas yang sering ditanyakan mencakup fungsi-fungsi esensial yang Anda perlukan untuk mengimpor, membersihkan, dan memanipulasi data dalam pekerjaan data science Anda. Tidak yakin sudah cukup mendalam? Kursus Importing Data In Python kami akan membantu Anda! Jika Anda sudah menguasainya, Anda mungkin ingin melihat Pandas beraksi dalam proyek nyata. Seri tutorial Pentingnya Prapemrosesan dalam Data Science dan Machine Learning Pipeline wajib dibaca, dan kursus terbuka Introduction to Python & Machine Learning wajib diselesaikan.
Pelajari lebih lanjut tentang Python dan pandas
Kursus
Kursus
Kursus