Cursus
Gevorderd data importeren in Python
2 Hr
210.6K

Pandas is een populair Python-pakket voor data science, en met reden: het biedt krachtige, expressieve en flexibele datastructuren die het manipuleren en analyseren van data makkelijk maken, naast veel andere dingen. De DataFrame is een van deze structuren.
Deze tutorial behandelt pandas DataFrames, van basisbewerkingen tot geavanceerde operaties, aan de hand van 11 veelgestelde vragen, zodat je de twijfels begrijpt — en vermijdt — van de Pythonistas die je voorgingen.
Wil je meer oefenen? Probeer gratis het eerste hoofdstuk van deze cursus over Pandas DataFrames!
Voordat je begint, eerst even kort wat DataFrames zijn.
Wie met R vertrouwd is, kent de data frame als een manier om data op te slaan in rechthoekige rasters die je makkelijk kunt overzien. Elke rij in zo’n raster komt overeen met metingen of waarden van één instantie, terwijl elke kolom een vector is met data voor een specifieke variabele. Dat betekent dat de rijen van een data frame niet per se, maar wel kunnen, hetzelfde type waarden bevatten: numeriek, tekst, logisch, enz.
DataFrames in Python lijken hier sterk op: ze komen met de pandas-bibliotheek en zijn gedefinieerd als tweedimensionale, gelabelde datastructuren met kolommen die potentieel verschillende types hebben.
In het algemeen kun je zeggen dat de pandas DataFrame uit drie hoofdcomponenten bestaat: de data, de index en de kolommen.
DataFrameSeries: een eendimensionale gelabelde array die elk datatype kan bevatten met aslabels of index. Een voorbeeld van een Series-object is één kolom uit een DataFrame.ndarray, wat een record- of gestructureerde array kan zijnndarrayndarray’s, lijsten, dictionary’s of Series.Let op het verschil tussen np.ndarray en np.array(). De eerste is een echt datatype, terwijl de tweede een functie is om arrays te maken van andere datastructuren.
Gestructureerde arrays laten je data manipuleren via benoemde velden: in het voorbeeld hieronder wordt een gestructureerde array van drie tuples gemaakt. Het eerste element van elke tuple heet foo en is van het type int, terwijl het tweede element bar heet en een float is.
Record-arrays breiden daarentegen de eigenschappen van gestructureerde arrays uit. Ze laten je de velden van gestructureerde arrays benaderen via attributen in plaats van via index. Hieronder zie je dat de foo-waarden worden benaderd in de record-array r2.
Een voorbeeld:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Twijfel je nog over Pandas DataFrames en hoe ze verschillen van andere datastructuren zoals een NumPy-array of een Series? Bekijk dan de korte presentatie hieronder:
Let op dat in dit artikel de benodigde libraries meestal al zijn ingeladen. De Pandas-bibliotheek wordt doorgaans geïmporteerd onder het alias pd, terwijl de NumPy-bibliotheek als np wordt geladen. Onthoud dat je in je eigen data science-omgeving deze importstap niet mag vergeten, die je zo schrijft:
import numpy as np
import pandas as pdNu er geen twijfel meer is over wat DataFrames zijn, wat ze kunnen en hoe ze verschillen van andere structuren, is het tijd om de meest voorkomende vragen over het werken ermee aan te pakken!
Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenLogischerwijs is het maken van je DataFrames je eerste stap bij bijna alles wat je wilt doen op het gebied van datamunging in Python. Soms wil je vanaf nul beginnen, maar je kunt ook andere datastructuren, zoals lijsten of NumPy-arrays, omzetten naar Pandas DataFrames. In deze sectie behandel je alleen dat laatste. Als je echter meer wilt lezen over het maken van lege DataFrames die je later kunt vullen met data, ga dan naar sectie 7.
Onder de vele dingen die als input kunnen dienen om een ‘DataFrame’ te maken, is een NumPy-ndarray er een van. Om van een NumPy-array een data frame te maken, kun je die gewoon doorgeven aan de functie DataFrame() in het argument data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Let erop hoe de codeblokken hierboven elementen uit de NumPy-array selecteren om de DataFrame te construeren: je selecteert eerst de waarden die zitten in de lijsten die beginnen met Row1 en Row2, daarna selecteer je de index of rijnamen Row1 en Row2 en vervolgens de kolomnamen Col1 en Col2.
Vervolgens zie je ook dat we in het bovenstaande voorbeeld een kleine selectie van de data hebben geprint. Dit werkt hetzelfde als het subsetten van 2D NumPy-arrays: je geeft eerst de rij aan waarin je je data wilt opzoeken, daarna de kolom. Vergeet niet dat de indexering bij 0 begint! Voor data in het bovenstaande voorbeeld kijk je in de rijen op index 1 tot het einde, en selecteer je alle elementen na index 1. Daardoor selecteer je 1, 2, 3 en 4.
Deze aanpak om DataFrames te maken is hetzelfde voor alle structuren die DataFrame() als input kan aannemen.
Zie het onderstaande voorbeeld:
Onthoud dat de Pandas-bibliotheek al is geïmporteerd als pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Merk op dat de index van je Series (en DataFrame) de keys van de oorspronkelijke dictionary bevat, maar dat ze gesorteerd zijn: Belgium zal de index op 0 zijn, terwijl de United States de index op 3 zal zijn.
Nadat je je DataFrame hebt gemaakt, wil je er misschien wat meer over weten. Je kunt de eigenschap shape gebruiken of de functie len() in combinatie met de eigenschap .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Deze twee opties geven je lichtjes andere informatie over je DataFrame: de eigenschap shape geeft je de afmetingen van je DataFrame. Dat wil zeggen dat je de breedte en de hoogte van je DataFrame te weten komt. De functie len() geeft daarentegen, in combinatie met de eigenschap index, alleen informatie over de hoogte van je DataFrame.
Dat is niet uitzonderlijk, aangezien je de eigenschap index expliciet opgeeft.
Je zou ook df[0].count() kunnen gebruiken om meer te weten te komen over de hoogte van je DataFrame, maar dit sluit de NaN-waarden uit (als die er zijn). Daarom is .count() aanroepen op je DataFrame niet altijd de beste optie.
Als je meer informatie over je DataFrame-kolommen wilt, kun je altijd list(my_dataframe.columns.values) uitvoeren.
Nu je je data in een handigere Pandas DataFrame-structuur hebt gezet, is het tijd voor het echte werk!
Dit eerste deel begeleidt je door de eerste stappen van het werken met DataFrames in Python. Het behandelt de basisbewerkingen die je op je nieuw gemaakte DataFrame kunt doen: toevoegen, selecteren, verwijderen, hernoemen en meer.
Voordat je begint met het toevoegen, verwijderen en hernoemen van de componenten van je DataFrame, moet je eerst weten hoe je deze elementen kunt selecteren. Hoe doe je dat?
Ook al herinner je je misschien nog hoe het moet uit de vorige sectie: het selecteren van een index, kolom of waarde uit je DataFrame is niet moeilijk, integendeel. Het is vergelijkbaar met wat je ziet in andere talen (of pakketten!) die voor data-analyse worden gebruikt. Als je niet overtuigd bent, overweeg dan het volgende:
In R gebruik je de [,]-notatie om de waarden van de data frame te benaderen.
Stel dat je een DataFrame hebt zoals deze:
A B C
0 1 2 3
1 4 5 6
2 7 8 9En je wilt de waarde benaderen die op index 0 staat, in kolom ‘A’.
Er bestaan verschillende opties om je waarde 1 terug te krijgen:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1De belangrijkste om te onthouden zijn zonder twijfel .loc[] en .iloc[]. De subtiele verschillen tussen deze twee komen in de volgende secties aan bod.
Genoeg voorlopig over het selecteren van waarden uit je DataFrame. Hoe zit het met het selecteren van rijen en kolommen? In dat geval gebruik je:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Voor nu is het genoeg om te weten dat je de waarden kunt benaderen door ze aan te roepen op label of op positie in de index of kolom. Zie je dit niet, kijk dan nog eens naar de kleine verschillen in de commando’s: de ene keer zie je [0][0], de andere keer [0,'A'] om je waarde 1 op te halen.
Nu je hebt geleerd hoe je een waarde uit een DataFrame selecteert, is het tijd voor het echte werk: een index, rij of kolom toevoegen!
Wanneer je een DataFrame maakt, kun je input meegeven aan het argument ‘index’ om zeker te zijn dat je de gewenste index hebt. Als je dit niet specificeert, krijgt je DataFrame standaard een numerieke index die begint bij 0 en doorloopt tot de laatste rij van je DataFrame.
Maar zelfs als je index automatisch voor je is gespecificeerd, heb je nog steeds de mogelijkheid om een van je kolommen te hergebruiken en deze als index te gebruiken. Dat doe je eenvoudig door set_index() aan te roepen op je DataFrame. Probeer het hieronder!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9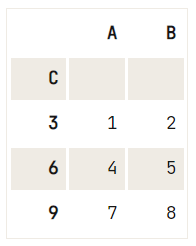
Voordat je naar de oplossing gaat, is het goed om het concept van loc te begrijpen en hoe het verschilt van andere indexeringsattributen zoals .iloc[] en .ix[]:
Dit lijkt misschien ingewikkeld. Laten we het illustreren met een klein voorbeeld:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Merk op dat we hier een DataFrame gebruiken die niet uitsluitend op gehele getallen is gebaseerd om het verschil makkelijker te maken. Je ziet duidelijk dat 2 doorgeven aan .loc[] of .iloc[]/.ix[] niet hetzelfde resultaat oplevert!
48 1
49 2
50 3.iloc[] kijkt naar de posities in de index. Wanneer je 2 doorgeeft, krijg je terug:48 7
49 8
50 9.ix[] hetzelfde gedrag vertonen als iloc en kijken naar de posities in de index. Je krijgt hetzelfde resultaat als met .iloc[].Nu het verschil tussen .iloc[], .loc[] en .ix[] duidelijk is, ben je klaar om rijen aan je DataFrame toe te voegen!
Tip: als gevolg van wat je net hebt gelezen, snap je nu ook dat het algemene advies is om .loc te gebruiken om rijen in je DataFrame in te voegen. Als je df.ix[] zou gebruiken, kun je proberen een numerieke index te refereren met de indexwaarde en per ongeluk een bestaande rij overschrijven. Dat wil je vermijden!
Bekijk het verschil nog eens in de onderstaande DataFrame:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Je ziet waarom dit verwarrend kan zijn, toch?
In sommige gevallen wil je je index onderdeel maken van je DataFrame. Dat kan eenvoudig door een kolom uit je DataFrame te nemen of te verwijzen naar een kolom die je nog niet hebt gemaakt en die toe te wijzen aan de eigenschap .index, zoals hier:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2Met andere woorden, je vertelt je DataFrame dat hij kolom A als index moet nemen.
Als je echter kolommen aan je DataFrame wilt toevoegen, kun je ook dezelfde aanpak volgen als bij het toevoegen van een index aan je DataFrame: je gebruikt .loc[] of .iloc[]. In dit geval voeg je met behulp van .loc[] een Series toe aan een bestaande DataFrame:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Onthoud dat een Series-object erg lijkt op een kolom van een DataFrame. Dat verklaart waarom je eenvoudig een Series aan een bestaande DataFrame kunt toevoegen. Merk ook op dat de eerdere opmerking over .loc[] geldig blijft, zelfs wanneer je kolommen aan je DataFrame toevoegt!
Wanneer je index er niet helemaal uitziet zoals je wilt, kun je ervoor kiezen hem te resetten. Dat kan eenvoudig met .reset_index(). Let wel op, want je kunt verschillende argumenten doorgeven die het succes van je reset kunnen maken of breken:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Je kunt proberen het argument drop in het bovenstaande voorbeeld te vervangen door inplace en kijken wat er gebeurt!
Let op hoe je het argument drop gebruikt om aan te geven dat je de bestaande index wilt verwijderen. Als je inplace had gebruikt, zou de oorspronkelijke index met floats als extra kolom aan je DataFrame zijn toegevoegd.
Nu je hebt gezien hoe je indexen, rijen en kolommen selecteert en toevoegt aan je DataFrame, is het tijd voor een andere usecase: deze drie uit je datastructuur verwijderen.
Als je de index uit je DataFrame wilt verwijderen, moet je dat heroverwegen, want DataFrames en Series hebben altijd een index.
Wat je echter wél kunt doen is bijvoorbeeld:
del df.index.name uit te voeren,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')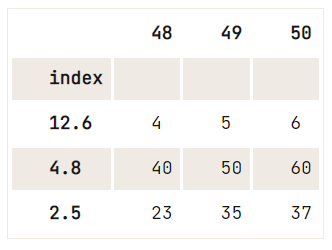
Nu je weet hoe je een index uit je DataFrame verwijdert, kun je verder met het verwijderen van kolommen en rijen!
Om (een selectie van) kolommen uit je DataFrame weg te halen, kun je de methode drop() gebruiken:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9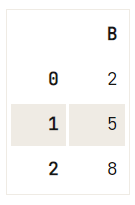
Je denkt nu misschien: dit is niet zo rechttoe rechtaan; Er worden wat extra argumenten doorgegeven aan de methode drop()!
axis is ofwel 0 wanneer het rijen aanduidt en 1 als het wordt gebruikt om kolommen te droppen.inplace op True zetten om de kolom te verwijderen zonder de DataFrame opnieuw te hoeven toewijzen.Je kunt dubbele rijen uit je DataFrame verwijderen door df.drop_duplicates() uit te voeren. Je kunt ook rijen verwijderen uit je DataFrame waarbij je alleen rekening houdt met de dubbele waarden die in één kolom bestaan.
Bekijk dit voorbeeld:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37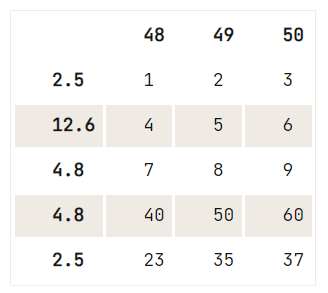
Als er geen uniekheidscriterium is voor de verwijdering die je wilt uitvoeren, kun je de methode drop() gebruiken, waarbij je met de eigenschap index aangeeft welke rijen je uit je DataFrame wilt verwijderen:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37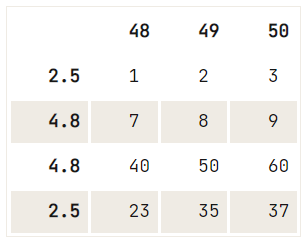
Na dit commando wil je misschien de index opnieuw resetten.
Tip: probeer zelf de index van de resulterende DataFrame te resetten! Vergeet niet het argument drop te gebruiken als je dat nodig acht.
Om de kolommen of je indexwaarden van je DataFrame een andere waarde te geven, gebruik je het best de methode .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9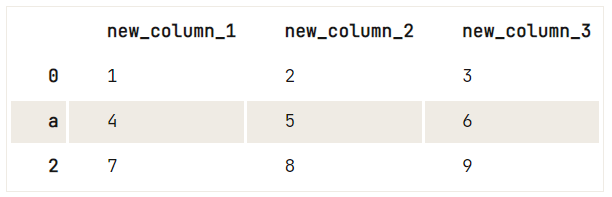
Tip: probeer het argument inplace in de eerste taak (je kolommen hernoemen) te veranderen naar False en kijk wat het script nu als resultaat geeft. Je ziet dat de DataFrame nu niet is heringesteld bij het hernoemen van de kolommen. Daardoor neemt de tweede taak de oorspronkelijke DataFrame als input en niet degene die je net terugkreeg van de eerste rename()-operatie.
Nu je een eerste set vragen over Pandas’ DataFrames hebt doorlopen, is het tijd om verder te gaan dan de basis en echt je handen vuil te maken, want er is veel meer aan DataFrames dan wat je in het eerste deel hebt gezien.
Meestal wil je ook bewerkingen kunnen doen op de daadwerkelijke waarden die in je DataFrame zitten. In de volgende secties behandel je verschillende manieren waarop je de waarden van je pandas DataFrame kunt formatteren.
Om bepaalde strings in je DataFrame te vervangen, kun je eenvoudig replace() gebruiken: geef de waarden door die je wilt veranderen, gevolgd door de waarden waarmee je ze wilt vervangen.
Zo dus:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor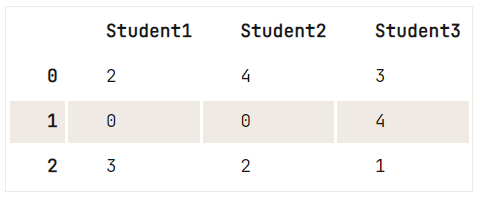
Let op dat er ook een argument regex is dat je enorm kan helpen wanneer je te maken krijgt met vreemde stringcombinaties:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9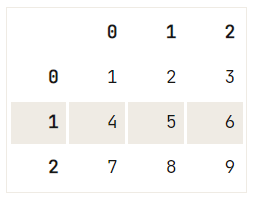
Kortom, replace() is meestal wat je nodig hebt als je waarden of strings in je DataFrame door andere wilt vervangen!
Ongewenste delen uit strings verwijderen is lastig werk. Gelukkig is er een eenvoudige oplossing voor dit probleem!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Je gebruikt map() op kolom result om de lambda-functie elementgewijs op elk element van de kolom toe te passen. De functie zelf neemt de stringwaarde en stript het + of - aan de linkerkant, en haalt ook de zes tekens aAbBcC aan de rechterkant weg.
Dit is een wat lastigere formatteringsopdracht. Toch loodst het volgende codeblok je door de stappen:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12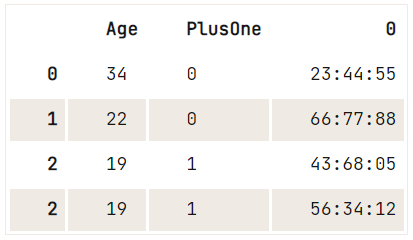
Kort gezegd doe je het volgende:
Ticket uit de DataFrame df en splitst strings op een spatie. Zo komen de twee tickets uiteindelijk in twee aparte rijen terecht. Vervolgens zet je deze vier waarden (de vier ticketnummers) in een Series-object: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN-waarden in! Je moet de Series stacken om ervoor te zorgen dat er geen NaN-waarden in de resulterende Series zitten.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket verwijderen.Je wilt de data in je DataFrame misschien aanpassen door er een functie op toe te passen. Laten we beginnen met het maken van je eigen lambda-functie:
doubler = lambda x: x*2Tip: als je meer wilt weten over functies in Python, bekijk dan deze Python-tutorial over functies.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Let op dat je ook de rij van je DataFrame kunt selecteren en de lambda-functie doubler daarop kunt toepassen. Onthoud dat je eenvoudig een rij uit je DataFrame kunt selecteren met .loc[] of .iloc[].
Dan voer je iets uit als dit, afhankelijk van of je je index op positie of op label wilt selecteren:
df.loc[0].apply(doubler)Let op dat de functie apply() de functie doubler alleen toepast langs de as van je DataFrame. Dat betekent dat je ofwel de index ofwel de kolommen target. Of, met andere woorden, een rij of een kolom.
Wil je het echter op elk element toepassen, dus elementgewijs, dan kun je gebruikmaken van de functie map(). Je kunt de functie apply() in het bovenstaande codeblok gewoon vervangen door map(). Vergeet niet nog steeds de functie doubler door te geven om ervoor te zorgen dat je de waarden met 2 vermenigvuldigt.
Stel dat je deze verdubbelingsfunctie niet alleen op de kolom A van je DataFrame wilt toepassen, maar op de hele DataFrame. In dat geval kun je applymap() gebruiken om de functie doubler op elk element in de hele DataFrame toe te passen:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Let op dat we in deze gevallen hebben gewerkt met lambda-functies of anonieme functies die tijdens runtime worden gemaakt. Je kunt echter ook je eigen functie schrijven. Bijvoorbeeld:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Wil je meer informatie over de stroom van controlestromen in Python, bekijk dan gerust onze andere bronnen.
De functie die je gebruikt is de Pandas-Dataframe()-functie: je geeft de data door die je wilt plaatsen, de indexen en de kolommen.
Onthoud dat de data die in de data frame zit niet homogeen hoeft te zijn. Het kan uit verschillende datatypes bestaan!
Er zijn verschillende manieren om deze functie te gebruiken om een lege DataFrame te maken. Ten eerste kun je numpy.nan gebruiken om je data frame te initialiseren met NaN’s. Merk op dat numpy.nan het type float heeft.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNOp dit moment wordt het datatype van de data frame standaard afgeleid: omdat numpy.nan het type float heeft, bevat de data frame ook waarden van het type float. Je kunt de DataFrame echter ook dwingen een bepaald type te hebben door het attribuut dtype toe te voegen en het gewenste type in te vullen. Zoals in dit voorbeeld:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNMerk op dat als je de aslabels of index niet specificeert, ze op basis van gezond verstandregels uit de inputdata worden geconstrueerd.
Pandas kan het herkennen, maar je moet een beetje helpen: voeg het argument parse_dates toe wanneer je data inleest uit bijvoorbeeld een comma-separated value (CSV)-bestand:
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Er zijn echter altijd vreemde datum-tijdformaten.
Geen zorgen! In zulke gevallen kun je je eigen parser maken om dit af te handelen. Je zou bijvoorbeeld een lambda-functie kunnen maken die je DateTime neemt en deze controleert met een formatstring.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Je DataFrame reshapen is hem transformeren zodat de resulterende structuur geschikter wordt voor je data-analyse. Met andere woorden, reshapen gaat niet zozeer over het formatteren van de waarden in de DataFrame, maar meer over het transformeren van de vorm ervan.
Dat beantwoordt het wanneer en waarom. Maar hoe reshape je je DataFrame?
Er zijn drie manieren van reshapen die vaak vragen oproepen bij gebruikers: pivotten, stacken en unstacken, en melten.
Je kunt de functie pivot() gebruiken om een nieuwe afgeleide tabel uit je oorspronkelijke te maken. Wanneer je de functie gebruikt, kun je drie argumenten doorgeven:
values: hiermee geef je aan welke waarden van je oorspronkelijke DataFrame je in je draaitabel wilt zien.columns: wat je hieraan doorgeeft, wordt een kolom in je resulterende tabel.index: wat je hieraan doorgeeft, wordt een index in je resulterende tabel.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Wanneer je niet specifiek invult welke waarden je verwacht in je resulterende tabel, pivot je over meerdere kolommen:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Let op dat je data geen rijen mag hebben met dubbele waarden voor de kolommen die je specificeert. Als dat niet zo is, krijg je een foutmelding. Als je de uniciteit van je data niet kunt garanderen, wil je in plaats daarvan de methode pivot_table gebruiken:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Let op het extra argument aggfunc dat wordt doorgegeven aan de methode pivot_table. Dit argument geeft aan dat je een aggregatiefunctie gebruikt om meerdere waarden te combineren. In dit voorbeeld zie je duidelijk dat de functie mean wordt gebruikt.
stack() en unstack() gebruiken om je Pandas DataFrame te reshapenJe hebt in sectie 5 al een voorbeeld van stacken gezien. In essentie herinner je je misschien nog dat je een DataFrame hoger maakt wanneer je hem stackt. Je verplaatst de binnenste kolomindex zodat die de binnenste rijindex wordt. Je krijgt een DataFrame terug met een index met een nieuw, binnenste niveau van rijlabels.
Ga terug naar de volledige walkthrough in sectie 5 als je niet zeker bent van de werking vanstack().
Het omgekeerde van stacken heet unstacken. Net als bij stack() gebruik je unstack() om de binnenste rijindex de binnenste kolomindex te laten worden.
Voor een uitleg van pands pivotten, stacken en unstacken, bekijk onze cursus Reshaping Data with pandas.
melt()Melten is nuttig in gevallen waarin je data hebt met één of meer kolommen die identificerende variabelen zijn, terwijl alle andere kolommen als gemeten variabelen worden beschouwd.
Deze gemeten variabelen worden allemaal “ontpivot” naar de rij-as. Dat wil zeggen: terwijl de gemeten variabelen over de breedte van de DataFrame waren verspreid, zorgt de melt ervoor dat ze op de hoogte terechtkomen. Of, anders gezegd, je DataFrame wordt nu langer in plaats van breder.
Als resultaat heb je twee niet-identificerende kolommen, namelijk ‘variable’ en ‘value’.
Laten we dit illustreren met een voorbeeld:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Zoek je meer manieren om je data te reshapen, bekijk dan de documentatie.
Je kunt over de rijen van je DataFrame itereren met behulp van een for-loop in combinatie met een iterrows()-aanroep op je DataFrame:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() laat je efficiënt over je DataFrame-rijen lopen als paren (index, Series). Met andere woorden, het geeft je (index, rij)-tuples als resultaat.
Als je je datamunging en -manipulatie met Pandas hebt gedaan, wil je de DataFrame misschien exporteren naar een ander formaat. Deze sectie behandelt twee manieren om je pandas DataFrame uit te schrijven naar een CSV- of Excel-bestand.
Om een DataFrame als CSV-bestand te schrijven, kun je to_csv() gebruiken:
import pandas as pd
df.to_csv('myDataFrame.csv')Dat stukje code lijkt vrij simpel, maar hier beginnen voor de meesten de moeilijkheden, omdat je specifieke eisen hebt voor de output van je data. Misschien wil je geen komma als scheidingsteken, of wil je een specifieke encoding opgeven.
Geen zorgen! Je kunt extra argumenten doorgeven aan to_csv() om ervoor te zorgen dat je data wordt weggeschreven zoals jij wilt!
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding gebruiken:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN- of missende waarden moeten worden weergegeven, of je de header wilt uitschrijven, of je rijlabels wilt wegschrijven, of je compressie wilt, enzovoort. Je kunt de opties nalezen.Net als bij het wegschrijven van je DataFrame naar CSV, kun je to_excel() gebruiken om je tabel naar Excel te schrijven. Dat is echter net iets complexer:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Let wel, net als bij to_csv() heb je veel extra argumenten zoals startcol, startrow, enzovoort, om je data correct weg te schrijven. Je kunt meer leren over hoe je data importeert uit en exporteert naar CSV-bestanden met pandas in onze tutorial.
Wil je echter meer informatie over IO-tools in Pandas, bekijk dan de pandas documentatie over DataFrames naar Excel.
Dat was het! Je hebt de Pandas DataFrame-tutorial succesvol afgerond!
De antwoorden op de 11 veelgestelde Pandas-vragen vertegenwoordigen essentiële functies die je nodig hebt om je data te importeren, schoon te maken en te manipuleren voor je data science-werk. Weet je niet zeker of je hier diep genoeg in bent gegaan? Onze cursus Importing Data In Python helpt je op weg! Als je dit onder de knie hebt, wil je misschien Pandas aan het werk zien in een echte case. De tutorialserie The Importance of Preprocessing in Data Science and the Machine Learning Pipeline is een must-read, en de open cursus Introduction to Python & Machine Learning is een must-do.
Leer meer over Python en pandas
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
