Courses
Nhập dữ liệu nâng cao trong Python
2 giờ
210.6K

Pandas là một gói Python phổ biến cho khoa học dữ liệu, và có lý do chính đáng: nó cung cấp các cấu trúc dữ liệu mạnh mẽ, biểu đạt và linh hoạt, giúp việc thao tác và phân tích dữ liệu trở nên dễ dàng, cùng nhiều thứ khác. DataFrame là một trong những cấu trúc đó.
Hướng dẫn này giới thiệu về pandas DataFrame, từ thao tác cơ bản đến các thao tác nâng cao, thông qua 11 câu hỏi phổ biến nhất để bạn hiểu rõ —và tránh— những băn khoăn của các Pythonista đi trước.
Để luyện tập thêm, hãy thử miễn phí chương đầu của khóa học Pandas DataFrames này!
Trước khi bắt đầu, hãy cùng điểm lại nhanh DataFrame là gì.
Những ai quen với R biết data frame là cách lưu trữ dữ liệu dưới dạng lưới hình chữ nhật dễ quan sát. Mỗi hàng trong lưới tương ứng với các phép đo hay giá trị của một thực thể, trong khi mỗi cột là một vector chứa dữ liệu cho một biến cụ thể. Điều này có nghĩa là các hàng của data frame không nhất thiết phải chứa cùng một kiểu giá trị: có thể là số, ký tự, logic, v.v.
Giờ đây, DataFrame trong Python rất giống như vậy: chúng đi kèm thư viện pandas và được định nghĩa là cấu trúc dữ liệu hai chiều có nhãn, với các cột có thể thuộc nhiều kiểu khác nhau.
Nói chung, bạn có thể cho rằng pandas DataFrame gồm ba thành phần chính: dữ liệu, chỉ mục (index) và các cột (columns).
DataFrame của PandasSeries của Pandas: mảng một chiều có nhãn, có thể chứa bất kỳ kiểu dữ liệu nào, với nhãn trục hoặc chỉ mục. Ví dụ về đối tượng Series là một cột trong DataFrame.ndarray của NumPy, có thể là record hoặc structuredndarray hai chiềundarray một chiều, list, dictionary hoặc Series.Lưu ý sự khác biệt giữa np.ndarray và np.array(). Cái đầu là một kiểu dữ liệu thực sự, còn cái sau là một hàm để tạo mảng từ các cấu trúc dữ liệu khác.
Mảng có cấu trúc (structured arrays) cho phép người dùng thao tác dữ liệu bằng các trường có tên: trong ví dụ dưới đây, một mảng có cấu trúc gồm ba bộ giá trị (tuple) được tạo. Phần tử đầu tiên của mỗi tuple sẽ được gọi là foo và có kiểu int, trong khi phần tử thứ hai sẽ được đặt tên bar và là số thực (float).
Ngược lại, mảng record (record arrays) mở rộng đặc tính của mảng có cấu trúc. Chúng cho phép truy cập các trường của mảng có cấu trúc bằng thuộc tính thay vì chỉ mục. Bạn thấy dưới đây các giá trị foo được truy cập trong mảng record r2.
Ví dụ:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Nếu bạn vẫn còn băn khoăn về Pandas DataFrame và cách chúng khác với các cấu trúc dữ liệu khác như mảng NumPy hoặc Series, bạn có thể xem bài thuyết trình ngắn dưới đây:
Lưu ý rằng trong bài viết này, hầu hết thời gian, các thư viện cần thiết đã được nạp sẵn. Thư viện Pandas thường được import với bí danh pd, trong khi thư viện NumPy được nạp là np. Hãy nhớ rằng khi bạn viết mã trong môi trường khoa học dữ liệu của riêng mình, đừng quên bước import này, bạn viết như sau:
import numpy as np
import pandas as pdGiờ thì bạn đã nắm rõ DataFrame là gì, làm được gì và khác biệt ra sao với các cấu trúc khác, đã đến lúc giải quyết những câu hỏi thường gặp nhất khi làm việc với chúng!
Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãRõ ràng, việc tạo DataFrame là bước đầu tiên trong hầu như mọi việc bạn muốn làm khi xử lý dữ liệu trong Python. Đôi khi, bạn sẽ muốn bắt đầu từ đầu, nhưng bạn cũng có thể chuyển đổi các cấu trúc dữ liệu khác, như list hoặc mảng NumPy, thành Pandas DataFrame. Trong phần này, bạn chỉ đề cập đến cách sau. Tuy nhiên, nếu bạn muốn đọc thêm về tạo DataFrame rỗng để điền dữ liệu sau, hãy đến phần 7.
Trong số nhiều thứ có thể làm đầu vào để tạo một ‘DataFrame’, ndarray của NumPy là một trong số đó. Để tạo data frame từ mảng NumPy, bạn chỉ cần truyền nó vào hàm DataFrame() ở tham số data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Hãy chú ý cách các đoạn mã trên chọn phần tử từ mảng NumPy để tạo DataFrame: bạn đầu tiên chọn các giá trị nằm trong các list bắt đầu bằng Row1 và Row2, sau đó bạn chọn chỉ mục hoặc số hàng Row1 và Row2 rồi đến tên cột Col1 và Col2.
Tiếp theo, bạn cũng thấy rằng, trong ví dụ trên, chúng ta in ra một phần nhỏ dữ liệu. Cách này giống với việc lấy lát (subset) mảng NumPy 2D: bạn chỉ định hàng trước, rồi đến cột. Đừng quên rằng chỉ mục bắt đầu từ 0! Với data trong ví dụ trên, bạn xem các hàng từ chỉ số 1 đến hết, và chọn tất cả phần tử sau chỉ số 1. Kết quả, bạn chọn được 1, 2, 3 và 4.
Cách tiếp cận tạo DataFrame này giống nhau cho mọi cấu trúc mà DataFrame() có thể nhận làm đầu vào.
Xem ví dụ dưới đây:
Hãy nhớ rằng thư viện Pandas đã được import dưới bí danh pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Lưu ý rằng chỉ mục của Series (và DataFrame) của bạn chứa các khóa của dictionary gốc, nhưng đã được sắp xếp: Belgium sẽ là chỉ mục tại 0, trong khi United States sẽ ở chỉ mục 3.
Sau khi tạo DataFrame, bạn có thể muốn biết thêm về nó. Bạn có thể dùng thuộc tính shape hoặc hàm len() kết hợp với thuộc tính .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Hai tùy chọn này cung cấp thông tin hơi khác nhau về DataFrame của bạn: thuộc tính shape cho bạn biết kích thước DataFrame, tức là chiều rộng và chiều cao. Mặt khác, hàm len() kết hợp với thuộc tính index chỉ cho bạn thông tin về chiều cao của DataFrame.
Tất nhiên điều này không có gì lạ, vì bạn đã truyền rõ thuộc tính index.
Bạn cũng có thể dùng df[0].count() để biết thêm về chiều cao DataFrame, nhưng cách này sẽ loại trừ các giá trị NaN (nếu có). Đó là lý do gọi .count() trên DataFrame không phải lúc nào cũng là lựa chọn tốt hơn.
Nếu muốn biết thêm thông tin về các cột của DataFrame, bạn có thể chạy list(my_dataframe.columns.values).
Giờ bạn đã đưa dữ liệu vào cấu trúc Pandas DataFrame thuận tiện hơn, đã đến lúc bắt tay vào công việc thực sự!
Phần đầu tiên này sẽ hướng dẫn bạn những bước đầu làm việc với DataFrame trong Python. Nó sẽ bao gồm các thao tác cơ bản mà bạn có thể thực hiện trên DataFrame mới tạo: thêm, chọn, xóa, đổi tên và hơn thế nữa.
Trước khi bắt đầu thêm, xóa và đổi tên các thành phần của DataFrame, bạn cần biết cách chọn các phần tử đó. Vậy làm thế nào?
Mặc dù bạn có thể còn nhớ cách làm từ phần trước: chọn chỉ mục, cột hoặc giá trị từ DataFrame không hề khó, thậm chí còn khá đơn giản. Nó tương tự như những gì bạn thấy trong các ngôn ngữ (hoặc gói!) khác dùng cho phân tích dữ liệu. Nếu bạn chưa tin, hãy xem xét điều sau:
Trong R, bạn dùng ký hiệu [,] để truy cập các giá trị của data frame.
Giờ, giả sử bạn có một DataFrame như sau:
A B C
0 1 2 3
1 4 5 6
2 7 8 9Và bạn muốn truy cập giá trị tại chỉ mục 0, ở cột ‘A’.
Có nhiều cách để nhận lại giá trị 1 của bạn:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Quan trọng nhất cần nhớ chắc chắn là .loc[] và .iloc[]. Sự khác biệt tinh tế giữa hai cách này sẽ được bàn trong các phần tiếp theo.
Tạm đủ về chọn giá trị từ DataFrame. Còn chọn hàng và cột thì sao? Khi đó, bạn sẽ dùng:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Hiện tại, chỉ cần biết rằng bạn có thể truy cập giá trị bằng cách gọi theo nhãn hoặc theo vị trí trong chỉ mục hoặc cột. Nếu bạn chưa thấy rõ, hãy nhìn lại sự khác biệt nhỏ trong lệnh: có lúc bạn thấy [0][0], lúc khác bạn thấy [0,'A'] để lấy lại giá trị 1.
Bây giờ bạn đã biết cách chọn một giá trị từ DataFrame, đã đến lúc bắt tay vào việc thực sự và thêm chỉ mục, hàng hoặc cột vào đó!
Khi tạo DataFrame, bạn có thể truyền vào tham số ‘index’ để chắc chắn có được chỉ mục như mong muốn. Khi không chỉ định, DataFrame của bạn mặc định sẽ có chỉ mục số bắt đầu từ 0 và tiếp tục đến hàng cuối cùng.
Tuy nhiên, ngay cả khi chỉ mục được tự động tạo, bạn vẫn có thể tái sử dụng một trong các cột để làm chỉ mục. Bạn có thể làm điều này dễ dàng bằng cách gọi set_index() trên DataFrame. Hãy thử dưới đây!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9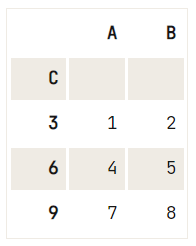
Trước khi đi đến lời giải, trước hết nên nắm khái niệm loc và cách nó khác với các thuộc tính lập chỉ mục khác như .iloc[] và .ix[]:
Tất cả những điều này có thể có vẻ phức tạp. Hãy minh họa bằng ví dụ nhỏ:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Lưu ý trong trường hợp này, bạn dùng ví dụ DataFrame không chỉ gồm số nguyên để dễ hiểu khác biệt. Rõ ràng truyền 2 vào .loc[] hoặc .iloc[]/.ix[] không cho cùng kết quả!
48 1
49 2
50 3.iloc[] sẽ tìm theo vị trí trong chỉ mục. Khi bạn truyền 2, bạn sẽ nhận lại:48 7
49 8
50 9.ix[] sẽ có hành vi như iloc và tìm theo vị trí trong chỉ mục. Bạn sẽ nhận lại cùng kết quả như .iloc[].Giờ sự khác biệt giữa .iloc[], .loc[] và .ix[] đã rõ, bạn sẵn sàng thử thêm hàng vào DataFrame!
Mẹo: hệ quả của những gì bạn vừa đọc là khuyến nghị chung là dùng .loc để chèn hàng vào DataFrame. Bởi nếu dùng df.ix[], bạn có thể vô tình tham chiếu một chỉ mục dạng số bằng giá trị chỉ mục và ghi đè lên một hàng hiện có trong DataFrame. Hãy tránh điều đó!
Hãy xem lại sự khác biệt trong DataFrame dưới đây:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Bạn thấy vì sao tất cả điều này có thể gây nhầm lẫn rồi chứ?
Trong một số trường hợp, bạn muốn đưa chỉ mục thành một phần của DataFrame. Bạn có thể làm điều này dễ dàng bằng cách lấy một cột từ DataFrame hoặc tham chiếu đến một cột bạn chưa tạo rồi gán nó cho thuộc tính .index, như sau:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2Nói cách khác, bạn nói với DataFrame rằng nó nên lấy cột A làm chỉ mục của mình.
Tuy nhiên, nếu bạn muốn thêm cột vào DataFrame, bạn cũng có thể làm theo cách giống như khi thêm chỉ mục: dùng .loc[] hoặc .iloc[]. Ở đây, bạn thêm một Series vào DataFrame hiện có với sự trợ giúp của .loc[]:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Hãy nhớ đối tượng Series rất giống một cột của DataFrame. Điều đó lý giải vì sao bạn có thể dễ dàng thêm Series vào DataFrame. Cũng lưu ý rằng nhận xét trước đó về .loc[] vẫn đúng, ngay cả khi bạn đang thêm cột vào DataFrame!
Khi chỉ mục không như ý, bạn có thể chọn đặt lại. Bạn có thể làm điều này dễ dàng với .reset_index(). Tuy nhiên, bạn vẫn nên chú ý, vì có thể truyền một số tham số có thể quyết định thành công hay thất bại của việc đặt lại:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Bạn có thể thử thay tham số drop bằng inplace trong ví dụ trên và xem điều gì xảy ra!
Lưu ý cách bạn dùng tham số drop để chỉ ra rằng bạn muốn loại bỏ chỉ mục hiện có. Nếu bạn dùng inplace, chỉ mục gốc dạng số thực sẽ được thêm làm một cột phụ vào DataFrame.
Giờ bạn đã biết cách chọn và thêm chỉ mục, hàng, cột vào DataFrame, đã đến lúc xem xét trường hợp khác: loại bỏ ba thành phần này khỏi cấu trúc dữ liệu.
Nếu bạn muốn loại bỏ chỉ mục khỏi DataFrame, bạn nên cân nhắc lại vì DataFrame và Series luôn có chỉ mục.
Tuy nhiên, những gì bạn có thể làm là, ví dụ:
del df.index.name,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')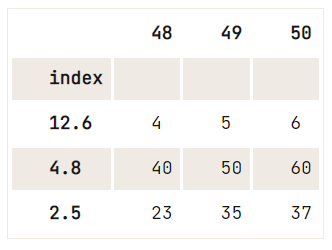
Giờ bạn đã biết cách loại bỏ một chỉ mục khỏi DataFrame, bạn có thể tiếp tục xóa cột và hàng!
Để loại bỏ (một lựa chọn) các cột khỏi DataFrame, bạn có thể dùng phương thức drop():
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9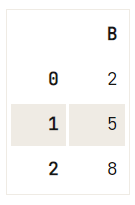
Bạn có thể nghĩ: điều này không quá đơn giản; Có một số tham số bổ sung được truyền vào phương thức drop()!
axis là 0 khi chỉ hàng và 1 khi dùng để xóa cột.inplace là True để xóa cột mà không cần gán lại DataFrame.Bạn có thể loại bỏ các hàng trùng lặp khỏi DataFrame bằng cách chạy df.drop_duplicates(). Bạn cũng có thể xóa hàng, chỉ xét các giá trị trùng lặp tồn tại trong một cột.
Xem ví dụ sau:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37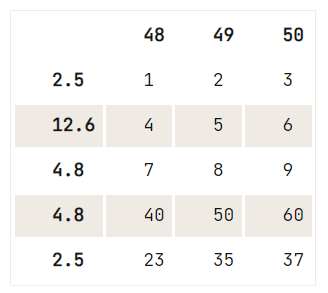
Nếu không có tiêu chí duy nhất cho việc xóa bạn muốn thực hiện, bạn có thể dùng phương thức drop(), trong đó dùng thuộc tính index để chỉ định chỉ mục của các hàng bạn muốn xóa khỏi DataFrame:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37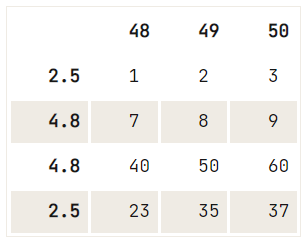
Sau lệnh này, bạn có thể sẽ muốn đặt lại chỉ mục.
Mẹo: hãy tự thử đặt lại chỉ mục của DataFrame kết quả! Đừng quên dùng tham số drop nếu bạn thấy cần thiết.
Để gán giá trị khác cho các cột hoặc các giá trị chỉ mục của DataFrame, tốt nhất bạn nên dùng phương thức .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9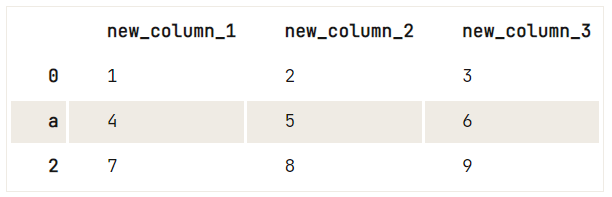
Mẹo: hãy thử đổi tham số inplace trong tác vụ đầu tiên (đổi tên các cột) thành False và xem script trả về gì. Bạn sẽ thấy DataFrame không được gán lại khi đổi tên các cột. Kết quả là tác vụ thứ hai nhận DataFrame gốc làm đầu vào, không phải DataFrame bạn vừa nhận từ thao tác rename() đầu tiên.
Giờ bạn đã đi qua bộ câu hỏi đầu tiên về Pandas DataFrame, đã đến lúc vượt qua phần cơ bản và thực sự lăn tay vào việc, vì còn nhiều điều hơn thế về DataFrame so với những gì bạn đã thấy ở phần đầu.
Phần lớn thời gian, bạn cũng sẽ muốn có thể thực hiện một số thao tác trên các giá trị thực sự có trong DataFrame. Trong các phần sau, bạn sẽ tìm hiểu một số cách định dạng các giá trị trong pandas DataFrame
Để thay thế các chuỗi nhất định trong DataFrame, bạn có thể dùng replace(): truyền vào các giá trị bạn muốn thay, tiếp theo là các giá trị bạn muốn thay thế bằng.
Như sau:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor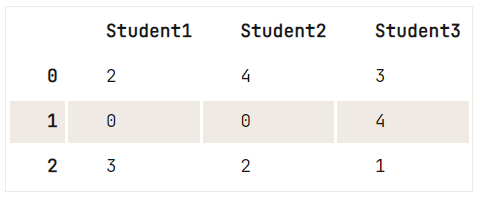
Lưu ý rằng còn có tham số regex có thể giúp bạn rất nhiều khi gặp các tổ hợp chuỗi lạ:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9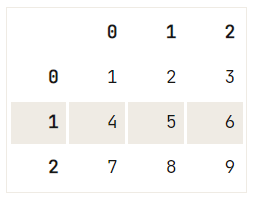
Tóm lại, replace() là thứ bạn cần khi muốn thay thế các giá trị hoặc chuỗi trong DataFrame bằng giá trị khác!
Loại bỏ các phần không mong muốn của chuỗi là công việc tẻ nhạt. May mắn thay, có giải pháp dễ dàng!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Bạn dùng map() trên cột result để áp dụng hàm lambda cho từng phần tử của cột. Bản thân hàm lấy giá trị chuỗi và loại bỏ ký tự + hoặc - ở bên trái, đồng thời bỏ đi bất kỳ trong sáu ký tự aAbBcC ở bên phải.
Đây là một tác vụ định dạng khó hơn đôi chút. Tuy nhiên, đoạn mã sau sẽ hướng dẫn bạn từng bước:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12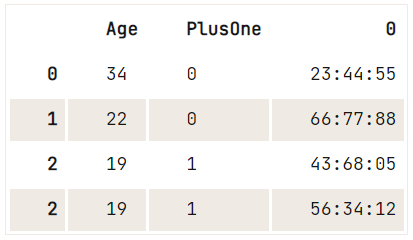
Tóm lại, những gì bạn làm là:
Ticket từ DataFrame df và tách chuỗi theo dấu cách. Điều này đảm bảo hai vé sẽ được tách thành hai hàng riêng về sau. Tiếp theo, bạn đưa bốn giá trị này (bốn số vé) vào một đối tượng Series: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN trong đó! Bạn cần stack Series để đảm bảo không còn NaN trong Series kết quả.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket gốc.Bạn có thể muốn điều chỉnh dữ liệu trong DataFrame bằng cách áp dụng một hàm cho nó. Hãy bắt đầu bằng cách tạo hàm lambda của riêng bạn:
doubler = lambda x: x*2Mẹo: nếu bạn muốn biết thêm về hàm trong Python, hãy xem hướng dẫn về hàm Python này.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Lưu ý rằng bạn cũng có thể chọn một hàng của DataFrame và áp dụng hàm lambda doubler cho nó. Hãy nhớ bạn có thể dễ dàng chọn một hàng từ DataFrame bằng .loc[] hoặc .iloc[].
Sau đó, bạn sẽ chạy một lệnh như sau, tùy vào việc bạn muốn chọn chỉ mục theo vị trí hay theo nhãn:
df.loc[0].apply(doubler)Lưu ý rằng hàm apply() chỉ áp dụng hàm doubler dọc theo một trục của DataFrame. Nghĩa là bạn hướng đến hoặc chỉ mục hoặc các cột. Hoặc nói cách khác, một hàng hoặc một cột.
Tuy nhiên, nếu bạn muốn áp dụng theo từng phần tử (element-wise), bạn có thể dùng hàm map(). Bạn chỉ cần thay apply() trong đoạn mã trên bằng map(). Đừng quên vẫn truyền hàm doubler để nhân các giá trị với 2.
Giả sử bạn muốn áp dụng hàm nhân đôi này không chỉ cho cột A mà cho toàn bộ DataFrame. Trong trường hợp này, bạn có thể dùng applymap() để áp dụng hàm doubler cho từng phần tử trong toàn bộ DataFrame:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Lưu ý rằng trong các trường hợp này, chúng ta làm việc với các hàm lambda hoặc hàm ẩn danh được tạo tại thời điểm chạy. Tuy nhiên, bạn cũng có thể tự viết hàm của mình. Ví dụ:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Nếu bạn muốn biết thêm về luồng điều khiển trong Python, bạn luôn có thể xem các tài nguyên khác của chúng tôi.
Hàm bạn sẽ dùng là hàm Dataframe() của Pandas: nó yêu cầu bạn truyền dữ liệu muốn đưa vào, chỉ mục và các cột.
Hãy nhớ rằng dữ liệu trong data frame không nhất thiết phải đồng nhất. Nó có thể thuộc các kiểu dữ liệu khác nhau!
Có một số cách bạn có thể dùng hàm này để tạo DataFrame rỗng. Thứ nhất, bạn có thể dùng numpy.nan để khởi tạo data frame với các giá trị NaN. Lưu ý numpy.nan có kiểu float.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNHiện tại, kiểu dữ liệu của data frame được suy ra theo mặc định: vì numpy.nan có kiểu float, data frame cũng sẽ chứa các giá trị kiểu float. Tuy nhiên, bạn cũng có thể ép DataFrame về kiểu cụ thể bằng cách thêm thuộc tính dtype và điền kiểu mong muốn. Như ví dụ sau:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNLưu ý nếu bạn không chỉ định nhãn trục hoặc chỉ mục, chúng sẽ được tạo từ dữ liệu đầu vào dựa trên các quy tắc thông thường.
Pandas có thể nhận diện, nhưng bạn cần hỗ trợ một chút: thêm tham số parse_dates khi bạn đọc dữ liệu từ, ví dụ, tệp giá trị phân tách bằng dấu phẩy (CSV):
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Tuy nhiên, luôn có những định dạng ngày giờ kỳ lạ.
Đừng lo! Trong những trường hợp như vậy, bạn có thể tự xây dựng bộ phân tích (parser) để xử lý. Bạn có thể, ví dụ, tạo một hàm lambda nhận DateTime và kiểm soát nó bằng chuỗi định dạng.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Biến đổi DataFrame là chuyển đổi nó sao cho cấu trúc kết quả phù hợp hơn cho phân tích dữ liệu của bạn. Nói cách khác, reshape không tập trung vào định dạng các giá trị trong DataFrame, mà là biến đổi hình dạng của nó.
Điều này trả lời câu hỏi khi nào và vì sao. Nhưng bằng cách nào bạn sẽ reshape DataFrame?
Có ba cách reshape thường gây thắc mắc: pivot, stacking/unstacking và melting.
Bạn có thể dùng hàm pivot() để tạo một bảng dẫn xuất mới từ bảng gốc. Khi dùng hàm, bạn có thể truyền ba tham số:
values: tham số này cho phép bạn chỉ định những giá trị nào của DataFrame gốc bạn muốn thấy trong bảng pivot.columns: bất cứ thứ gì bạn truyền vào tham số này sẽ trở thành một cột trong bảng kết quả.index: bất cứ thứ gì bạn truyền vào tham số này sẽ trở thành chỉ mục trong bảng kết quả.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Khi bạn không điền rõ các giá trị mong đợi có trong bảng kết quả, bạn sẽ pivot theo nhiều cột:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Lưu ý dữ liệu của bạn không thể có các hàng với giá trị trùng nhau cho các cột bạn chỉ định. Nếu không, bạn sẽ nhận lỗi. Nếu bạn không đảm bảo tính duy nhất của dữ liệu, bạn sẽ muốn dùng phương thức pivot_table thay thế:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Lưu ý tham số bổ sung aggfunc được truyền vào phương thức pivot_table. Tham số này chỉ ra bạn dùng một hàm gộp để kết hợp nhiều giá trị. Trong ví dụ này, rõ ràng hàm mean được dùng.
stack() và unstack() để reshape Pandas DataFrameBạn đã thấy ví dụ về stacking ở phần 5. Về bản chất, bạn có thể vẫn nhớ rằng khi stack một DataFrame, bạn làm nó cao hơn. Bạn chuyển chỉ mục cột trong cùng thành chỉ mục hàng trong cùng. Bạn nhận lại một DataFrame có chỉ mục với một cấp độ nhãn hàng mới ở trong cùng.
Quay lại phần hướng dẫn đầy đủ ở phần 5 nếu bạn chưa chắc về cách hoạt động củastack().
Phép nghịch đảo của stacking gọi là unstacking. Tương tự stack(), bạn dùng unstack() để chuyển chỉ mục hàng trong cùng thành chỉ mục cột trong cùng.
Để giải thích về pivot, stacking và unstacking trong pandas, hãy xem khóa học Reshaping Data with pandas của chúng tôi.
melt()Melting hữu ích trong các trường hợp dữ liệu của bạn có một hoặc nhiều cột là biến định danh (identifier), trong khi tất cả các cột khác được xem là biến đo lường (measured).
Những biến đo lường này đều được “gỡ xoay” (unpivot) xuống trục hàng. Tức là, trong khi các biến đo lường trước đó trải rộng theo chiều ngang của DataFrame, melt sẽ đảm bảo chúng được đưa vào chiều dọc. Hay nói cách khác, DataFrame của bạn sẽ dài hơn thay vì rộng hơn.
Kết quả, bạn có hai cột không phải định danh, là ‘variable’ và ‘value’.
Hãy minh họa bằng ví dụ:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Nếu bạn muốn tìm thêm cách reshape dữ liệu, hãy xem tài liệu.
Bạn có thể lặp qua các hàng của DataFrame với sự trợ giúp của vòng lặp for kết hợp với lời gọi iterrows() trên DataFrame:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() cho phép bạn lặp hiệu quả qua các hàng DataFrame dưới dạng cặp (index, Series). Nói cách khác, nó trả về các bộ (index, row).
Khi bạn đã xử lý và thao tác dữ liệu với Pandas, bạn có thể muốn xuất DataFrame sang định dạng khác. Phần này sẽ giới thiệu hai cách xuất pandas DataFrame ra CSV hoặc tệp Excel.
Để ghi DataFrame thành tệp CSV, bạn có thể dùng to_csv():
import pandas as pd
df.to_csv('myDataFrame.csv')Đoạn mã này có vẻ khá đơn giản, nhưng đây chính là nơi khó khăn bắt đầu với nhiều người vì bạn sẽ có các yêu cầu cụ thể cho đầu ra dữ liệu. Có thể bạn không muốn dấu phẩy làm dấu phân tách, hoặc bạn muốn chỉ định một mã hóa cụ thể.
Đừng lo! Bạn có thể truyền thêm một số tham số cho to_csv() để đảm bảo dữ liệu được xuất theo cách bạn muốn!
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN hay thiếu, có xuất header hay không, có ghi tên hàng hay không, có nén hay không, bạn có thể đọc thêm về các tùy chọn.Tương tự như xuất DataFrame ra CSV, bạn có thể dùng to_excel() để ghi bảng của bạn ra Excel. Tuy nhiên, hơi phức tạp hơn:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Lưu ý rằng, cũng như với to_csv(), bạn có rất nhiều tham số bổ sung như startcol, startrow, v.v., để đảm bảo xuất dữ liệu đúng cách. Bạn có thể tìm hiểu thêm về cách nhập dữ liệu từ và xuất dữ liệu ra tệp CSV bằng pandas trong hướng dẫn của chúng tôi.
Nếu bạn muốn biết thêm về các công cụ IO trong Pandas, hãy xem tài liệu DataFrames to excel của pandas.
Vậy là xong! Bạn đã hoàn thành hướng dẫn Pandas DataFrame!
Câu trả lời cho 11 câu hỏi thường gặp về Pandas đại diện cho các chức năng thiết yếu bạn sẽ cần để nhập, làm sạch và thao tác dữ liệu cho công việc khoa học dữ liệu. Bạn chưa chắc mình đã đào sâu đủ? Khóa học Importing Data In Python sẽ giúp bạn! Nếu bạn đã nắm vững phần này, bạn có thể muốn thấy Pandas hoạt động trong một dự án thực tế. Loạt hướng dẫn Tầm quan trọng của Tiền xử lý trong Khoa học Dữ liệu và Quy trình Machine Learning là tài liệu phải đọc, và khóa học mở Introduction to Python & Machine Learning là khóa nên hoàn thành.
Tìm hiểu thêm về Python và pandas
Courses
Courses
Courses