Corso
Importazione di dati in Python - livello intermedio
2 h
210.7K

Pandas è un popolare pacchetto Python per la data science, e a buon motivo: offre strutture dati potenti, espressive e flessibili che rendono facile la manipolazione e l’analisi dei dati, tra le tante cose. Il DataFrame è una di queste strutture.
Questo tutorial copre i DataFrame di pandas, dalle manipolazioni di base alle operazioni avanzate, affrontando 11 delle domande più comuni così che tu possa capire -e evitare- i dubbi dei Pythonisti che ti hanno preceduto.
Per fare pratica, prova gratis il primo capitolo di questo corso sui DataFrame di Pandas!
Prima di iniziare, facciamo un breve riepilogo di cosa sono i DataFrame.
Chi conosce R sa che il data frame è un modo per archiviare i dati in griglie rettangolari facilmente consultabili. Ogni riga di queste griglie corrisponde a misurazioni o valori di un’istanza, mentre ogni colonna è un vettore che contiene i dati per una variabile specifica. Ciò significa che le righe di un data frame non devono necessariamente contenere lo stesso tipo di valori, anche se possono: numerici, caratteri, logici, ecc.
Ora, i DataFrame in Python sono molto simili: arrivano con la libreria pandas e sono definiti come strutture dati etichettate bidimensionali con colonne potenzialmente di tipi diversi.
In generale, si può dire che un DataFrame di pandas è composto da tre componenti principali: i dati, l’indice e le colonne.
DataFrame di PandasSeries di Pandas: un array unidimensionale etichettato in grado di contenere qualsiasi tipo di dato con etichette di asse o indice. Un esempio di oggetto Series è una colonna di un DataFrame.ndarray di NumPy, che può essere record o strutturatondarray bidimensionalendarray unidimensionali, liste, dizionari o Series.Nota la differenza tra np.ndarray e np.array(). Il primo è un vero e proprio tipo di dato, mentre il secondo è una funzione per creare array da altre strutture dati.
Gli array strutturati permettono di manipolare i dati tramite campi con nome: nell’esempio sotto, viene creato un array strutturato di tre tuple. Il primo elemento di ogni tupla si chiamerà foo e sarà di tipo int, mentre il secondo elemento si chiamerà bar e sarà un float.
Gli array record, invece, estendono le proprietà degli array strutturati. Consentono di accedere ai campi degli array strutturati per attributo invece che per indice. Sotto vedi che i valori di foo sono accessibili nell’array record r2.
Un esempio:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Se hai ancora dubbi sui DataFrame di Pandas e su come differiscono da altre strutture dati come un array NumPy o una Series, puoi guardare la breve presentazione qui sotto:
Nota che in questo post, per la maggior parte delle volte, le librerie di cui hai bisogno sono già state caricate. La libreria Pandas viene solitamente importata con l’alias pd, mentre la libreria NumPy viene caricata come np. Ricorda che quando scrivi codice nel tuo ambiente di data science, non devi dimenticare questo passaggio di import, che si scrive così:
import numpy as np
import pandas as pdOra che non hai più dubbi su cosa sono i DataFrame, cosa possono fare e in cosa differiscono dalle altre strutture, è il momento di affrontare le domande più comuni che gli utenti hanno quando ci lavorano!
Esegui e modifica il codice da questo tutorial online
Esegui codiceOvviamente, creare i tuoi DataFrame è il primo passo in quasi tutto ciò che vuoi fare quando si tratta di data munging in Python. A volte vorrai partire da zero, ma puoi anche convertire altre strutture dati, come liste o array NumPy, in DataFrame di Pandas. In questa sezione coprirai solo il secondo caso. Tuttavia, se vuoi leggere di più sulla creazione di DataFrame vuoti da riempire in seguito, vai alla sezione 7.
Tra le molte cose che possono fungere da input per creare un “DataFrame”, c’è un ndarray di NumPy. Per creare un data frame da un array NumPy, puoi semplicemente passarlo alla funzione DataFrame() nell’argomento data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Fai attenzione a come i blocchi di codice sopra selezionano elementi dall’array NumPy per costruire il DataFrame: prima selezioni i valori contenuti nelle liste che iniziano con Row1 e Row2, poi selezioni l’indice o i numeri di riga Row1 e Row2 e infine i nomi delle colonne Col1 e Col2.
Inoltre, nell’esempio sopra, stampiamo una piccola selezione dei dati. Questo funziona allo stesso modo del sottoinsieme di array NumPy 2D: prima indichi la riga in cui cercare i dati, poi la colonna. Non dimenticare che gli indici partono da 0! Per data nell’esempio sopra, vai a cercare nelle righe all’indice 1 fino alla fine, e selezioni tutti gli elementi che vengono dopo l’indice 1. Di conseguenza, finisci per selezionare 1, 2, 3 e 4.
Questo approccio alla creazione dei DataFrame sarà lo stesso per tutte le strutture che DataFrame() può accettare come input.
Vedi l’esempio qui sotto:
Ricorda che la libreria Pandas è già stata importata come pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Nota che l’indice della tua Series (e del DataFrame) contiene le chiavi del dizionario originale, ma sono ordinate: Belgium sarà l’indice a 0, mentre United States sarà l’indice a 3.
Dopo aver creato il tuo DataFrame, potresti voler sapere qualcosa in più su di esso. Puoi usare la proprietà shape o la funzione len() in combinazione con la proprietà .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Queste due opzioni ti danno informazioni leggermente diverse sul tuo DataFrame: la proprietà shape ti fornirà le dimensioni del DataFrame. Significa che conoscerai la larghezza e l’altezza del DataFrame. D’altro canto, la funzione len(), in combinazione con la proprietà index, ti darà informazioni solo sull’altezza del DataFrame.
Nulla di straordinario, comunque, dato che imposti esplicitamente la proprietà index.
Potresti anche usare df[0].count() per ottenere informazioni sull’altezza del DataFrame, ma questo escluderà i valori NaN (se presenti). Ecco perché chiamare .count() sul DataFrame non è sempre l’opzione migliore.
Se vuoi più informazioni sulle colonne del DataFrame, puoi sempre eseguire list(my_dataframe.columns.values).
Ora che hai messo i tuoi dati in una struttura Pandas DataFrame più comoda, è il momento di passare al lavoro vero!
Questa prima sezione ti guiderà attraverso i primi passi per lavorare con i DataFrame in Python. Coprirà le operazioni di base che puoi fare sul tuo DataFrame appena creato: aggiungere, selezionare, eliminare, rinominare e altro.
Prima di iniziare ad aggiungere, eliminare e rinominare i componenti del tuo DataFrame, devi prima sapere come selezionare questi elementi. Quindi, come si fa?
Anche se potresti ricordare come farlo dalla sezione precedente: selezionare un indice, una colonna o un valore dal DataFrame non è difficile, anzi. È simile a quanto vedi in altri linguaggi (o pacchetti!) utilizzati per l’analisi dei dati. Se non sei convinto, considera quanto segue:
In R, usi la notazione [,] per accedere ai valori del data frame.
Ora, supponiamo di avere un DataFrame come questo:
A B C
0 1 2 3
1 4 5 6
2 7 8 9E vuoi accedere al valore che è all’indice 0, nella colonna “A”.
Esistono varie opzioni per ottenere di nuovo il tuo valore 1:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Quelle da ricordare sono senza dubbio .loc[] e .iloc[]. Le sottili differenze tra queste due verranno discusse nelle prossime sezioni.
Basta parlare di selezione di valori dal DataFrame. Che ne dici di selezionare righe e colonne? In tal caso, useresti:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Per ora, basta sapere che puoi accedere ai valori chiamandoli con la loro etichetta oppure con la loro posizione nell’indice o nella colonna. Se non ti è chiaro, guarda di nuovo le leggere differenze nei comandi: una volta vedi [0][0], l’altra vedi [0,'A'] per recuperare il valore 1.
Ora che hai imparato come selezionare un valore da un DataFrame, è il momento di passare al lavoro vero e aggiungere un indice, una riga o una colonna!
Quando crei un DataFrame, hai la possibilità di passare un input all’argomento “index” per assicurarti di avere l’indice che desideri. Se non lo specifichi, il tuo DataFrame avrà, per impostazione predefinita, un indice numerico che parte da 0 e continua fino all’ultima riga del DataFrame.
Tuttavia, anche quando l’indice viene specificato automaticamente, hai comunque la possibilità di riutilizzare una delle colonne e renderla il tuo indice. Puoi farlo facilmente chiamando set_index() sul DataFrame. Provalo qui sotto!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9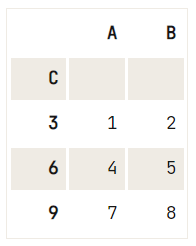
Prima di arrivare alla soluzione, è bene capire il concetto di loc e come differisce da altri attributi di indicizzazione come .iloc[] e .ix[]:
Tutto ciò può sembrare complicato. Illustriamo con un piccolo esempio:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Nota che in questo caso abbiamo usato un esempio di DataFrame non esclusivamente basato su interi per rendere più facile capire le differenze. Vedi chiaramente che passare 2 a .loc[] o a .iloc[]/.ix[] non restituisce lo stesso risultato!
48 1
49 2
50 3.iloc[] guarderà le posizioni nell’indice. Quando passi 2, otterrai:48 7
49 8
50 9.ix[] avrà lo stesso comportamento di iloc e guarderà le posizioni nell’indice. Otterrai lo stesso risultato di .iloc[].Ora che la differenza tra .iloc[], .loc[] e .ix[] è chiara, sei pronto per provare ad aggiungere righe al tuo DataFrame!
Consiglio: come conseguenza di quanto appena letto, capisci anche che la raccomandazione generale è usare .loc per inserire righe nel DataFrame. Questo perché se usassi df.ix[], potresti provare a fare riferimento a un indice numerico con il valore dell’indice e sovrascrivere accidentalmente una riga esistente del DataFrame. Evitalo!
Guarda di nuovo la differenza nel DataFrame qui sotto:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Vedi perché tutto questo può essere confuso, giusto?
In alcuni casi, vuoi rendere l’indice parte del tuo DataFrame. Puoi farlo facilmente prendendo una colonna del DataFrame o facendo riferimento a una colonna che non hai ancora creato e assegnandola alla proprietà .index, proprio così:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2In altre parole, dici al DataFrame che dovrebbe prendere la colonna A come indice.
Tuttavia, se vuoi aggiungere colonne al tuo DataFrame, puoi anche seguire lo stesso approccio usato per aggiungere un indice: usa .loc[] o .iloc[]. In questo caso, aggiungi una Series a un DataFrame esistente con l’aiuto di .loc[]:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Ricorda: un oggetto Series è molto simile a una colonna di un DataFrame. Questo spiega perché puoi aggiungere facilmente una Series a un DataFrame esistente. Nota anche che l’osservazione fatta prima su .loc[] resta valida anche quando aggiungi colonne al DataFrame!
Quando il tuo indice non è proprio come lo vuoi, puoi scegliere di reimpostarlo. Puoi farlo facilmente con .reset_index(). Tuttavia, fai attenzione, perché puoi passare diversi argomenti che possono determinare il successo del reset:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Puoi provare a sostituire l’argomento drop con inplace nell’esempio sopra e vedere cosa succede!
Nota come usi l’argomento drop per indicare che vuoi eliminare l’indice precedente. Se avessi usato inplace, l’indice originale con float verrebbe aggiunto come colonna extra al DataFrame.
Ora che hai visto come selezionare e aggiungere indici, righe e colonne al tuo DataFrame, è il momento di considerare un altro caso d’uso: rimuovere questi tre elementi dalla tua struttura dati.
Se vuoi rimuovere l’indice dal DataFrame, dovresti ripensarci perché DataFrame e Series hanno sempre un indice.
Tuttavia, quello che puoi fare è, per esempio:
del df.index.name,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')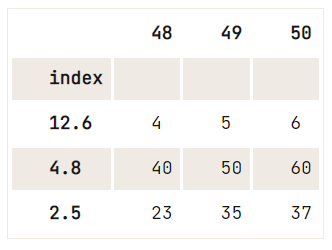
Ora che sai come rimuovere un indice dal DataFrame, puoi passare a rimuovere colonne e righe!
Per eliminare (una selezione di) colonne dal DataFrame, puoi usare il metodo drop():
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9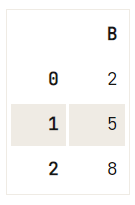
Potresti pensare: beh, non è così lineare; Ci sono alcuni argomenti extra passati al metodo drop()!
axis è 0 quando indica le righe e 1 quando viene usato per eliminare colonne.inplace su True per eliminare la colonna senza dover riassegnare il DataFrame.Puoi rimuovere righe duplicate dal DataFrame eseguendo df.drop_duplicates(). Puoi anche rimuovere righe dal DataFrame tenendo conto solo dei valori duplicati presenti in una colonna.
Guarda questo esempio:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37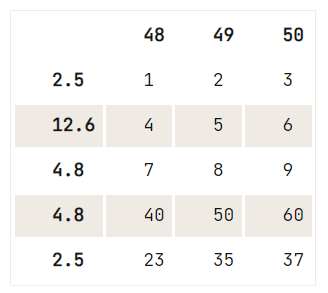
Se non c’è un criterio di unicità per l’eliminazione che vuoi eseguire, puoi usare il metodo drop(), in cui usi la proprietà index per specificare l’indice delle righe che vuoi rimuovere dal DataFrame:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37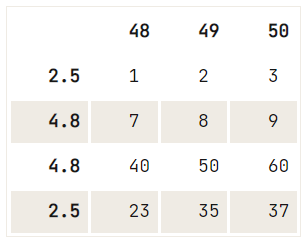
Dopo questo comando, potresti voler reimpostare di nuovo l’indice.
Suggerimento: prova tu stesso a reimpostare l’indice del DataFrame risultante! Non dimenticare di usare l’argomento drop se lo ritieni necessario.
Per dare alle colonne o ai valori dell’indice del tuo dataframe un valore diverso, è meglio usare il metodo .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9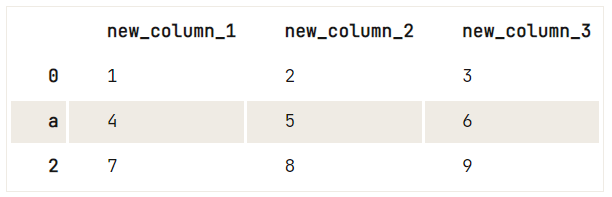
Consiglio: prova a cambiare l’argomento inplace nel primo task (rinominare le colonne) in False e guarda cosa produce ora lo script. Vedi che il DataFrame non è stato riassegnato durante la rinomina delle colonne. Di conseguenza, il secondo task prende come input il DataFrame originale e non quello appena ottenuto dalla prima operazione di rename().
Ora che hai superato un primo set di domande sui DataFrame di Pandas, è il momento di andare oltre le basi e sporcarsi davvero le mani, perché c’è molto di più nei DataFrame di quanto visto nella prima sezione.
La maggior parte delle volte vorrai anche eseguire alcune operazioni sui valori effettivi contenuti nel DataFrame. Nelle sezioni seguenti, vedrai vari modi per formattare i valori del tuo DataFrame di pandas
Per sostituire determinate stringhe nel DataFrame, puoi usare facilmente replace(): passa i valori che vuoi cambiare, seguiti dai valori con cui vuoi sostituirli.
Proprio così:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor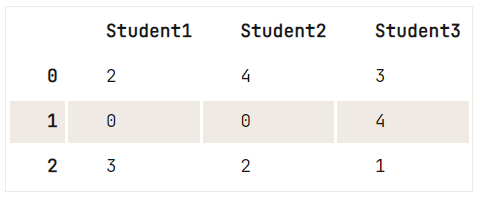
Nota che esiste anche un argomento regex che può aiutarti moltissimo quando ti trovi di fronte a strane combinazioni di stringhe:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9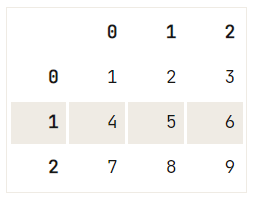
In breve, replace() è per lo più ciò di cui hai bisogno quando vuoi sostituire valori o stringhe nel DataFrame con altri!
Rimuovere parti indesiderate di stringhe è un lavoro noioso. Per fortuna, c’è una soluzione semplice!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Usi map() sulla colonna result per applicare la funzione lambda a ciascun elemento (element-wise) della colonna. La funzione prende il valore stringa e rimuove il + o il - a sinistra e rimuove anche qualsiasi dei sei caratteri aAbBcC a destra.
Questo è un compito di formattazione un po’ più difficile. Tuttavia, il prossimo blocco di codice ti guiderà attraverso i passaggi:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12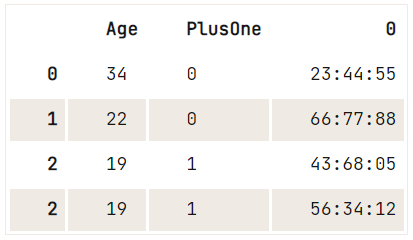
In breve, quello che fai è:
Ticket dal DataFrame df e dividi le stringhe su uno spazio. Questo farà sì che i due biglietti finiscano in due righe separate alla fine. Poi prendi questi quattro valori (i quattro numeri di biglietto) e li metti in un oggetto Series: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN! Devi impilare (stack) la Series per assicurarti di non avere NaN nella Series risultante.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket originale.Potresti voler modificare i dati nel DataFrame applicando loro una funzione. Iniziamo rispondendo a questa domanda creando una funzione lambda:
doubler = lambda x: x*2Consiglio: se vuoi saperne di più sulle funzioni in Python, considera questo tutorial sulle funzioni in Python.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Nota che puoi anche selezionare una riga del DataFrame e applicare ad essa la funzione lambda doubler. Ricorda che puoi selezionare facilmente una riga del DataFrame usando .loc[] o .iloc[].
Quindi, eseguiresti qualcosa del genere, a seconda che tu voglia selezionare l’indice in base alla sua posizione o alla sua etichetta:
df.loc[0].apply(doubler)Nota che la funzione apply() applica la funzione doubler solo lungo l’asse del DataFrame. Significa che prendi di mira o l’indice o le colonne. Ovvero, una riga o una colonna.
Tuttavia, se vuoi applicarla a ciascun elemento (element-wise), puoi usare la funzione map(). Puoi semplicemente sostituire la funzione apply() nel blocco di codice sopra con map(). Non dimenticare di passare comunque la funzione doubler per raddoppiare i valori.
Supponiamo che tu voglia applicare questa funzione di raddoppio non solo alla colonna A del DataFrame ma a tutto quanto. In questo caso, puoi usare applymap() per applicare la funzione doubler a ogni singolo elemento dell’intero DataFrame:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Nota che in questi casi abbiamo lavorato con funzioni lambda o funzioni anonime create a runtime. Tuttavia, puoi anche scrivere una tua funzione. Per esempio:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Se vuoi maggiori informazioni sul flusso di controllo in Python, puoi sempre consultare le nostre altre risorse.
La funzione che userai è la funzione Dataframe() di Pandas: richiede che tu passi i dati che vuoi inserire, gli indici e le colonne.
Ricorda che i dati contenuti nel data frame non devono essere omogenei. Possono essere di tipi diversi!
Ci sono diversi modi in cui puoi usare questa funzione per creare un DataFrame vuoto. Innanzitutto, puoi usare numpy.nan per inizializzare il tuo data frame con NaN. Nota che numpy.nan ha tipo float.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNAl momento, il tipo di dati del data frame è dedotto per impostazione predefinita: poiché numpy.nan è di tipo float, il data frame conterrà anche valori di tipo float. Puoi, tuttavia, forzare il DataFrame a essere di un tipo particolare aggiungendo l’attributo dtype e inserendo il tipo desiderato. Proprio come in questo esempio:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNNota che se non specifichi le etichette degli assi o l’indice, verranno costruiti dai dati di input in base a regole di buon senso.
Pandas può riconoscerle, ma devi aiutarlo un po’: aggiungi l’argomento parse_dates quando leggi i dati, ad esempio, da un file CSV:
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Ci sono, tuttavia, sempre formati data-ora strani.
Nessun problema! In questi casi, puoi costruire un tuo parser per gestirli. Potresti, ad esempio, creare una funzione lambda che prenda la tua DateTime e la controlli con una stringa di formato.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Rimodellare il DataFrame significa trasformarlo in modo che la struttura risultante lo renda più adatto alla tua analisi dei dati. In altre parole, il reshaping non riguarda tanto la formattazione dei valori contenuti nel DataFrame, quanto la trasformazione della sua forma.
Questo risponde al quando e al perché. Ma come rimodelleresti il tuo DataFrame?
Ci sono tre modi di rimodellare che spesso suscitano domande negli utenti: pivot, stacking e unstacking e melting.
Puoi usare la funzione pivot() per creare una nuova tabella derivata a partire da quella originale. Quando usi la funzione, puoi passare tre argomenti:
values: questo argomento ti consente di specificare quali valori del DataFrame originale vuoi vedere nella pivot table.columns: qualunque cosa passi a questo argomento diventerà una colonna nella tabella risultante.index: qualunque cosa passi a questo argomento diventerà un indice nella tabella risultante.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Quando non compili specificamente quali valori ti aspetti siano presenti nella tabella risultante, farai il pivot su più colonne:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Nota che i tuoi dati non possono avere righe con valori duplicati per le colonne che specifichi. Se non è così, riceverai un messaggio di errore. Se non puoi garantire l’unicità dei dati, vorrai invece usare il metodo pivot_table:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Nota l’argomento aggiuntivo aggfunc passato al metodo pivot_table. Questo argomento indica che usi una funzione di aggregazione per combinare valori multipli. In questo esempio, vedi chiaramente che viene usata la funzione mean.
stack() e unstack() per rimodellare il tuo DataFrame di PandasHai già visto un esempio di stacking nella sezione 5. In sostanza, potresti ricordare che quando fai lo stack di un DataFrame, lo rendi più alto. Sposti l’indice di colonna più interno per farlo diventare l’indice di riga più interno. Ottieni un DataFrame con un indice che ha un nuovo livello interno di etichette di riga.
Go back to the full walk-through in section 5 if you’re unsure of the workings ofstack().
L’inverso dello stacking si chiama unstacking. Proprio come stack(), usi unstack() per spostare l’indice di riga più interno e farlo diventare l’indice di colonna più interno.
Per una spiegazione su pivot, stacking e unstacking in pandas, dai un’occhiata al nostro corso Reshaping Data with pandas.
melt()Il melting è utile nei casi in cui hai dati con una o più colonne che sono variabili identificative, mentre tutte le altre colonne sono considerate variabili misurate.
Queste variabili misurate vengono tutte “sbilanciate” sull’asse delle righe. Cioè, mentre le variabili misurate erano distribuite sulla larghezza del DataFrame, il melt farà in modo che vengano posizionate in altezza. In altre parole, il tuo DataFrame diventerà più lungo invece che più largo.
Di conseguenza, avrai due colonne non identificative, ovvero “variable” e “value”.
Illustriamo con un esempio:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Se cerchi altri modi per rimodellare i tuoi dati, consulta la documentazione.
Puoi iterare sulle righe del DataFrame con l’aiuto di un ciclo for in combinazione con una chiamata a iterrows() sul DataFrame:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() ti permette di ciclare in modo efficiente sulle righe del DataFrame come coppie (indice, Series). In altre parole, restituisce tuple (indice, riga).
Quando hai fatto il tuo data munging e le manipolazioni con Pandas, potresti voler esportare il DataFrame in un altro formato. Questa sezione coprirà due modi per esportare il tuo DataFrame pandas in un file CSV o Excel.
Per scrivere un DataFrame come file CSV, puoi usare to_csv():
import pandas as pd
df.to_csv('myDataFrame.csv')Quel pezzetto di codice sembra piuttosto semplice, ma è proprio qui che iniziano le difficoltà per molti, perché potresti avere requisiti specifici per l’output dei dati. Forse non vuoi una virgola come delimitatore, o vuoi specificare una codifica particolare.
Niente paura! Puoi passare alcuni argomenti aggiuntivi a to_csv() per assicurarti che i tuoi dati vengano esportati come desideri!
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN o mancanti, se vuoi o meno esportare l’header, se vuoi o meno scrivere i nomi di riga, se vuoi la compressione: puoi leggere le opzioni.In modo simile a quanto fatto per esportare il DataFrame in CSV, puoi usare to_excel() per scrivere la tua tabella in Excel. Tuttavia, è un po’ più complicato:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Nota, tuttavia, che, proprio come con to_csv(), hai molte opzioni extra come startcol, startrow e così via, per assicurarti di esportare i dati correttamente. Puoi imparare di più su come importare dati da e esportare dati in file CSV usando pandas nel nostro tutorial.
Se, però, vuoi maggiori informazioni sugli strumenti di IO in Pandas, consulta la documentazione dei DataFrame verso Excel di pandas.
È tutto! Hai completato con successo il tutorial sui DataFrame di Pandas!
Le risposte alle 11 domande frequenti su Pandas rappresentano funzioni essenziali di cui avrai bisogno per importare, pulire e manipolare i dati per il tuo lavoro di data science. Non sei sicuro di essere andato abbastanza a fondo? Il nostro corso Importing Data In Python ti aiuterà! Se hai preso la mano, potresti voler vedere Pandas all’opera in un progetto reale. La serie di tutorial L’importanza del preprocessing nella data science e nella pipeline di machine learning è da leggere, e il corso aperto Introduction to Python & Machine Learning è da completare.
Approfondisci Python e pandas
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

