
Lernpfad
Python-Entwickler
28 Std.
Wenn Leute, die mit Daten arbeiten, heute über Datenspeicherung reden, meinen sie meistens, wo die Daten gespeichert sind, egal ob in lokalen Dateien, SQL- oder nosql-Datenbanken oder in der Cloud. Ein weiterer wichtiger Punkt bei der Datenspeicherung ist aber auch, wie die Daten gespeichert werden.
Wie Daten gespeichert werden, passiert oft auf einer niedrigeren Ebene, also im Kern der Programmiersprachen. Es geht eher darum, wie die Tools, die wir benutzen, gestaltet sind, als darum, wie man sie benutzt. Aber zu wissen, wie Daten gespeichert werden, ist echt wichtig, um die Mechanismen zu verstehen, die die Arbeit möglich machen. Außerdem kann dieses Wissen uns dabei helfen, bessere Entscheidungen zu treffen, um die Rechenleistung zu verbessern.
Wenn du dich wirklich für Hashmaps sowie für verknüpfte Listen, Stapel, Warteschlangen und Graphen interessierst, melde dich bei DataCamp an, damit du unseren Kurs Datenstrukturen und Algorithmen in Python belegen kannst.
Um eine Hashmap zu definieren, müssen wir erst mal wissen, was Hashing ist. Hashing ist der Vorgang, bei dem ein bestimmter Schlüssel oder eine Zeichenfolge in einen anderen Wert umgewandelt wird. Das Ergebnis ist normalerweise ein kürzerer Wert mit fester Länge, der rechnerisch einfacher zu verarbeiten ist als der ursprüngliche Schlüssel.
Hashmaps, auch als Hash-Tabellen bekannt, sind eine der häufigsten Arten, Hashing zu machen. Hashmaps speichern Schlüssel-Wert-Paare (z. B. Mitarbeiter-ID und Name) in einer Liste, auf die man über ihren Index zugreifen kann. Man könnte sagen, dass eine Hashmap in „ “ eine Datenstruktur ist, die Hash-Techniken nutzt, um Daten auf assoziative Weise zu speichern. Das sind optimierte Datenstrukturen, die schnellere Datenoperationen wie Einfügen, Löschen und Suchen ermöglichen.
Die Idee hinter Hashmaps ist, die Einträge (Schlüssel/Wert-Paare) auf eine Reihe von Buckets zu verteilen. Mit einem Schlüssel berechnet eine Hash-Funktion einen eindeutigen Index, der angibt, wo der Eintrag zu finden ist. Durch die Verwendung eines Index anstelle des ursprünglichen Schlüssels eignen sich Hashmaps besonders gut für verschiedene Datenoperationen, wie zum Beispiel das Einfügen, Entfernen und Suchen von Daten.
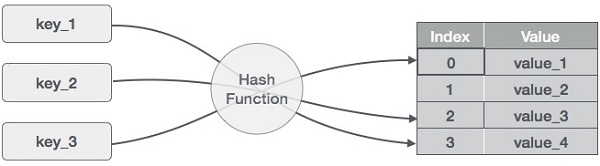
Wie ein Hashmap funktioniert. Bild vom Autor
Um den Hashwert oder einfach Hash zu berechnen, generiert eine Hashfunktion neue Werte nach einem mathematischen Hash-Algorithmus. Da Schlüssel-Wert-Paare theoretisch unbegrenzt sind, ordnet die Hash-Funktion die Schlüssel anhand einer bestimmten Tabelle zu.
Es gibt mehrere Hash-Funktionen, jede mit ihren Vor- und Nachteilen. Das Hauptziel einer Hash-Funktion ist, für dieselbe Eingabe immer denselben Wert zurückzugeben.
Die häufigsten sind die folgenden:
Python macht Hashmaps über den eingebauten Datentyp „Dictionary“. {key:value} Genau wie Hashmaps speichern Wörterbücher Daten in Schlüssel-Wert-Paaren. Sobald du das Wörterbuch erstellt hast (siehe nächster Abschnitt), nutzt Python eine praktische Hash-Funktion, um den Hashwert jedes Schlüssels zu berechnen.
Python-Wörterbücher haben die folgenden Funktionen:
Also, wenn du dich schon mal gefragt hast, was der Unterschied zwischen Hashmaps und Wörterbüchern ist, ist die Antwort ganz einfach. Ein Wörterbuch ist einfach die native Implementierung von Hashmaps in Python. Während eine Hashmap eine Datenstruktur ist, die mit verschiedenen Hash-Techniken erstellt werden kann, ist ein Wörterbuch eine spezielle, Python-basierte Hashmap, deren Design und Verhalten in der Python-Klasse „dict“ festgelegt sind.
Viele moderne Programmiersprachen wie Python, Java und C++ können mit Hashmaps umgehen. In Python werden Hashmaps über Wörterbücher gemacht, eine weit verbreitete Datenstruktur, die du wahrscheinlich kennst. In den nächsten Abschnitten schauen wir uns die Grundlagen von Wörterbüchern an, wie sie funktionieren und wie man sie mit verschiedenen Python-Paketen umsetzt.
Schauen wir uns mal ein paar der häufigsten Wörterbuchoperationen an. Wenn du mehr über die Verwendung von Wörterbüchern erfahren möchtest, schau dir unser Python-Wörterbuch-Tutorial an.
Das Erstellen von Wörterbüchern in Python ist ziemlich einfach. Du musst einfach nur geschweifte Klammern nehmen und die Schlüssel-Wert-Paare durch Kommas getrennt einfügen. Du kannst auch die eingebaute Funktion dict() benutzen. Lass uns ein Wörterbuch erstellen, das Hauptstädte den Ländern zuordnet:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Man muss bedenken, dass ein Schlüssel in einem Wörterbuch einzigartig sein muss; Duplikate sind nicht erlaubt. Bei doppelten Schlüsseln gibt Python aber keinen Fehler aus, sondern nimmt einfach das letzte Schlüsselpaar als gültig und ignoriert das erste Schlüssel-Wert-Paar. Schau es dir selbst an:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Um Infos in unserem Wörterbuch zu suchen, müssen wir den Schlüssel in Klammern angeben, und Python gibt dann den dazugehörigen Wert zurück, wie folgt:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainWenn du versuchst, auf einen Schlüssel zuzugreifen, der nicht im Wörterbuch steht, gibt Python eine Fehlermeldung aus. Um das zu vermeiden, kannst du stattdessen mit der Methode .get() auf die Schlüssel zugreifen. Wenn der Schlüssel nicht da ist, wird einfach ein None-Wert zurückgegeben:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneLass uns ein neues Paar aus Hauptstadt und Land hinzufügen:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}Die gleiche Syntax kann verwendet werden, um den mit einem Schlüssel verbundenen Wert zu aktualisieren. Lass uns den Wert für Berlin festlegen:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Jetzt löschen wir eins der Paare in unserem Wörterbuch.
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Oder wenn du alle Schlüssel-Wert-Paare im Wörterbuch löschen willst, kannst du die Methode .clear() verwenden:
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Wenn du alle Schlüssel-Wert-Paare abrufen willst, nimm die Methode .items(), und Python gibt dir eine durchlaufbare Liste von Tupeln zurück:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinWenn du eine iterierbare Liste mit den Schlüsseln und Werten abrufen willst, kannst du die Methoden .keys() und .values() verwenden:
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYHashmaps sind echt mächtige Datenstrukturen, die man fast überall in der digitalen Welt findet. Hier findest du eine Liste mit echten Anwendungen von Hashmaps:
Hashmaps sind echt vielseitige und effiziente Datenstrukturen. Allerdings bringen sie auch Probleme und Einschränkungen mit sich. Um die üblichen Probleme mit Hashmaps zu lösen, solltest du ein paar Dinge beachten und bewährte Vorgehensweisen anwenden.
Das macht Sinn: Wenn sich der Inhalt des Schlüssels ändert, gibt die Hash-Funktion einen anderen Hash zurück, sodass Python den mit dem Schlüssel verbundenen Wert nicht finden kann.
Hashing klappt nur, wenn jedes Element einem eindeutigen Speicherplatz in der Hash-Tabelle zugeordnet ist. Aber manchmal können Hash-Funktionen für unterschiedliche Eingaben dieselbe Ausgabe liefern. Wenn du zum Beispiel eine Divisions-Hash-Funktion benutzt, können verschiedene ganze Zahlen dieselbe Hash-Funktion haben (sie können bei der Modulo-Division denselben Rest ergeben), was zu einem Problem namens Kollision führt. Kollisionen müssen gelöst werden, und dafür gibt's verschiedene Techniken. Zum Glück kümmert sich Python bei Wörterbüchern im Hintergrund um mögliche Kollisionen.
Der Auslastungsfaktor ist das Verhältnis zwischen der Anzahl der Elemente in den Tabellen und der Gesamtzahl der Buckets. Das ist eine Methode, um zu sehen, wie gleichmäßig die Daten verteilt sind. Als Faustregel gilt: Je gleichmäßiger die Daten verteilt sind, desto geringer ist die Wahrscheinlichkeit von Kollisionen. Auch bei Dictionaries passt Python die Größe der Tabelle automatisch an, wenn neue Schlüssel-Wert-Paare eingefügt oder gelöscht werden.
Eine gute Hash-Funktion sollte die Anzahl der Kollisionen minimieren, einfach zu berechnen sein und die Elemente in der Hash-Tabelle gleichmäßig verteilen. Das könnte man machen, indem man die Größe der Tabelle oder die Komplexität der Hash-Funktion erhöht. Das ist zwar praktisch, wenn es nur wenige Elemente gibt, aber nicht machbar, wenn es viele Elemente gibt, weil das zu speicherintensiven, weniger effizienten Hash-Maps führen würde.
Wörterbücher sind super, aber andere Datenstrukturen könnten für deine speziellen Daten und Bedürfnisse besser passen. Letztendlich unterstützen Wörterbücher keine gängigen Funktionen wie Indizierung, Slicing und Verkettung, was sie weniger flexibel macht und die Arbeit mit ihnen in bestimmten Situationen erschwert.
Wie schon gesagt, Python macht Hashmaps mit eingebauten Wörterbüchern. Man sollte aber wissen, dass es noch andere native Python-Tools und Bibliotheken von Drittanbietern gibt, mit denen man die Vorteile von Hashmaps nutzen kann.
Schauen wir uns ein paar der bekanntesten Beispiele an.
Jedes Mal, wenn du versuchst, auf einen Schlüssel zuzugreifen, der nicht in deinem Wörterbuch steht, gibt Python einen KeyError zurück. Eine Möglichkeit, das zu verhindern, ist, mit der Methode .get() nach Infos zu suchen. Eine super Methode dafür ist die Verwendung von Defaultdict, das im Modul collections zu finden ist. Defaultdict und Wörterbücher sind fast gleich. Der einzige Unterschied ist, dass Defaultdict nie einen Fehler auslöst, weil es einen Standardwert für nicht vorhandene Schlüssel bereitstellt.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter ist eine Unterklasse eines Python-Wörterbuchs, das speziell fürs Zählen von hashbaren Objekten entwickelt wurde. Es ist ein Wörterbuch, in dem Elemente als Schlüssel und ihre Anzahl als Werte gespeichert werden.
Es gibt mehrere Möglichkeiten, Counter zu starten:
Durch eine Reihe von Elementen.
Nach Schlüsseln und Zählungen in einem Wörterbuch.
name:value -Mapping verwenden.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})Die Counter-Klasse hat ein paar praktische Methoden für gängige Berechnungen.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, auch bekannt als sklearn, ist eine robuste Open-Source-Bibliothek für maschinelles Lernen in Python. Es wurde entwickelt, um die Implementierung von maschinellem Lernen und statistischen Modellen in Python einfacher zu machen.
Sklearn hat verschiedene Hash-Methoden, die bei der Feature-Engineering-Arbeit echt nützlich sein können.
Eine der häufigsten Methoden ist die CountVectorizer-Methode. Es wird benutzt, um einen Text in einen Vektor umzuwandeln, basierend auf der Häufigkeit, mit der jedes Wort im ganzen Text vorkommt. Die Häufigkeit der Wörter ( CountVectorizer ) ist besonders nützlich bei der Textanalyse.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Es gibt noch andere Hash-Methoden in sklearn, wie zum Beispiel FeatureHasher und DictVectorizer. Unsere Fallstudien Schulbudgetierung mit maschinellem Lernen in Python sind super Beispiele, um zu sehen, wie das in der Praxis funktioniert.
Herzlichen Glückwunsch, dass du dieses Tutorial über Hashmaps durchgemacht hast. Wir hoffen, dass du jetzt Hashmaps und Python-Dictionaries besser verstehst. Wenn du mehr über Wörterbücher und ihre Verwendung in realen Szenarien erfahren möchtest, empfehlen wir dir, unser spezielles Python-Wörterbuch-Tutorial sowie unser Python-Wörterbuch-Verständnis-Tutorial zu lesen.
Wenn du gerade erst mit Python anfängst und mehr darüber lernen möchtest, schau dir den Kurs Einführung in die Datenwissenschaft mit Python von DataCamp an und check unser Python-Tutorial für Anfänger aus.
Starte noch heute deine Python-Reise!
Lernpfad
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Samuel Shaibu
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
Tutorial
DataCamp Team

