
programa
Fundamentos de la IA
10 h
Hay múltiples ventajas a corto y largo plazo por elegir LLM de código abierto en lugar de LLM propietarios. A continuación, encontrarás una lista con las razones más convincentes:
Una de las mayores preocupaciones del uso de LLM propietarios es el riesgo de fugas de datos o de acceso no autorizado a datos confidenciales por parte del proveedor de LLM. De hecho, ya se han producido varias controversias en relación con el supuesto uso de datos personales y confidenciales con fines formativos.
Al utilizar LLM de código abierto, las empresas serán las únicas responsables de la protección de los datos personales, ya que mantendrán el control total sobre ellos.
La mayoría de los LLM propietarios requieren una licencia para poder utilizarlos. A largo plazo, esto puede suponer un gasto importante que algunas empresas, especialmente las pymes, podrían no poder permitirse. Este no es el caso de los LLM de código abierto, ya que normalmente son de uso gratuito.
Sin embargo, es importante tener en cuenta que ejecutar LLM requiere recursos considerables, incluso solo para la inferencia, lo que significa que normalmente tendrás que pagar por el uso de servicios de nube o una infraestructura potente.
Las empresas que opten por los LLM de código abierto tendrán acceso al funcionamiento de los LLM, incluyendo su código fuente, arquitectura, datos de entrenamiento y mecanismo de entrenamiento e inferencia. Esta transparencia es el primer paso para el escrutinio, pero también para la personalización.
Dado que los LLM de código abierto son accesibles para todo el mundo, incluido su código fuente, las empresas que los utilizan pueden personalizarlos para sus casos de uso particulares.
El movimiento de código abierto promete democratizar el uso y el acceso a las tecnologías LLM y de IA generativa. Permitir a los programadores inspeccionar el funcionamiento interno de los LLM es clave para el futuro desarrollo de esta tecnología. Al reducir las barreras de entrada para los programadores de todo el mundo, los LLM de código abierto pueden fomentar la innovación y mejorar los modelos al reducir los sesgos y aumentar la precisión y el rendimiento general.
Tras la popularización de los LLM, los investigadores y los organismos de control medioambiental están expresando su preocupación por la huella de carbono y el consumo de agua que requieren estas tecnologías. Los LLM propietarios rara vez publican información sobre los recursos necesarios para entrenar y operar los LLM, ni sobre la huella medioambiental asociada.
Con el LLM de código abierto, los investigadores tienen más oportunidades de conocer esta información, lo que puede abrir la puerta a nuevas mejoras diseñadas para reducir la huella medioambiental de la IA.
GLM-4.6 es un modelo de lenguaje grande de última generación que sucede a GLM-4.5. Está diseñado para mejorar los flujos de trabajo de los agentes, proporcionar una asistencia sólida en la codificación, facilitar el razonamiento avanzado y generar un lenguaje natural de alta calidad. El modelo está dirigido tanto a entornos de investigación como de producción, y se centra en la comprensión de contextos más amplios, la inferencia aumentada por herramientas y una redacción que se ajusta de forma más natural a las preferencias de los usuarios.
Fuente:zai-org/GLM-4.6
En comparación con GLM-4.5, GLM-4.6 introduce varias mejoras clave: la ventana de contexto se ha ampliado de 128 000 a 200 000 tokens, lo que permite tareas agenticas más complejas. El rendimiento de la codificación también se ha mejorado, lo que ha dado lugar a puntuaciones de referencia más altas y resultados más sólidos en aplicaciones del mundo real.
GLM-4.6 muestra claras mejoras en ocho benchmarks públicos relacionados con agentes, razonamiento y codificación, superando a GLM-4.5 y demostrando ventajas competitivas sobre modelos líderes como DeepSeek-V3.1-Terminus y Claude Sonnet 4.
gpt-oss-120b es la joya de la corona de la serie gpt-oss, los modelos de peso abierto de OpenAI diseñados para razonamiento avanzado, tareas agentivas y flujos de trabajo versátiles para programadores. Esta serie incluye dos versiones: gpt-oss-120b, destinada a casos de uso de nivel de producción y uso general que requieren un razonamiento de alto nivel y pueden funcionar con una sola GPU de 80 GB (con 117 000 millones de parámetros, de los cuales 5100 millones están activos); y gpt-oss-20b, optimizada para una menor latencia y despliegues locales o especializados (con 21 000 millones de parámetros y 3600 millones activos). Ambos modelos se entrenan utilizando el formato de respuesta de armonía y deben utilizarse con el marco de armonía para que funcionen de manera eficaz.
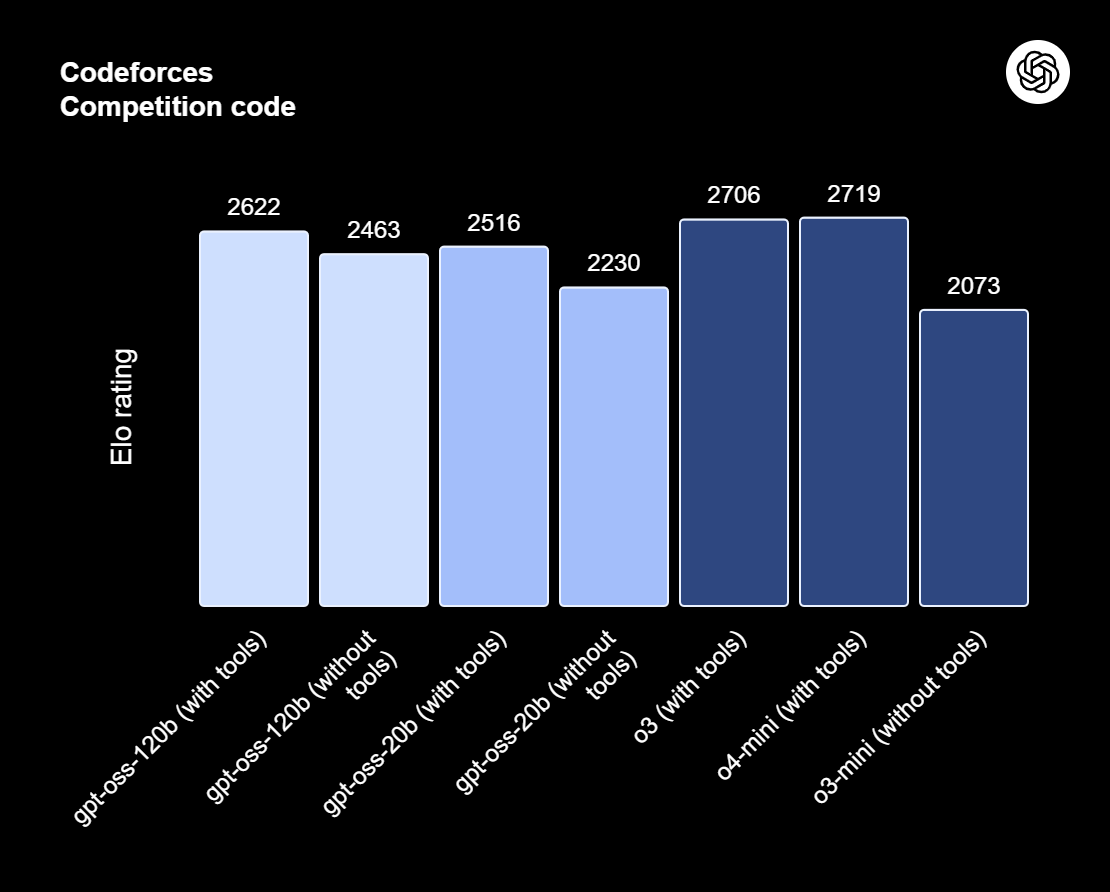
Fuente: Presentamos gpt-oss | OpenAI
El gpt-oss-120b también ofrece esfuerzos de razonamiento configurables: bajos, medios o altos, para equilibrar la profundidad y la latencia. Proporciona acceso completo a la cadena de pensamiento con fines de depuración y auditoría. Estos modelos pueden ajustarse con precisión y vienen con capacidades agenticas integradas, como llamadas a funciones, navegación web, ejecución de código Python y salidas estructuradas.
Gracias a la cuantificación MXFP4 de los pesos MoE, gpt-oss-120b puede ejecutarse en una sola GPU de 80 GB, mientras que gpt-oss-20b puede funcionar en un entorno de 16 GB. Lee nuestro artículo sobre las 10 formas de acceder a GPT-OSS 120B de forma gratuita.
Qwen3-235B-A22B-Instruct-2507 es el modelo insignia sin capacidad de pensamiento de la familia Qwen3-MoE, diseñado para seguir instrucciones de alta precisión, realizar razonamientos lógicos rigurosos, comprender textos multilingües, matemáticas, ciencias, codificación, uso de herramientas y tareas que requieren contextos muy largos. Es una mezcla de modelos lingüísticos causales expertos (MoE) con un total de 235 000 millones de parámetros, de los cuales 22 000 millones son activos (utilizando 128 expertos, con 8 activos a la vez). El modelo consta de 94 capas, incluye un mecanismo GQA con 64 cabezales de consulta y 4 cabezales de clave-valor, y tiene una ventana de contexto nativa de 262 000 tokens, que puede ampliarse hasta aproximadamente 1,01 millones de tokens.
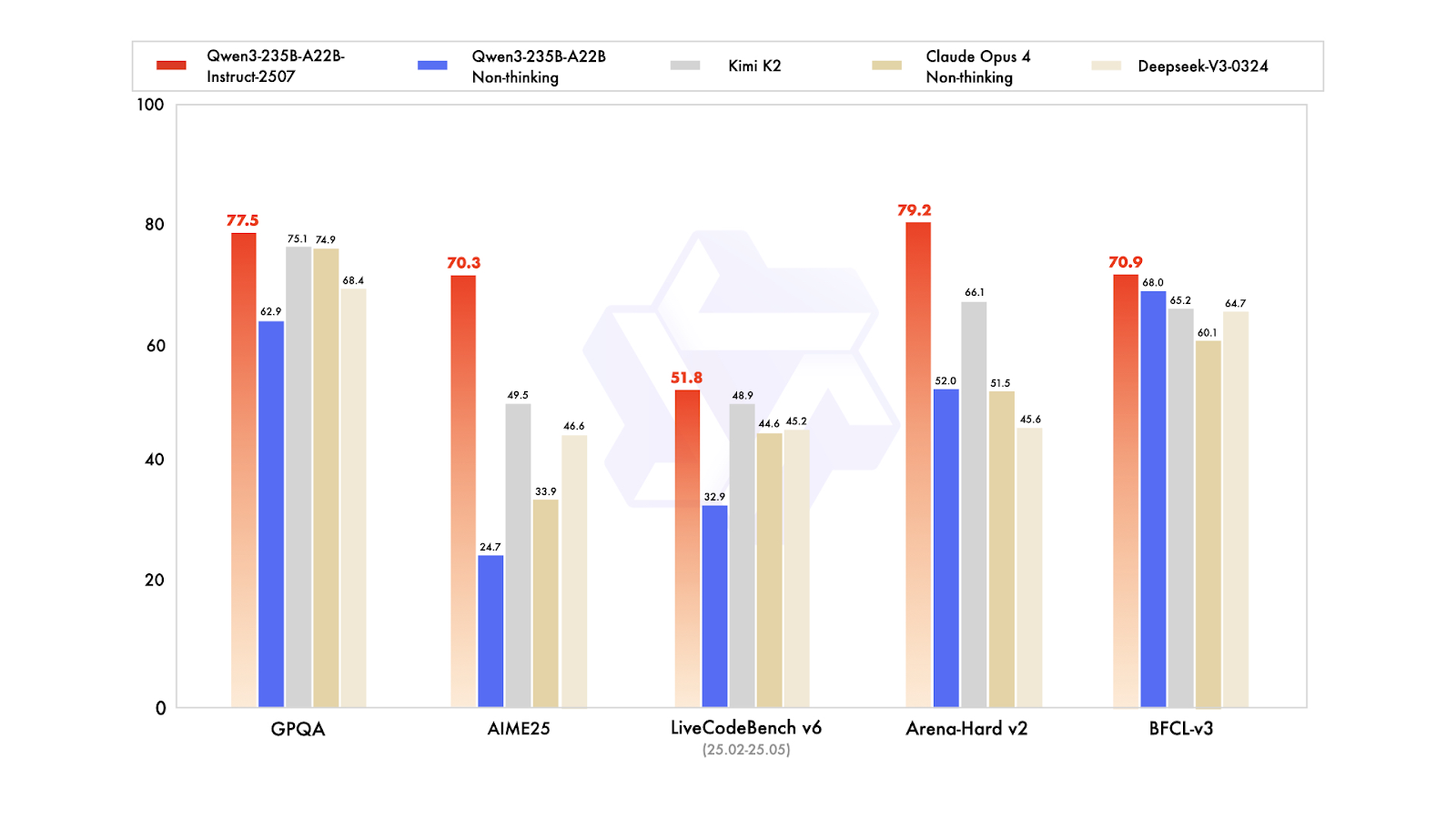
La última actualización de Instruct-2507 introduce mejoras significativas en las capacidades generales y amplía la cobertura de conocimientos especializados en varios idiomas. También ofrece una alineación de preferencias notablemente mejor para tareas abiertas y mejora la calidad de la escritura, especialmente para la comprensión de contextos largos de más de 256 000 caracteres.
En las pruebas de rendimiento públicas, muestra resultados excepcionales. En la práctica, esto posiciona a Instruct-2507 como un modelo sin pensamiento de primer nivel, superando tanto a la variante sin pensamiento anterior Qwen3-235B-A22B como a los principales competidores, como DeepSeek-V3, GPT-4o, Claude Opus 4 (sin pensamiento) y Kimi K2.
Puedes obtener más información sobre Qwen3 en nuestro artículo completo.
DeepSeek-V3.2-Exp es una versión experimental intermedia que conduce a la próxima generación de la arquitectura DeepSeek. Se basa en V3.1-Terminus e introduce DeepSeek Sparse Attention para mejorar la eficiencia del entrenamiento y la inferencia, especialmente en escenarios de contexto largo. Este modelo tiene como objetivo mejorar la eficiencia del transformador para secuencias prolongadas, al tiempo que mantiene la calidad de salida que se espera de la línea Terminus.
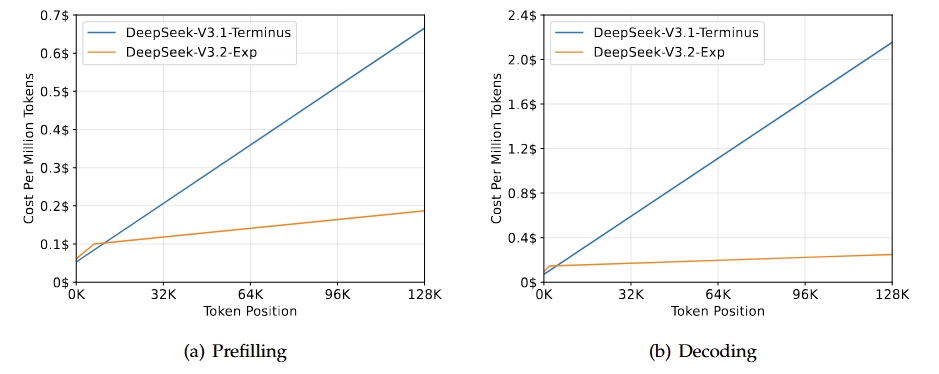
Fuente: DeepSeek-V3.2-Exp
El resultado principal de esta versión es que iguala las capacidades generales de V3.1-Terminus, al tiempo que proporciona mejoras significativas en la eficiencia para tareas de contexto largo. Las evaluaciones y los análisis de terceros muestran que su rendimiento es comparable al de Terminus, con una notable reducción de los costes computacionales. Esto confirma que una atención esporádica puede mejorar la eficiencia sin comprometer la calidad.
Lee nuestra guía completa sobre DeppSeek-V3.2-Exp para trabajar en un proyecto de demostración.
DeepSeek-R1 ha recibido una actualización menor de versión a DeepSeek-R1-0528, que mejora tus capacidades de razonamiento e inferencia gracias al aumento de la potencia computacional y a las optimizaciones algorítmicas posteriores al entrenamiento. Como resultado, se han producido mejoras significativas en diversas áreas, entre ellas las matemáticas, la programación y la lógica general. El rendimiento general ahora está más cerca del de sistemas líderes como O3 y Gemini 2.5 Pro.
Además de las capacidades básicas, esta actualización hace hincapié en la utilidad práctica con mejores flujos de trabajo de llamada de funciones y codificación, lo que refleja un enfoque en la producción de resultados más fiables y orientados a la productividad.
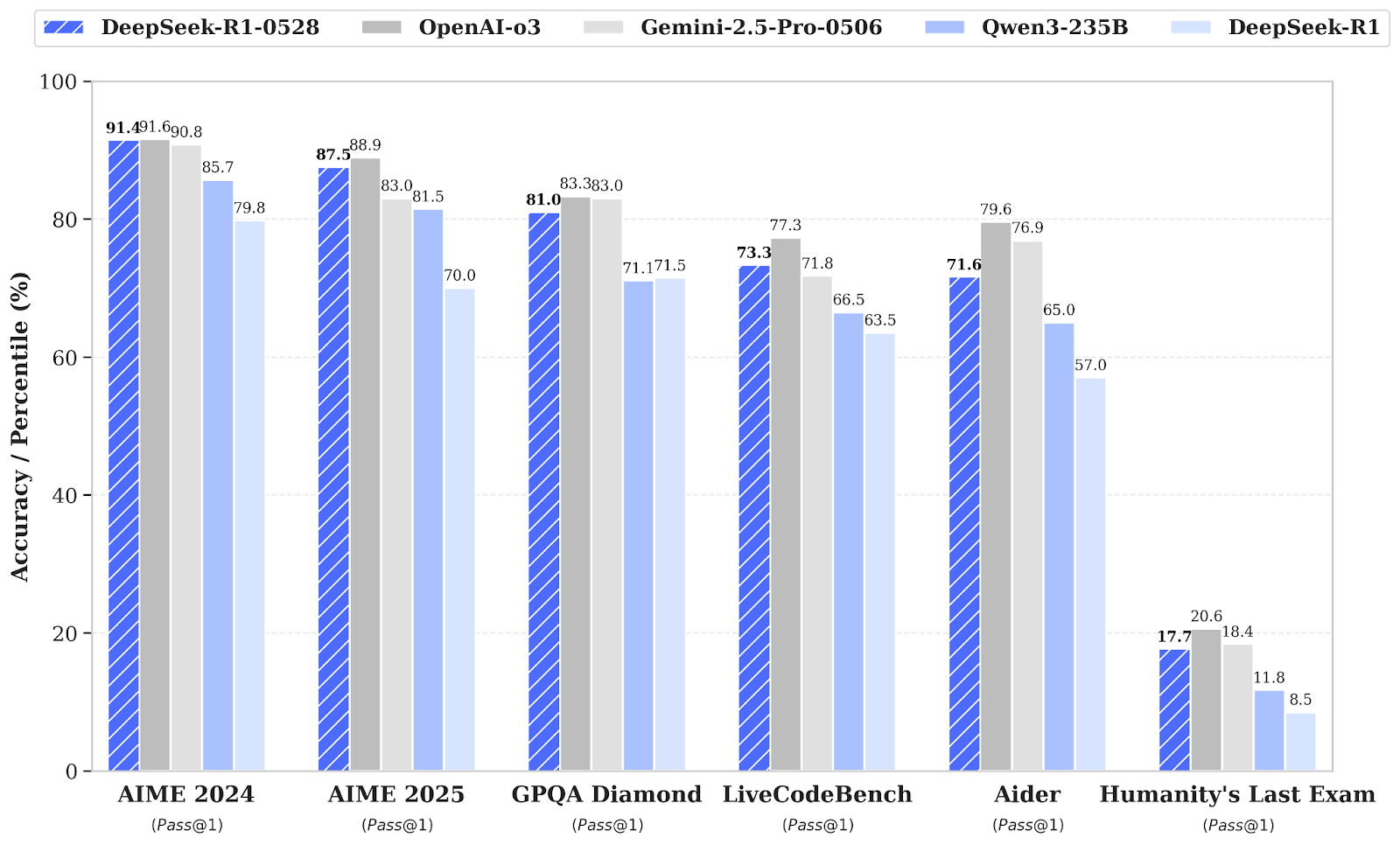
Fuente: deepseek-ai/DeepSeek-R1-0528
En comparación con la versión anterior DeepSeel R1, el modelo actualizado muestra un progreso sustancial en el razonamiento complejo. Por ejemplo, en el examen AIME 2025, la precisión mejoró del 70 % al 87,5 %, gracias a un pensamiento analítico más profundo (el número medio de tokens por pregunta aumentó de aproximadamente 12 000 a 23 000).
Evaluaciones más amplias también muestran tendencias positivas en áreas como el conocimiento, el razonamiento y el rendimiento en codificación. Algunos ejemplos son las mejoras en LiveCodeBench, las calificaciones de Codeforces, SWE Verified y Aider-Polyglot, que indican una mayor profundidad en la resolución de problemas y unas capacidades de codificación superiores en el mundo real.
Apriel-1.5-15b-Thinker es un modelo de razonamiento multimodal de la serie Apriel SLM de ServiceNow. Ofrece un rendimiento competitivo con solo 15 000 millones de parámetros, con el objetivo de obtener resultados de vanguardia dentro de las limitaciones de un presupuesto para una sola GPU. Este modelo no solo añade capacidades de razonamiento por imágenes al modelo anterior, que solo trabajaba con texto, sino que también profundiza en sus capacidades de razonamiento textual.
Como segundo modelo de la serie de razonamiento, ha sido sometido a un extenso entrenamiento previo continuo tanto en el ámbito del texto como en el de la imagen. El posentrenamiento implica un ajuste supervisado (SFT) solo de texto, sin ningún SFT específico para imágenes ni aprendizaje por refuerzo. A pesar de estas limitaciones, el modelo apunta a una calidad de vanguardia en el razonamiento textual y visual para su tamaño.
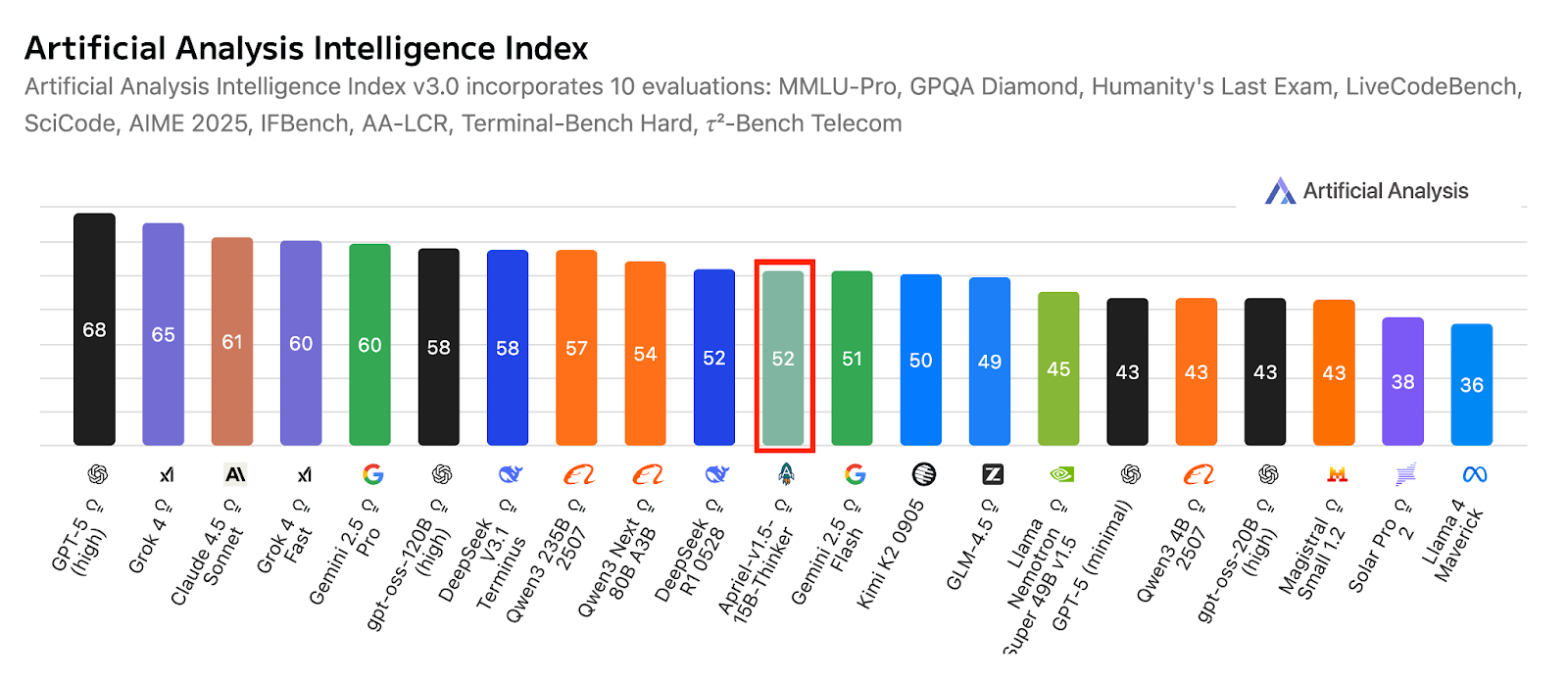
Fuente: ServiceNow-AI/Apriel-1.5-15b-Thinker
Diseñado para funcionar con una sola GPU, prioriza la implementación práctica y la eficiencia. Los resultados de la evaluación indican una gran preparación para aplicaciones en el mundo real, con una puntuación de 52 en el índice de análisis artificial, lo que posiciona al modelo de forma competitiva frente a sistemas mucho más grandes. Esta puntuación también refleja su cobertura en comparación con otros modelos compactos y de vanguardia líderes, al tiempo que mantiene un tamaño reducido adecuado para su uso empresarial.
Kimi-K2-Instruct-0905 es el modelo más reciente y avanzado de la gama Kimi K2. Se trata de un modelo lingüístico de vanguardia basado en la mezcla de expertos, con un total de 1 billón de parámetros y 32 000 millones de parámetros activados. Este modelo está diseñado específicamente para flujos de trabajo de razonamiento y codificación de alta gama.
K2-Instruct-0905 mejora significativamente la capacidad de K2 para gestionar tareas a largo plazo con una ventana de contexto de 256 000 tokens, lo que supone un aumento con respecto a los 128 000 tokens anteriores. Su objetivo es dar soporte a casos de uso robustos basados en agentes, que incluyen chat asistido por herramientas y asistencia para la programación. Como lanzamiento estrella de la serie K2 Instruct, se centra en una ergonomía y fiabilidad sólidas para programadores, con aplicaciones de calidad profesional.
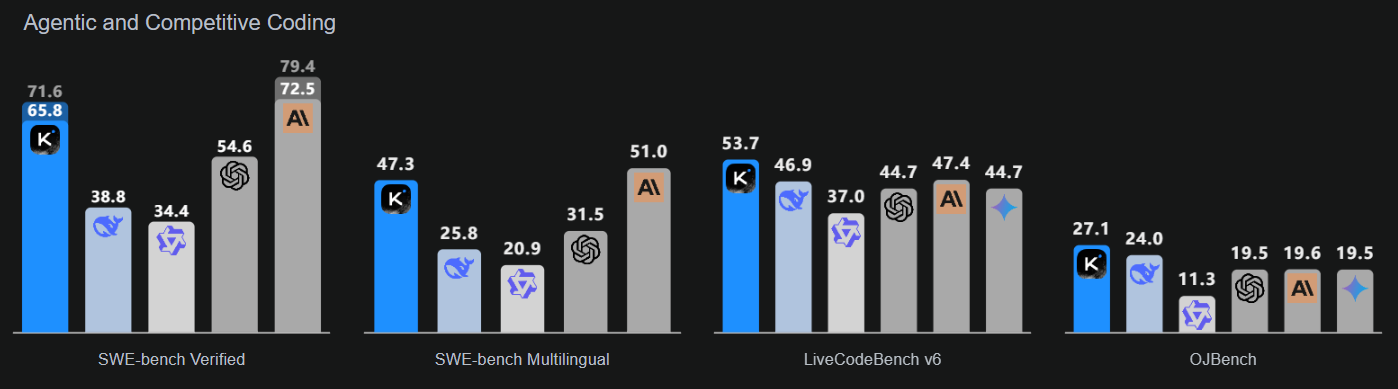
Fuente: Kimi K2: Inteligencia artificial abierta
Este modelo hace hincapié en tres áreas clave: inteligencia de codificación mejorada para tareas basadas en agentes, que muestra claras mejoras en los puntos de referencia públicos y las aplicaciones del mundo real; una interfaz de usuario mejorada que realza tanto la estética como la funcionalidad; y una longitud de contexto ampliada de 256 000 tokens que permite bucles de planificación y edición más extensos.
Llama-3_3-Nemotron-Super-49B-v1_5 es un modelo mejorado de 49 000 millones de parámetros de la línea Nemotron de NVIDIA, derivado del Llama-3.3-70B-Instruct de Meta. Está diseñado específicamente como modelo de razonamiento para tareas de chat y agentes alineadas con los humanos, como la generación aumentada por recuperación (RAG) y la invocación de herramientas.
Este modelo ha sido sometido a un entrenamiento posterior para mejorar sus capacidades de razonamiento, alineación de preferencias y uso de herramientas. También admite flujos de trabajo de contexto largo de hasta 128 000 tokens, lo que lo hace adecuado para aplicaciones complejas de varios pasos.
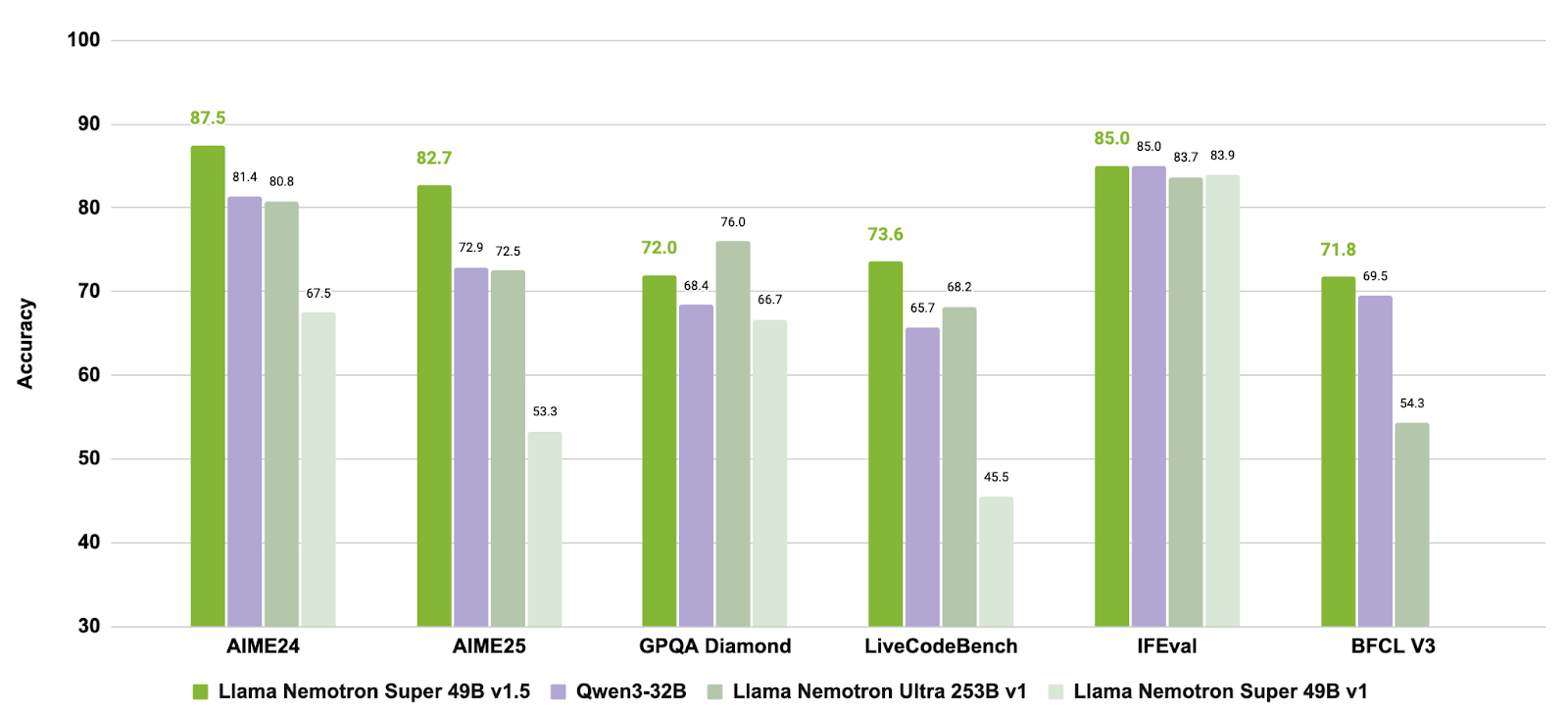
Fuente: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Al combinar un entrenamiento específico posterior para el razonamiento y los comportamientos de los agentes con soporte para tareas de contexto largo, Llama-3.3-Nemotron-Super-49B-v1.5 ofrece una solución equilibrada para los programadores que necesitáis capacidades de razonamiento avanzadas y un uso robusto de las herramientas sin sacrificar la eficiencia en tiempo de ejecución.
Mistral-Small-3.2-24B-Instruct-2506 es una mejora significativa con respecto a Mistral-Small-3.1-24B-Instruct-2503, ya que mejora el seguimiento de instrucciones, reduce los errores de repetición y proporciona una plantilla de llamada de funciones más robusta, todo ello mientras mantiene o mejora ligeramente las capacidades generales. Como modelo de instrucción de 24B parámetros, es ampliamente accesible en todas las plataformas, incluidos los mercados de AWS, donde destaca por su mayor cumplimiento de las instrucciones.
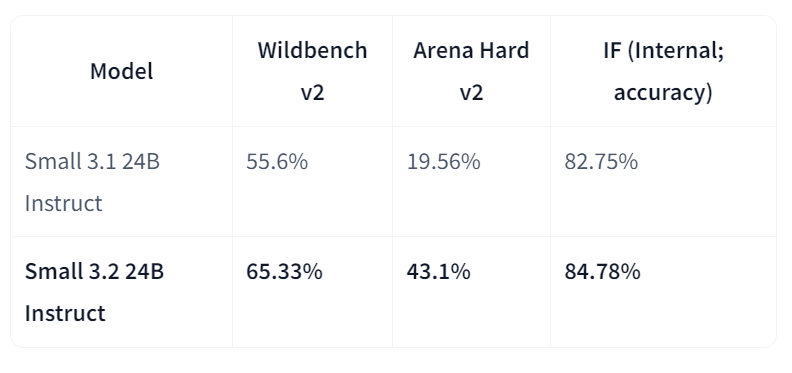
Fuente: mistralai/Mistral-Small-3.2-24B-Instruct-2506
En comparación directa con la versión 3.1, Small-3.2 muestra claras mejoras en la calidad y fiabilidad del asistente. Mejora el rendimiento en el seguimiento de instrucciones en Wildbench v2 (del 55,6 % al 65,33 %) y Arena Hard v2 (del 19,56 % al 43,1 %), mientras que la precisión interna en el seguimiento de instrucciones aumenta del 82,75 % al 84,78 %. Los fallos por repetición en indicaciones difíciles se reducen a la mitad (del 2,11 % al 1,29 %). Mientras tanto, el rendimiento en STEM sigue siendo comparable, con un 69,42 % en MATEMÁTICAS y un 92,90 % en HumanEval+ Pass@5.
En la siguiente tabla, puedes ver una comparación de los mejores modelos:
| Modelo | Puntos fuertes clave | Mejoras y características destacadas |
|---|---|---|
| GLM 4.6 | Razonamiento sólido, flujos de trabajo agenticos y capacidades de codificación. | Ventana de contexto ampliada de 128K a 200K; rendimiento de referencia mejorado frente a GLM-4.5 y DeepSeek-V3.1 |
| gpt-oss-120B | Modelo GPT de peso abierto para razonamiento avanzado y tareas de agencia. | Profundidad de razonamiento configurable, acceso a la cadena de pensamiento, llamada de funciones y formato de respuesta armoniosa. |
| Qwen3-235B-Instruct-2507 | Razonamiento multilingüe de alta precisión y seguimiento de instrucciones. | Contexto de más de 1 millón de tokens, escritura alineada con las preferencias, superando a GPT-4o y Claude Opus 4 (sin pensamiento). |
| DeepSeek-V3.2-Exp | Procesamiento eficiente de contextos largos mediante atención dispersa | Iguala el rendimiento de la versión V3.1 con un consumo informático reducido; eficiencia del transformador optimizada. |
| DeepSeek-R1-0528 | Capacidad avanzada de razonamiento, matemáticas y programación. | Mejora del 17,5 % en el AIME 2025; mayor profundidad analítica y fiabilidad de la codificación. |
| Apriel-1.5-15B-Pensador | Razonamiento multimodal (texto + imagen) en una sola GPU | Preentrenamiento continuo con texto e imágenes; razonamiento de vanguardia para un modelo de tamaño compacto. |
| Kimi-K2-Instruct-0905 | Razonamiento de alto nivel y flujos de trabajo de codificación basados en agentes | Contexto de tokens de 256 K, ergonomía mejorada para los programadores y soporte de tareas mejorado con herramientas. |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Modelo equilibrado de razonamiento y uso de herramientas | Optimizado por NVIDIA para aplicaciones RAG y agenticas; compatibilidad con contextos largos de hasta 128 000 tokens. |
| Mistral-Small-3.2-24B-Instruct-2506 | Seguimiento de instrucciones compacto y fiable | Reducción de los errores de repetición (−50 %) y mejoras significativas en WildBench v2 y Arena Hard v2. |
El espacio LLM de código abierto se está expandiendo rápidamente. Hoy en día, hay muchos más LLM de código abierto que propietarios, y la brecha de rendimiento podría cerrarse pronto, ya que programadores de todo el mundo colaboran para actualizar los LLM actuales y diseñar otros más optimizados.
En este contexto tan dinámico y emocionante, puede resultar difícil elegir el LLM de código abierto más adecuado para tus necesidades. A continuación, se incluye una lista de algunos de los factores que debes tener en cuenta antes de optar por un LLM de código abierto específico:
Los LLM de código abierto no son solo para proyectos o intereses individuales. A medida que la revolución de la IA generativa continúa acelerándose, las empresas están reconociendo la importancia fundamental de comprender e implementar estas herramientas. Los LLM ya se han convertido en un elemento fundamental para impulsar aplicaciones avanzadas de IA, desde chatbots hasta tareas complejas de procesamiento de datos. Garantizar que tu equipo domine las tecnologías de IA y LLM ya no es solo una ventaja competitiva, sino una necesidad para preparar tu negocio para el futuro.
Si eres jefe de equipo o propietario de una empresa y deseas dotar a tu equipo de conocimientos sobre IA y LLM, DataCamp for Business ofrece programas de formación completos que pueden ayudar a tus empleados a adquirir las habilidades necesarias para sacar partido a estas potentes herramientas. Ofrecemos:
Invertir en IA y en la mejora de las habilidades de LLM no solo mejora las capacidades de tu equipo, sino que también posiciona a tu empresa a la vanguardia de la innovación, lo que te permite aprovechar todo el potencial de estas tecnologías transformadoras. Ponte en contacto con nuestro equipo para solicitar una demostración y empezar a crear tu plantilla preparada para la IA hoy mismo.
Los LLM de código abierto están viviendo un momento apasionante. Con su rápida evolución, parece que el espacio de la IA generativa no estará necesariamente monopolizado por los grandes actores que pueden permitirse crear y utilizar estas potentes herramientas.
Solo hemos visto ocho LLM de código abierto, pero el número es mucho mayor y está creciendo rápidamente. En DataCamp seguiremos proporcionando información sobre las últimas novedades en el ámbito de los LLM, ofreciendo cursos, artículos y tutoriales sobre los LLM. Por ahora, echa un vistazo a nuestra lista de materiales seleccionados:
¡Comienza hoy mismo tu aventura con la IA!
programa
Curso
Curso
blog
Yuliya Melnik
15 min
blog
Abid Ali Awan
9 min
blog
Stanislav Karzhev
9 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali


