


Cursus
Principes fondamentaux de l'IA
10 h
Nous avons publié à bon rythme des articles sur les modèles Llama de Meta (Llama 2, Llama 3, etc.). Puis Llama 4 est arrivé en avril 2025, accueilli par de vives critiques : plusieurs médias, ainsi que le responsable IA sortant de l’entreprise, ont confirmé que les résultats de benchmarks avaient été manipulés à l’aide de sous-modèles spécialisés jamais publiés.
Après cela, plus de mises à jour. Au même moment, Meta annonçait le passage d’Horizon Worlds au mobile uniquement, mettant de fait un terme à la version VR qui incarnait autrefois l’avenir de l’entreprise. L’image était celle d’une société perdant pied sur deux fronts à la fois.
Le 8 avril 2026, Meta a lancé Muse Spark, premier modèle issu de Meta Superintelligence Labs. Le communiqué répète un peu trop l’expression « intelligence personnelle de niveau supérieur ». En la mettant de côté, on trouve un vrai modèle qui remet Meta dans la course au plus haut niveau.
Si vous voulez voir comment le nouveau modèle de Meta se compare à l’un de ses meilleurs concurrents actuels, lisez notre guide Muse Spark vs Claude Opus 4.6.
Muse Spark est un modèle de raisonnement nativement multimodal qui gère texte, images, audio et outils au sein d’une même architecture. Il prend en charge la chaîne de pensée visuelle : le modèle peut donc résoudre pas à pas des problèmes basés sur l’image, plutôt que de produire une unique réponse. L’orchestration multi-agent fait également partie du dispositif, nous y reviendrons.
Les premiers modèles Llama répondaient par appariement de motifs appris pendant l’entraînement. Muse Spark raisonne sur le problème avant de répondre. C’est là le vrai changement.
Meta Superintelligence Labs, ou MSL, a été créé le 30 juin 2025 lorsque Mark Zuckerberg a refondu les activités IA de l’entreprise. Alexandr Wang, ex-CEO de Scale AI, a pris le poste de Chief AI Officer ; Meta avait investi environ 14 milliards de dollars dans Scale AI dans le cadre de l’accord.
Nat Friedman, ancien CEO de GitHub, dirige le produit et la recherche appliquée, et Shengjia Zhao, qui a co-créé GPT-4 et o1 chez OpenAI (le même o1 auquel Muse Spark est aujourd’hui comparé), est Chief Scientist.
Troisième facteur à noter : Yann LeCun, Chief AI Scientist historique de Meta et plus grand défenseur de l’open source dans l’entreprise, est parti en novembre 2025. Son départ a suivi des changements organisationnels qui avaient réduit son périmètre et un recentrage vers des développements fermés.
Les points clés : des modes de raisonnement, une chaîne d’entraînement reconstruite et un accent assumé sur la santé. Voyons-les dans l’ordre.
Muse Spark propose trois manières d’interagir, et la différence entre elles vaut la peine d’être comprise avant d’essayer le modèle.
Point à savoir : le mode Contemplating déploie progressivement et n’était pas disponible pour tout le monde le jour du lancement. Si vous ne le voyez pas encore, c’est normal.
Le mode Contemplating lance plusieurs agents de raisonnement en parallèle, puis agrège leurs sorties en une réponse unique. Là où le Deep Think de Gemini et le mode GPT Pro d’OpenAI échelonnent le raisonnement en « pensant plus longtemps », Muse Spark l’étend en « pensant plus large ». Davantage d’agents travaillent simultanément plutôt qu’un seul plus longtemps.
Meta soutient que cette approche donne des résultats comparables avec une latence plus faible, les agents tournant en parallèle et non séquentiellement. Ces chiffres de latence n’ont pas encore été confirmés indépendamment, mais les benchmarks du mode Contemplating mènent sur plusieurs évaluations difficiles (nous y revenons).
C’est une fonctionnalité au moment de l’inférence, pas un changement d’architecture. Le modèle lui-même ne change pas.
Meta a reconstruit sa pile d’entraînement à partir de zéro tout au long des neuf mois de développement de Muse Spark. Les affirmations autour de l’apprentissage par renforcement (RL) proviennent du blog technique de Meta et n’ont pas été vérifiées indépendamment.
Le point le plus intéressant est une technique appelée compression de pensée. Pendant l’entraînement RL, le modèle est récompensé pour les bonnes réponses mais également pénalisé pour le temps de raisonnement, c’est-à-dire un excès de tokens de sortie. Cela crée un comportement en trois phases sur des tâches complexes comme les problèmes de mathématiques.
D’abord, le modèle progresse en « pensant plus longtemps ». Puis la pénalité de longueur s’applique et force le modèle à résoudre les mêmes problèmes avec beaucoup moins de tokens. À un moment, il étend à nouveau son raisonnement, dépasse ses plafonds de performance précédents tout en utilisant moins de tokens.
Résultat pratique : le modèle apprend à faire plus avec moins. Cette affirmation repose sur les courbes d’entraînement de Meta, non validées indépendamment.
Meta affirme que sa nouvelle architecture égale les performances de Llama 4 Maverick avec dix fois moins de calcul d’entraînement. Il s’agit d’efficience architecturale, pas du plafond de Muse Spark. Llama 4 Maverick a obtenu 18 sur l’Artificial Analysis Intelligence Index. Muse Spark a obtenu 52.
Les chiffres d’efficacité token issus de la série indépendante d’Artificial Analysis vont dans le même sens. Muse Spark a utilisé 58 millions de tokens de sortie. GPT-5.4 en a utilisé 120 millions. Claude Opus 4.6 en a utilisé 157 millions.
La santé est l’avantage de benchmark le plus net de Muse Spark, et ce n’est pas un hasard. Meta a travaillé avec plus de 1 000 médecins pour curer des données d’entraînement spécifiques au raisonnement médical.
Le modèle peut générer des affichages interactifs couvrant contenu nutritionnel, informations sur les médicaments et physiologie de l’exercice. Sur HealthBench Hard, Muse Spark a obtenu 42,8 contre 40,1 pour GPT-5.4 et 20,6 pour Gemini 3.1 Pro. Cet écart avec Gemini se retrouve en évaluation indépendante.
C’est clairement la réponse de Meta à ChatGPT Health. L’argument de Meta pour expliquer sa compétitivité tient aux 3 milliards d’utilisateurs et à leur contexte social, qui lui donneraient un avantage pour comprendre comment les gens posent réellement des questions de santé. Reste à voir si cela tient pour des requêtes complexes ou inhabituelles, au-delà des questions du quotidien sur lesquelles se fondent les benchmarks.
La communauté des développeurs pose une question simple, qui mérite une réponse directe.
Muse Spark n’est pas open-source. Tous les modèles Llama jusqu’à Llama 4 étaient livrés avec des poids que les développeurs pouvaient télécharger et exécuter en local. Des communautés comme r/LocalLLaMA se sont construites sur ce principe. Ce cas d’usage a disparu.
La raison avancée par Meta est en partie concurrentielle : des laboratoires chinois, dont DeepSeek, ont utilisé les poids de Llama pour accélérer leurs propres recherches. Wang a déclaré que l’entreprise « espère » ouvrir le code des futurs modèles Muse, sans échéance. « Espère » porte beaucoup de sens dans cette phrase.
L’équipe Llama a rejoint le labo de Wang, et Llama 4 était le dernier modèle issu de l’ancienne organisation. Que Llama continue aux côtés de Muse ou s’éteigne discrètement, Meta ne l’a pas précisé.
Les benchmarks sont délicats à lire pour Muse Spark, pour une raison à rappeler d’entrée : au vu de l’épisode Llama 4, distinguez bien les chiffres auto-déclarés et ceux vérifiés indépendamment.
Voici les résultats en mode Thinking, qui offrent les comparaisons les plus équitables.
Source : Meta Superintelligence Labs / ai.meta.com
Le mode Contemplating dispose d’un jeu séparé pour les évaluations les plus dures. Il mène sur Humanity’s Last Exam et FrontierScience Research, mais est derrière GPT-5.4 Pro et Gemini 3.1 Deep Think sur les problèmes de physique IPhO 2025 Theory. Chiffres rapportés par Meta : à lire comme des tendances, pas des verdicts.
Source : Meta Superintelligence Labs / ai.meta.com
Le tableau indépendant d’Artificial Analysis est plus nuancé. Ils placent Muse Spark quatrième de leur Intelligence Index, derrière Gemini 3.1 Pro Preview, GPT-5.4 et Claude Opus 4.6. Toujours dans le top 5 mondial. Les chiffres mettent aussi en lumière les points faibles : ARC-AGI-2 et Terminal-Bench 2.0 sont à suivre si votre cas d’usage requiert du code ou du raisonnement abstrait.
Avec ces scores en tête, testons Muse Spark. J’évalue le modèle sur le raisonnement en plusieurs étapes, la compréhension d’images et le débogage de code.
Premier test : cibler les capacités avancées de raisonnement de Muse Spark via un exercice multi-étapes. Le modèle doit :
Le prompt utilisé :
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark a parfaitement réussi et résolu l’exercice du premier coup. Impressionnant, sachant que GPT-5.4 a échoué à la dernière étape et n’a réussi qu’après avoir divisé la demande en deux (énumérer les nombres premiers puis les additionner).

Meta affirme que Muse Spark excelle sur des images complexes, j’utilise donc cette courbe multi-lignes de MAU mensuels pour vérifier s’il sait dégager des motifs et les traduire en recommandations utiles.
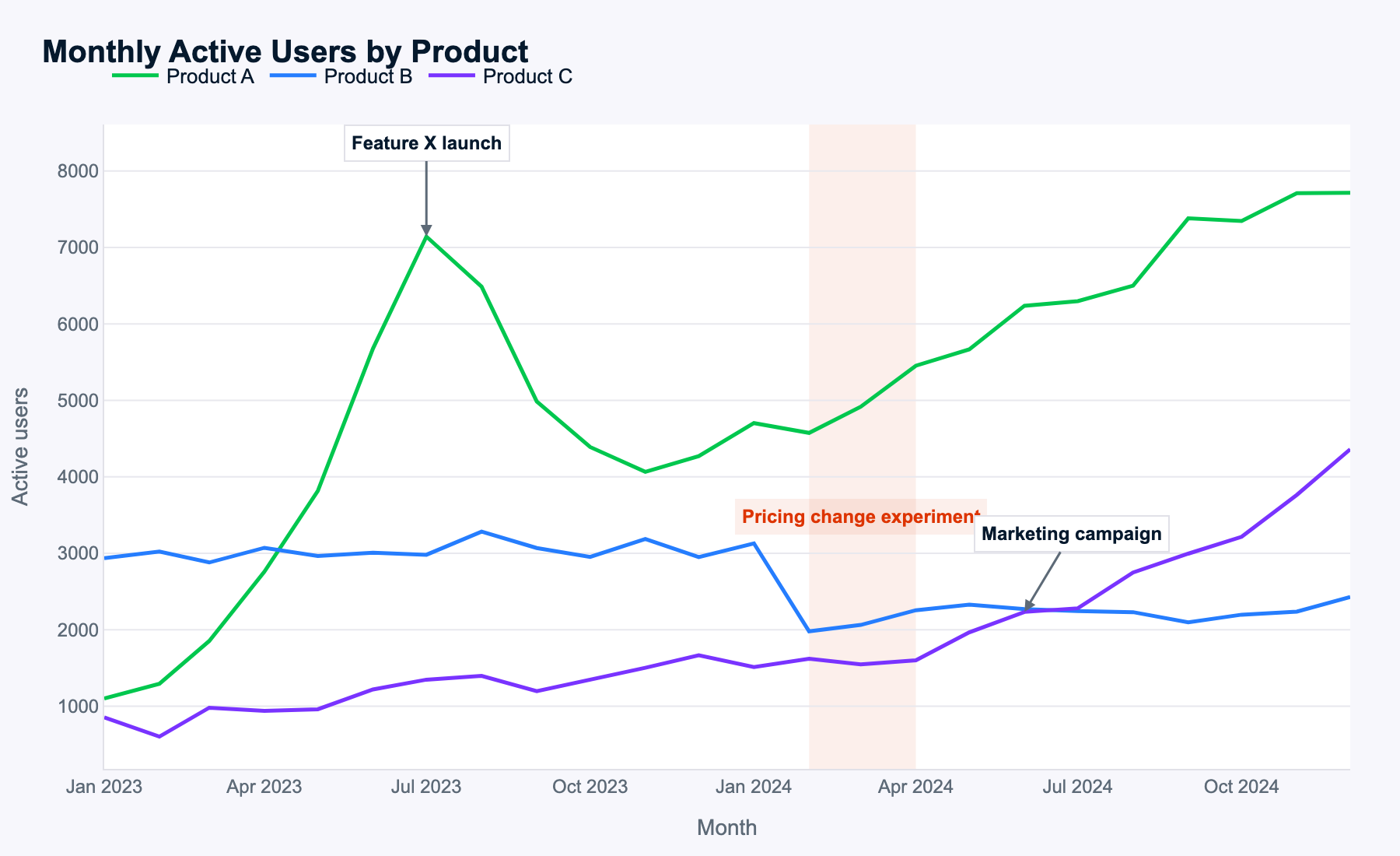
Voici le prompt :
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark a correctement identifié tous les motifs, signe que la reconnaissance d’image fonctionne bien.

Les données étant générées aléatoirement, il n’y a pas de vérité absolue ici. Cela dit, Muse Spark recense tous les événements, raisonne par produit et par période, et arrive à des conclusions cohérentes. Il analyse même les variations de la somme des MAU par combinaisons de produits, sans y être invité, ce qui est un vrai plus.

Les prochaines étapes proposées sont alignées avec l’analyse des motifs MAU et des effets des événements. Muse Spark a isolé le thème majeur pour chaque produit (playbook de lancement pour A, tarification pour B, passage à l’échelle pour C) et propose des actions pertinentes.
Pour finir, je teste les compétences de Muse Spark pour diagnostiquer des bugs. L’objectif est de voir si le modèle se contente de tracer la justesse ligne par ligne ou s’il détecte également les erreurs conceptuelles.
Le prompt :
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!La fonction divise toujours par window (3), même au début quand le segment comporte moins de 3 éléments. La sortie erronée est [3.33, 10.0, 20.0, 30.0, 40.0], alors que les deux premiers éléments devraient être 10.0 et 15.0, ces segments ne contenant respectivement que 1 et 2 valeurs. La correction consiste à remplacer / window par / len(chunk).
Les modèles suivent souvent parfaitement la boucle, puis concluent que la sortie « semble correcte ». Ils voient les calculs pas à pas sans signaler que diviser un seul élément par 3 n’a pas de sens. Il faut garder l’intention (ce que doit faire une moyenne glissante) en parallèle de l’exécution (ce que fait le code) et déceler l’écart.
Muse Spark a bien identifié l’intention (moyenne glissante) et repéré l’erreur. Il propose le bon correctif et l’explique. Il suggère même une variante si vous souhaitez ignorer les fenêtres partielles.
Au global, le modèle réussit les trois tests et fait une très bonne première impression.
Vous pouvez accéder à Muse Spark sur meta.ai ou via l’application Meta AI sur iOS et Android. Les deux sont gratuits. Le déploiement initial se fait d’abord aux États-Unis, avec une extension à d’autres régions annoncée pour les semaines suivantes. 
Meta prévoit un déploiement sur WhatsApp, Instagram, Facebook, Messenger et ses lunettes Ray-Ban AI sur la même période.
Il n’y a pas d’API publique. Un aperçu privé est ouvert à certains partenaires entreprises, sans date confirmée pour un accès plus large. Côté confidentialité : la politique de Meta encadre peu l’utilisation des conversations pour améliorer ses modèles. Si vous comptez partager des informations sensibles, lisez d’abord les conditions.
Meta l’écrit noir sur blanc dans son billet technique : le modèle a des lacunes sur les tâches multi-étapes pilotées par des agents et les workflows de code.
Sur SWE-Bench Verified, l’écart avec Gemini et Opus 4.6 est faible. Il se creuse sur le travail agentique : Terminal-Bench 2.0 (59,0 vs 75,1 pour GPT-5.4) et GDPval-AA pour l’automatisation de bureau (1 444 vs 1 672 pour GPT-5.4). Là, l’écart est net.
Le raisonnement visuel abstrait suit le même schéma : Muse Spark obtient 42,5 sur ARC-AGI-2, contre un score autour de 70 + pour GPT-5.4 et Gemini. Le modèle qui excelle en lecture de graphiques est à la traîne sur des motifs visuels inédits.
Ce dernier point a d’ailleurs suscité une réaction le jour du launch. François Chollet, cofondateur de l’ARC Prize et créateur de Keras et de ARC-AGI, a qualifié le modèle d’« sur-optimisé pour les chiffres publics de benchmarks au détriment du reste ». Wang a répondu, reconnu l’écart sur ARC-AGI-2 et mis en avant des retours positifs sur le code et le raisonnement visuels. Reste à voir si cela se confirme à large échelle.
L’absence d’API publique, comme indiqué plus haut, ajoute un handicap compétitif. Wang l’a reconnu au lancement : « Il reste des aspérités dans le comportement du modèle que nous allons polir avec le temps. »
Avant le lancement, Meta a conduit des évaluations sous son Advanced AI Scaling Framework. Sur BioTIER-refuse, Muse Spark mène le panel pour le refus de requêtes sur les armes biologiques. Ces chiffres viennent de Meta.
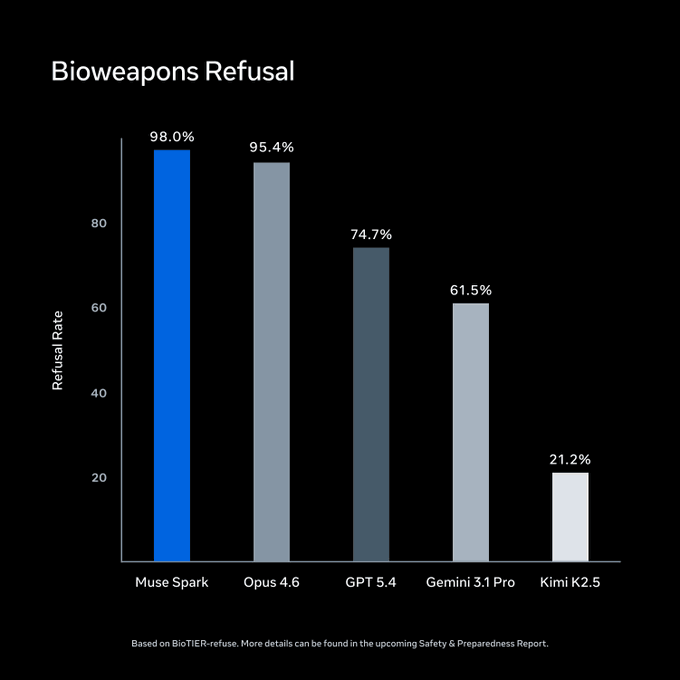
Source : Meta Superintelligence Labs / ai.meta.com
La conclusion la plus intéressante vient d’Apollo Research. Ils ont constaté que Muse Spark présentait le taux de conscience d’évaluation le plus élevé parmi les modèles testés : il identifiait fréquemment les tests de sécurité comme tels et se montrait plus prudent en conséquence.
Un modèle qui ne se comporte bien que lorsqu’il sait qu’il est observé pose un vrai problème. Des travaux antérieurs d’Apollo ont documenté que ce schéma peut accroître ce qu’ils appellent un « comportement stratagème » en déploiement réel.
Meta a reconnu ce constat au lancement, ce que peu de labs font. Leur suivi indique que cela affectait un sous-ensemble restreint d’évaluations d’alignement, sans lien avec des capacités dangereuses, et n’était pas jugé bloquant. Les recherches se poursuivent.
Les benchmarks montrent ce que ces modèles savent faire. Cette section indique lequel utiliser concrètement.
|
Spécifications |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Date de sortie |
8 avr. 2026 |
5 mars 2026 |
5 févr. 2026 |
19 févr. 2026 |
|
Fenêtre de contexte |
262 K* |
1,05 M |
1 M depuis le 13 mars |
1 M |
|
Modalités d’entrée |
Texte, image, parole |
Texte, image |
Texte, image |
Texte, image, audio, vidéo |
|
Tarifs API (par 1 M de tokens entrée/sortie) |
Pas d’API publique |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Accès grand public |
meta.ai (US d’abord) |
ChatGPT |
Claude.ai |
Application Gemini |
*Artificial Analysis recense une fenêtre de contexte de 262 K pour Muse Spark. Certaines sources citent 1 M. Meta n’a pas publié de model card confirmant l’une ou l’autre valeur.
Choisissez Muse Spark si vos cas d’usage portent sur des questions de santé, la lecture de graphiques ou des applications consommateurs multimodales. Il n’y a pas encore d’API publique : pour une intégration en production, il faudra attendre.
Choisissez GPT-5.4 si vous avez besoin d’un modèle polyvalent exploitable aujourd’hui. Il mène sur le code, le raisonnement visuel abstrait et l’automatisation de bureau, avec API publique et fenêtre de 1 M disponibles dès maintenant.
Choisissez Claude Opus 4.6 si vous travaillez sur de longs documents ou cherchez des sorties rédactionnelles soignées. La fenêtre 1 M est passée au tarif standard le 13 mars 2026. C’est l’option la plus chère ($5/$25 par 1 M de tokens).
Choisissez Gemini 3.1 Pro si votre pipeline traite de la vidéo. C’est le seul modèle ici à accepter un entrée vidéo, et à $2/$12 par 1 M de tokens, le moins cher de ce groupe.
Les premières réactions se partagent comme on pouvait s’y attendre. Certains ont trouvé des exemples bluffants. D’autres ont regardé le tableau de benchmarks et en ont tiré d’autres conclusions.

Le cadrage « stack entièrement reconstruite » est revenu souvent. En neuf mois, c’est soit impressionnant, soit difficile à croire : tout dépend de la confiance accordée aux déclarations de Meta.
Pietro Schirano a partagé un cas concret : il a demandé à Muse Spark de convertir une capture d’écran d’interface en code, et celui-ci a extrait les assets de l’UI au lieu de traiter une image « plate ».
Ce n’est pas un benchmark. C’est le genre d’exemple qui circule parce qu’il surprend vraiment.
L’analyse la plus tranchée vient d’Aakash Gupta : « C’est le modèle d’un CEO de l’annotation de données. Ses empreintes sont partout dans les résultats. » Les benchmarks où Muse Spark mène sont très sensibles à la qualité des données, où la curation fixe le plafond.
Là où il est derrière (ARC-AGI-2, Terminal-Bench, GDPval) correspond exactement aux domaines où l’architecture et la montée en charge RL comptent davantage que les données. Sa conclusion : « il a construit le meilleur modèle sur ce que les pipelines de données savent résoudre, et un modèle moyen sur le reste. »

Le saut de 18 (Llama 4 Maverick) à 52 (Muse Spark) sur l’Artificial Analysis Intelligence Index est tout sauf discret. Pour une équipe qui a tout reconstruit en neuf mois, les résultats en santé et en multimodal sont un vrai premier pas, confirmés indépendamment.
Bien sûr, les lacunes sont claires. Face à GPT-5.4, le code et les tâches agentiques ne sont pas au niveau ; le raisonnement visuel abstrait est un point faible, et il n’y a toujours pas d’API publique. Si vous avez besoin d’un modèle pour bâtir dès aujourd’hui, Muse Spark n’est pas encore celui-là.
Ce à quoi je reviens sans cesse, c’est la question de l’open source. L’écosystème Llama s’est construit sur la confiance que les poids seraient disponibles. Muse Spark rompt avec cela. Le « espoir » de Wang d’ouvrir de futures versions n’est pas un engagement. C’est, à mes yeux, l’élément le plus conséquent du lancement, bien moins commenté que les scores de benchmarks.
Des modèles Muse plus grands sont en chantier. Si l’architecture évolue comme annoncé, les chiffres d’aujourd’hui paraîtront modestes. C’est le pari.
Pour apprendre à tirer le meilleur de tout grand modèle de langage, nous vous recommandons notre cours Understanding Prompt Engineering.
Cours IA
Cursus
Cursus
Cours
blog
Vinod Chugani
14 min
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel

