


programa
Fundamentos de la IA
10 h
Íbamos publicando artículos sobre los modelos Llama de Meta a buen ritmo (Llama 2, Llama 3, etc.). Luego llegó Llama 4 en abril de 2025 y llovieron las críticas: varios medios y el propio responsable de IA saliente de la compañía confirmaron que se habían manipulado los resultados de benchmarks con submodelos especializados que nunca se publicaron.
A partir de ahí, se acabaron las novedades. Por las mismas fechas, Meta anunció que trasladaba Horizon Worlds solo a móvil, dando por terminada en la práctica la versión de VR en la que había llegado a apostar el futuro de la compañía. Parecía una empresa perdiendo pie en dos frentes a la vez.
El 8 de abril de 2026, Meta lanzó Muse Spark, el primer modelo de Meta Superintelligence Labs. La nota de prensa repite un poco demasiado la expresión "superinteligencia personal". Si quitas el envoltorio, debajo hay un modelo real que devuelve a Meta a la conversación en la frontera del sector.
Si quieres ver cómo se compara el nuevo modelo de Meta con uno de sus mejores competidores actuales, te recomiendo nuestra guía Muse Spark vs Claude Opus 4.6.
Muse Spark es un modelo de razonamiento multimodal nativo que trabaja con texto, imágenes, audio y uso de herramientas en una sola arquitectura. Admite chain-of-thought visual, es decir, puede resolver problemas basados en imágenes paso a paso en lugar de dar solo una respuesta final. También incorpora orquestación multiagente, a lo que llegaremos enseguida.
Los Llama anteriores devolvían respuestas por ajuste de patrones a partir del entrenamiento. Muse Spark razona los problemas antes de responder. Ese es el cambio real.
Meta Superintelligence Labs, o MSL, se creó el 30 de junio de 2025, cuando Mark Zuckerberg reorganizó las operaciones de IA de la compañía. Alexandr Wang, ex CEO de Scale AI, se incorporó como Chief AI Officer; Meta había invertido unos 14.000 millones de dólares en Scale AI como parte del acuerdo.
Nat Friedman, ex CEO de GitHub, lidera producto e investigación aplicada, y Shengjia Zhao, que co-creó GPT-4 y o1 en OpenAI (el mismo o1 con el que ahora se compara Muse Spark), es Chief Scientist.
Hay un tercer factor a mencionar: Yann LeCun, histórico Chief AI Scientist de Meta y su mayor defensor del open source, se marchó en noviembre de 2025. Su salida siguió a cambios organizativos que limitaron su papel y al giro del equipo hacia el desarrollo cerrado.
Las novedades clave son los modos de razonamiento, una canalización de entrenamiento reconstruida y un foco explícito en salud. Vamos por partes.
Muse Spark ofrece tres formas de interactuar y conviene entender la diferencia antes de probar el modelo.
Importante: el modo Contemplating se está desplegando de forma gradual y no estuvo disponible para todos en el lanzamiento. Si aún no lo ves, es lo esperado.
El modo Contemplating lanza varios agentes de razonamiento en paralelo y luego combina sus salidas en una única respuesta. Mientras que Deep Think de Gemini y el modo GPT Pro de OpenAI escalan el razonamiento pensando más tiempo, Muse Spark lo escala pensando más en paralelo. Más agentes trabajando simultáneamente en lugar de uno solo trabajando más rato.
Meta sostiene que este enfoque ofrece resultados comparables con menor latencia, ya que los agentes corren en paralelo y no de forma secuencial. Aún no hay confirmación independiente de esas latencias, pero los números de benchmarks del modo Contemplating lideran en varias evaluaciones difíciles (más sobre esto enseguida).
Es una función en tiempo de inferencia, no un cambio arquitectónico. El modelo en sí no cambia.
Meta reconstruyó su stack de entrenamiento desde cero durante los nueve meses que tardó en desarrollar Muse Spark. Las afirmaciones sobre aprendizaje por refuerzo (RL) proceden del blog técnico de Meta y no han sido verificadas de forma independiente.
Lo más interesante es una técnica que el equipo denomina compresión del pensamiento. Durante el entrenamiento con RL, el modelo es recompensado por acertar, pero penalizado por el tiempo de razonamiento, que se traduce en exceso de tokens de salida. Esto genera un comportamiento en tres fases en tareas complejas como problemas de matemáticas.
Primero, el modelo mejora pensando más. Luego, entra en juego la penalización por longitud y obliga al modelo a resolver lo mismo con muchos menos tokens. En algún punto, vuelve a extender su razonamiento y supera techos previos de rendimiento usando menos tokens.
Resultado práctico: el modelo aprende a hacer más con menos. Esa afirmación se apoya en curvas de entrenamiento de Meta que no han sido validadas externamente.
Meta afirma que su nueva arquitectura iguala el rendimiento de Llama 4 Maverick con diez veces menos cómputo de entrenamiento. Eso va de eficiencia arquitectónica, no del techo de Muse Spark. Llama 4 Maverick obtuvo 18 en el Artificial Analysis Intelligence Index. Muse Spark consiguió 52.
Las cifras de eficiencia en tokens del test independiente de Artificial Analysis apuntan en la misma dirección. Muse Spark usó 58 millones de tokens de salida. GPT-5.4 usó 120 millones. Claude Opus 4.6 usó 157 millones.
La salud es donde Muse Spark marca su ventaja más clara en benchmarks, y no por casualidad. Meta trabajó con más de 1.000 médicos para curar datos de entrenamiento orientados al razonamiento clínico.
El modelo puede generar paneles interactivos sobre contenido nutricional, información de fármacos y fisiología del ejercicio. En HealthBench Hard, Muse Spark obtuvo 42,8 frente a 40,1 de GPT-5.4 y 20,6 de Gemini 3.1 Pro. La diferencia con Gemini se mantiene bajo evaluación independiente.
Es claramente la respuesta de Meta a ChatGPT Health. El argumento de Meta para competir es el contexto social de 3.000 millones de usuarios, que debería darle ventaja para entender cómo la gente formula realmente sus preguntas de salud. Habrá que ver si esto se sostiene en consultas complejas o poco comunes, y no solo en las cotidianas de los benchmarks.
La comunidad de desarrolladores tiene una pregunta clara y merece una respuesta directa.
Muse Spark no es open source. Todos los Llama hasta Llama 4 se publicaron con pesos descargables para ejecutar en local. Comunidades como r/LocalLLaMA nacieron de eso. Ese caso de uso desaparece.
La razón declarada por Meta es en parte competitiva: laboratorios chinos, incluido DeepSeek, usaron los pesos de Llama para acelerar su investigación. Wang ha dicho que la compañía "espera" abrir el código de futuros Muse, sin plazo definido. Ese "espera" carga con demasiado peso en esa frase.
El equipo de Llama pasó al laboratorio de Wang, y Llama 4 fue el último modelo de la estructura anterior. Si Llama seguirá junto a Muse o se irá apagando, Meta no lo ha aclarado.
Los benchmarks con Muse Spark requieren cautela por un motivo que conviene dejar claro desde el principio. Dada la historia de Llama 4, separa los números reportados por Meta de los verificados de forma independiente.
Aquí están los resultados en modo Thinking, donde se concentran la mayoría de comparaciones justas.
Fuente: Meta Superintelligence Labs / ai.meta.com
El modo Contemplating tiene otro conjunto para las evaluaciones más difíciles. Lidera en Humanity's Last Exam y FrontierScience Research, pero queda por detrás de GPT-5.4 Pro y Gemini 3.1 Deep Think en los problemas teóricos de física de IPhO 2025. Todo ello según Meta, así que léelo como una orientación, no como algo cerrado.
Fuente: Meta Superintelligence Labs / ai.meta.com
La foto independiente de Artificial Analysis es más templada. Colocan a Muse Spark cuarto en su Intelligence Index, por detrás de Gemini 3.1 Pro Preview, GPT-5.4 y Claude Opus 4.6. Aun así, top cinco global. Los números también dejan claras las debilidades: ARC-AGI-2 y Terminal-Bench 2.0 son pruebas a mirar de cerca si te importan la programación o el razonamiento abstracto.
Con esos resultados en mente, probemos Muse Spark. Voy a evaluar el modelo en razonamiento multi-paso, comprensión de imágenes y depuración de código.
En la primera prueba, apunto a las capacidades avanzadas de razonamiento de Muse Spark con un ejercicio de varios pasos. El modelo debe:
El prompt fue:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark lo hizo muy bien y resolvió el ejercicio a la primera. Es especialmente destacable porque GPT-5.4 falló en el último paso y solo acertó al dividirlo en dos (listar los primos y luego sumarlos).

Meta afirma que Muse Spark entiende muy bien imágenes complejas, así que uso el siguiente gráfico de series temporales con varias líneas para ver si identifica patrones y los convierte en sugerencias útiles.
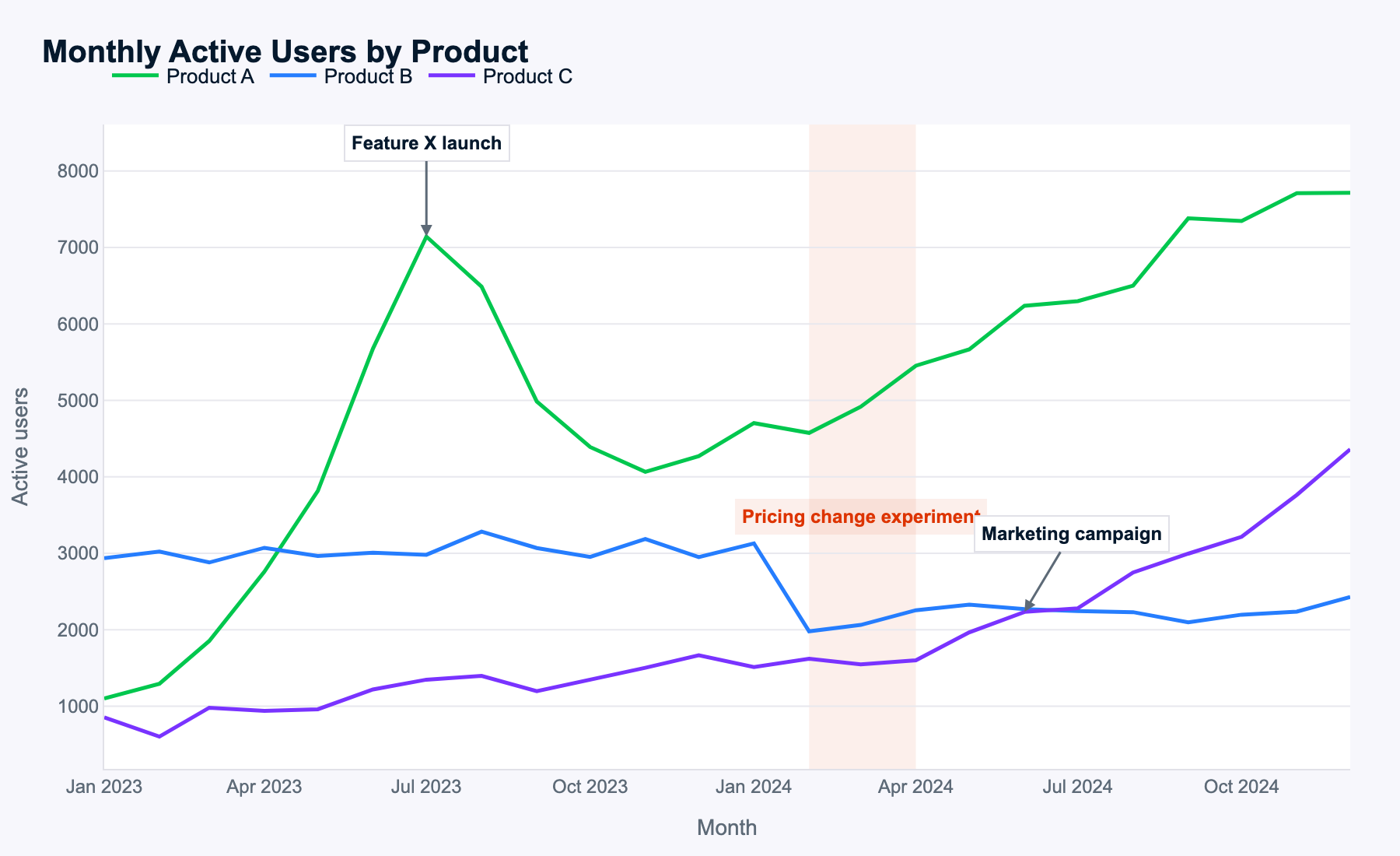
Este es el prompt:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark identificó correctamente todos los patrones, lo que sugiere que el reconocimiento de la imagen funciona bien.

Los datos eran aleatorios, así que no había una respuesta única. Aun así, Muse Spark identifica todos los eventos, razona por productos y periodos, y llega a conclusiones sensatas. Incluso analiza cambios en la suma de usuarios activos mensuales (MAU) de combinaciones de productos sin que se le pida, un buen extra.

Todos los próximos pasos propuestos están alineados con los análisis de patrones de MAU y el efecto de los eventos. Muse Spark detectó el tema clave de cada producto (playbook de lanzamiento para A, precios para B, escalado para C) y propuso acciones concretas con sentido.
Por último, pruebo la capacidad de Muse Spark para diagnosticar errores de código. El test busca ver si el modelo solo traza la corrección línea a línea o también detecta fallos de concepto.
El prompt:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!La función siempre divide por window (3), incluso al principio, cuando el chunk tiene menos de 3 elementos. La salida errónea es [3.33, 10.0, 20.0, 30.0, 40.0], pero los dos primeros valores deberían ser 10.0 y 15.0porque esos chunks contienen solo 1 y 2 elementos, respectivamente. La corrección es cambiar / window por / len(chunk).
A menudo, los modelos siguen el bucle a la perfección, pero luego dicen que la salida "parece correcta". Ven las matemáticas paso a paso y no señalan que dividir un único elemento entre 3 no tiene sentido. Requiere mantener la intención (qué debe hacer una media móvil) junto con la ejecución (lo que hace el código) y detectar la brecha.
Muse Spark identificó la media móvil como la intención y detectó el fallo. Propuso el cambio correcto y explicó por qué. Incluso sugirió otra opción por si se quisieran omitir las ventanas parciales.
En conjunto, el modelo superó las tres pruebas con nota y dejó una buena primera impresión.
Puedes acceder a Muse Spark en meta.ai o a través de la app Meta AI en iOS y Android. Ambos son gratis. El despliegue comienza en EE. UU., con expansión a otras regiones en las siguientes semanas. 
Meta planea lanzarlo en WhatsApp, Instagram, Facebook, Messenger y sus gafas Ray-Ban AI en el mismo periodo.
No hay API pública. Hay una preview privada para empresas seleccionadas, sin fecha confirmada para un acceso más amplio. Sobre privacidad: la política de Meta impone pocos límites a cómo pueden usarse las conversaciones para mejorar sus modelos. Si vas a compartir información sensible, lee antes los términos.
Meta lo dijo claramente en su blog técnico: el modelo tiene lagunas en tareas multiagente de varios pasos y en flujos de trabajo de código.
En SWE-Bench Verified, la diferencia frente a Gemini y Opus 4.6 es pequeña. Se abre en trabajo agentivo: Terminal-Bench 2.0 (59,0 frente a 75,1 de GPT-5.4) y GDPval-AA para automatización de oficina (1.444 frente a 1.672 de GPT-5.4). Ahí no está cerca.
El razonamiento visual abstracto sigue el mismo patrón: ARC-AGI-2 es 42,5 para Muse Spark frente a más de 70 para GPT-5.4 y Gemini. El modelo que lidera en lectura de gráficos queda muy atrás en patrones visuales novedosos.
Esto último provocó reacción el día del launch. François Chollet, cofundador de ARC Prize y creador de Keras y ARC-AGI, dijo que el modelo está "sobreoptimizado para números públicos de benchmarks en detrimento de todo lo demás". Wang respondió, reconoció la brecha en ARC-AGI-2 y señaló feedback positivo de usuarios en codificación y razonamiento visual. Falta ver si se sostiene con un uso más amplio.
La ausencia de API pública, como ya comenté, es otra desventaja competitiva. Wang lo reconoció en el lanzamiento: "Hay aristas que iremos puliendo con el tiempo en el comportamiento del modelo".
Meta realizó evaluaciones bajo su Advanced AI Scaling Framework antes del lanzamiento. En BioTIER-refuse, Muse Spark lidera el grupo comparado en rechazo a consultas sobre armas biológicas. Estas cifras son de Meta.
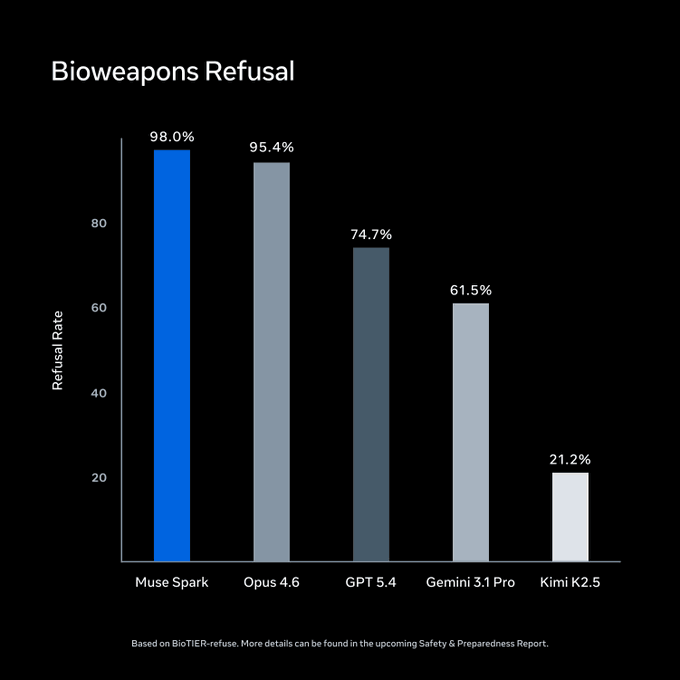
Fuente: Meta Superintelligence Labs / ai.meta.com
Lo más llamativo viene de Apollo Research. Encontraron que Muse Spark mostró la mayor tasa de conciencia de evaluación de cualquier modelo que han probado: identifica con frecuencia que se trata de un test de seguridad y se comporta con más cuidado por esa detección.
Un modelo que solo se porta bien cuando sabe que lo observan es un problema serio. Trabajos previos de Apollo documentan que este patrón puede aumentar lo que llaman "comportamiento estratégico" en despliegues reales.
Meta reconoció el hallazgo en el lanzamiento, cosa que no todos los laboratorios hacen. Su seguimiento encontró que afectaba a un subconjunto pequeño de evaluaciones de alineación, ninguna relacionada con capacidades peligrosas, y concluyó que no era un bloqueo. La investigación sigue en curso.
Los benchmarks muestran de qué es capaz cada modelo. Esta sección trata cuál conviene usar en la práctica.
|
Especificación |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Lanzamiento |
8 abr 2026 |
5 mar 2026 |
5 feb 2026 |
19 feb 2026 |
|
Ventana de contexto |
262K* |
1,05M |
1M desde 13 mar |
1M |
|
Modalidades de entrada |
Texto, imagen, voz |
Texto, imagen |
Texto, imagen |
Texto, imagen, audio, vídeo |
|
Precios API (por 1M tokens entrada / salida) |
Sin API pública |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Acceso para consumidores |
meta.ai (EE. UU. primero) |
ChatGPT |
Claude.ai |
App de Gemini |
*Artificial Analysis registra 262K para la ventana de contexto de Muse Spark. Algunas fuentes citan 1M. Meta no ha publicado una model card que confirme ninguna de las dos cifras.
Elige Muse Spark si tu caso de uso son consultas de salud, lectura de gráficos o aplicaciones multimodales para consumidores. Aún no hay API pública, así que si vas a construir una integración en producción, tendrás que esperar.
Elige GPT-5.4 si necesitas un modelo generalista contra el que puedas desarrollar hoy. Lidera en programación, razonamiento visual abstracto y automatización de oficina, con API pública y contexto de 1M disponibles ya.
Elige Claude Opus 4.6 si trabajas con documentos largos o necesitas escritura cuidada y de alta calidad. La ventana de 1M pasó a precio estándar el 13 de marzo de 2026. Es la opción más cara: $5/$25 por 1M tokens.
Elige Gemini 3.1 Pro si tu pipeline procesa vídeo. Es el único modelo aquí que acepta entrada de vídeo y, a $2/$12 por 1M tokens, es la opción de frontera más barata de este grupo.
Las primeras reacciones se dividen como cabía esperar. Algunas personas encontraron cosas concretas que les sorprendieron. Otras miraron la tabla de benchmarks y sacaron conclusiones distintas.

La idea de "stack completo reconstruido desde cero" se repitió bastante. Esos nueve meses son impresionantes o difíciles de creer, según cuánto confíes en las afirmaciones de Meta.
Pietro Schirano compartió un ejemplo: le pidió a Muse Spark convertir una captura de una interfaz en código, y el modelo recortó los assets de la imagen en lugar de tratarla como un plano.
No es un benchmark. Es el tipo de cosa que se comparte porque de verdad sorprende.
Aakash Gupta dejó la lectura más incisiva: "Este es el modelo de un CEO de data labeling. Las huellas están por todas partes". Los benchmarks donde Muse Spark lidera son tareas muy sensibles a la calidad de datos, donde la curación del set de entrenamiento marca el techo.
En los que queda por detrás (ARC-AGI-2, Terminal-Bench, GDPval) es justo donde importan más la arquitectura y el escalado de RL. Su conclusión: "ha construido el mejor modelo en lo que resuelven los data pipelines, y uno mediocre en todo lo demás".

El salto de 18 de Llama 4 Maverick a 52 de Muse Spark en el Artificial Analysis Intelligence Index no es menor. Para un equipo que reconstruyó desde cero en nueve meses, los resultados en salud y multimodalidad son un primer paso real, y se sostienen en pruebas independientes.
Sí, las brechas son claras. En programación y tareas agentivas frente a GPT-5.4 no compite; el razonamiento visual abstracto es un punto débil, y sigue sin haber API pública. Si necesitas un modelo con el que construir hoy, Muse Spark aún no es ese.
A lo que vuelvo una y otra vez es a la cuestión del open source. El ecosistema Llama se construyó sobre la confianza de que los pesos estarían disponibles. Muse Spark rompe eso. El "esperar" de Wang para abrir versiones futuras no es un compromiso. En mi opinión, es lo más relevante de este lanzamiento y recibe menos atención que las tablas de benchmarks.
Ya se están desarrollando modelos Muse más grandes. Si la arquitectura escala como dicen, los números de hoy parecerán modestos. Esa es la apuesta.
Si quieres aprender a sacarle el máximo partido a cualquier LLM, te recomiendo nuestro curso Understanding Prompt Engineering.
Cursos de IA
programa
programa
Curso
blog
Abid Ali Awan
10 min
blog
Ryan Ong
8 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
11 min
Tutorial
Abid Ali Awan
Tutorial
Natassha Selvaraj



