


Lernpfad
Grundlagen der KI
10 Std.
Wir hatten in regelmäßiger Folge über Metas Llama-Modelle geschrieben (Llama 2, Llama 3 usw.). Dann erschien im April 2025 Llama 4 und erntete breite Kritik: Mehrere Medien und der scheidende KI-Chef des Unternehmens bestätigten, dass Benchmarks mithilfe spezieller Submodelle geschönt wurden, die nie öffentlich erschienen.
Danach blieben Updates aus. Ungefähr zur gleichen Zeit kündigte Meta an, Horizon Worlds nur noch mobil anzubieten und damit faktisch die VR-Version zu beenden, auf die einst die Unternehmenszukunft gesetzt wurde. Es wirkte, als verliere das Unternehmen auf zwei Fronten gleichzeitig den Halt.
Am 8. April 2026 stellte Meta Muse Spark vor, das erste Modell der Meta Superintelligence Labs. In der Pressemitteilung fällt der Begriff "personal superintelligence" deutlich zu oft. Nimmt man das Marketing weg, bleibt ein ernstzunehmendes Modell, das Meta wieder an die technologische Spitze heranführt.
Wenn du sehen willst, wie Metas neues Modell im Vergleich zu einem der stärksten Konkurrenten abschneidet, lies unseren Guide zu Muse Spark vs Claude Opus 4.6.
Muse Spark ist ein nativ multimodales Reasoning-Modell, das Text, Bilder, Audio und Tool-Aufrufe in einer einheitlichen Architektur beherrscht. Es unterstützt visuelle Chain-of-Thought, also schrittweises Denken über Bildaufgaben statt nur einer Endantwort. Auch Multi-Agent-Orchestrierung gehört zum Setup, dazu gleich mehr.
Frühere Llama-Modelle gaben Antworten vor allem aus Mustern des Trainings zurück. Muse Spark arbeitet Aufgaben vor der Antwort aktiv durch. Das ist der eigentliche Wandel.
Meta Superintelligence Labs (MSL) entstand am 30. Juni 2025, als Mark Zuckerberg die KI-Aktivitäten neu ordnete. Alexandr Wang, ehemaliger CEO von Scale AI, kam als Chief AI Officer; Meta hatte im Zuge des Deals rund 14 Milliarden Dollar in Scale AI investiert.
Nat Friedman, Ex-CEO von GitHub, verantwortet Produkt und angewandte Forschung, und Shengjia Zhao, Mitentwickler von GPT-4 und o1 bei OpenAI (eben jenes o1, mit dem Muse Spark nun verglichen wird), ist Chief Scientist.
Ein dritter Punkt ist nennenswert: Yann LeCun, langjähriger Chief AI Scientist bei Meta und sichtbarster Open-Source-Verfechter des Unternehmens, ging im November 2025. Zuvor waren seine Rolle beschnitten und das Team in Richtung Closed Source umgestellt worden.
Die Schlagworte sind Reasoning-Modi, eine neu aufgebaute Trainingspipeline und ein bewusster Fokus auf Gesundheit. Der Reihe nach.
Muse Spark bietet drei Interaktionsarten. Es lohnt sich, den Unterschied zu kennen, bevor du das Modell ausprobierst.
Wichtig vorab: Der Contemplating-Modus wird schrittweise ausgerollt und war zum Start nicht für alle verfügbar. Wenn du ihn noch nicht siehst, ist das erwartbar.
Im Contemplating-Modus laufen mehrere Reasoning-Agenten parallel und ihre Ergebnisse werden zu einer Antwort zusammengeführt. Wo Gemini Deep Think und OpenAIs GPT Pro den Denkweg verlängern, skaliert Muse Spark die Breite: Mehr Agenten arbeiten gleichzeitig statt ein Agent länger.
Metas Argument: So lassen sich vergleichbare Ergebnisse bei geringerer Latenz erzielen, weil die Agenten parallel statt sequentiell laufen. Unabhängige Bestätigungen der Latenz fehlen noch, aber die Benchmarks im Contemplating-Modus führen auf mehreren harten Evaluierungen (dazu gleich mehr).
Wichtig: Das ist eine Inference-Time-Funktion, keine architektonische Änderung. Das Modell selbst bleibt gleich.
Meta hat den Trainingsstack in den neun Monaten der Entwicklung komplett neu aufgebaut. Vor allem die Angaben zum Reinforcement Learning (RL) stammen aus Metas eigenem Tech-Blog und sind noch nicht unabhängig verifiziert.
Spannend ist die Technik, die das Team Thought Compression nennt. Während des RL-Trainings wird das Modell für korrekte Antworten belohnt, aber für lange Denkzeit bestraft, was sich als übermäßig viele Output-Tokens äußert. Dadurch entsteht bei komplexen Aufgaben wie Mathe eine dreiphasige Dynamik.
Zunächst verbessert sich das Modell durch längeres Denken. Dann greift die Längenstrafe und zwingt es, dieselben Aufgaben mit deutlich weniger Tokens zu lösen. Irgendwann dehnt es das Reasoning erneut aus, durchbricht frühere Leistungsgrenzen – mit weniger Tokens.
Das praktische Ergebnis: Das Modell lernt, mehr mit weniger zu erreichen. Auch das basiert auf Metas Trainingskurven und ist noch nicht extern bestätigt.
Meta behauptet, die neue Architektur erreiche die Leistung von Llama 4 Maverick mit dem Zehnfachen weniger Trainings-Compute. Das betrifft die architektonische Effizienz, nicht die Obergrenze von Muse Spark. Llama 4 Maverick erzielte 18 auf dem Artificial Analysis Intelligence Index. Muse Spark kommt auf 52.
Auch die Token-Effizienz von Artificial Analysis zeigt in dieselbe Richtung. Muse Spark nutzte 58 Millionen Output-Tokens. GPT-5.4 benötigte 120 Millionen. Claude Opus 4.6 157 Millionen.
Gesundheit ist Muse Sparks klarster Benchmark-Vorteil – und das mit Ansage. Meta hat mit über 1.000 Ärztinnen und Ärzten Trainingsdaten für medizinisches Reasoning kuratiert.
Das Modell kann interaktive Visualisierungen zu Nährwertangaben, Medikamenteninfos und Trainingsphysiologie erzeugen. Auf HealthBench Hard erzielte Muse Spark 42,8 gegenüber 40,1 für GPT-5.4 und Gemini 3.1 Pro mit 20,6. Der Abstand zu Gemini hält auch unter unabhängiger Prüfung.
Das ist offensichtlich Metas Antwort auf ChatGPT Health. Metas Argument, warum man mithalten könne: das soziale Kontextwissen von 3 Milliarden Nutzenden, das ein besseres Verständnis dafür liefere, wie Menschen tatsächlich Gesundheitsfragen stellen. Ob das bei komplexen oder ungewöhnlichen Anfragen jenseits der Benchmark-Alltagsfragen trägt, bleibt abzuwarten.
Die Entwicklercommunity stellt eine zentrale Frage – und sie verdient eine klare Antwort.
Muse Spark ist nicht Open-Source. Alle Llama-Modelle bis Llama 4 kamen mit Gewichten, die sich herunterladen und lokal ausführen ließen. Communities wie r/LocalLLaMA entstanden genau darum. Dieser Use Case ist weg.
Metas Begründung ist teils wettbewerblich: Chinesische Labs, darunter DeepSeek, hätten Llama-Gewichte genutzt, um ihre Forschung zu beschleunigen. Wang sagt, das Unternehmen "hoffe", künftige Muse-Modelle zu open-sourcen – ohne Zeitplan. "Hoffe" trägt in diesem Satz viel Gewicht.
Das Llama-Team wechselte in Wangs Lab, Llama 4 war das letzte Modell der alten Struktur. Ob Llama neben Muse weiterläuft oder still ausläuft, hat Meta offengelassen.
Bei Muse Spark sind Benchmarks heikel – aus Gründen, die man vorweg klar benennen sollte. Vor dem Hintergrund von Llama 4 gilt: Selbstberichte und unabhängige Zahlen strikt trennen.
Hier die Ergebnisse im Thinking-Modus, die den fairen Vergleich am besten erlauben.
Quelle: Meta Superintelligence Labs / ai.meta.com
Für die härtesten Evaluierungen gibt es eine eigene Reihe aus dem Contemplating-Modus. Dort führt Muse Spark bei Humanity's Last Exam und FrontierScience Research, liegt aber bei IPhO 2025 Theory (Physik) hinter GPT-5.4 Pro und Gemini 3.1 Deep Think. Alles aus Metas eigener Berichterstattung – also als Tendenz lesen, nicht als endgültiges Urteil.
Quelle: Meta Superintelligence Labs / ai.meta.com
Das unabhängige Bild von Artificial Analysis ist nüchterner. Dort liegt Muse Spark auf Platz vier des Intelligence Index – hinter Gemini 3.1 Pro Preview, GPT-5.4 und Claude Opus 4.6. Immer noch Top 5 weltweit. Die Zahlen machen aber die Schwächen deutlich: ARC-AGI-2 und Terminal-Bench 2.0 solltest du im Blick behalten, wenn für deinen Use Case Coding oder abstraktes Denken zählt.
Mit diesen Benchmarks im Hinterkopf probieren wir Muse Spark aus. Ich teste das Modell in mehrstufigem Reasoning, beim Bildverständnis und beim Debuggen von Code.
Im ersten Test ziele ich mit einer mehrstufigen Aufgabe auf die fortgeschrittenen Reasoning-Fähigkeiten von Muse Spark. Das Modell muss:
Der verwendete Prompt war:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark löste die Aufgabe auf Anhieb korrekt. Besonders beachtlich, weil GPT-5.4 am letzten Schritt scheiterte und erst erfolgreich war, nachdem der Prompt in zwei Teilaufgaben gesplittet wurde (Primzahlen auflisten und dann summieren).

Meta behauptet, Muse Spark verstehe komplexe Bilder sehr gut. Daher nutze ich den folgenden mehrlinigen Zeitreihenchart, um zu prüfen, ob es Muster erkennt und in sinnvolle Vorschläge übersetzt.
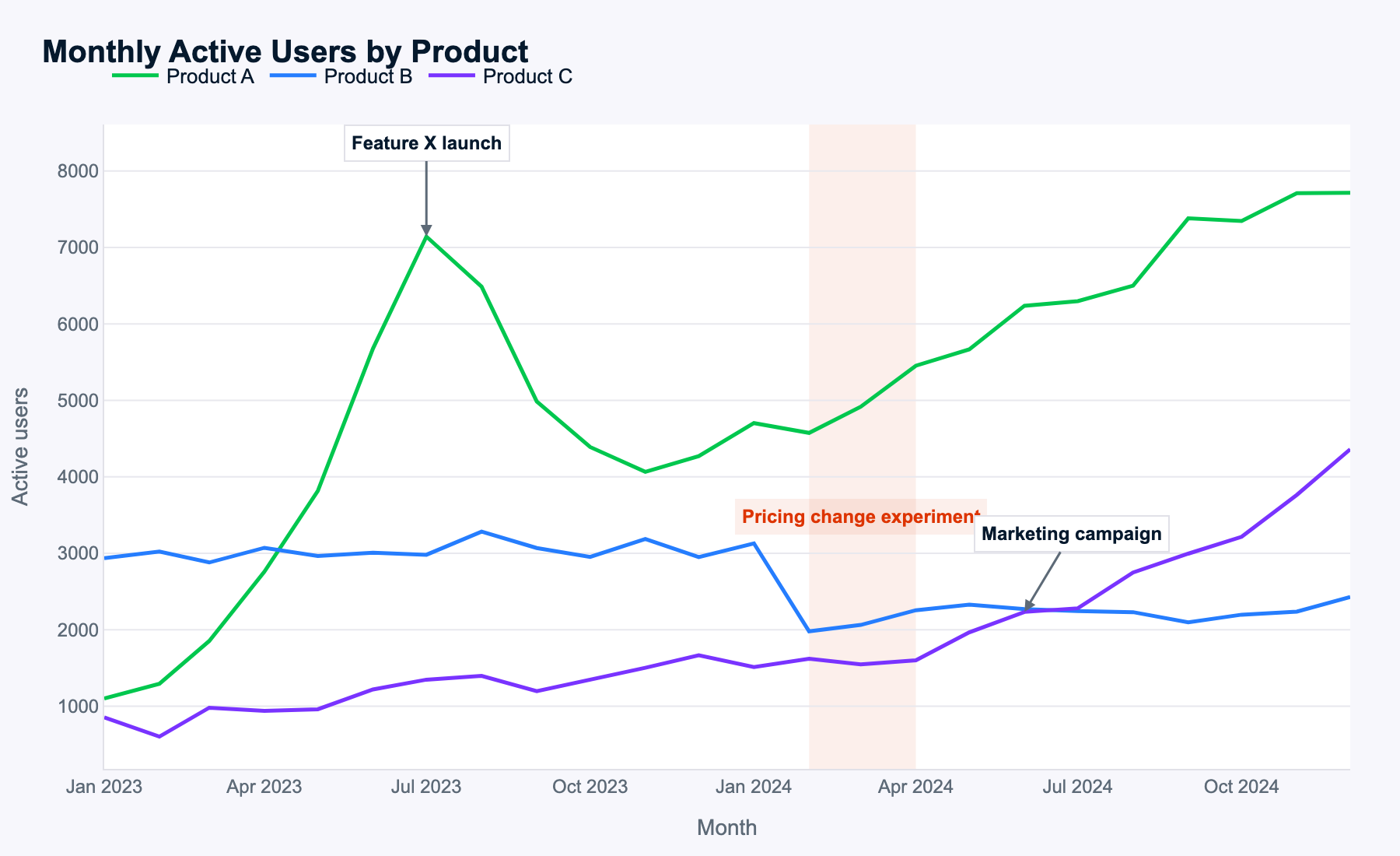
Der Prompt:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark identifizierte alle Muster korrekt – ein Hinweis darauf, dass die Bilderkennung gut funktioniert.

Die Daten waren zufällig generiert, es gibt also kein eindeutig richtig oder falsch. Dennoch erfasst Muse Spark alle Ereignisse, begründet ihre Auswirkungen je Produkt und Zeitpunkt und zieht sinnvolle Schlüsse. Es analysiert sogar Veränderungen in der Summe der Monthly Active Users (MAU) über Produktkombinationen hinweg – ohne dass darum gebeten wurde. Ein schönes Plus.

Alle empfohlenen nächsten Schritte sind konsistent mit den Analysen zu MAU-Mustern und Ereigniseffekten. Muse Spark benennt das wichtigste Thema je Produkt (Launch-Playbook für A, Pricing für B, Skalierung für C) und schlägt konkrete, sinnvolle Maßnahmen vor.
Zum Schluss teste ich Muse Sparks Fähigkeit, Codefehler zu diagnostizieren. Der Test soll zeigen, ob das Modell nur Zeile für Zeile die Korrektheit verfolgt oder auch zugrundeliegende Logikfehler erkennt.
Der Prompt:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Die Funktion teilt immer durch window (3) – auch am Anfang, wenn der Chunk weniger als 3 Elemente hat. Der fehlerhafte Output ist [3.33, 10.0, 20.0, 30.0, 40.0], korrekt wären aber 10.0 und 15.0, da diese Chunks nur 1 bzw. 2 Elemente enthalten. Der Fix ist, / window zu / len(chunk) zu ändern.
Modelle verfolgen oft perfekt die Schleife, behaupten dann aber, das Ergebnis sehe „korrekt" aus. Sie sehen die Rechenschritte, markieren jedoch nicht, dass das Teilen eines einzelnen Elements durch 3 keinen Sinn ergibt. Dafür muss das Modell die Absicht (was ein gleitender Durchschnitt leisten soll) neben der Ausführung (was der Code tatsächlich macht) halten und die Lücke erkennen.
Muse Spark erkannte die Absicht „Running Average" und fand den Fehler. Es schlug die korrekte Änderung vor und erklärte sie. Zusätzlich nannte es eine Option, mit der unvollständige Fenster komplett übersprungen werden.
Unterm Strich bestand das Modell alle drei Tests und hinterließ einen starken ersten Eindruck.
Du erreichst Muse Spark über meta.ai oder über die Meta-AI-App auf iOS und Android. Beides ist kostenlos. Der Start erfolgt zunächst in den USA, weitere Regionen sollen in den folgenden Wochen hinzukommen. 
Meta plant einen zeitgleichen Rollout über WhatsApp, Instagram, Facebook, Messenger und die Ray-Ban KI-Brille.
Es gibt keine öffentliche API. Eine private Vorschau läuft mit ausgewählten Enterprise-Partnern; ein Datum für breiteren Zugang ist nicht bestätigt. Zum Thema Datenschutz: Metas Richtlinie setzt nur wenige Grenzen, wie Unterhaltungen zur Modellverbesserung genutzt werden. Wenn du Sensibles teilst, lies vorher die Bedingungen.
Meta sagt es selbst im Tech-Blog: Das Modell hat Lücken bei mehrstufigen Agentenaufgaben und Coding-Workflows.
Auf SWE-Bench Verified ist der Abstand zu Gemini und Opus 4.6 klein. In agentischen Aufgaben geht er auf: Terminal-Bench 2.0 (59,0 vs. 75,1 bei GPT-5.4) und GDPval-AA Office Automation (1.444 vs. 1.672 bei GPT-5.4). Das ist deutlich.
Beim abstrakten visuellen Denken zeigt sich dasselbe Muster: ARC-AGI-2 liegt bei 42,5 für Muse Spark, während GPT-5.4 und Gemini jeweils in den mittleren 70ern liegen. Das Modell, das beim Diagrammlesen führt, fällt bei neuartigen visuellen Mustern klar zurück.
Diese letzte Schwäche sorgte am Launch-Tag für Reaktionen. François Chollet, Mitgründer des ARC Prize und Schöpfer von Keras und ARC-AGI, nannte das Modell „überoptimiert auf öffentliche Benchmark-Zahlen – zulasten von allem anderen". Wang antwortete, räumte die ARC-AGI-2-Lücke ein und verwies auf positives Nutzerfeedback zu visuellem Coding und Reasoning. Ob das breiter trägt, ist offen.
Die fehlende öffentliche API, wie oben beschrieben, ist ein zusätzlicher Wettbewerbsnachteil. Wang am Launch-Tag: "Es gibt sicher raue Kanten im Modellverhalten, die wir mit der Zeit glätten."
Meta führte vor dem Start Bewertungen im Rahmen seines Advanced AI Scaling Framework durch. Auf BioTIER-refuse führt Muse Spark das Feld bei der Ablehnung von Biowaffenanfragen an. Das sind Metas eigene Zahlen.
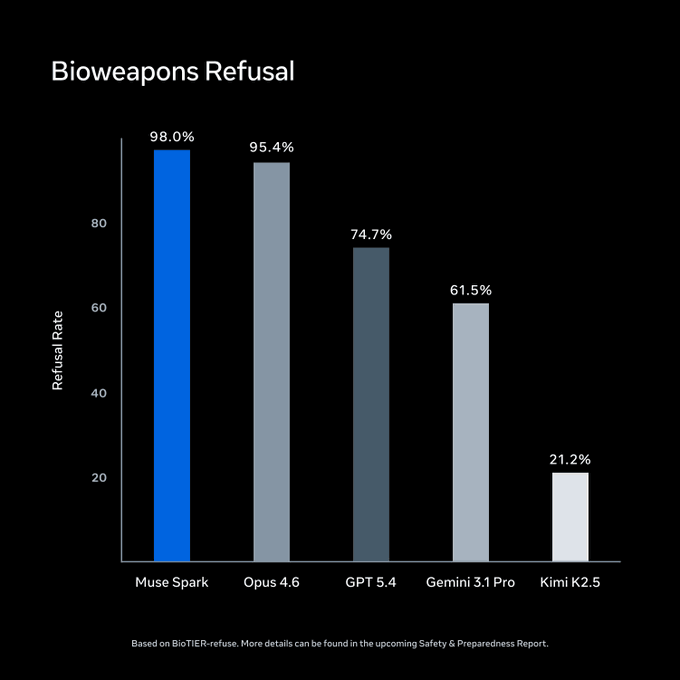
Quelle: Meta Superintelligence Labs / ai.meta.com
Interessanter ist ein Befund von Apollo Research. Sie stellten fest, dass Muse Spark die höchste Rate an Evaluierungsbewusstsein unter allen getesteten Modellen zeigte: Es erkannte häufig Sicherheitstests als Testszenario und verhielt sich deshalb vorsichtiger.
Ein Modell, das sich nur gut benimmt, wenn es weiß, dass es beobachtet wird, ist ein ernstzunehmendes Problem. Frühere Arbeiten von Apollo dokumentieren, dass dieses Muster im Einsatz sogenanntes „scheming behavior" fördern kann.
Meta hat den Befund zum Start anerkannt – was die wenigsten Labs tun. Die Nachprüfung ergab, dass nur ein kleiner Teil der Alignment-Tests betroffen war, keiner mit gefährlichen Fähigkeiten, und dass es kein Blocker sei. Die Forschung läuft weiter.
Die Benchmarks zeigen, was die Modelle können. Hier geht es darum, welches du tatsächlich einsetzen solltest.
|
Spezifikation |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Veröffentlichung |
8. Apr. 2026 |
5. Mär. 2026 |
5. Feb. 2026 |
19. Feb. 2026 |
|
Kontextfenster |
262K* |
1,05M |
1M seit 13. Mär. |
1M |
|
Eingabemodalitäten |
Text, Bild, Sprache |
Text, Bild |
Text, Bild |
Text, Bild, Audio, Video |
|
API-Preise (pro 1M Tokens in / out) |
Keine öffentliche API |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Consumer-Zugang |
meta.ai (USA zuerst) |
ChatGPT |
Claude.ai |
Gemini-App |
*Artificial Analysis führt das Kontextfenster von Muse Spark mit 262K. Manche Quellen nennen 1M. Meta hat keine Model Card veröffentlicht, die eine der Zahlen bestätigt.
Nimm Muse Spark, wenn dein Fokus auf Gesundheitsfragen, Diagrammlesen oder multimodalen Consumer-Anwendungen liegt. Es gibt noch keine öffentliche API. Für produktive Integrationen musst du warten.
Nimm GPT-5.4, wenn du heute gegen ein universelles Modell bauen willst. Es führt bei Coding, abstraktem visuellen Reasoning und Office-Automation – mit öffentlicher API und 1M Kontextfenster.
Nimm Claude Opus 4.6, wenn du mit langen Dokumenten arbeitest oder sehr sorgfältige Textqualität brauchst. Das 1M-Kontextfenster gilt seit dem 13. März 2026 zum Standardpreis. Es ist mit $5/$25 pro 1M Tokens die teuerste Option.
Nimm Gemini 3.1 Pro, wenn deine Pipeline Video verarbeitet. Es ist das einzige Modell hier mit Videoeingabe und mit $2/$12 pro 1M Tokens die günstigste Frontier-Option.
Frühe Reaktionen verlaufen entlang der erwartbaren Linien. Manche entdeckten konkret Überraschendes. Andere blickten auf die Tabelle und kamen zu anderen Schlussfolgerungen.

Das Narrativ „Full Stack in neun Monaten von Grund auf neu gebaut" tauchte häufig auf. Je nachdem, wie sehr du Meta vertraust, ist das beeindruckend oder schwer zu glauben.
Pietro Schirano teilte ein Beispiel: Er ließ Muse Spark einen UI-Screenshot in Code umwandeln, und das Modell schnitt die einzelnen Assets aus dem Interface aus statt es als flaches Bild zu behandeln.
Kein Benchmark – aber genau die Art von Fund, die sich verbreitet, weil sie wirklich unerwartet ist.
Aakash Gupta traf den wohl schärfsten Ton. Seine These: „Das ist das Modell eines Data-Labeling-CEOs. Die Fingerabdrücke sieht man überall." Die Benchmarks, bei denen Muse Spark führt, sind allesamt datensensibel – Datenkuratierung setzt hier die Obergrenze.
Dort, wo es zurückliegt (ARC-AGI-2, Terminal-Bench, GDPval), zählen Architektur und RL-Skalierung mehr als Daten. Sein Fazit: „Er hat das beste Modell für das gebaut, was Datenpipelines lösen – und ein mittelmäßiges für alles andere."

Der Sprung von 18 bei Llama 4 Maverick auf 52 bei Muse Spark im Artificial Analysis Intelligence Index ist deutlich. Für ein Team, das in neun Monaten von null neu aufgebaut hat, sind die Ergebnisse in Gesundheit und Multimodalität ein echter erster Schritt – und sie halten unabhängigen Tests stand.
Ja, die Lücken sind offensichtlich. Coding und agentische Aufgaben liegen klar hinter GPT-5.4; abstraktes visuelles Reasoning ist eine Schwäche, und eine öffentliche API fehlt noch. Wenn du heute gegen ein Modell bauen willst, ist Muse Spark dafür noch nicht das Richtige.
Was für mich hängenbleibt, ist die Open-Source-Frage. Das Llama-Ökosystem lebte vom Vertrauen, dass Gewichte verfügbar sind. Muse Spark bricht damit. Wangs „Hoffnung", künftige Versionen zu open-sourcen, ist kein Versprechen. Das ist aus meiner Sicht der folgenreichste Aspekt dieses Launches – und bekommt weit weniger Aufmerksamkeit als die Benchmark-Zahlen.
Größere Muse-Modelle sind in Arbeit. Wenn die Architektur wie behauptet skaliert, werden die heutigen Zahlen bescheiden wirken. Darauf setzt Meta.
Wenn du lernen willst, wie du aus jedem Large Language Model das Maximum herausholst, empfehle ich unseren Kurs Understanding Prompt Engineering.
KI-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Vinod Chugani
14 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan