
Cursus
Ingénieur IA associé pour les scientifiques de données
40 h
MiniMax M2.7 se distingue de nombreux modèles open-weight car il est conçu pour des workflows agentiques complexes, incluant l’usage d’outils, des tâches de codage en plusieurs étapes et un raisonnement orienté productivité.
Bien qu’il appartienne à la catégorie des modèles de taille intermédiaire plutôt qu’aux très grands modèles, MiniMax M2.7 vise une solide performance en codage et en raisonnement, tout en restant bien plus simple à déployer en pratique.
Dans ce guide, j’utilise Hyperbolic, qui offre l’accès H200 à la demande le moins cher, un provisionnement rapide et un moyen simple de lancer des machines Linux avec GPU pour servir des modèles comme en local.
Vous apprendrez à :
Lancer une machine Linux H200 sur Hyperbolic
Installer llama.cpp pour l’inférence locale
Télécharger la version UD-IQ4_XS GGUF de MiniMax M2.7 d’Unsloth
Exécuter llama-server comme API locale compatible OpenAI
Connecter le modèle local à OpenCode pour des workflows de codage agentiques
MiniMax M2.7 adopte une approche plus centrée agent que les modèles ouverts précédents, comme MiniMax M2.5. Ce qui le démarque, ce n’est pas seulement ses capacités de codage ou de raisonnement, mais le fait qu’il soit conçu pour contribuer à son propre processus d’amélioration.
Selon MiniMax, M2.7 est leur premier modèle à contribuer en profondeur à sa propre évolution en aidant à construire des harnais d’agents complexes, en gérant des tâches de productivité élaborées et en collaborant avec des équipes d’agents, des compétences avancées et une recherche dynamique d’outils.
Un changement majeur avec M2.7 est son workflow d’auto‑évolution. Durant le développement, le modèle a été utilisé pour mettre à jour sa propre mémoire, créer des compétences complexes pour des expériences d’apprentissage par renforcement, et affiner son propre apprentissage en fonction des résultats de ces expériences.
Tout cela fait de M2.7 moins un modèle statique classique qu’un système pensé pour l’amélioration itérative.
Source : MiniMaxAI/MiniMax-M2.7 · Hugging Face
Ce que je trouve le plus intéressant, c’est que MiniMax positionne M2.7 comme bien plus qu’un énième modèle ouvert. À mes yeux, il annonce une façon plus durable d’améliorer et d’entraîner des modèles, où des systèmes avancés peuvent jouer un rôle plus actif dans leur propre développement.
Plutôt que de s’appuyer uniquement sur d’immenses jeux de données frais, il montre comment de nouvelles méthodes d’entraînement et des boucles d’auto‑amélioration peuvent encore faire progresser les performances.
Allez sur Hyperbolic, créez un compte, et ajoutez au moins 5 $ de crédit avec votre carte. Rendez‑vous ensuite dans l’onglet GPUs, cliquez sur Launch Instance et sélectionnez la machine H200 SXM5.
Ce guide utilise un serveur GPU distant. Avant de lancer la machine, vérifiez que votre accès SSH est prêt. SSH vous permet de vous connecter en toute sécurité depuis votre terminal à la machine Linux exécutée sur Hyperbolic.
Si vous utilisez déjà SSH et disposez d’une paire de clés, passez à la suite. Sinon, vous devrez d’abord en créer une.
Sur votre machine locale, ouvrez un terminal et générez une clé SSH si vous n’en avez pas déjà une :
ssh-keygenLorsque vous y êtes invité, appuyez sur Entrée pour l’enregistrer à l’emplacement par défaut. Vous pouvez aussi ajouter une phrase secrète pour plus de sécurité, mais c’est facultatif.
Une fois la clé créée, affichez votre clé publique pour pouvoir la copier :
cat ~/.ssh/id_rsa.pubSi votre système utilise le format Ed25519, exécutez :
cat ~/.ssh/id_ed25519.pubCopiez l’intégralité de la sortie et ajoutez‑la à votre compte Hyperbolic. Assurez‑vous de ne téléverser que la clé publique. La clé privée reste sur votre ordinateur et ne doit jamais être partagée.
Une fois votre clé SSH ajoutée, allez sur le tableau de bord Hyperbolic, ouvrez l’onglet GPUs et cliquez sur Launch Instance. Dans la liste des machines disponibles, choisissez l’instance H200 SXM5 pour cette configuration.
Avant de démarrer la machine, donnez à l’instance un nom clair et reconnaissable. Vous la retrouverez ainsi plus facilement, surtout si vous lancez plusieurs machines ou si vous y revenez plus tard.
Ensuite, vérifiez les paramètres de l’instance, confirmez que votre clé SSH est bien attachée et démarrez la machine. La plateforme va alors provisionner le serveur GPU pour vous.
Une fois la machine prête, elle apparaît en actif dans le tableau de bord. Vous verrez alors aussi la commande SSH à utiliser pour vous y connecter depuis votre terminal local. Vous vous en servirez à l’étape suivante.
Ouvrez maintenant votre terminal local et lancez la commande SSH avec le transfert de port activé dès le départ :
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Cette commande connecte votre machine locale au serveur Linux distant et transfère aussi le port 8001, afin que vous puissiez ensuite accéder au serveur llama.cpp dans votre navigateur via http://127.0.0.1:8001.
Si c’est votre première connexion au serveur, SSH vous demandera de confirmer l’empreinte. Tapez yes et appuyez sur Entrée.
Si vous avez défini une phrase secrète lors de la création de votre clé SSH, SSH vous la demandera avant d’établir la connexion. Saisissez‑la puis appuyez sur Entrée. L’usage d’une phrase secrète est recommandé car elle ajoute une couche de protection à votre clé privée.
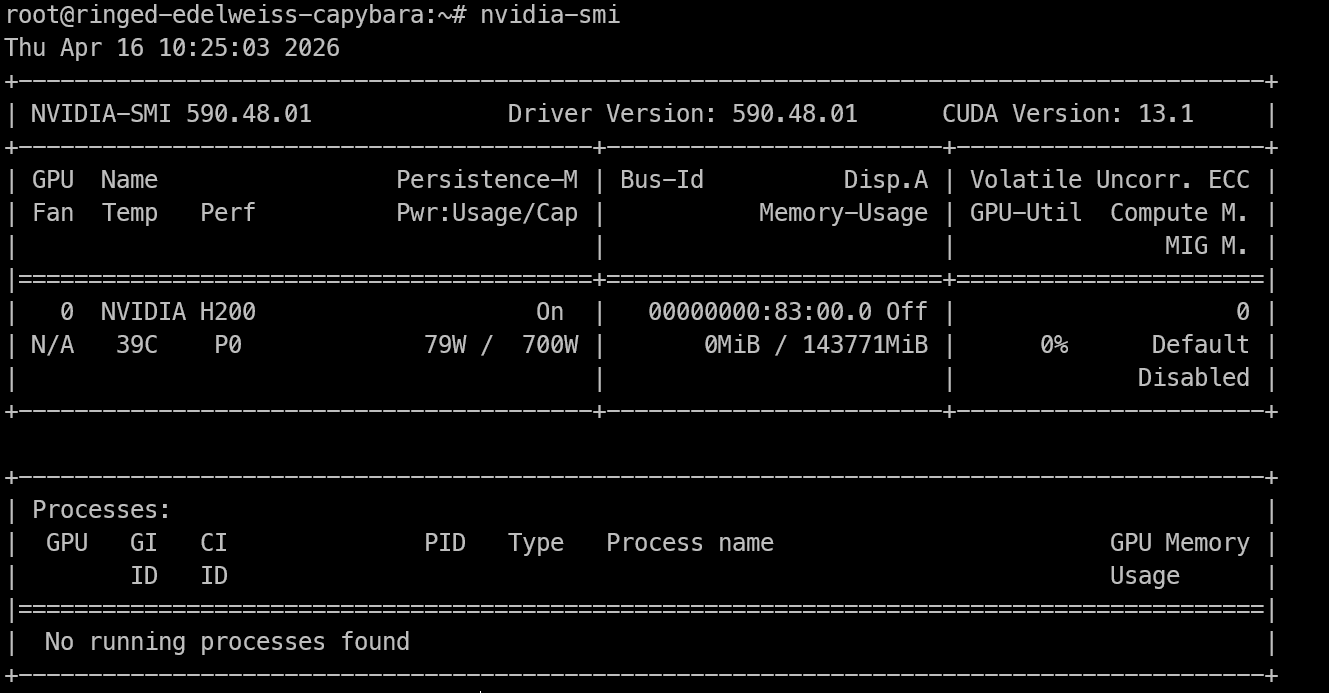
Une fois l’accès à la machine H200 établi, vérifiez d’abord que le GPU est visible et que les pilotes NVIDIA fonctionnent correctement.
Exécutez :
nvidia-smiLa commande doit afficher le GPU NVIDIA installé, la version du pilote, la version de CUDA et la mémoire disponible. Si vous voyez le H200 listé, la machine est prête pour l’inférence.
Installez maintenant les paquets système requis pour compiler llama.cpp et exécuter le modèle en local.
Exécutez :
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipCes paquets fournissent les outils nécessaires pour la suite :
build-essential et cmake sont requis pour compiler llama.cpp
git permet de cloner le dépôt
curl et wget facilitent le téléchargement de fichiers
tmux est utile pour garder des processus longue durée actifs même après la fermeture du terminal.
Maintenant que la machine est prête, installez llama.cpp, que nous utiliserons pour exécuter MiniMax M2.7 en local. Vous obtiendrez à la fois les outils en ligne de commande pour tester le modèle et le serveur que nous exposerons ensuite via une API compatible OpenAI.
Commencez par cloner le dépôt officiel llama.cpp sur la machine distante :
git clone https://github.com/ggml-org/llama.cppCela crée un dossier llama.cpp dans votre répertoire courant avec tous les fichiers sources nécessaires.
Exécutez ensuite CMake pour configurer la build. Ici, nous activons CUDA afin que llama.cpp utilise le GPU H200 pour l’inférence.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONCette commande prépare les fichiers de build dans le répertoire llama.cpp/build.
Compilez maintenant les outils nécessaires :
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitCela construit trois binaires principaux :
llama-cli pour tester et exécuter le modèle depuis le terminal
llama-server pour servir le modèle via une API locale et une interface navigateur
llama-gguf-split pour travailler avec des fichiers de modèle GGUF segmentés
Copier les binaires dans le dossier principal
Une fois la compilation terminée, copiez les binaires dans le dossier principal llama.cpp :
cp llama.cpp/build/bin/llama-* llama.cppCela facilite l’exécution des outils sans devoir saisir le chemin de build complet à chaque fois.
Enfin, exécutez les commandes d’aide ci‑dessous pour vous assurer que tout est correctement installé :
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpSi les deux commandes renvoient les informations d’usage sans erreur, llama.cpp est installé avec succès et vous pouvez télécharger le modèle MiniMax M2.7.
Avant de télécharger le modèle, installez les outils de téléchargement Hugging Face sur la machine distante :
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferCela installe le CLI hf ainsi que hf-xet, qui améliore la gestion des gros téléchargements.
Créez ensuite un dossier pour les fichiers du modèle et téléchargez la version GGUF UD-IQ4_XS de MiniMax M2.7.
Exécutez :
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Cette commande crée un répertoire dédié au modèle et ne télécharge que les fichiers UD-IQ4_XS, la quantification 4 bits utilisée dans ce guide.
Le téléchargement est volumineux, environ 108 Go, il peut donc prendre du temps selon le réseau de votre instance.
Une fois le téléchargement terminé, vérifiez que tous les shards GGUF sont présents en exécutant :
find /models/minimax-m27 -name "*.gguf"Vous devriez voir quatre fichiers GGUF listés, comme ceci :
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufSi les quatre fichiers sont là, le modèle a été correctement téléchargé et vous pouvez démarrer le serveur à l’étape suivante.
Il est temps de lancer le modèle avec llama-server. Cela chargera le modèle GGUF MiniMax M2.7, l’exécutera sur le GPU et l’exposera via un serveur local sur le port 8001.
Avant de lancer le serveur du modèle, démarrez une session tmux afin que le processus continue de tourner si votre connexion SSH tombe ou si vous fermez le terminal.
Exécutez :
tmux new -s minimaxCela crée une session tmux nommée minimax, que nous utiliserons pour exécuter le serveur.
Placez‑vous maintenant dans le répertoire llama.cpp et lancez le serveur avec le chemin du modèle et les paramètres d’inférence :
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Le serveur démarre sur le port 8001 et charge le modèle. Surveillez les logs dans le terminal au chargement.

Si le modèle se charge correctement en mémoire GPU, un message indiquera que le serveur écoute sur l’adresse et le port configurés.
Une fois le modèle chargé, laissez‑le tourner dans tmux et détachez‑vous de la session sans l’arrêter.
Appuyez sur Ctrl+B puis D. Vous revenez ainsi au terminal normal, tandis que le serveur reste actif en arrière‑plan.
Pour revoir les logs plus tard, rattachez‑vous à la session avec :
tmux attach -t minimaxAprès le démarrage du serveur, ouvrez une autre session terminal et exécutez :
curl http://127.0.0.1:8001/v1/modelsVous devriez obtenir une sortie de ce type :
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Si vous voyez le modèle MiniMax-M2.7 listé, le serveur fonctionne correctement.
Comme vous avez démarré SSH avec un transfert de port sur 8001, vous pouvez maintenant ouvrir la WebUI de llama.cpp directement dans votre navigateur en allant sur http://127.0.0.1:8001.
Vous accédez ainsi à l’interface du modèle depuis votre navigateur local.
À ce stade, le modèle est prêt à l’emploi. Testez‑le dans la WebUI ou via des requêtes API depuis le terminal pour vérifier que tout fonctionne.
Dans ma configuration, MiniMax M2.7 répondait extrêmement vite, autour de 120 tokens par seconde. Honnêtement, c’est le modèle local de cette taille le plus rapide que j’aie exécuté jusqu’ici, notamment grâce à sa réactivité même sur des invites longues et techniques.
Une fois les réponses correctes obtenues, MiniMax M2.7 tourne entièrement en local et peut être intégré à votre workflow de développement.
Maintenant que le serveur local llama.cpp est en marche, l’étape suivante consiste à le connecter à OpenCode. OpenCode est un agent de codage en terminal qui prend en charge des fournisseurs personnalisés via son fichier de configuration. Pour en savoir plus, consultez notre comparatif OpenCode vs Claude Code.
Pour les modèles locaux comme llama.cpp, l’approche la plus propre consiste à pointer OpenCode vers l’endpoint local compatible OpenAI sur http://127.0.0.1:8001/v1.
Installez OpenCode sur la machine distante avec :
curl -fsSL https://opencode.ai/install | bash
Rechargez ensuite votre shell et vérifiez la version pour confirmer l’installation :
source ~/.bashrc
opencode --version1.4.6Créez ensuite un fichier opencode.json indiquant à OpenCode d’utiliser votre serveur local llama.cpp en tant que fournisseur compatible OpenAI.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFCette configuration oriente OpenCode vers le serveur local, définit le modèle par défaut sur MiniMax-M2.7 et reprend l’approche fournisseur compatible OpenAI décrite par OpenCode pour les providers personnalisés. OpenCode permet aussi de sélectionner les modèles dans l’application avec la commande /models.
Créez maintenant un dossier de projet simple et lancez OpenCode à l’intérieur :
mkdir ml-app
cd ml-app/
OpencodeUne fois OpenCode ouvert, tapez /models et sélectionnez MiniMax-M2.7 sous votre fournisseur local.
Une fois le modèle sélectionné, proposez‑lui une vraie consigne de développement. Par exemple :
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.En pratique, c’est là que la configuration impressionne. Le modèle se met au travail presque immédiatement, crée un plan d’actions et commence à générer les fichiers. Lors de mes tests, il m’a semblé très réactif, en phase avec la vitesse observée via llama.cpp.
Au final, il a pu créer les fichiers, exécuter les tests et afficher les résultats.
Ensuite, vous pouvez aller plus loin : tester les endpoints de l’API ML, améliorer l’architecture de l’app ou ajouter des fonctionnalités. Comme OpenCode est conçu pour des workflows de codage en terminal, c’est à ce moment que la configuration locale de MiniMax prend l’allure d’un agent de développement opérationnel, et pas seulement d’un modèle tournant sur un serveur.
Dans mon cas, l’app d’API ML locale fonctionnait correctement à la fin de l’exécution. Nous avons lancé des tests unitaires, réalisé des smoke tests et vérifié l’absence d’erreurs pendant l’exécution et les tests du code. Au total, cela a pris environ 2 minutes, ce qui illustre la rapidité du modèle dans un workflow de développement local.
Au départ, j’avais commencé avec vLLM, mais j’ai rencontré plusieurs problèmes, notamment en tentant d’exécuter un modèle AWQ 4 bits. Pour ce type de configuration, j’ai trouvé llama.cpp bien plus simple à utiliser. L’installation est plus fluide, le workflow plus direct, et l’ensemble a fonctionné bien plus rapidement.
J’ai aussi apprécié que llama.cpp propose une WebUI intégrée, pour tester le modèle immédiatement dans une interface proche de ChatGPT depuis le navigateur. On peut ainsi valider rapidement des prompts, tester les réponses et s’assurer que tout fonctionne avant de le connecter à un outil comme OpenCode.
Pour un usage local, je pense que MiniMax M2.7 est l’un des meilleurs modèles que j’aie exécutés à ce jour. Il est plus petit que GLM 5.1, il paraît plus rapide, comprend bien le code et est performant sur des tâches de codage agentiques. Même la version 4 bits s’en est très bien sortie sur des tâches plus complexes, ce qui la rend pertinente pour un usage réel et pas seulement pour de l’expérimentation.
La vitesse joue un rôle clé dans l’intérêt de cette configuration. Dans mon cas, MiniMax M2.7 tournait autour de 120 tokens par seconde avec une génération très fluide et, grâce au transfert de port SSH, je pouvais l’utiliser depuis mon navigateur ou mon API locaux comme s’il tournait sur ma propre machine. L’ensemble du workflow s’en trouve rapide, simple et très pratique.
Cours d’ingénierie de l’IA
Cursus
Cursus
Cours
blog
Kurtis Pykes
9 min
blog
Vinod Chugani
14 min
blog
Zoumana Keita
15 min
Tutoriel
Tutoriel
Stephen Gruppetta
Tutoriel
Mark Pedigo
