
programa
Ingeniero Asociado de IA para Científicos de Datos
40 h
MiniMax M2.7 destaca frente a muchos modelos de pesos abiertos porque está diseñado para flujos de trabajo agentivos complejos, incluido el uso de herramientas, tareas de programación en varios pasos y razonamiento orientado a la productividad.
Aunque pertenece a la gama de tamaño medio y no al segmento de modelos más grandes, MiniMax M2.7 está orientado a ofrecer un gran rendimiento en programación y razonamiento con una huella de despliegue mucho más práctica.
En esta guía usaré Hyperbolic porque ofrece el acceso H200 bajo demanda más barato, aprovisionamiento rápido y una forma sencilla de lanzar máquinas Linux con GPU para servir modelos como si fueran locales.
Aprenderás a:
Lanzar una máquina Linux H200 en Hyperbolic
Instalar llama.cpp para inferencia en local
Descargar la versión UD-IQ4_XS GGUF de MiniMax M2.7 de Unsloth
Ejecutar llama-server como una API local compatible con OpenAI
Conectar el modelo local a OpenCode para flujos de trabajo de programación con agentes
MiniMax M2.7 introduce un enfoque más centrado en agentes que modelos abiertos anteriores, como MiniMax M2.5. Lo que lo hace diferente no es solo su capacidad de programación o razonamiento, sino el hecho de que está diseñado para participar en su propio proceso de mejora.
Según MiniMax, M2.7 es su primer modelo que contribuye de forma profunda a su propia evolución ayudando a construir arneses de agentes complejos, gestionando tareas de productividad elaboradas y trabajando con equipos de agentes, habilidades avanzadas y búsqueda dinámica de herramientas.
Un cambio importante con M2.7 es su flujo de autoevolución. Durante el desarrollo, el modelo se utilizó para actualizar su propia memoria, crear habilidades complejas para experimentos de aprendizaje por refuerzo y afinar su propio proceso de aprendizaje en función de los resultados de esos experimentos.
Todo esto hace que M2.7 se sienta menos como un modelo estático estándar y más como un sistema construido para mejorar de forma iterativa.
Fuente: MiniMaxAI/MiniMax-M2.7 · Hugging Face
Lo que me parece más interesante es que MiniMax posiciona M2.7 como algo más que otro modelo abierto. Para mí, apunta a una forma más sostenible de mejorar y entrenar modelos, donde los sistemas avanzados pueden desempeñar un papel más activo en su propio desarrollo.
En lugar de depender solo de conjuntos de datos nuevos y masivos, muestra cómo los métodos de entrenamiento más recientes y los bucles de auto-mejora pueden ayudar a impulsar aún más el rendimiento.
Ve a Hyperbolic, regístrate y añade al menos 5 $ de crédito con tu tarjeta. Luego ve a la pestaña GPUs, haz clic en Launch Instance y selecciona la máquina H200 SXM5.
Esta guía usa un servidor remoto con GPU, así que antes de lanzar la máquina debes asegurarte de que tu acceso SSH está listo. SSH es lo que te permite conectarte de forma segura desde tu terminal a la máquina Linux que se ejecuta en Hyperbolic.
Si ya usas SSH y tienes un par de claves configurado, puedes pasar a la siguiente parte. Si no, primero tendrás que crear uno.
En tu máquina local, abre una terminal y genera una clave SSH si aún no tienes:
ssh-keygenCuando se te pida, pulsa Intro para guardarla en la ubicación por defecto. También puedes añadir una frase de paso si quieres más seguridad, pero es opcional.
Una vez creada la clave, muestra tu clave pública para poder copiarla:
cat ~/.ssh/id_rsa.pubSi tu sistema usa el formato Ed25519, ejecuta:
cat ~/.ssh/id_ed25519.pubCopia toda la salida y añádela a tu cuenta de Hyperbolic. Asegúrate de subir solo la clave pública. La clave privada se queda en tu ordenador y nunca debe compartirse.
Cuando hayas añadido tu clave SSH, ve al panel de Hyperbolic, abre la pestaña GPUs y haz clic en Launch Instance. En la lista de máquinas disponibles, elige la instancia H200 SXM5 para esta configuración.
Antes de iniciar la máquina, ponle a la instancia un nombre claro y reconocible. Así te será mucho más fácil identificarla después, sobre todo si lanzas más de una máquina o vuelves a ella pasado un tiempo.
Después, revisa la configuración de la instancia, confirma que tu clave SSH está adjunta e inicia la máquina. La plataforma comenzará a aprovisionar el servidor con GPU para ti.
Cuando la máquina esté lista del todo, aparecerá como activa en el panel. En ese momento también verás el comando SSH que necesitas para conectarte desde tu terminal local. Usarás ese comando en el siguiente paso.
Ahora abre tu terminal local y ejecuta el comando SSH con reenvío de puertos activado desde el principio:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Esto conecta tu máquina local con el servidor Linux remoto y además reenvía el puerto 8001, para que más tarde puedas acceder al servidor de llama.cpp en tu navegador a través de http://127.0.0.1:8001.
Si es la primera vez que te conectas al servidor, SSH te pedirá confirmar la huella. Escribe yes y pulsa Intro.
Si estableciste una frase de paso al crear tu clave SSH, SSH te la pedirá antes de completar la conexión. Escribe tu frase de paso y pulsa Intro. Usar una frase de paso es recomendable porque añade una capa extra de protección a tu clave privada.
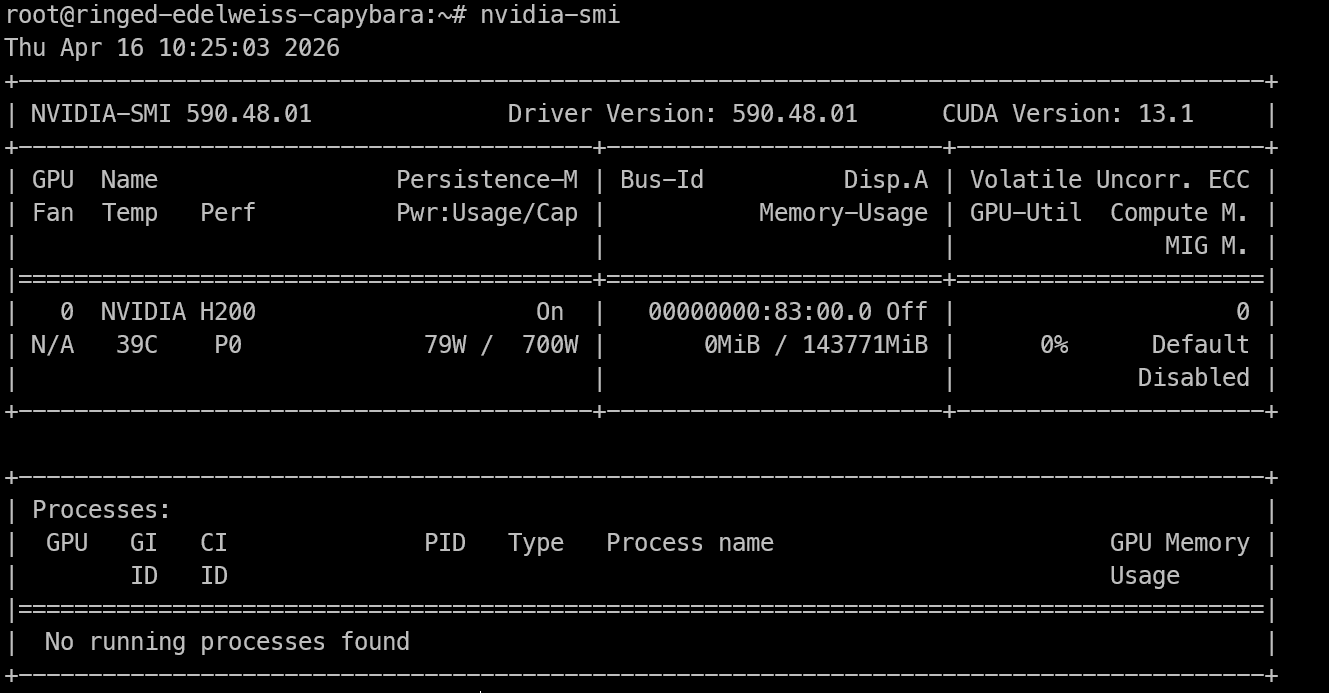
Una vez tengas acceso remoto a la H200, lo primero es comprobar que la GPU es visible y que los drivers de NVIDIA funcionan correctamente.
Ejecuta:
nvidia-smiEste comando debería mostrar la GPU NVIDIA instalada, la versión del driver, la versión de CUDA y la memoria disponible. Si ves la H200 listada aquí, la máquina está lista para inferencia.
Ahora instala los paquetes del sistema necesarios para compilar llama.cpp y ejecutar el modelo en local.
Ejecuta:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipEstos paquetes te dan las herramientas necesarias para el resto de la configuración:
build-essential y cmake son necesarios para compilar llama.cpp
git te permite clonar el repositorio
curl y wget ayudan a descargar archivos
tmux es útil si quieres mantener procesos de larga duración activos incluso tras cerrar la terminal.
Ahora que la máquina está lista, el siguiente paso es instalar llama.cpp, que usaremos para ejecutar MiniMax M2.7 en local. Esto nos da tanto las herramientas de línea de comandos para probar el modelo como el servidor que expondremos más tarde como una API compatible con OpenAI.
Empieza clonando el repositorio oficial de llama.cpp en la máquina remota:
git clone https://github.com/ggml-org/llama.cppEsto creará una carpeta llama.cpp en tu directorio actual con todos los archivos fuente necesarios para compilar el proyecto.
A continuación, ejecuta CMake para configurar la compilación. En esta configuración activamos CUDA para que llama.cpp pueda usar la GPU H200 para la inferencia.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONEste comando prepara los archivos de compilación dentro del directorio llama.cpp/build.
Ahora compila las herramientas que necesitamos:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitEsto compila tres binarios principales:
llama-cli para probar y ejecutar el modelo desde la terminal
llama-server para servir el modelo mediante una API local e interfaz en el navegador
llama-gguf-split para trabajar con archivos GGUF divididos
Copia los binarios en la carpeta principal
Cuando termine la compilación, copia los binarios en la carpeta principal de llama.cpp:
cp llama.cpp/build/bin/llama-* llama.cppAsí te resultará más fácil ejecutar las herramientas sin tener que escribir la ruta completa cada vez.
Por último, ejecuta los comandos de ayuda para asegurarte de que todo está instalado correctamente:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpSi ambos comandos devuelven información de uso en lugar de un error, llama.cpp se ha instalado correctamente y ya puedes descargar el modelo MiniMax M2.7.
Antes de descargar el modelo, instala las herramientas de descarga de Hugging Face en la máquina remota:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferEsto instala la CLI hf junto con hf-xet, que ayuda a gestionar descargas de archivos grandes de forma más eficiente.
Después, crea una carpeta para los archivos del modelo y descarga la versión GGUF UD-IQ4_XS de MiniMax M2.7.
Ejecuta:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Esto crea un directorio dedicado al modelo y descarga solo los archivos UD-IQ4_XS, que son la versión cuantizada a 4 bits usada en esta guía.
La descarga es grande, alrededor de 108 GB, así que puede tardar según la velocidad de red de tu instancia.
Cuando termine, comprueba que están todos los fragmentos GGUF ejecutando:
find /models/minimax-m27 -name "*.gguf"Deberías ver cuatro archivos GGUF listados, algo así:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufSi están los cuatro archivos, el modelo se ha descargado correctamente y ya puedes iniciar el servidor en el siguiente paso.
Ahora toca iniciar el modelo con llama-server. Esto cargará el modelo GGUF de MiniMax M2.7, lo ejecutará en la GPU y lo expondrá a través de un servidor local en el puerto 8001.
Antes de lanzar el servidor del modelo, inicia una sesión de tmux para que el proceso siga en marcha aunque se caiga tu conexión SSH o cierres la ventana.
Ejecuta:
tmux new -s minimaxEsto crea una nueva sesión tmux llamada minimax, que usaremos para ejecutar el servidor.
Ahora entra en el directorio llama.cpp y ejecuta el servidor con la ruta del modelo y los ajustes de inferencia:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Esto inicia el servidor en el puerto 8001 y carga el modelo. Mientras se carga, observa los registros en la terminal.

Si el modelo se carga correctamente en la memoria de la GPU, verás un mensaje indicando que el servidor está escuchando en la dirección y puerto configurados.
Con el modelo ya cargado, puedes dejarlo ejecutándose dentro de tmux y desacoplarte de la sesión sin pararlo.
Pulsa Ctrl+B y luego D. Volverás a tu terminal normal y el servidor del modelo seguirá activo en segundo plano.
Si más tarde quieres revisar los logs, vuelve a adjuntarte a la sesión con:
tmux attach -t minimaxTras iniciar el servidor, abre otra sesión de terminal y ejecuta:
curl http://127.0.0.1:8001/v1/modelsDeberías ver una salida como esta:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Si ves el modelo MiniMax-M2.7 listado, el servidor está funcionando correctamente.
Como ya iniciaste SSH con reenvío del puerto 8001, ahora puedes abrir la WebUI de llama.cpp directamente en tu navegador yendo a http://127.0.0.1:8001.
Esto te da acceso directo a la interfaz del modelo desde tu navegador local.
A estas alturas, el modelo debería estar listo para usar. Puedes probarlo en la WebUI o mediante peticiones API desde la terminal para asegurarte de que todo funciona bien.
En mi configuración, MiniMax M2.7 respondía muy rápido, alcanzando unos 120 tokens por segundo. Sinceramente, se sentía como el modelo local más veloz que he ejecutado de este tamaño, especialmente por lo reactivo que era incluso con prompts largos y técnicos.
Una vez que responde correctamente, MiniMax M2.7 está funcionando totalmente en local y listo para conectarse a tu flujo de trabajo de programación.
Ahora que el servidor local de llama.cpp está en marcha, el siguiente paso es conectarlo a OpenCode. OpenCode es un agente de programación basado en terminal que admite proveedores personalizados mediante su archivo de configuración. Si te interesa saber más, echa un vistazo a nuestra comparativa OpenCode vs Claude Code.
Para modelos locales como llama.cpp, la configuración más limpia es apuntar OpenCode al endpoint local compatible con OpenAI en http://127.0.0.1:8001/v1.
Instala OpenCode en la máquina remota con:
curl -fsSL https://opencode.ai/install | bash
Luego recarga tu shell y comprueba la versión para confirmar que se instaló correctamente:
source ~/.bashrc
opencode --version1.4.6A continuación, crea un archivo opencode.json que le indique a OpenCode que use tu servidor local de llama.cpp como proveedor compatible con OpenAI.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFEsta configuración apunta OpenCode al servidor local, establece el modelo por defecto como MiniMax-M2.7 y utiliza el mismo enfoque de proveedor compatible con OpenAI que documenta OpenCode para proveedores personalizados. OpenCode también permite seleccionar modelos dentro de la app con el comando /models.
Ahora crea una carpeta de proyecto sencilla y lanza OpenCode dentro:
mkdir ml-app
cd ml-app/
OpencodeCuando se abra OpenCode, escribe /models y selecciona MiniMax-M2.7 bajo tu proveedor local.
Con el modelo seleccionado, dale un prompt de programación real. Por ejemplo:
Construye una API sencilla de machine learning con FastAPI usando solo dos archivos: un archivo app.py para la API y la lógica de carga/predicción del modelo, y un archivo test_app.py para pruebas básicas de endpoints.En la práctica, aquí es donde la configuración empieza a impresionar. El modelo se pone a trabajar casi al instante, crea un plan de tareas y comienza a generar los archivos. En mis pruebas, se sintió muy reactivo, en línea con la velocidad a la que ya corría a través de llama.cpp.
Al final, fue capaz de crear los archivos, ejecutar las pruebas y mostrar los resultados.
A partir de ahí, puedes seguir exigiéndole más pidiéndole que pruebe los endpoints del API de ML, que mejore la estructura de la app o que añada nuevas funciones. Como OpenCode está pensado para flujos de trabajo de programación en terminal, este es el punto en el que la configuración local de MiniMax empieza a sentirse como un agente de código práctico y no solo como un modelo corriendo en un servidor.
En mi caso, la API de ML local funcionaba correctamente al finalizar. Ejecutamos tests unitarios, hicimos pruebas de humo y nos aseguramos de que no hubiera errores al ejecutar y probar el código. En total tardó unos 2 minutos en completar todo, lo que demuestra lo rápido que se siente este modelo en un flujo de trabajo de programación local.
Empecé originalmente con vLLM, pero me encontré con varios problemas, sobre todo al intentar ejecutar un modelo AWQ de 4 bits. Para este tipo de configuración, llama.cpp me resultó mucho más sencillo. La instalación fue más simple, el flujo más directo y todo funcionó correctamente mucho más rápido.
Otra cosa que me gustó de llama.cpp es que incluye una WebUI integrada, así que puedes probar el modelo de inmediato en una interfaz tipo ChatGPT desde el navegador. Esto facilita mucho comprobar rápidamente los prompts, probar respuestas y asegurarte de que el modelo funciona antes de conectarlo a algo como OpenCode.
Para uso local, creo que MiniMax M2.7 es de los mejores modelos que he ejecutado hasta ahora. Es más pequeño que GLM 5.1, se siente más rápido, entiende bien el código y rinde muy bien en tareas de programación con agentes. Incluso la versión de 4 bits hizo un gran trabajo en tareas más complejas, lo que la hace práctica para uso real y no solo para experimentar.
La velocidad es una parte clave de por qué esta configuración destaca. En mi caso, MiniMax M2.7 corría a unos 120 tokens por segundo con una generación muy fluida, y gracias al reenvío de puertos por SSH, podía usarlo desde mi navegador o API locales como si corriera en mi propia máquina. Todo el flujo se sintió rápido, sencillo y muy práctico.
Cursos de ingeniería de IA
programa
programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes

