
Programa
Engenheiro associado de IA para cientistas de dados
40 h
O MiniMax M2.7 se destaca de muitos modelos open-weight porque foi projetado para fluxos de trabalho agentic complexos, incluindo uso de ferramentas, tarefas de código em múltiplas etapas e raciocínio voltado à produtividade.
Embora fique na faixa de tamanho intermediário, e não no patamar dos modelos gigantes, o MiniMax M2.7 foi pensado para oferecer forte desempenho em código e raciocínio com um footprint de implantação muito mais prático.
Neste guia, vou usar a Hyperbolic porque ela oferece o acesso sob demanda mais barato a H200, provisionamento rápido e uma forma simples de subir máquinas Linux com GPU para servir modelos no estilo local.
Você vai aprender a:
Iniciar uma máquina Linux H200 na Hyperbolic
Instalar o llama.cpp para inferência local
Baixar a versão UD-IQ4_XS GGUF do MiniMax M2.7 da Unsloth
Executar o llama-server como uma API local compatível com OpenAI
Conectar o modelo local ao OpenCode para fluxos de trabalho de programação agentic
O MiniMax M2.7 traz um direcionamento mais focado em agentes do que modelos abertos anteriores, como o MiniMax M2.5. O que o diferencia não é apenas a habilidade de programar ou raciocinar, mas o fato de ter sido projetado para participar do próprio processo de melhoria.
Segundo a MiniMax, o M2.7 é o primeiro modelo deles a contribuir profundamente para sua própria evolução, ajudando a construir arneses de agentes complexos, lidando com tarefas elaboradas de produtividade e trabalhando com times de agentes, habilidades avançadas e busca dinâmica de ferramentas.
Uma grande mudança no M2.7 é o fluxo de autoevolução. Durante o desenvolvimento, o modelo foi usado para atualizar sua própria memória, criar habilidades complexas para experimentos de aprendizado por reforço e refinar seu próprio processo de aprendizagem com base nos resultados desses experimentos.
Tudo isso faz o M2.7 parecer menos um modelo estático padrão e mais um sistema criado para melhoria iterativa.
Fonte: MiniMaxAI/MiniMax-M2.7 · Hugging Face
O que acho mais interessante é que a MiniMax está posicionando o M2.7 como mais do que apenas mais um modelo aberto. Para mim, ele aponta para uma forma mais sustentável de melhorar e treinar modelos, em que sistemas avançados podem ter um papel mais ativo no próprio desenvolvimento.
Em vez de depender só de novos megadatasets, ele mostra como métodos de treinamento mais recentes e ciclos de autoaperfeiçoamento podem ajudar a impulsionar ainda mais o desempenho.
Acesse a Hyperbolic, crie sua conta e adicione pelo menos US$ 5 de crédito com seu cartão. Depois, vá até a aba GPUs, clique em Launch Instance e selecione a máquina H200 SXM5.
Este guia usa um servidor de GPU remoto, então, antes de iniciar a máquina, é importante garantir que seu acesso SSH esteja pronto. O SSH é o que permite você se conectar com segurança, a partir do seu terminal, à máquina Linux em execução na Hyperbolic.
Se você já usa SSH e tem um par de chaves configurado, pode seguir para a próxima parte. Caso contrário, será preciso criar um primeiro.
Na sua máquina local, abra um terminal e gere uma chave SSH se você ainda não tiver:
ssh-keygenQuando solicitado, pressione Enter para salvar no local padrão. Você também pode adicionar uma senha (passphrase) para mais segurança, mas é opcional.
Depois que a chave for criada, imprima sua chave pública para poder copiá-la:
cat ~/.ssh/id_rsa.pubSe seu sistema usar o formato Ed25519, rode:
cat ~/.ssh/id_ed25519.pubCopie a saída completa e adicione à sua conta na Hyperbolic. Certifique-se de enviar apenas a chave pública. A chave privada fica no seu computador e nunca deve ser compartilhada.
Depois que sua chave SSH for adicionada, vá ao dashboard da Hyperbolic, abra a aba GPUs e clique em Launch Instance. Na lista de máquinas disponíveis, escolha a instância H200 SXM5 para esta configuração.
Antes de iniciar a máquina, dê um nome claro e fácil de reconhecer à instância. Isso facilita muito identificá-la depois, especialmente se você iniciar mais de uma máquina ou voltar a ela após algum tempo.
Em seguida, revise as configurações da instância, confirme que sua chave SSH está anexada e inicie a máquina. A plataforma começará a provisionar o servidor de GPU para você.
Quando a máquina estiver totalmente pronta, ela aparecerá como ativa no dashboard. Nesse momento, você também verá o comando SSH necessário para se conectar a partir do seu terminal local. Você usará esse comando no próximo passo.
Agora abra seu terminal local e rode o comando SSH com o redirecionamento de porta habilitado desde o início:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Isso conecta sua máquina local ao servidor Linux remoto e também faz o redirecionamento da porta 8001, para que mais tarde você possa acessar o servidor do llama.cpp no navegador por http://127.0.0.1:8001.
Se esta for sua primeira conexão com o servidor, o SSH pedirá para confirmar a impressão digital (fingerprint). Digite yes e pressione Enter.
Se você definiu uma passphrase ao criar a chave SSH, o SSH vai solicitá-la antes de concluir a conexão. Digite sua passphrase e pressione Enter. Usar passphrase é recomendado porque adiciona uma camada extra de proteção à sua chave privada.
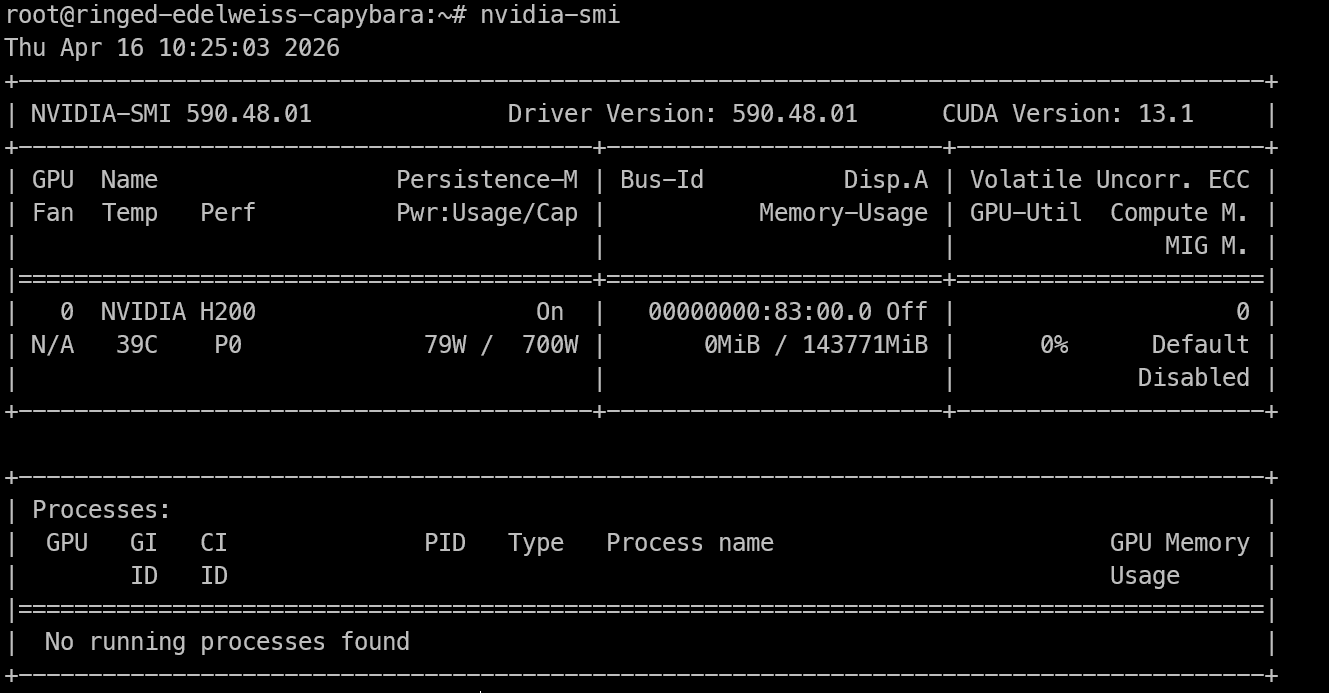
Assim que tiver acesso remoto à máquina H200, a primeira verificação é se a GPU está visível e os drivers NVIDIA estão funcionando corretamente.
Rode:
nvidia-smiEsse comando deve mostrar a GPU NVIDIA instalada, a versão do driver, a versão do CUDA e a memória disponível. Se você ver a H200 listada aqui, a máquina está pronta para inferência.
Agora instale os pacotes do sistema necessários para compilar o llama.cpp e executar o modelo localmente.
Rode:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipEsses pacotes fornecem as ferramentas necessárias para o restante da configuração:
build-essential e cmake são necessários para compilar o llama.cpp
git permite clonar o repositório
curl e wget ajudam a baixar arquivos
tmux é útil para manter processos de longa duração ativos mesmo após fechar o terminal.
Agora que a máquina está pronta, o próximo passo é instalar o llama.cpp, que usaremos para rodar o MiniMax M2.7 localmente. Isso nos dá tanto as ferramentas de linha de comando para testar o modelo quanto o servidor que depois vamos expor como uma API compatível com OpenAI.
Comece clonando o repositório oficial do llama.cpp na máquina remota:
git clone https://github.com/ggml-org/llama.cppIsso criará uma nova pasta llama.cpp no diretório atual com todos os arquivos-fonte necessários para compilar o projeto.
Em seguida, rode o CMake para configurar o build. Nesta configuração, vamos habilitar CUDA para que o llama.cpp use a GPU H200 na inferência.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONEsse comando prepara os arquivos de build dentro do diretório llama.cpp/build.
Agora compile as ferramentas de que precisamos:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitIsso gera três binários principais:
llama-cli para testar e rodar o modelo pelo terminal
llama-server para servir o modelo por uma API local e interface no navegador
llama-gguf-split para trabalhar com arquivos de modelo GGUF fracionados
Copie os binários para a pasta principal
Quando o build terminar, copie os binários compilados para a pasta principal do llama.cpp:
cp llama.cpp/build/bin/llama-* llama.cppIsso facilita executar as ferramentas sem precisar digitar o caminho completo do build toda vez.
Por fim, rode os comandos de ajuda abaixo para confirmar que tudo foi instalado corretamente:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpSe ambos os comandos retornarem informações de uso em vez de erro, o llama.cpp foi instalado com sucesso e você já pode baixar o modelo MiniMax M2.7.
Antes de baixar o modelo, instale as ferramentas de download do Hugging Face na máquina remota:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferIsso instala o CLI hf junto com o hf-xet, que ajuda a lidar com downloads de arquivos grandes de forma mais eficiente.
Em seguida, crie uma pasta para os arquivos do modelo e baixe a versão GGUF UD-IQ4_XS do MiniMax M2.7.
Rode:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Isso cria um diretório dedicado ao modelo e baixa apenas os arquivos UD-IQ4_XS, que são a versão quantizada em 4 bits usada neste guia.
O download é grande, cerca de 108 GB, então pode levar um tempo dependendo da velocidade de rede da sua instância.
Quando o download terminar, verifique se todos os shards GGUF estão presentes rodando:
find /models/minimax-m27 -name "*.gguf"Você deve ver quatro arquivos GGUF listados, algo assim:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufSe os quatro arquivos estiverem lá, o modelo foi baixado corretamente e você está pronto para iniciar o servidor no próximo passo.
Agora é hora de iniciar o modelo com o llama-server. Ele vai carregar o modelo GGUF do MiniMax M2.7, rodá-lo na GPU e expô-lo em um servidor local na porta 8001.
Antes de subir o servidor do modelo, inicie uma sessão tmux para manter o processo rodando mesmo se sua conexão SSH cair ou você fechar o terminal.
Rode:
tmux new -s minimaxIsso cria uma nova sessão tmux chamada minimax, que vamos usar para rodar o servidor.
Agora entre no diretório llama.cpp e rode o servidor com o caminho do modelo e as configurações de inferência:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Isso inicia o servidor na porta 8001 e carrega o modelo. Enquanto o modelo carrega, acompanhe os logs no terminal.

Se o modelo carregar com sucesso na memória da GPU, você verá uma mensagem mostrando que o servidor está ouvindo no endereço e porta configurados.
Quando o modelo estiver totalmente carregado, você pode deixá-lo rodando dentro do tmux e se desconectar da sessão sem interromper o processo.
Pressione Ctrl+B e depois D. Você voltará ao seu terminal normal e o servidor do modelo continuará ativo em segundo plano.
Se quiser ver os logs novamente depois, reanexe a sessão com:
tmux attach -t minimaxDepois que o servidor iniciar, abra outra sessão de terminal e rode:
curl http://127.0.0.1:8001/v1/modelsVocê deve ver uma saída como esta:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Se o modelo MiniMax-M2.7 aparecer listado, o servidor está funcionando corretamente.
Como você já iniciou o SSH com redirecionamento de porta em 8001, agora pode abrir o WebUI do llama.cpp diretamente no navegador acessando http://127.0.0.1:8001.
Isso dá acesso direto à interface do modelo pelo seu navegador local.
Neste ponto, o modelo deve estar pronto para uso. Você pode testá-lo no WebUI ou por requisições de API via terminal para garantir que está tudo certo.
Na minha configuração, o MiniMax M2.7 respondeu extremamente rápido, chegando a cerca de 120 tokens por segundo. Sinceramente, pareceu o modelo local mais veloz que rodei até agora nesse porte, especialmente considerando o quão responsivo ficou mesmo com prompts mais longos e técnicos.
Depois que ele responder corretamente, o MiniMax M2.7 estará rodando 100% localmente e pronto para ser conectado ao seu fluxo de programação.
Agora que o servidor local do llama.cpp está em execução, o próximo passo é conectá-lo ao OpenCode. O OpenCode é um agente de programação baseado em terminal que suporta provedores customizados via arquivo de configuração. Se você quiser saber mais, confira nossa comparação de OpenCode vs Claude Code.
Para modelos locais como o llama.cpp, a configuração mais limpa é apontar o OpenCode para o endpoint local compatível com OpenAI rodando em http://127.0.0.1:8001/v1.
Instale o OpenCode na máquina remota com:
curl -fsSL https://opencode.ai/install | bash
Depois, recarregue seu shell e verifique a versão para confirmar a instalação:
source ~/.bashrc
opencode --version1.4.6Em seguida, crie um arquivo opencode.json que instrui o OpenCode a usar seu servidor local do llama.cpp como um provedor compatível com OpenAI.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFEssa config aponta o OpenCode para o servidor local, define o modelo padrão como MiniMax-M2.7 e usa a mesma abordagem de provedor compatível com OpenAI que o OpenCode documenta para provedores personalizados. O OpenCode também permite selecionar modelos dentro do app com o comando /models.
Agora, crie uma pasta simples de projeto e abra o OpenCode dentro dela:
mkdir ml-app
cd ml-app/
OpencodeQuando o OpenCode abrir, digite /models e selecione o MiniMax-M2.7 sob o seu provedor local.
Depois que o modelo estiver selecionado, dê a ele um prompt de programação real. Por exemplo:
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.Na prática, é aqui que a configuração começa a impressionar. O modelo começa a trabalhar quase imediatamente, cria um plano de tarefas e inicia a construção dos arquivos. Nos meus testes, ele pareceu muito responsivo, o que combina com a velocidade que já estava mostrando no llama.cpp.
No final, ele conseguiu criar os arquivos, rodar os testes e mostrar os resultados.
A partir daí, você pode ir além pedindo para testar os endpoints da API de ML, melhorar a estrutura do app ou adicionar novas funcionalidades. Como o OpenCode foi feito para fluxos de trabalho de programação no terminal, esse é o momento em que o setup local do MiniMax começa a parecer um agente de código prático — não apenas um modelo rodando em um servidor.
No meu caso, o app local de API de ML estava funcionando corretamente no final da execução. Rodamos testes unitários, fizemos smoke testing e garantimos que não havia erros durante a execução e os testes do código. No geral, levou cerca de 2 minutos para concluir tudo, o que mostra como esse modelo é rápido em um fluxo de programação local.
Eu comecei com o vLLM, mas encontrei vários problemas, especialmente ao tentar rodar um modelo AWQ de 4 bits. Para este tipo de setup, achei o llama.cpp muito mais fácil de usar. A instalação pareceu mais simples, o fluxo mais direto e foi bem mais rápido colocar tudo para rodar direito.
Outra coisa que gostei no llama.cpp é que ele já vem com um WebUI embutido, então você pode testar o modelo na hora em uma interface parecida com o ChatGPT, direto do navegador. Isso facilita muito validar prompts, testar respostas e garantir que o modelo está funcionando antes de conectá-lo a algo como o OpenCode.
Para uso local, eu considero o MiniMax M2.7 um dos melhores modelos que rodei até agora. Ele é menor do que o GLM 5.1, parece mais rápido, entende bem código e tem ótimo desempenho em tarefas de programação agentic. Até a versão de 4 bits foi muito bem em tarefas mais complexas, o que o torna prático para uso real e não apenas para experimentação.
A velocidade é uma grande razão para esse setup se destacar. No meu caso, o MiniMax M2.7 estava rodando a cerca de 120 tokens por segundo com geração bem fluida e, por meio do redirecionamento de porta via SSH, eu podia usá-lo no meu navegador local ou via API como se estivesse rodando na minha própria máquina. Isso deixou todo o fluxo rápido, simples e muito prático.
Cursos de engenharia de IA
Programa
Programa
Curso
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Bex Tuychiev

