
Lernpfad
Associate AI Engineer für Datenwissenschaftler
40 Std.
MiniMax M2.7 hebt sich von vielen Open-Weight-Modellen ab, weil es speziell für komplexe agentische Workflows entwickelt wurde – inklusive Toolnutzung, mehrstufiger Coding-Aufgaben und produktivitätsorientiertem Reasoning.
Obwohl es nicht zur größten Modellklasse gehört, ist MiniMax M2.7 darauf ausgelegt, starke Coding- und Reasoning-Leistung bei deutlich schlankerem Deployment-Footprint zu liefern.
In diesem Guide nutze ich Hyperbolic, weil es den günstigsten On-Demand-Zugang zur H200 bietet, eine schnelle Bereitstellung ermöglicht und das Aufsetzen von Linux-GPU-Maschinen für lokales Model Serving enorm vereinfacht.
Du lernst, wie du:
Eine Hyperbolic-H200-Linux-Maschine startest
llama.cpp für lokale Inferenz installierst
Unsloths UD-IQ4_XS GGUF-Version von MiniMax M2.7 herunterlädst
llama-server als OpenAI-kompatible lokale API startest
Das lokale Modell an OpenCode für agentische Coding-Workflows anbindest
MiniMax M2.7 schlägt eine stärker agentenzentrierte Richtung ein als frühere Open-Modelle wie MiniMax M2.5. Herausragend ist nicht nur die Coding- oder Reasoning-Fähigkeit, sondern vor allem, dass es dafür gebaut ist, aktiv an seinem eigenen Verbesserungsprozess mitzuwirken.
Laut MiniMax ist M2.7 ihr erstes Modell, das seine eigene Evolution maßgeblich mitgestaltet – indem es komplexe Agenten-Harnesses aufbaut, aufwendige Produktivitätsaufgaben übernimmt und mit Agententeams, fortgeschrittenen Fähigkeiten und dynamischer Toolsuche arbeitet.
Ein großer Schritt bei M2.7 ist der Self-Evolution-Workflow. Während der Entwicklung wurde das Modell genutzt, um sein eigenes Gedächtnis zu aktualisieren, komplexe Skills für Reinforcement-Learning-Experimente zu erzeugen und seinen Lernprozess anhand der Experimentergebnisse zu verfeinern.
All das lässt M2.7 weniger wie ein statisches Standardmodell wirken – und mehr wie ein System, das auf iterative Verbesserung ausgelegt ist.
Quelle: MiniMaxAI/MiniMax-M2.7 · Hugging Face
Spannend finde ich vor allem, dass MiniMax M2.7 nicht als „noch ein Open-Modell“ positioniert. Für mich weist es auf einen nachhaltigeren Weg hin, Modelle zu verbessern und zu trainieren – bei dem fortgeschrittene Systeme aktiver an ihrer eigenen Entwicklung mitarbeiten.
Statt nur auf riesige neue Datensätze zu setzen, zeigt es, wie moderne Trainingsmethoden und Selbstverbesserungsschleifen die Leistung weiter nach vorn bringen können.
Gehe zu Hyperbolic, registriere dich und lade mindestens 5 $ Guthaben per Karte auf. Wechsle dann zum Tab GPUs, klicke auf Launch Instance und wähle die Maschine H200 SXM5.
Dieser Guide nutzt einen Remote-GPU-Server. Bevor du die Maschine startest, stelle sicher, dass dein SSH-Zugang bereit ist. SSH ermöglicht dir die sichere Verbindung von deinem Terminal zur Linux-Maschine auf Hyperbolic.
Wenn du SSH bereits nutzt und ein Schlüsselpaar eingerichtet hast, kannst du direkt weitermachen. Falls nicht, lege zuerst ein Schlüsselpaar an.
Öffne auf deinem lokalen Rechner ein Terminal und erzeuge einen SSH-Schlüssel, falls du noch keinen hast:
ssh-keygenSpeichere ihn bei der Abfrage mit Enter am Standardspeicherort. Optional kannst du eine Passphrase setzen, um die Sicherheit zu erhöhen.
Sobald der Schlüssel erstellt ist, gib deinen Public Key aus, damit du ihn kopieren kannst:
cat ~/.ssh/id_rsa.pubFalls dein System stattdessen das Ed25519-Format nutzt, verwende:
cat ~/.ssh/id_ed25519.pubKopiere die komplette Ausgabe und füge sie in deinem Hyperbolic-Konto hinzu. Lade nur den Public Key hoch. Der Private Key bleibt auf deinem Rechner und darf niemals geteilt werden.
Sobald dein SSH-Schlüssel hinzugefügt ist, öffne im Hyperbolic-Dashboard den Tab GPUs und klicke auf Launch Instance. Wähle für dieses Setup die H200-SXM5-Instanz aus.
Gib der Instanz vor dem Start einen klaren, wiedererkennbaren Namen. So findest du sie später leichter, vor allem, wenn du mehrere Maschinen startest oder später zurückkehrst.
Prüfe danach die Einstellungen, bestätige, dass dein SSH-Schlüssel angehängt ist, und starte die Maschine. Die Plattform beginnt dann mit der Bereitstellung des GPU-Servers.
Sobald die Maschine vollständig bereit ist, erscheint sie im Dashboard als aktiv. Dann siehst du auch den SSH-Befehl, mit dem du dich vom lokalen Terminal verbinden kannst. Diesen verwendest du im nächsten Schritt.
Öffne jetzt dein lokales Terminal und führe den SSH-Befehl direkt mit Portweiterleitung aus:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Damit verbindest du deinen Rechner mit dem entfernten Linux-Server und leitest zusätzlich den Port 8001 weiter, sodass du den llama.cpp-Server später im Browser über http://127.0.0.1:8001 erreichst.
Wenn du zum ersten Mal verbindest, fragt SSH nach der Bestätigung des Fingerprints. Tippe yes und drücke Enter.
Wenn du beim Erstellen des SSH-Schlüssels eine Passphrase gesetzt hast, wird SSH sie vor dem Verbindungsaufbau abfragen. Tippe sie ein und drücke Enter. Eine Passphrase ist empfehlenswert, da sie deinen Private Key zusätzlich schützt.
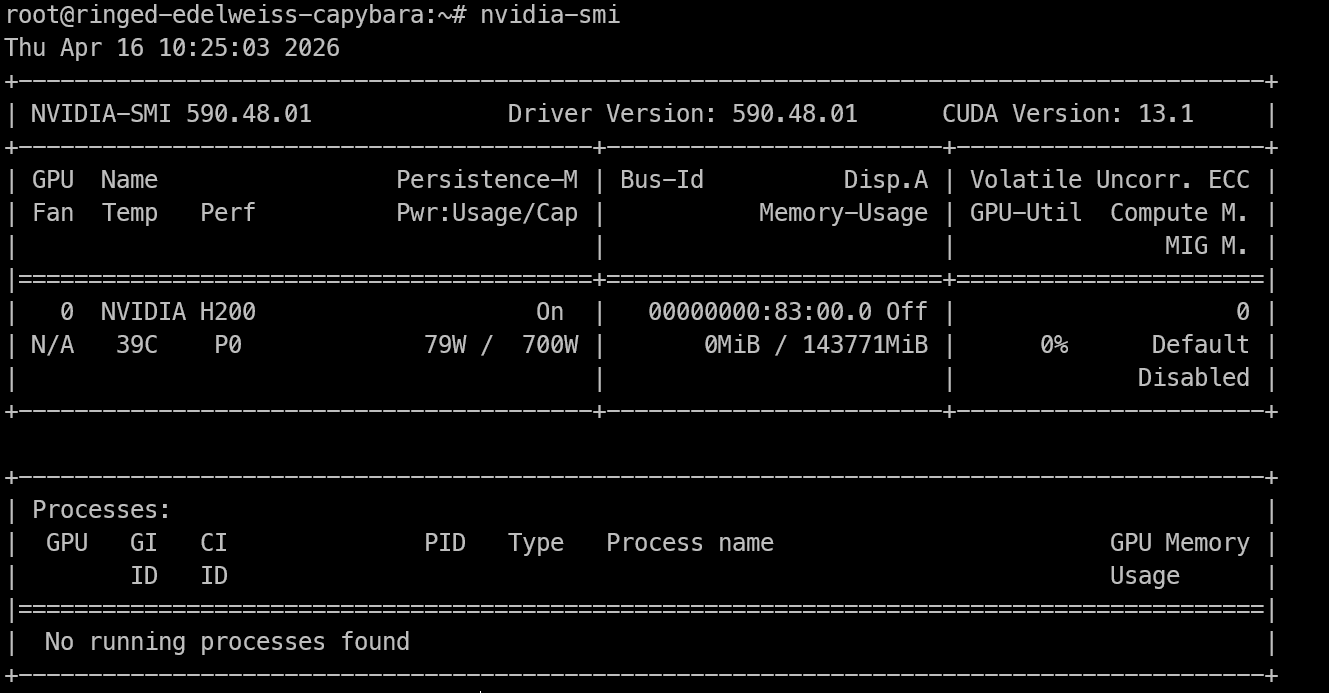
Sobald du Remote-Zugang zur H200 hast, prüfe zuerst, ob die GPU sichtbar ist und die NVIDIA-Treiber korrekt laufen.
Führe aus:
nvidia-smiDer Befehl zeigt die installierte NVIDIA-GPU, die Treiberversion, die CUDA-Version und den verfügbaren Speicher. Wenn die H200 hier gelistet ist, ist die Maschine bereit für Inferenz.
Installiere jetzt die Systempakete, die zum Bauen von llama.cpp und zum lokalen Ausführen des Modells nötig sind.
Führe aus:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipDiese Pakete liefern dir die nötigen Werkzeuge für den weiteren Ablauf:
build-essential und cmake sind für das Kompilieren von llama.cpp erforderlich
git zum Klonen des Repos
curl und wget zum Herunterladen von Dateien
tmux ist praktisch, um lang laufende Prozesse aktiv zu halten, auch wenn du das Terminal schließt.
Jetzt, da die Maschine bereit ist, installierst du llama.cpp, mit dem wir MiniMax M2.7 lokal ausführen. Du erhältst sowohl CLI-Tools zum Testen als auch den Server, den wir später als OpenAI-kompatible API bereitstellen.
Klonen wir zunächst das offizielle llama.cpp-Repo auf die Remote-Maschine:
git clone https://github.com/ggml-org/llama.cppDadurch entsteht ein llama.cpp-Ordner mit allen Quelldateien zum Bauen des Projekts.
Als Nächstes konfigurieren wir den Build mit CMake. In diesem Setup aktivieren wir CUDA, damit llama.cpp die H200-GPU für Inferenz nutzen kann.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONDieser Befehl erzeugt die Build-Dateien im Verzeichnis llama.cpp/build.
Kompiliere nun die benötigten Tools:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitDabei entstehen drei Haupt-Binaries:
llama-cli zum Testen und Ausführen des Modells im Terminal
llama-server zum Bereitstellen über eine lokale API und Browseroberfläche
llama-gguf-split für den Umgang mit gesplitteten GGUF-Modellfiles
Binaries in den Hauptordner kopieren
Sobald der Build fertig ist, kopiere die kompilierten Binaries in den Hauptordner von llama.cpp:
cp llama.cpp/build/bin/llama-* llama.cppSo kannst du die Tools nutzen, ohne jedes Mal den kompletten Build-Pfad anzugeben.
Führe abschließend die Hilfe-Befehle aus, um zu prüfen, ob alles korrekt installiert ist:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpWenn beide Befehle Nutzungsinformationen statt einer Fehlermeldung zurückgeben, wurde llama.cpp erfolgreich installiert und du kannst das MiniMax-M2.7-Modell herunterladen.
Bevor du das Modell herunterlädst, installiere die Hugging-Face-Downloadtools auf der Remote-Maschine:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferDamit installierst du die hf-CLI sowie hf-xet, was große Downloads effizienter handhabt.
Lege als Nächstes einen Ordner für die Modelldateien an und lade die UD-IQ4_XS-GGUF-Version von MiniMax M2.7 herunter.
Führe aus:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Damit wird ein eigener Modellordner angelegt und ausschließlich die UD-IQ4_XS-Dateien geladen – die 4‑Bit-quantisierte Version, die wir hier verwenden.
Der Download ist groß, etwa 108 GB – je nach Netzgeschwindigkeit der Instanz kann das dauern.
Sobald der Download abgeschlossen ist, prüfe, ob alle GGUF-Shards vorhanden sind:
find /models/minimax-m27 -name "*.gguf"Du solltest vier GGUF-Dateien sehen, in etwa so:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufWenn alle vier Dateien da sind, ist das Modell korrekt heruntergeladen und du kannst im nächsten Schritt den Server starten.
Jetzt starten wir das Modell mit llama-server. Dabei wird das MiniMax-M2.7-GGUF-Modell geladen, auf der GPU ausgeführt und über einen lokalen Server auf Port 8001 bereitgestellt.
Starte vor dem Serverlaunch eine tmux-Session, damit der Prozess weiterläuft, falls die SSH-Verbindung abreißt oder du das Terminal schließt.
Führe aus:
tmux new -s minimaxDamit erstellst du eine tmux-Session namens minimax, in der wir den Server laufen lassen.
Wechsle in das Verzeichnis llama.cpp und starte den Server mit Modellpfad und Inferenzparametern:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Damit startest du den Server auf Port 8001 und lädst das Modell. Behalte beim Laden die Logs im Terminal im Blick.

Wenn das Modell erfolgreich in den GPU-Speicher geladen wurde, siehst du eine Meldung, dass der Server auf der konfigurierten Adresse und dem Port lauscht.
Sobald das Modell vollständig geladen ist, kannst du es in tmux laufen lassen und die Session trennen, ohne sie zu beenden.
Drücke Strg+B, dann D. Du kehrst in dein normales Terminal zurück, während der Model-Server im Hintergrund weiterläuft.
Wenn du die Logs später wieder ansehen willst, hänge die Session erneut an mit:
tmux attach -t minimaxNachdem der Server gestartet ist, öffne eine weitere Terminal-Session und führe aus:
curl http://127.0.0.1:8001/v1/modelsDu solltest eine Ausgabe wie diese sehen:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Wenn das Modell MiniMax-M2.7 gelistet ist, läuft der Server ordnungsgemäß.
Da du SSH bereits mit Portweiterleitung auf 8001 gestartet hast, kannst du die llama.cpp-WebUI jetzt direkt im Browser unter http://127.0.0.1:8001 öffnen.
So greifst du direkt aus deinem lokalen Browser auf die Modelloberfläche zu.
An diesem Punkt sollte das Modell einsatzbereit sein. Teste es in der WebUI oder über API-Requests im Terminal, um sicherzustellen, dass alles korrekt funktioniert.
In meinem Setup reagierte MiniMax M2.7 extrem schnell – etwa 120 Tokens pro Sekunde. Es fühlte sich ehrlich gesagt wie das schnellste lokale Modell in dieser Größenordnung an, zumal es auch bei längeren, technischeren Prompts sehr responsiv blieb.
Sobald die Antworten passen, läuft MiniMax M2.7 vollständig lokal und ist bereit für die Einbindung in deinen Coding-Workflow.
Da der lokale llama.cpp-Server läuft, verbinden wir ihn jetzt mit OpenCode. OpenCode ist ein terminalbasierter Coding-Agent und unterstützt eigene Provider über seine Konfigurationsdatei. Wenn du mehr wissen willst, lies unseren Vergleich OpenCode vs Claude Code.
Für lokale Modelle wie llama.cpp ist es am saubersten, OpenCode auf den lokalen OpenAI-kompatiblen Endpoint unter http://127.0.0.1:8001/v1 zu zeigen.
Installiere OpenCode auf der Remote-Maschine mit:
curl -fsSL https://opencode.ai/install | bash
Lade dann deine Shell neu und prüfe die Version, um die erfolgreiche Installation zu bestätigen:
source ~/.bashrc
opencode --version1.4.6Lege als Nächstes eine Datei opencode.json an, die OpenCode mitteilt, deinen lokalen llama.cpp-Server als OpenAI-kompatiblen Provider zu nutzen.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFDiese Config verweist OpenCode auf den lokalen Server, setzt MiniMax-M2.7 als Standardmodell und nutzt den gleichen OpenAI-kompatiblen Provideransatz, den OpenCode für Custom Provider dokumentiert. Alternativ kannst du Modelle in der App mit dem Befehl /models auswählen.
Erstelle nun einen einfachen Projektordner und starte OpenCode darin:
mkdir ml-app
cd ml-app/
OpencodeWenn OpenCode geöffnet ist, tippe /models und wähle MiniMax-M2.7 unter deinem lokalen Provider aus.
Gib dem Modell, sobald es ausgewählt ist, einen realen Coding-Prompt. Zum Beispiel:
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.In der Praxis zeigt sich hier, wie beeindruckend das Setup ist. Das Modell legt fast sofort los, erstellt einen Aufgabenplan und beginnt mit dem Aufbau der Dateien. In meinen Tests wirkte es sehr reaktionsschnell – konsistent mit der hohen Geschwindigkeit über llama.cpp.
Am Ende konnte es die Dateien erstellen, die Tests ausführen und die Ergebnisse anzeigen.
Danach kannst du weitergehen: bitte das Modell, die ML-API-Endpunkte zu testen, die App-Struktur zu verbessern oder neue Features hinzuzufügen. Da OpenCode für terminalbasierte Coding-Workflows gebaut ist, fühlt sich das lokale MiniMax-Setup hier wie ein praxisnaher Coding-Agent an – nicht nur wie ein Modell auf einem Server.
In meinem Fall lief die lokale ML-API-App am Ende korrekt. Wir haben Unit-Tests ausgeführt, Smoke-Tests gemacht und sichergestellt, dass beim Ausführen und Testen keine Fehler auftraten. Insgesamt dauerte alles rund 2 Minuten – ein gutes Indiz dafür, wie schnell sich dieses Modell im lokalen Coding-Workflow anfühlt.
Ursprünglich habe ich mit vLLM begonnen, bin aber auf einige Probleme gestoßen – besonders beim Ausführen eines 4‑Bit‑AWQ-Modells. Für dieses Setup war llama.cpp deutlich angenehmer: die Installation simpler, der Ablauf geradliniger und alles viel schneller einsatzbereit.
Praktisch ist auch die integrierte WebUI von llama.cpp. So kannst du das Modell sofort in einer ChatGPT-ähnlichen Oberfläche testen – Prompts prüfen, Antworten testen und sicherstellen, dass alles läuft, bevor du es an OpenCode anbindest.
Für den lokalen Einsatz ist MiniMax M2.7 eines der besten Modelle, die ich bisher genutzt habe. Es ist kleiner als GLM 5.1, fühlt sich schneller an, versteht Code gut und liefert starke Ergebnisse bei agentischen Coding-Aufgaben. Selbst die 4‑Bit‑Version hat bei komplexeren Tasks sehr gut gearbeitet – praxisnah, nicht nur zum Experimentieren.
Die Geschwindigkeit ist ein wesentlicher Pluspunkt dieses Setups. Bei mir lief MiniMax M2.7 mit rund 120 Tokens pro Sekunde bei sehr flüssiger Generierung – und dank SSH-Portweiterleitung konnte ich es aus meinem lokalen Browser oder per API nutzen, als liefe es direkt auf meinem Rechner. Das macht den gesamten Workflow schnell, unkompliziert und sehr alltags tauglich.
KI-Engineering-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Vinod Chugani
14 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Kurtis Pykes
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Adel Nehme