
Cursus
Principes de base des données en Python
28 h
Une liste chaînée est une structure de données essentielle pour organiser et gérer l’information. Elle contient une série de nœuds stockés à des emplacements aléatoires en mémoire, ce qui favorise une gestion efficace de la mémoire. Chaque nœud d’une liste chaînée comporte deux éléments principaux : la partie données et une référence vers le nœud suivant dans la séquence.
Si le concept vous paraît complexe au premier abord, pas d’inquiétude !
Nous allons le ramener à ses fondamentaux pour expliquer ce qu’est une liste chaînée, pourquoi on l’utilise et les avantages spécifiques qu’elle offre.
Les listes chaînées ont été conçues pour pallier plusieurs limites liées au stockage de données dans des listes et des tableaux classiques, comme indiqué ci-dessous :
Dans les listes, insérer ou supprimer un élément à une position autre que la fin impose de décaler tous les éléments suivants. Cette opération a une complexité en temps de O(n) et peut dégrader fortement les performances à mesure que la liste grandit. Si vous n’êtes pas encore familier avec le fonctionnement ou l’implémentation des listes, consultez notre tutoriel sur les listes en Python.
Les listes chaînées, elles, fonctionnent différemment. Elles stockent les éléments dans des emplacements mémoire non contigus et les relient par des pointeurs vers les nœuds suivants. Cette structure permet d’ajouter ou de retirer des éléments à n’importe quelle position en modifiant simplement les liens pour inclure un nouvel élément ou contourner celui supprimé.
Dès lors que vous disposez d’une référence directe vers le nœud au point d’insertion ou de suppression, l’opération en elle‑même est en O(1). En revanche, trouver cette position nécessite toujours un parcours en O(n) ; le bénéfice en O(1) ne s’applique donc que lorsque vous détenez déjà un pointeur vers le nœud pertinent (par exemple en travaillant en tête de liste).
Les listes Python sont des tableaux dynamiques, ce qui leur confère une certaine flexibilité de taille.
Cependant, ce redimensionnement implique des opérations coûteuses, notamment la réallocation du tableau dans un bloc mémoire plus grand. Cette réallocation est inefficace car les éléments doivent être recopiés dans un nouveau bloc, avec parfois plus d’espace que nécessaire à court terme.
À l’inverse, les listes chaînées peuvent croître et rétrécir dynamiquement sans réallocation ni redimensionnement. Elles sont donc à privilégier pour les tâches qui exigent une grande flexibilité.
Les listes allouent la mémoire de tous leurs éléments dans un bloc contigu. Si une liste doit dépasser sa taille initiale, elle doit allouer un nouveau bloc contigu plus grand puis copier tous les éléments existants dans ce bloc. Cette opération est chronophage et inefficace, en particulier pour les grandes listes. À l’inverse, si la taille initiale est surestimée, la mémoire non utilisée est gaspillée.
Les listes chaînées, elles, allouent la mémoire de chaque élément séparément. Cette organisation améliore l’utilisation de la mémoire, car l’allocation des nouveaux éléments se fait au fil de l’eau, à mesure qu’ils sont ajoutés.
Même si les listes chaînées offrent des avantages face aux listes et tableaux classiques, comme la taille dynamique et une meilleure efficience mémoire, elles ont aussi des limites. Comme chaque élément doit stocker un pointeur vers le nœud suivant, l’empreinte mémoire par élément est plus élevée. De plus, cette structure ne permet pas l’accès direct aux données : accéder à un élément impose un parcours séquentiel depuis le début de la liste, ce qui donne une complexité de recherche en O(n).
Le choix entre liste chaînée et tableau dépend donc des besoins de votre application. Les listes chaînées sont particulièrement utiles lorsque :
On distingue trois types de listes chaînées, chacune présentant des atouts spécifiques selon les cas d’usage :
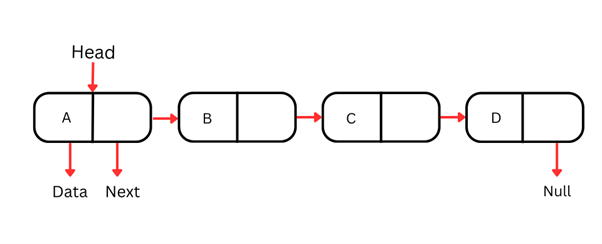
Liste simplement chaînée
La liste simplement chaînée est la forme la plus simple : chaque nœud contient des données et une référence vers le nœud suivant. Le parcours ne se fait que dans un seul sens : de la tête (premier nœud) vers la queue (dernier nœud).
Chaque nœud d’une liste simplement chaînée comprend généralement deux parties :
Comme ces structures ne se parcourent que dans un sens, accéder à un élément précis par valeur ou par index impose de partir de la tête et d’avancer nœud par nœud jusqu’à trouver l’élément voulu. Cette opération est en O(n), ce qui est moins efficace pour de grandes listes.
Insérer ou supprimer un nœud au début d’une liste simplement chaînée est très efficace, en O(1). En revanche, les insertions et suppressions au milieu ou à la fin nécessitent de parcourir la liste jusqu’au point visé, soit une complexité en O(n).
Par conception, les listes simplement chaînées sont particulièrement utiles lorsque la majorité des opérations se fait en tête de liste.
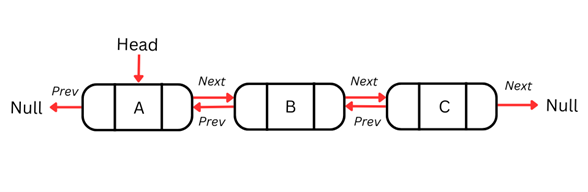
Liste doublement chaînée
L’un des inconvénients des listes simplement chaînées est qu’elles ne se parcourent que dans un sens ; on ne peut pas revenir au nœud précédent si nécessaire. Cette contrainte limite les opérations nécessitant une navigation bidirectionnelle.
Les listes doublement chaînées résolvent ce problème en ajoutant un pointeur supplémentaire dans chaque nœud, ce qui permet un parcours dans les deux sens. Chaque nœud contient alors trois éléments : les données, un pointeur vers le nœud suivant et un pointeur vers le nœud précédent.
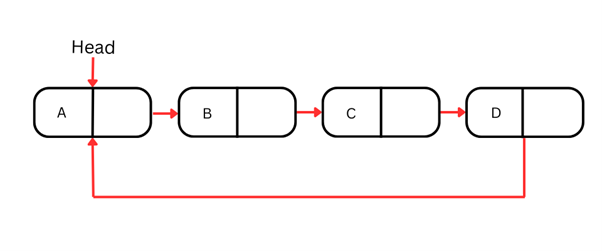
Liste chaînée circulaire
Les listes chaînées circulaires sont une forme particulière où le dernier nœud pointe vers le premier, créant une structure en boucle. Contrairement aux listes simplement ou doublement chaînées vues précédemment, la liste circulaire ne se termine pas : elle boucle indéfiniment.
Cette cyclicité les rend idéales pour des scénarios nécessitant un parcours continu, par exemple des jeux de plateau où l’on revient du dernier au premier joueur, ou des algorithmes comme l’ordonnancement « round‑robin ».
Un récapitulatif utile pour comparer rapidement les listes chaînées aux listes Python :
| Opération | Liste simplement chaînée | Tableau/Liste Python |
|---|---|---|
| Accès par index | O(n) | O(1) |
| Recherche par valeur | O(n) | O(n) |
| Insertion en tête | O(1) | O(n) |
| Insertion en fin | O(n) | O(1) amorti |
| Insertion au milieu | O(n) | O(n) |
| Suppression en tête | O(1) | O(n) |
| Suppression en fin | O(n) | O(1) amorti |
À retenir : les listes chaînées excellent pour les insertions et suppressions en tête (O(1)), mais sont moins performantes pour le reste. Si vous n’ajoutez ni ne supprimez fréquemment des éléments au début de votre structure, une liste Python classique sera probablement un meilleur choix.
Maintenant que vous savez ce qu’est une liste chaînée, pourquoi on l’utilise et quelles sont ses variantes, passons à son implémentation en Python. Le notebook de ce tutoriel est disponible dans ce workbook DataLab ; en en créant une copie, vous pourrez modifier et exécuter le code. Idéal si vous rencontrez des difficultés à l’exécuter localement !
Comme nous l’avons vu, un nœud est un élément de la liste chaînée qui stocke des données et une référence vers le nœud suivant. Voici comment définir un nœud en Python :
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"Le code ci‑dessus initialise un nœud en effectuant deux actions principales : l’attribut « data » reçoit la valeur représentant l’information à stocker, et l’attribut « next », qui représente l’adresse du nœud suivant, est initialisé à None, indiquant qu’il n’est relié à aucun autre nœud. Au fur et à mesure que nous ajouterons de nouveaux nœuds, cet attribut pointera vers le nœud suivant.
Ensuite, nous allons créer la classe de la liste chaînée. Elle regroupera toutes les opérations de gestion des nœuds, comme l’insertion et la suppression. Commençons par initialiser la liste chaînée :
class LinkedList:
def __init__(self):
self.head = None # Initialize head as NoneEn définissant self.head à None, nous indiquons que la liste est initialement vide et qu’aucun nœud n’est référencé. Nous allons maintenant la peupler en insérant de nouveaux nœuds.
Au sein de la classe LinkedList, ajoutons une méthode qui crée un nouveau nœud et le place en tête de liste :
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new nodeÀ chaque appel de cette méthode, un nouveau nœud est créé avec les données fournies. Son pointeur « next » est défini sur l’actuelle tête de liste, ce qui place ce nœud devant les autres. Enfin, ce nouveau nœud devient la tête.
Nous allons maintenant peupler la liste avec une série de mots pour mieux comprendre l’insertion. Pour cela, commençons par créer une méthode qui parcourt et affiche le contenu de la liste :
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new lineCette méthode affiche le contenu de notre liste chaînée. Utilisons maintenant les méthodes définies pour peupler la liste avec ces mots : « the quick brown fox ».
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()Ce code devrait produire la sortie suivante :
"the quick brown fox"
Créons maintenant une méthode insertAtEnd dans la classe LinkedList pour ajouter un nœud en fin de liste. Si la liste est vide, le nouveau nœud devient la tête. Sinon, il est chaîné après le dernier nœud. Voyons cela en pratique :
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_nodeLa méthode commence par créer un nœud. Si la liste est vide, il devient la tête. Sinon, elle parcourt la liste pour trouver le dernier nœud et définit son pointeur suivant vers le nouveau nœud.
Ajoutez cette méthode à la classe LinkedList et utilisez‑la pour ajouter un mot à la fin de la liste. Pour cela, modifiez votre fonction principale comme suit :
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()Ici, nous appelons simplement insertAtEnd pour ajouter « jumps » à la fin de la liste. La sortie attendue est :
"the quick brown fox jumps"
Supprimer le premier nœud est simple : il suffit de faire pointer la tête vers le deuxième nœud. Ainsi, le premier nœud ne fait plus partie de la liste. Ajoutez la méthode suivante à la classe LinkedList :
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new headPour supprimer le dernier nœud, on parcourt la liste pour trouver l’avant‑dernier et on met son pointeur suivant à None. Ainsi, le dernier nœud est détaché. Copiez la méthode suivante dans votre classe LinkedList :
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to NoneLa méthode vérifie d’abord si la liste est vide, et renvoie un message le cas échéant. Si la liste ne contient qu’un seul nœud, celui‑ci est supprimé. Sinon, elle localise l’avant‑dernier nœud et met sa référence « next » à None.
Mettons maintenant à jour la fonction principale pour supprimer des éléments au début et à la fin :
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()Ce code affiche la liste avant et après suppression, ce qui illustre le fonctionnement des opérations d’insertion et de suppression. Vous devriez obtenir :
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown foxLa dernière opération de ce chapitre consiste à récupérer une valeur spécifique dans la liste chaînée. Pour ce faire, la méthode part de la tête et parcourt chaque nœud en vérifiant si ses données correspondent à la valeur recherchée. Voici une implémentation pratique :
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" Pour chercher des valeurs précises dans la liste que nous avons créée, mettez à jour votre fonction principale pour inclure cette méthode de recherche :
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to findLa sortie attendue est :
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the listLe mot « quick » est bien trouvé, puisqu’il est à la première position. En revanche, « lazy » ne fait pas partie de la liste, d’où l’absence de correspondance.
Bravo si vous êtes arrivé jusqu’ici ! Vous disposez désormais d’une solide compréhension des principes de base des listes chaînées : leur structure, leurs types, l’ajout et la suppression d’éléments, ainsi que leur parcours.
Mais ce n’est qu’un début. Les listes chaînées ouvrent la porte au monde des structures de données et des algorithmes. Voici quelques pistes pour aller plus loin :
Mettez en pratique les listes chaînées en les intégrant à un projet de code ou de data science. Elles servent à développer des systèmes de fichiers, construire des tables de hachage, et même créer des systèmes de navigation GPS ou des jeux de plateau. Pour vous lancer, explorez nos projets de data science guidés et gratuits qui vous apprennent à résoudre des problèmes concrets en Python, R et SQL.
Apprendre d’autres structures, comme les arbres, piles et files, est la suite logique après les listes chaînées. Ces structures s’appuient sur leurs principes et vous aident à résoudre efficacement un plus large éventail de problèmes. Les arbres et arbres binaires de recherche, par exemple, étendent le concept des listes chaînées sous une forme hiérarchique, où chaque nœud peut se connecter à plusieurs éléments.
Si ces notions vous semblent nouvelles, pas d’inquiétude ! Datacamp propose un cours complet sur les structures de données et algorithmes en Python, qui les détaille pas à pas. Vous y verrez d’abord les piles, arbres, tables de hachage, files et graphes. Puis vous aborderez les algorithmes de recherche et de tri, de quoi devenir un programmeur plus efficace et un meilleur résolveur de problèmes.
Dans ce tutoriel, nous avons implémenté des listes simplement chaînées, avec les opérations d’insertion, de suppression et de parcours.
Poursuivez en découvrant l’implémentation des listes doublement chaînées et circulaires. Les « skip lists » sont une autre extension permettant d’accélérer les recherches en facilitant l’accès aux éléments.
Maîtriser ces structures avancées fera progresser vos compétences techniques et améliorera nettement vos capacités de programmation, vous préparant à des défis plus complexes en data science, développement logiciel et ingénierie en apprentissage automatique.
Si vous souhaitez une introduction plus accessible à la programmation avant d’aborder ces sujets avancés, explorez notre parcours Python Programmer. Il propose une série de cours pour apprendre les fondamentaux du langage.
Continuez à apprendre Python !
Cursus
Cursus
Cours
Tutoriel
Abid Ali Awan
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Allan Ouko
Tutoriel
Sejal Jaiswal
Tutoriel
Mark Pedigo
