Tracks
Python データ基礎
28時間
連結リストは、データの整理と管理において重要な役割を果たすデータ構造です。メモリ上のランダムな位置に保存された一連のノードで構成され、効率的なメモリ管理を可能にします。連結リストの各ノードは、データ部分と、次のノードへの参照という2つの主要な要素を持ちます。
最初は難しく感じられるかもしれませんが、ご安心ください。
連結リストとは何か、なぜ使うのか、そしてそれがもたらす固有の利点について、基礎からわかりやすく解説します。
連結リストは、通常のリストや配列でデータを保存する際のさまざまな欠点を克服するために作られました。以下で説明します。
リストでは、末尾以外の位置に要素を挿入・削除すると、後続の要素をすべてずらす必要があります。この処理の時間計算量はO(n)で、リストが大きくなるほど性能が低下します。リストの仕組みや実装にまだ慣れていない場合は、Pythonリストのチュートリアルをご覧ください。
一方、連結リストは仕組みが異なります。要素は非連続のメモリ領域に保存され、次のノードへのポインタで接続されます。この構造により、連結リストではリンクを付け替えるだけで任意の位置に要素を追加・削除できます。
挿入・削除位置のノードを直接参照できる場合、その操作自体はO(1)です。ただし、その位置を見つけるにはO(n)の走査が必要になるため、O(1)の利点は、対象ノードへのポインタをすでに保持している場合(たとえばリストの先頭を操作する場合)にのみ当てはまります。
Pythonのリストは動的配列であり、サイズを変更できる柔軟性があります。
しかしこの過程では、より大きなメモリブロックへの再割り当てなど、複雑な処理が伴います。再割り当てでは要素を新しいブロックにコピーする必要があり、当面不要な領域まで確保してしまう可能性があるため非効率です。
対照的に、連結リストは再割り当てやサイズ変更をせずに動的に伸縮できます。高い柔軟性が求められるタスクに適しています。
リストはすべての要素に対して連続したメモリ領域を確保します。初期サイズを超えて拡張する必要がある場合は、より大きな連続領域を新たに確保し、既存の要素をすべてコピーし直さなければなりません。これは特に大きなリストでは時間がかかり非効率です。逆に初期サイズを過大に見積もると、未使用メモリが無駄になります。
一方、連結リストは各要素ごとに個別にメモリを確保します。新しい要素の追加時に必要分だけを確保できるため、メモリの利用効率が高くなります。
連結リストは、動的サイズやメモリ効率など、通常のリストや配列に対する利点を持つ一方で、制約もあります。各要素に次ノードへのポインタを保持する必要があるため、要素あたりのメモリ使用量は増えます。また、このデータ構造ではデータへの直接アクセスができません。要素にアクセスするには先頭から順にたどる必要があり、探索の時間計算量はO(n)です。
連結リストと配列のどちらを使うかは、アプリケーションの要件によって決まります。連結リストが特に有用なのは次のような場合です。
連結リストには3種類があり、シナリオごとに異なる利点を提供します。以下の3つです。
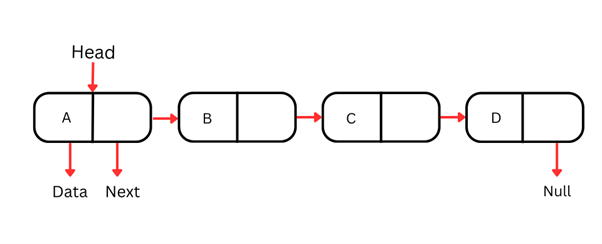
単方向連結リスト
単方向連結リストは最も基本的な形式で、各ノードがデータと、次のノードへの参照を持ちます。先頭(最初のノード)から末尾(最後のノード)へ、1方向にのみ走査できます。
単方向連結リストの各ノードは通常、次の2つの部分で構成されます。
1方向にしか走査できないため、値やインデックスで特定の要素にアクセスするには、先頭から順に目的のノードに到達するまで移動する必要があります。この操作の時間計算量はO(n)であり、大きなリストでは非効率です。
先頭へのノードの挿入・削除は時間計算量O(1)で非常に効率的です。ただし、中間や末尾での挿入・削除は、その位置まで走査が必要なためO(n)になります。
単方向連結リストは、リストの先頭で頻繁に操作を行う場合に有用です。
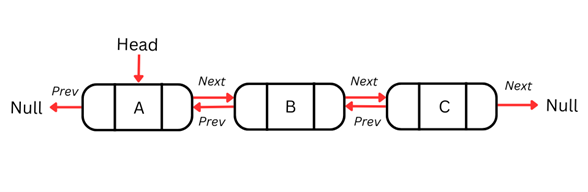
双方向連結リスト
単方向連結リストの欠点は、1方向にしか走査できず、必要に応じて前のノードへ戻れないことです。この制約は、双方向の移動が必要な操作の妨げになります。
双方向連結リストは、各ノードに追加のポインタを持たせることで、この問題を解決します。これにより、リストを双方向に走査できます。双方向連結リストの各ノードは、データ、次のノードへのポインタ、前のノードへのポインタという3要素を持ちます。
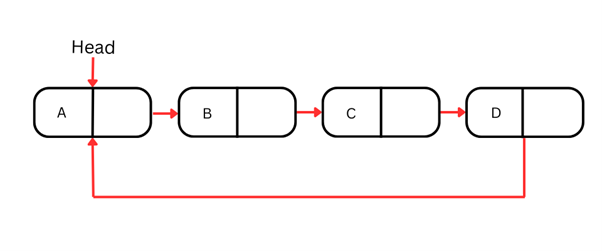
循環連結リスト
循環連結リストは、最後のノードが最初のノードを指す特殊な形式で、円環状の構造を成します。つまり、これまで見た単方向・双方向連結リストと異なり、循環連結リストには終端がなく、ループします。
この循環的な性質は、最後のプレイヤーから最初のプレイヤーに戻るボードゲームや、ラウンドロビン・スケジューリングのように、継続的にループ処理が必要な場面に適しています。
連結リストとPythonリストの違いを一目で把握しましょう。
| 操作 | 単方向連結リスト | 配列/Pythonリスト |
|---|---|---|
| インデックスによるアクセス | O(n) | O(1) |
| 値による探索 | O(n) | O(n) |
| 先頭への挿入 | O(1) | O(n) |
| 末尾への挿入 | O(n) | 償却O(1) |
| 中間への挿入 | O(n) | O(n) |
| 先頭の削除 | O(1) | O(n) |
| 末尾の削除 | O(n) | 償却O(1) |
要点: 連結リストは先頭での挿入・削除がO(1)で有利ですが、それ以外は不利です。データ構造の先頭での追加・削除を頻繁に行わないなら、通常のPythonリストのほうが適している可能性が高いでしょう。
連結リストの概要、用途、バリエーションがわかったところで、Pythonで実装してみましょう。本チュートリアルのノートブックはこのDataLabワークブックでも利用できます。コピーを作成すれば、コードを編集して実行できます。手元の環境でうまく動かない場合にも便利です。
前述のとおり、ノードはデータと、次のノードへの参照を保持する連結リストの要素です。Pythonでノードを定義する方法は以下のとおりです。
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"上のコードは、ノードを初期化する際に2つの主要な処理を行います。まず、ノードの「data」属性に、そのノードが保持すべき実データを代入します。次に、「next」属性は次のノードのアドレスを表し、現在はNoneに設定されています。これは、現時点では他のノードにリンクしていないことを意味します。連結リストに新しいノードを追加していくにつれて、この属性は後続ノードを指すように更新されます。
続いて、連結リストのクラスを作成します。ここでは挿入や削除など、ノード管理のための操作をカプセル化します。まずは連結リストの初期化から始めます。
class LinkedList:
def __init__(self):
self.head = None # Initialize head as Noneself.headをNoneに設定することで、連結リストが空であり、指し示すノードがないことを表します。ここから新しいノードを挿入してリストを構築していきます。
LinkedListクラス内に、新しいノードを作成してリストの先頭に配置するメソッドを追加します。
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new nodeこのメソッドを呼ぶたびに、指定したデータを持つ新しいノードが作成されます。新ノードの次ポインタは現在の先頭を指すように設定され、既存ノードの前に配置されます。最後に、その新しいノードがリストの先頭になります。
挿入の流れをよりよく理解するため、いくつかの単語を使ってリストを構築してみましょう。まず、リストの内容を走査して表示するメソッドを作成します。
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new lineこのメソッドは、連結リストの内容を表示します。では、定義したメソッドを使って「the quick brown fox」という一連の単語でリストを構築してみましょう。
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()上のコードは次の出力を生成するはずです。
"the quick brown fox"
LinkedListクラス内にinsertAtEndというメソッドを作成し、リストの末尾に新しいノードを追加します。リストが空の場合は、新しいノードが先頭になります。そうでなければ、現在の最後のノードの後ろに追加されます。実装は次のとおりです。
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_nodeこのメソッドは新しいノードを作成し、リストが空かどうかを確認します。空であればそのノードを先頭に設定し、そうでなければ末尾ノードを見つけて、その次ポインタを新ノードに設定します。
このメソッドをLinkedListクラスに追加し、リストの末尾に単語を1つ加えてみましょう。メイン関数を次のように変更します。
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()ここでは、insertAtEndを呼び出して、末尾に「jumps」を追加しています。上のコードは次の出力を生成するはずです。
"the quick brown fox jumps"
連結リストの先頭ノードの削除は簡単で、先頭を2番目のノードに付け替えるだけです。これにより、元の先頭ノードはリストから外れます。次のメソッドをLinkedListクラスに追加してください。
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new head連結リストの最後のノードを削除するには、リストを走査して「最後から2番目のノード」を見つけ、その次ポインタをNoneに変更します。これで最後のノードがリストから外れます。以下のメソッドをLinkedListクラスに追加してください。
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to Noneこのメソッドは、まず連結リストが空かどうかを確認し、空ならメッセージを返します。要素が1つだけなら、そのノードを削除します。複数ノードがある場合は最後から2番目のノードを見つけ、その次ノードの参照をNoneに更新します。
では、メイン関数を更新し、先頭と末尾から要素を削除してみましょう。
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()このコードは、削除前後のリストを表示し、連結リストでの挿入・削除の動作を確認できます。実行すると次の出力が得られるはずです。
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox最後に学ぶ操作は、連結リストから特定の値を取得する方法です。リストの先頭から開始し、各ノードを順にチェックして、そのデータが探索値と一致するかを確認します。実装例は以下のとおりです。
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" 作成した連結リストで特定の値を検索してみましょう。メイン関数を更新し、先ほどのsearchメソッドを組み込みます。
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to findこのコードは次の出力を生成します。
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the list「quick」はリストの先頭に存在するため、正しく見つかっています。一方で「lazy」はリストに含まれていないため、見つかりません。
ここまで読み進めた方はおめでとうございます。連結リストの基本原理、構造、種類、要素の追加・削除方法、そして走査方法についてしっかり理解できたはずです。
しかし、ここがゴールではありません。連結リストは、データ構造とアルゴリズムの世界への入り口にすぎません。理解を深めるための次のステップをいくつか紹介します。
連結リストを実際のコーディングやデータサイエンスのプロジェクトに組み込んで、実用面から学んでみてください。連結リストは、ファイルシステムの開発、ハッシュテーブルの構築、GPSナビゲーションやボードゲームの作成などで使われます。自分のプロジェクトを始めるには、Python、R、SQLで実世界の課題解決を学べる無料のガイド付きデータサイエンスプロジェクトをチェックしてください。
スタック、キュー、木構造など、他のデータ構造を学ぶのは自然な次のステップです。これらは連結リストの原理を発展させたもので、より幅広い計算問題を効率的に解く助けになります。たとえば木構造や二分探索木は、連結リストの概念を階層的に拡張し、各ノードが構造内の複数要素に接続できるようにします。
もしこれらの概念に馴染みがなくても心配はいりません。DatacampにはPythonで学ぶデータ構造とアルゴリズムのコースがあり、詳細に解説します。まずスタック、木、ハッシュテーブル、キュー、グラフといったデータ構造を学び、その後、探索・ソートアルゴリズムを理解して、より効率的なプログラマ兼問題解決者になることを目指します。
このチュートリアルでは単方向連結リストを実装し、挿入、削除、走査といった操作を扱いました。
さらに一歩進んで、双方向連結リストや循環連結リストの実装を学んでみてください。スキップリストは連結リストの拡張で、要素へのより高速なアクセスを可能にし、探索を高速化します。
こうした高度なデータ構造を学ぶことで、技術スキルが一段と向上し、データサイエンス、ソフトウェア開発、機械学習エンジニアリングといった分野で、より複雑な課題に取り組む準備が整います。
もしこれらの高度なトピックの前に、より入門的なプログラミングの学習をしたい場合は、Python Programmerキャリアトラックをご覧ください。言語の基礎を学べる一連のコースが含まれています。
Python学習を続けましょう!
Tracks
Tracks
Courses