tracks
Python 데이터 기초
28
연결 리스트(linked list)는 데이터 조직과 관리에서 핵심적인 역할을 하는 자료 구조입니다. 메모리의 임의 위치에 저장된 일련의 노드로 구성되어 있어 메모리를 효율적으로 관리할 수 있습니다. 연결 리스트의 각 노드는 두 가지 주요 구성 요소를 갖습니다: 데이터 부분과 다음 노드를 가리키는 참조입니다.
처음 들으면 복잡하게 느껴질 수 있지만 걱정하지 마세요!
연결 리스트가 무엇인지, 왜 사용하는지, 그리고 어떤 고유한 장점이 있는지 기초부터 차근차근 설명하겠습니다.
연결 리스트는 일반 리스트와 배열에 데이터를 저장할 때 발생하는 여러 단점을 보완하기 위해 만들어졌습니다. 아래에서 살펴보겠습니다.
리스트에서 끝이 아닌 임의의 위치에 요소를 삽입하거나 삭제하려면, 그 이후의 모든 항목을 새로운 위치로 이동해야 합니다. 이 과정의 시간 복잡도는 O(n)이며, 특히 리스트 크기가 커질수록 성능이 크게 저하될 수 있습니다. 리스트의 작동 방식이나 구현에 아직 익숙하지 않다면 파이썬 리스트 튜토리얼을 참고하세요.
반면 연결 리스트는 다르게 동작합니다. 요소를 비연속적인 다양한 메모리 위치에 저장하고, 다음 노드를 가리키는 포인터로 서로 연결합니다. 이 구조 덕분에 링크만 수정하여 새 요소를 포함시키거나 삭제된 요소를 건너뛰는 방식으로, 어느 위치에서든 요소를 추가하거나 제거할 수 있습니다.
삽입 혹은 삭제 지점의 노드를 직접 참조할 수 있다면, 해당 연산 자체는 O(1)입니다. 다만 그 위치를 찾기 위해서는 여전히 O(n) 순회가 필요하므로, O(1) 이점은 관련 노드에 대한 포인터를 이미 가지고 있을 때(예: 리스트의 머리에서 작업할 때)에만 적용됩니다.
파이썬 리스트는 동적 배열로, 크기를 유연하게 변경할 수 있습니다.
하지만 이 과정에는 더 큰 메모리 블록으로 배열을 재할당하는 등 복잡한 작업이 수반됩니다. 재할당 시 요소를 새 블록으로 복사해야 하고, 당장 필요 이상으로 많은 공간이 할당될 수 있어 비효율적입니다.
이에 비해 연결 리스트는 재할당이나 리사이징 없이도 동적으로 커지거나 줄어들 수 있습니다. 높은 유연성이 필요한 작업에 더 적합한 선택입니다.
리스트는 모든 요소에 대해 연속된 메모리 블록을 할당합니다. 초기 크기를 넘어 확장해야 하면 더 큰 연속 메모리 블록을 새로 할당하고 기존 요소를 모두 복사해야 합니다. 이는 특히 큰 리스트일수록 시간도 많이 들고 비효율적입니다. 반대로 초기 크기를 과대평가하면 사용하지 않는 메모리가 낭비됩니다.
반면 연결 리스트는 각 요소마다 별도로 메모리를 할당합니다. 새로운 요소가 추가될 때마다 필요한 만큼만 메모리를 할당할 수 있어 메모리 활용도가 더 높습니다.
연결 리스트는 동적 크기와 메모리 효율성 등에서 일반 리스트와 배열 대비 이점이 있지만, 한계도 있습니다. 각 요소가 다음 노드를 참조하기 위한 포인터를 저장해야 하므로, 요소 하나당 메모리 사용량이 더 큽니다. 또한 이 자료 구조는 데이터에 대한 직접 접근을 허용하지 않습니다. 특정 요소에 접근하려면 리스트의 시작부터 순차적으로 순회해야 하므로, 탐색의 시간 복잡도는 O(n)입니다.
연결 리스트와 배열 중 무엇을 사용할지는 애플리케이션의 요구 사항에 달려 있습니다. 연결 리스트가 특히 유용한 경우는 다음과 같습니다.
연결 리스트에는 세 가지 종류가 있으며, 각기 다른 상황에서 고유한 이점을 제공합니다. 다음과 같습니다.
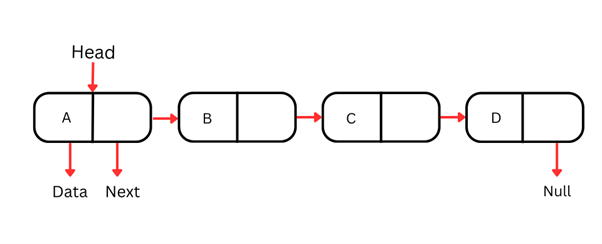
단일 연결 리스트
단일 연결 리스트는 가장 단순한 형태로, 각 노드가 데이터와 다음 노드에 대한 참조를 담습니다. 오직 한 방향으로만 순회할 수 있습니다. 즉, 머리(첫 번째 노드)에서 꼬리(마지막 노드)로 진행합니다.
단일 연결 리스트의 각 노드는 일반적으로 두 부분으로 이루어집니다.
이 자료 구조는 한 방향으로만 순회할 수 있기 때문에, 값이나 인덱스로 특정 요소에 접근하려면 머리부터 시작해 원하는 노드를 찾을 때까지 순차적으로 이동해야 합니다. 이 연산의 시간 복잡도는 O(n)이며, 큰 리스트에서는 비효율적입니다.
반면 리스트의 시작 부분에서 노드를 삽입하거나 삭제하는 작업은 매우 효율적이며 시간 복잡도는 O(1)입니다. 하지만 중간이나 끝에서의 삽입·삭제는 해당 지점까지 리스트를 순회해야 하므로 O(n) 시간이 듭니다.
단일 연결 리스트의 설계는 리스트의 시작 부분에서 발생하는 작업에 특히 유용합니다.
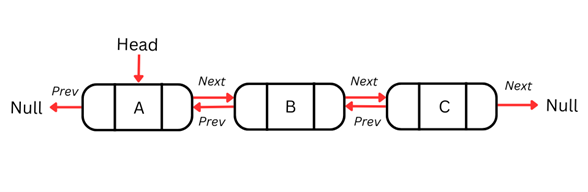
이중 연결 리스트
단일 연결 리스트의 단점은 한 방향으로만 순회할 수 있어 필요할 때 이전 노드로 되돌아갈 수 없다는 점입니다. 이 제약은 양방향 내비게이션이 필요한 작업에 한계를 줍니다.
이중 연결 리스트는 각 노드에 포인터를 하나 더 추가해 이 문제를 해결합니다. 리스트를 양방향으로 순회할 수 있도록, 각 노드는 데이터, 다음 노드에 대한 포인터, 이전 노드에 대한 포인터의 세 요소를 가집니다.
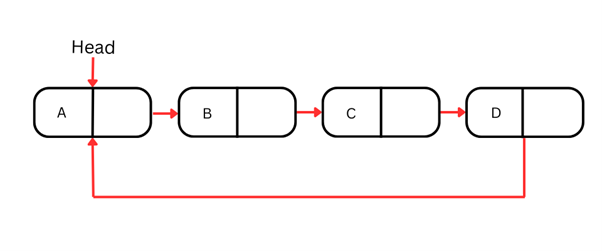
원형 연결 리스트
원형 연결 리스트는 마지막 노드가 첫 번째 노드를 다시 가리키는 특수한 형태로, 원형 구조를 이룹니다. 즉, 지금까지 본 단일·이중 연결 리스트와 달리, 원형 연결 리스트는 끝나지 않고 순환합니다.
이 순환적 특성은 마지막 플레이어에서 첫 번째 플레이어로 돌아가는 보드게임처럼 계속 반복 순회해야 하는 상황이나, 라운드 로빈 스케줄링 같은 컴퓨팅 알고리즘에 이상적입니다.
연결 리스트와 파이썬 리스트를 한눈에 비교하면 다음과 같습니다.
| 연산 | 단일 연결 리스트 | 배열/파이썬 리스트 |
|---|---|---|
| 인덱스로 접근 | O(n) | O(1) |
| 값으로 검색 | O(n) | O(n) |
| 처음에 삽입 | O(1) | O(n) |
| 끝에 삽입 | O(n) | 상환 O(1) |
| 중간에 삽입 | O(n) | O(n) |
| 처음에서 삭제 | O(1) | O(n) |
| 끝에서 삭제 | O(n) | 상환 O(1) |
핵심 요약: 연결 리스트는 머리에서의 삽입과 삭제가 O(1)로 유리하지만, 그 외 대부분에서는 불리합니다. 데이터 구조의 시작 부분에서 요소를 자주 추가하거나 제거하지 않는다면 일반 파이썬 리스트가 더 나은 선택일 가능성이 큽니다.
연결 리스트의 개념, 사용 이유, 변형을 이해했으니 이제 파이썬으로 구현해 보겠습니다. 이 튜토리얼의 노트북은 이 DataLab 워크북에서도 제공됩니다. 사본을 만들어 코드를 편집하고 실행할 수 있으니, 로컬 실행에 문제가 생길 경우 좋은 대안입니다.
앞서 배운 대로, 노드는 데이터와 다음 노드에 대한 참조를 저장하는 연결 리스트의 구성 요소입니다. 파이썬에서 노드를 정의하는 방법은 다음과 같습니다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"위 코드는 두 가지 주요 동작으로 노드를 초기화합니다. 첫째, 노드의 “data” 속성에 노드가 담아야 할 실제 정보를 할당합니다. 둘째, “next” 속성은 다음 노드의 주소를 나타내며, 현재는 None으로 설정되어 리스트의 다른 어떤 노드와도 연결되지 않았음을 의미합니다. 연결 리스트에 새 노드를 추가해 나가면, 이 속성은 다음 노드를 가리키도록 업데이트됩니다.
다음으로 연결 리스트 클래스를 만들어야 합니다. 이 클래스는 삽입, 제거 같은 노드 관리 연산을 모두 캡슐화합니다. 초기화부터 시작해 보겠습니다.
class LinkedList:
def __init__(self):
self.head = None # Initialize head as Noneself.head를 None으로 설정함으로써, 연결 리스트가 초기에는 비어 있으며 가리킬 노드가 없음을 나타냅니다. 이제 새 노드를 삽입해 리스트를 채워 보겠습니다.
LinkedList 클래스 안에, 새 노드를 만들고 리스트의 시작에 배치하는 메서드를 추가하겠습니다.
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new node위 메서드를 호출할 때마다 지정한 데이터로 새 노드가 생성됩니다. 새 노드의 다음 포인터를 현재 머리로 설정해 기존 노드들 앞에 배치한 다음, 새 노드를 리스트의 머리로 만듭니다.
이제 삽입 동작을 더 잘 이해하기 위해 일련의 단어로 연결 리스트를 채워 보겠습니다. 이를 위해 먼저 리스트의 내용을 순회하며 출력하는 메서드를 작성합니다.
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new line위 메서드는 연결 리스트의 내용을 출력합니다. 이제 정의한 메서드들을 사용해 “the quick brown fox”라는 단어들을 리스트에 채워 보겠습니다.
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()위 코드는 다음과 같은 출력을 생성합니다.
"the quick brown fox"
LinkedList 클래스에 insertAtEnd라는 메서드를 만들어 리스트의 끝에 새 노드를 추가하겠습니다. 리스트가 비어 있다면 새 노드가 머리가 됩니다. 그렇지 않다면 현재 마지막 노드 뒤에 이어 붙입니다. 실제 작동 방식을 보겠습니다.
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_node이 메서드는 새 노드를 만든 뒤 리스트가 비어 있는지 확인합니다. 비어 있다면 새 노드를 머리로 지정합니다. 그렇지 않으면 리스트를 순회해 마지막 노드를 찾고, 그 노드의 포인터를 새 노드로 설정합니다.
이제 이 메서드를 LinkedList 클래스에 포함하고, 리스트의 끝에 단어를 추가해 보겠습니다. 이를 위해 메인 함수를 다음과 같이 수정하세요.
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()방금 insertAtEnd 메서드를 호출해 리스트의 끝에 “jumps”를 추가했습니다. 위 코드는 다음과 같은 출력을 생성합니다.
"the quick brown fox jumps"
연결 리스트의 첫 번째 노드를 삭제하는 일은 간단합니다. 머리를 두 번째 노드로 바꾸기만 하면 첫 번째 노드는 더 이상 리스트의 일부가 아닙니다. 이를 위해 LinkedList 클래스에 다음 메서드를 추가하세요.
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new head연결 리스트의 마지막 노드를 삭제하려면, 리스트를 순회해 끝에서 두 번째 노드를 찾은 뒤 그 노드의 다음 포인터를 None으로 바꿔야 합니다. 그러면 마지막 노드는 더 이상 리스트의 일부가 아닙니다. 다음 메서드를 LinkedList 클래스에 추가하세요.
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to None위 메서드는 먼저 연결 리스트가 비어 있는지 확인하고, 비어 있다면 메시지를 반환합니다. 한 개의 노드만 있으면 그 노드를 제거합니다. 여러 노드가 있는 경우에는 끝에서 두 번째 노드를 찾아, 그 노드의 다음 참조를 None으로 업데이트합니다.
이제 메인 함수를 업데이트하여 연결 리스트의 시작과 끝에서 요소를 삭제해 보겠습니다.
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()위 코드는 삭제 전후의 리스트를 출력하여, 연결 리스트에서 삽입/삭제 연산이 어떻게 동작하는지 보여줍니다. 실행하면 다음과 같은 출력을 확인할 수 있습니다.
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox이번 장의 마지막으로, 연결 리스트에서 특정 값을 찾는 방법을 배웁니다. 이를 위해 메서드는 리스트의 머리에서 시작해 각 노드를 순회하며, 노드의 데이터가 찾는 값과 일치하는지 확인해야 합니다. 실용적인 구현은 다음과 같습니다.
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" 방금 만든 검색 메서드를 메인 함수에 추가해, 생성한 연결 리스트에서 특정 값을 찾아봅시다.
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to find위 코드는 다음과 같은 출력을 생성합니다.
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the list단어 “quick”은 리스트의 첫 번째 위치에 있으므로 성공적으로 찾아졌습니다. 반면 “lazy”는 리스트에 없기 때문에 찾을 수 없습니다.
여기까지 오셨다면 축하합니다! 이제 연결 리스트의 기본 원리, 구조와 종류, 요소를 추가·제거하는 방법, 그리고 순회 방법에 대해 탄탄히 이해하셨습니다.
하지만 여기가 끝은 아닙니다. 연결 리스트는 자료 구조와 알고리즘 세계의 출발점일 뿐입니다. 다음은 이해를 한층 더 심화하기 위한 잠재적인 다음 단계입니다.
연결 리스트를 코딩 또는 데이터 사이언스 프로젝트에 통합해 실제 활용을 탐구해 보세요. 연결 리스트는 파일 시스템 개발, 해시 테이블 구성, GPS 내비게이션 시스템과 보드게임 제작 등에도 사용됩니다. 직접 프로젝트를 시작하려면, 파이썬·R·SQL로 현실 세계의 문제를 해결하는 방법을 가르쳐 주는 무료 가이드형 데이터 사이언스 프로젝트를 확인해 보세요.
트리, 스택, 큐 같은 다른 자료 구조를 배우는 것은 연결 리스트 이해 이후의 자연스러운 다음 단계입니다. 이러한 구조는 연결 리스트의 원리를 확장해 더 다양한 계산 문제를 효율적으로 해결하도록 도와줍니다. 예를 들어 트리와 이진 탐색 트리는 연결 리스트 개념을 계층적 형태로 확장해, 각 노드가 자료 구조 내 여러 요소와 연결될 수 있게 합니다.
이 개념들이 낯설게 느껴진다면 걱정하지 마세요! Datacamp에는 파이썬으로 배우는 자료 구조와 알고리즘 전용 코스가 있어 이러한 개념을 더 깊이 있게 다룹니다. 먼저 스택, 트리, 해시 테이블, 큐, 그래프 등 자료 구조를 배우고, 이어서 탐색과 정렬 알고리즘을 이해해 더 효율적인 프로그래머이자 문제 해결자가 될 수 있습니다.
이 튜토리얼에서는 단일 연결 리스트를 구현하며 삽입, 삭제, 순회 같은 연산을 다뤘습니다.
여기서 한 걸음 더 나아가 이중 및 원형 연결 리스트 구현을 배울 수 있습니다. 스킵 리스트는 연결 리스트의 또 다른 확장으로, 요소에 더 빠르게 접근할 수 있어 검색 속도를 높여 줍니다.
이러한 고급 자료 구조를 학습하면 기술 역량이 한 단계 도약하고, 데이터 사이언스, 소프트웨어 개발, 머신러닝 엔지니어링 같은 분야에서 더 복잡한 과제에 대비할 수 있습니다.
고급 주제를 다루기 전에 더 기초적인 프로그래밍 입문을 원하신다면, Python Programmer 커리어 트랙을 살펴보세요. 언어의 기초를 배우는 일련의 과정을 제공합니다.
파이썬 학습을 이어가세요!
tracks
tracks
courses